




光学文字認識識(OCR)は、時間とともに重要な文書が損傷する可能性に関する懸念を解消できる技術です。では、OCRとは何ですか? FPT.AIと共にOCR技術が、タイピングされた、手書きまたは印刷されたテキストの画像をデジタルデータに変換する方法を学び、MB銀行とGRABが成功したデジタル化を実現した方法を見てみましょう。
OCRとは? OCR とは何の略ですか?
OCRは「光学文字認識識」の略で、タイピングされた、手書きまたは印刷されたテキストをコンピュータが読み取れる形式(機械可読形式)に変換する技術です。OCRは、ユーザーが自動的にデータを抽出し(自動データ抽出)、編集、フォーマット、検索を行うことを可能にし、それらがワードプロセッサで作成されたかのように扱えるようにします。
光学文字認識(OCR)は、パターン認識、人工知能(AI)、およびコンピュータビジョン(Computer Vision)の研究から発展しました。OCRソフトウェアは、認知コンピューティング(Cognitive Computing)、機械翻訳(Machine Translation)、テキスト音声変換(Text-to-Speech, TTS)、主要データマイニング(Key Data Mining)、および**テキストマイニング(Text Mining)**を活用し、ユーザーがテキストデータを自動的に抽出、編集、フォーマット、検索できるようにします。これにより、まるでワードプロセッサ(Word Processor)で作成されたかのように、テキストを自在に操作することが可能になります。
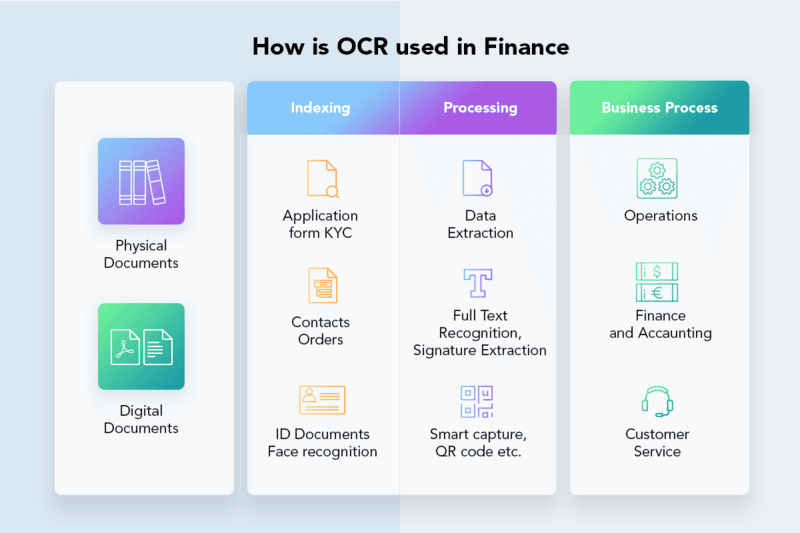
組織は通常、パスポートの書類(passport documents)、請求書(invoices)、銀行明細書(bank statements)、電子領収書(computerized receipts)、名刺(business cards)、郵便物(mail)、印刷されたデータ(printed data)など、紙の記録からデータ入力の形式として光学文字認識識(OCR)を使用します。
現在、光学式文字認識 (OCR) はほぼ完璧な精度を実現しており、ラテン語、キリル文字、アラビア語、ヘブライ語、インド文字、中国語、日本語、韓国語など、多くの表記体系をサポートしています。 OCR テクノロジーの大幅な発展により、テキストを自動的に処理できるようになり、手動によるデータ入力に比べて時間が節約され、エラーが最小限に抑えられます。
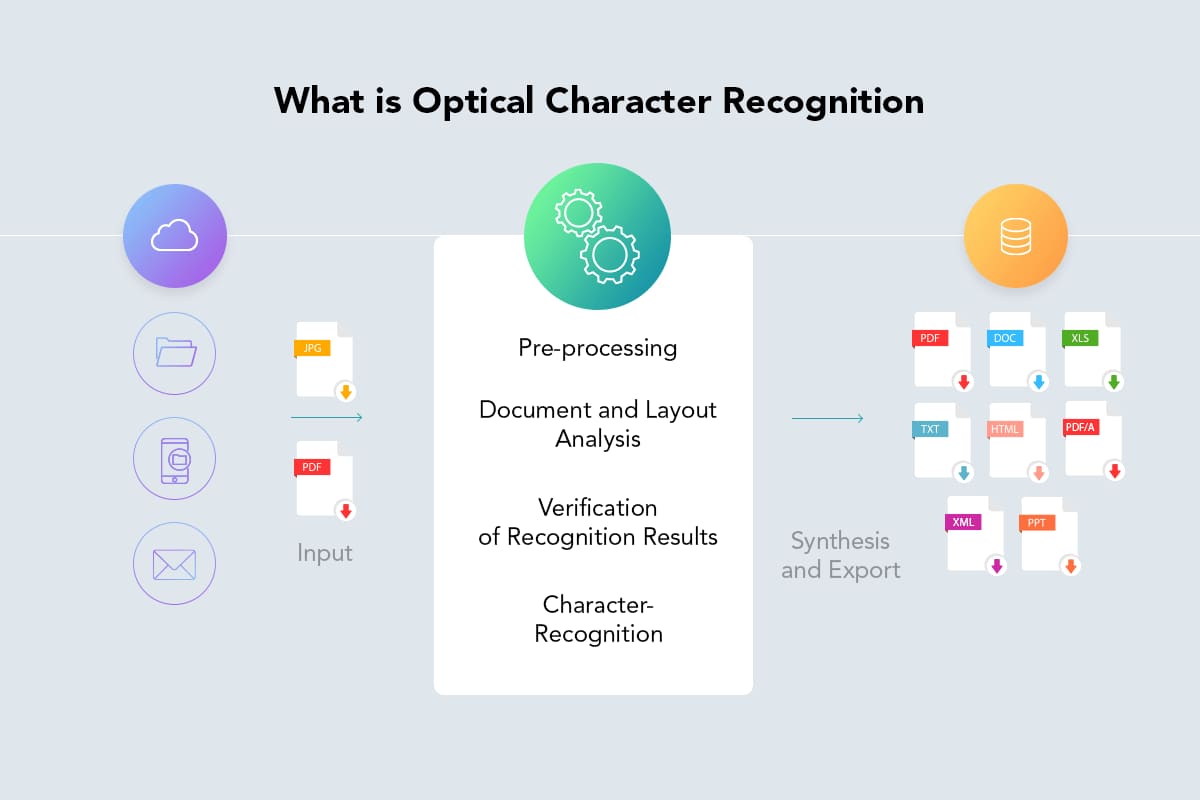
OCR技術はどのように機能するのでしょうか?
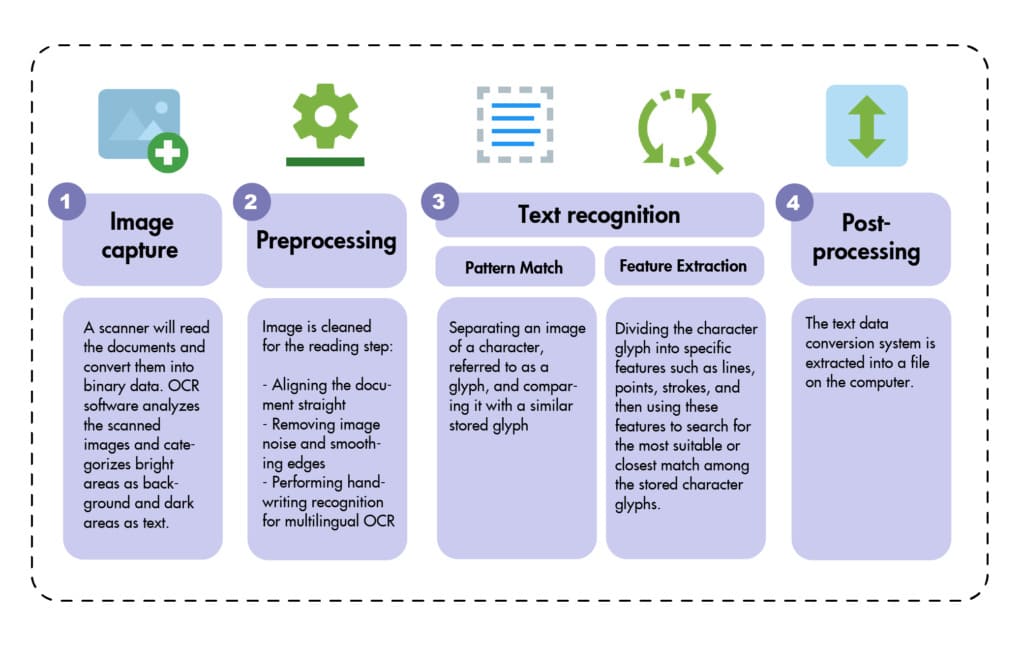
OCR技術を使用するソフトウェア(OCRソフトウェア)は、次の手順でデータをデジタル化します:
- 画像の取得: 文書のページをスキャンして解析し、暗い部分が認識する必要のある文字であり、明るい部分が背景です。
