Improving Sequence Tagging for Vietnamese Text Using Transformer-based Neural Models
Authors: Viet Bui The, Oanh Tran Thi, Phuong Le-Hong
Comments: Accepted at the Conference PACLIC 2020
Subjects: Computation and Language (cs.CL)
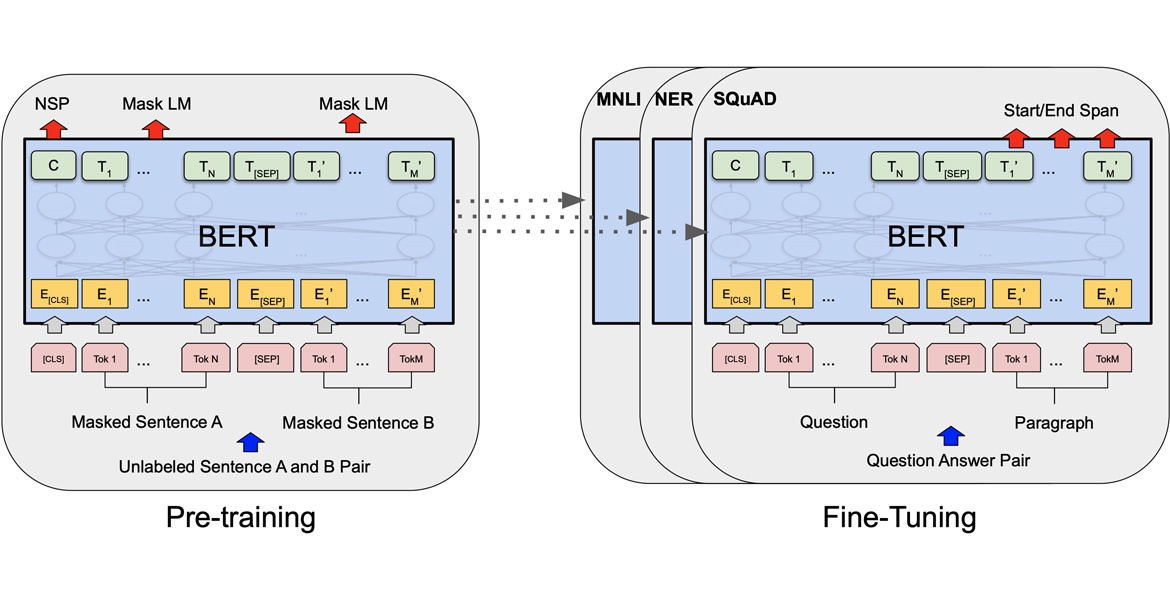
Abstract: This paper describes our study on using mutilingual BERT embeddings and some new neural models for improving sequence tagging tasks for the Vietnamese language. We propose new model architectures and evaluate them extensively on two named entity recognition datasets of VLSP 2016 and VLSP 2018, and on two part-of-speech tagging datasets of VLSP 2010 and VLSP 2013. Our proposed models outperform existing methods and achieve new state-of-the-art results. In particular, we have pushed the accuracy of part-of-speech tagging to 95.40% on the VLSP 2010 corpus, to 96.77% on the VLSP 2013 corpus; and the F1 score of named entity recognition to 94.07% on the VLSP 2016 corpus, to 90.31% on the VLSP 2018 corpus. Our code and pre-trained models viBERT and vELECTRA are released as open source to facilitate adoption and further research
Published: 6/29/2020
Download PDF: https://arxiv.org/pdf/2006.15994.pdf
See more: https://arxiv.org/abs/2006.15994