




ASR (Automatic Speech Recognition) đang trở thành công nghệ then chốt giúp doanh nghiệp mở ra kỷ nguyên hội thoại thông minh. Nhờ kết hợp với Natural Language Processing (NLP) và Text to Speech (TTS), hệ thống có thể nghe – hiểu – phản hồi bằng giọng nói tự nhiên, mang đến trải nghiệm cá nhân hóa và tối ưu vận hành ở quy mô lớn.
Thực trạng ASR và xu hướng ứng dụng trên thế giới
ASR (Automatic Speech Recognition – Nhận dạng giọng nói tự động) là công nghệ cho phép máy tính chuyển giọng nói của con người thành văn bản một cách tự động, chính xác và nhanh chóng. Đây là nền tảng quan trọng trong các hệ thống tương tác bằng giọng nói như trợ lý ảo (Google Assistant, Siri, Alexa), tổng đài thông minh, Voicebot hay các thiết bị IoT. Từ một công nghệ mang tính nghiên cứu, ASR hiện đã phát triển mạnh mẽ và trở thành một phần không thể thiếu trong cuộc sống hiện đại.
Trên thế giới, các “ông lớn” công nghệ như Google, Apple, Amazon, Microsoft và OpenAI đều đầu tư mạnh vào lĩnh vực này. ASR không chỉ được ứng dụng trong điện thoại hay loa thông minh, mà còn mở rộng ra các lĩnh vực như chăm sóc khách hàng, y tế, giáo dục, tài chính, sản xuất và ô tô. Tại Mỹ và châu Âu, công nghệ ASR đã trở thành công cụ phổ biến trong việc ghi biên bản họp tự động, chuyển lời giảng thành tài liệu học tập hay hỗ trợ người khuyết tật giao tiếp. Các mô hình tiên tiến như Whisper của OpenAI hay wav2vec 2.0 của Meta AI đang mở ra xu hướng “End-to-End ASR” – tích hợp toàn bộ pipeline trong một mô hình duy nhất, giúp tăng độ chính xác, giảm độ trễ và dễ huấn luyện cho nhiều ngôn ngữ, bao gồm cả tiếng địa phương.
Nguyên lý hoạt động của ASR
Về cơ bản, một hệ thống ASR hoạt động qua 6 bước chính: (1) thu âm và xử lý tín hiệu âm thanh, (2) trích xuất đặc trưng âm học, (3) mô hình hóa âm thanh bằng mạng neural, (4) mô hình ngôn ngữ để dự đoán chuỗi từ hợp lý, (5) từ điển phát âm (nếu có), và (6) bộ giải mã đưa ra văn bản đầu ra. Với sự phát triển của trí tuệ nhân tạo, các mô hình ASR hiện đại tích hợp toàn bộ các bước trên trong một mạng nơ-ron học sâu, giúp cải thiện đáng kể độ chính xác trong môi trường tiếng nói tự nhiên, nhiều tạp âm, ngữ điệu phức tạp.
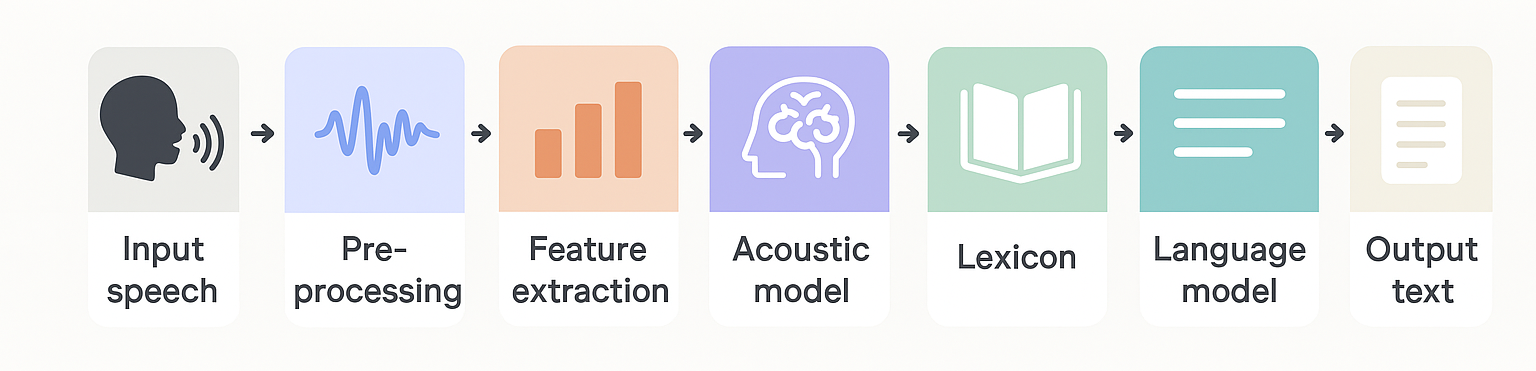
Sơ đồ một hệ thống ASR hoạt động qua 6 bước chính
Bộ ba công nghệ ASR (Nhận dạng giọng nói) + NLP (Hiểu ngôn ngữ tự nhiên) + TTS (Tổng hợp giọng nói) tạo thành trục xương sống cho hệ thống hội thoại AI hiện đại, mở ra một kỷ nguyên mới cho tự động hóa giao tiếp trong doanh nghiệp.