- 前処理: 画像から不要なピクセルを取り除き、その後、直線補正、ノイズ除去、文字のエッジを滑らかにする、画像の点を除去する、枠線を消す、明るさを調整する、またはぼやけを減らす技術を使用して調整します。
- レイアウト認識: OCRソフトウェアは、文書の構造を解析し、ページをテキストブロック、テーブル、または画像に分割します。行は単語に、単語は文字に分割されます。文字が分割された後、ソフトウェアはそれらを画像サンプルのセットと比較します。結果が一致すると、プログラムは認識されたテキストを返します。
- テキスト認識: 暗い領域は、次の 2 つのアルゴリズムのいずれかを使用して文字、数字、または記号を検出するために処理されます。
- テンプレートマッチング:事前に複数のフォントや書式でトレーニングされたOCRプログラムを使用し、入力された文字をシステム内に保存された文字と比較する手法です。この方法は、高品質で標準的なフォーマットの画像に適しています。しかし、世界中のあらゆるフォントや言語の組み合わせに対応するOCRモデルをトレーニングするには、膨大なシステムリソースが必要となります。
- 特徴抽出: 特徴(角度の数、交差点、ループ、または曲線)に基づいて文字を認識する手法で、OCRが訓練されていないフォントを分析する際に使用されます。例えば、”A”は交差する2本の斜線と中央に1本の水平線で識別されます。識別後、文字はコンピュータシステムが処理できるASCII(アメリカ標準情報交換コード)に変換されます。
- テキスト変換: 認識された文字を編集可能なデジタル テキストに変換します。最新の OCR ツールの多くは、特に手書きや不明瞭な文字の精度を向上させるために AI と機械学習を組み込んでいます。
- 後処理: 収集された情報は、編集可能なデジタルファイルまたはPDF形式で保存されます。一部のシステムでは、元の画像とOCR後のバージョンを保持し、比較しやすく、文書管理を簡素化します。
主要なOCRソフトウェア
以下は一般的なOCRソフトウェアの種類の詳細な説明です:
- 簡単な光学文字認識識ソフトウェア:画像内の各文字を内部データベースと照合するために、テンプレートマッチングアルゴリズムを使用します(光学的文字認識)。
- インテリジェント文字認識ソフトウェア(ICR)と機械学習ソフトウェアを使用して、人間のようにテキストを読む技術です。このシステムでは、ニューラルネットワークがテキストを多段階で解析し、繰り返し画像を処理して曲線、直線、円弧などの特性を識別し、その結果を統合して最終的な認識を行います。各文字を処理しますが、全体のプロセスは非常に迅速に行われます(数秒以内に完了)。
- インテリジェント単語認識:ICRのように文字ごとに処理する代わりに、単語全体の画像を分析してその構造と意味を識別し、テキスト認識の精度を高めます。
- 光学的シンボル認識:このOSRソフトウェアは、文書内のロゴ、透かし、およびその他のシンボルを認識することに特化しています。
- 光学マーク認識(OMR):アンケートのチェックボックスや署名を認識することに焦点を当てた技術です。この技術は、保存された画像と照合することによってロゴ、記号、透かしも識別します。