ASR chính là là công nghệ giúp máy nghe và chuyển lời nói thành văn bản – “cửa ngõ” để các hệ thống Voicebot và AI Agent có thể tiếp nhận đầu vào bằng lời nói. Đây là điểm khởi đầu của mọi tương tác bằng giọng nói. Nhờ vào ASR, hệ thống có thể tiếp nhận thông tin đầu vào từ con người một cách tự nhiên, không cần chạm – chỉ cần nói. Công nghệ ASR hiện đại như Whisper (OpenAI) hay FPT AI Speech to Text tại Việt Nam có thể nhận diện giọng nói đa vùng miền, nhiều ngữ điệu, tốc độ tự nhiên, giúp người dùng cảm thấy “máy móc đang thật sự lắng nghe”.
Sau khi lời nói được chuyển thành văn bản, hệ thống cần hiểu được nội dung, ý định và ngữ cảnh. Đó là lúc NLP phát huy vai trò. NLP giúp phân tích văn bản, xác định mục đích người dùng (intent), trích xuất thông tin quan trọng (entities), và chọn cách phản hồi phù hợp. Ví dụ: Khách nói: “Tôi muốn tra hóa đơn tháng trước” → ASR chuyển thành văn bản → NLP hiểu đây là ý định tra cứu thông tin hóa đơn → Gọi API → Text to Speech phản hồi. NLP cũng chính là nơi để “đào tạo” hệ thống hiểu ngôn ngữ ngành, ngôn ngữ khách hàng, và tự thích nghi dần theo thời gian. Tại Việt Nam, nền tảng Conversational AI của FPT.AI cung cấp khả năng huấn luyện kịch bản hội thoại thông minh, linh hoạt theo domain doanh nghiệp.
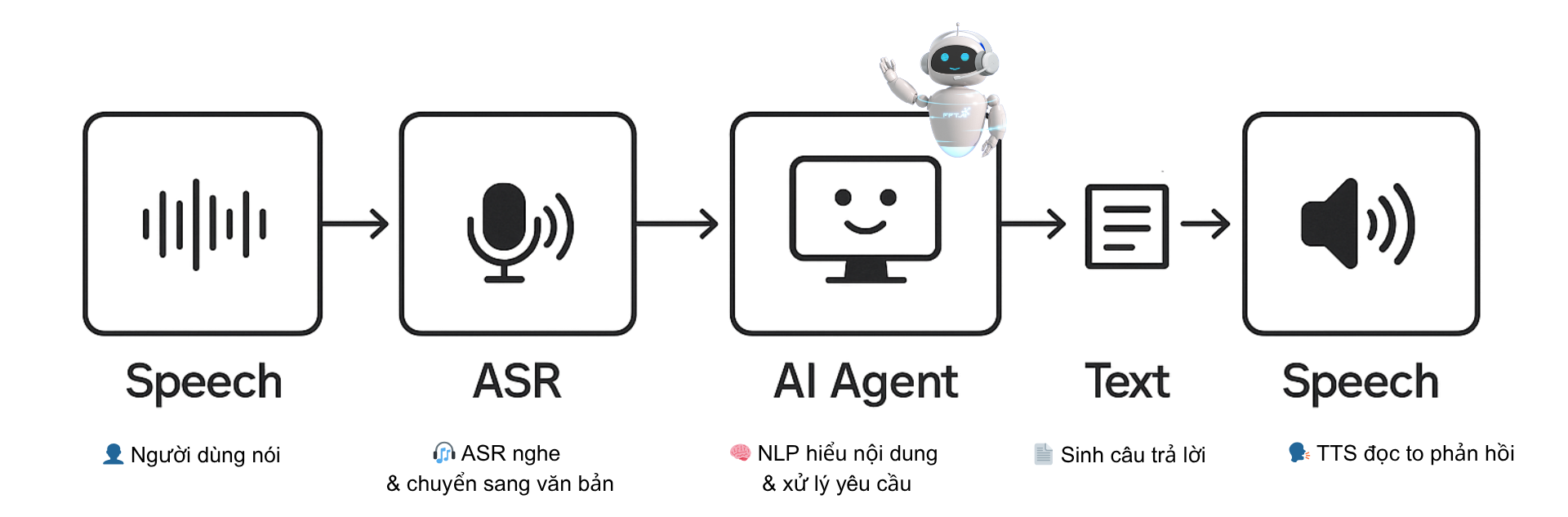
Câu trả lời sẽ được tổng hợp lại bằng hệ thống nói lại câu trả lời bằng giọng nói tự nhiên Text to Speech, để phát ra thành giọng nói. Các Voicebot hiện đại không chỉ trả lời các câu hỏi đơn giản mà còn có khả năng xử lý hội thoại đa lượt, cá nhân hóa phản hồi, ghi nhận trạng thái cảm xúc của người dùng – tất cả đều bắt đầu từ việc hiểu chính xác lời nói thông qua ASR. Đây là bước cuối cùng giúp khép lại vòng tròn hội thoại: người dùng nói → máy hiểu → máy trả lời bằng chính ngôn