光学文字認識(OCR)の文書デジタル化における利点
- 画像から高精度でテキストを電子データ化可能。特に高品質なフラットベッドスキャナーを使用すると効果的。
- 手作業のデータ入力によるヒューマンエラーを排除または最小化。
- 紙の文書保管コストを削減。
- 複数のドキュメントを同時に処理し、情報検索時間を2〜3秒に短縮。
- 文書のルーティング、コンテンツ処理、テキストマイニングを自動化。
- 視覚障がい者の従業員や顧客が、最新かつ正確な情報にアクセス可能。
- 最新のOCRソフトウェアは、元の表、列、テキストフォーマットを維持しながらデータを変換可能。
ベトナム語OCRの課題
- ⚠ 印刷されたテキストには高精度で対応できるが、手書き認識の精度は低下。
- 一部のOCRソフトウェアおよびハードウェアには大規模な投資が必要。
- OCRの精度は画像品質に依存し、不鮮明な画像やノイズの多いデータは処理が困難。
- 複雑な文書では完全な精度を達成できず、認識後に手動で修正が必要。
- 文字数が少ない文書では、OCRの処理時間が長くなり、効率が低下。

光学文字認識(OCR)の実用化
視覚障害者や高齢者が文書を読むのをサポートします
1974年、Ray KurzweilはKurzweil Computer Products, Inc.を創設し、ほぼすべてのフォントから印刷されたテキストを認識できるOCR技術(オムニフォントOCR)を開発しました。彼は視覚障害者を支援する可能性を認識し、CCD タイプのフラットベッド スキャナーとテキスト音声合成装置を組み合わせたテキスト読み上げ装置を開発し、視覚障害者や高齢者が音声形式の書籍、新聞、文書に簡単にアクセスできるようにしました。
法律事務所や裁判所での書類整理
訴訟では、法的文書の量が非常に多く、高い精度が求められます。ベトナム語OCRソフトウェアは、弁護士が文書を迅速にデジタル化できるようサポートし、キーワード、ファイル番号、または事件日付で情報を検索できるようにします。これにより、弁護士は時間を節約し、スタッフの必要性を減らしながらも、業務を科学的かつ正確に管理できます。
貴重な文書の保存
図書館、文化センター、博物館は多くの貴重な文書を保存していますが、それらの保存は時間の経過とともに損傷のリスクがあるため、難しいことがあります。光学文字認識識(OCR)技術は、これらの文書を紙から電子ファイルに変換し、保存、保存、そして文化遺産へのアクセスを容易にし、長期的な持続可能性を確保します。
個人識別
OCR は、銀行、空港、政府機関で ID カード、パスポート、運転免許証などの文書を迅速にスキャンして処理し、エラーを減らし、処理を高速化し、安全な情報保管をサポートします。
実際、バンク・オブ・アメリカは、OCR テクノロジーを使用して、支払いサービスにおける文書および請求書の処理を自動化しています。顧客はアプリケーションを通じて請求書の写真を撮るだけで、光学文字認識システムがデータを識別、処理し、必要なフォームに自動的に入力するため、顧客体験が向上し、待ち時間が短縮されます。