ngữ nói. Ngày nay, TTS không chỉ đơn thuần là giọng máy vô cảm. Nền tảng công nghệ Speech của FPT.AI cho phép tùy chỉnh giọng nói theo thương hiệu (voice branding), chọn giới tính, tốc độ, cảm xúc – giúp hệ thống voicebot mang màu sắc riêng, gần gũi và đáng tin cậy hơn trong mắt khách hàng.
FPT.AI khai thác sức mạnh của ASR như thế nào?
Tại Việt Nam, FPT.AI là đơn vị tiên phong trong việc phát triển và triển khai công nghệ ASR tiếng Việt một cách bài bản và hiệu quả, thông qua sản phẩm FPT.AI Speech to Text. Công nghệ này không chỉ hỗ trợ tốt giọng nói ba miền (Bắc – Trung – Nam), mà còn được tối ưu hóa cho từng ngành nghề, từ tài chính – ngân hàng, bảo hiểm, bán lẻ đến logistics và chăm sóc khách hàng. Đặc biệt, FPT.AI cung cấp cả hai dạng nhận diện: ghi âm sẵn (batch) và nhận dạng thời gian thực (streaming) – điều này rất quan trọng khi triển khai tổng đài thông minh hoặc Voicebot trong doanh nghiệp.
ASR là một phần không thể thiếu trong giải pháp AI Agent thế hệ mới của FPT Smart Cloud, nơi ASR kết hợp cùng NLP (FPT AI Engage) và TTS (FPT.AI Text to Speech) để tạo thành một vòng tròn hoàn chỉnh cho hội thoại giọng nói tự động. Trong các dự án thực tế, FPT.AI đã triển khai thành công voicebot chăm sóc khách hàng, tự động gọi nhắc thanh toán, xác minh danh tính bằng giọng nói và ghi nhận phản hồi khách hàng bằng ngôn ngữ tự nhiên.
Không chỉ là công nghệ lõi, ASR của FPT.AI còn mang lại giá trị kinh tế rõ rệt: giảm chi phí nhân sự, tăng tốc độ xử lý yêu cầu, nâng cao trải nghiệm khách hàng và cho phép doanh nghiệp hoạt động 24/7 mà không cần tăng tổng đài viên. Với định hướng phát triển công nghệ AI “thuần Việt nhưng tiêu chuẩn quốc tế”, FPT.AI đang đặt nền móng cho việc phổ biến hóa các giải pháp hội thoại bằng giọng nói trong mọi lĩnh vực tại Việt Nam.