請求書および文書処理
機関や組織では、印刷されたテキスト、手書きのテキスト、PDF、JPG など、さまざまな形式の大量の文書を処理することがよくあります。 OCR システムは、請求書や契約書を紙から電子ファイルに変換し、電子メール、ファックス、EDI などのデータベースやシステムへのデータの保存、編集、共有、統合を可能にして、作業効率を高め、エラーのリスクを最小限に抑えます。
Walmart は OCR を使用してサプライヤーの請求書をデジタル化し、管理しています。システムは紙の請求書を自動的に認識して電子システムに保存し、文書管理コストを節約します。請求書データは取引に直接リンクされているため、注文の追跡と処理の効率が向上します。
医療記録の識別とデジタル化
米国有数の病院の 1 つであるクリーブランド クリニックでは、光学式文字認識 (OCR) テクノロジを導入して、医療文書、処方箋、患者記録をデジタル化しています。このシステムは紙の記録を電子データに変換し、医師が患者の情報に素早くアクセスできるようにし、医療上の意思決定を改善し、紙の文書を保管することによるリスクを最小限に抑えます。
現在市場で最も優れた OCR ソフトウェア TOP 5
| ソフトウェア | アドバンテージ | 制限 | 対象者 |
| FPT AI Read | – 現在市場で最も高い精度、最大98%
– シンプルなインターフェース、プログラミングの知識がなくても使用可能 |
ぼやけた画像、不鮮明な画像、または解像度が低い画像は、データ抽出の精度を低下させる可能性があります。 | 企業には、API 統合とモデルのカスタマイズを備えた AI 搭載 OCR が必要です。 |
| Adobe Acrobat Pro | Adobe エコシステムとの統合、ドキュメント セキュリティ、および自動ドキュメント処理を可能にします。 | クラウド機能を最大限に活用するには、高度な構成、複雑なインターフェース、インターネット接続が必要です。 | スキャンされた文書、契約書、法的文書を OCR およびセキュリティを使用して処理する専門家。画像編集機能が制限されており、大きな PDF ファイルを処理するには高性能なコンピューターが必要です。 |
| Foxit PDF Editor | ドキュメントの抽出と要約、多言語サポート、AI ドキュメント分析、安全な暗号化。 | 画像編集機能が制限されており、大きな PDF ファイルを処理するには高性能なコンピューターが必要です。 | ユーザーには、ドキュメントの要約と AI 分析を備えた多言語 OCR テクノロジーが必要です。 |
| Microsoft OneNote | 画像や手書きのメモ用の基本的な OCR ツールで、複数ページのドキュメントからテキストを抽出します。 | 精度は画像の品質に依存し、複雑なドキュメントからのデータの自動分類や並べ替えには依存しません。 | ユーザーは、画像や手書きのメモ用の高速でシンプルな OCR を必要としています。 |
| Google Cloud Vision | クラウドベースの OCR ソフトウェア、高精度、手書き認識サポート、Google Cloud 統合。 | すべての機能を使用するにはコストが高く、複雑な構造のドキュメントの処理が難しく、技術的な知識が必要です。 | 組織には、Google Cloud 統合と画像分析を備えた大規模な OCR が必要です。 |
FPT AI Read はドキュメント テンプレートのライブラリを提供しており、ユーザーは ID カード、運転免許証、パスポート、VAT 請求書、契約書、文書、医療記録、車両登録、候補者の履歴書など 30 種類以上を最大 98% の精度で素早く抽出できます。このソリューションは、低品質 (ぼやけた、不鮮明な) 画像や複雑に構造化された画像の両方を適切に処理します。
画像をアップロードすると、システムは重要な情報フィールドを自動的に認識して抽出します。 FPT AI Read は、プログラミングの知識がないユーザーにも適した、シンプルで使いやすいインターフェースを備えています。ユーザーは、独自のモデルをトレーニングし、独自のデータにラベルを付け、API OCR を介して抽出されたデータを接続して使用することもできます。
FPT AI Read は、企業のドキュメント処理を自動化し、手作業を減らして運用効率を高めます。ソリューションの詳細については、次のビデオをご覧ください。
FPT AI Readベトナム語OCRソリューションがMB銀行のデジタル化を成功に導く
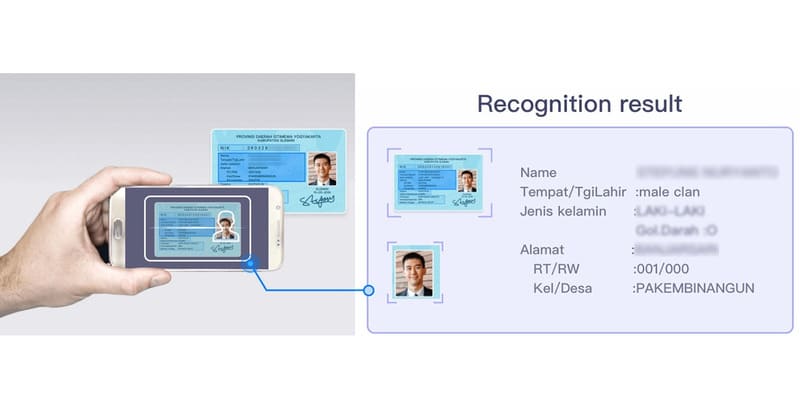
MB銀行では、2020年にMBファミリー製品パッケージを発表した際、登録書類の処理において大きな課題に直面しました。FPT AI Readは、身分証明書、住民票、出生証明書などの書類からデータを自動的に抽出し、顧客の書類処理、電子顧客識別(eKYC)を支援しました。
FPT AI Readは、銀行が1日約5,000件の要求を処理するのを助けるだけでなく、データ入力のスピードと精度を高く保ち、スタッフの負担を軽減し、顧客体験を向上させました。FPT AI ReadはMB銀行が迅速に顧客識別を行うことを支援します。
これまでの成功を考慮すると、OCR技術は多くの組織のデジタル化の道筋において今後も欠かせない要素であると言えます。企業に適した技術ソリューションの詳細な相談とカスタマイズを希望する場合は、FPT AIのホットライン(1900 638 399)に連絡するか、FPT.AIにアクセスして早急にサポートを受けてください!
参照元:
- IBM。 (日付なし)。光学文字認識。 IBM。 2025年1月21日取得、https://www.ibm.com/think/topics/optical-character-recognitionより
ウィキペディア。 (日付なし)。光学文字認識。ウィキペディア。 2025年1月21日取得、https://en.wikipedia.org/wiki/Optical_character_recognitionより




