Trong vài năm gần đây, các mô hình ngôn ngữ quy mô lớn (LLMs) đã chứng minh khả năng trả lời tự nhiên và gần với kỳ vọng của con người. Tuy nhiên, đi cùng chất lượng cao là chi phí vận hành rất lớn – từ hạ tầng tính toán đến tài nguyên xử lý. Vậy làm thế nào để doanh nghiệp có thể sử dụng mô hình AI vừa chất lượng lại vừa “hợp túi tiền”?
Đối với nhiều doanh nghiệp, đặc biệt là các hệ thống cần xử lý hàng nghìn hoặc hàng triệu yêu cầu mỗi ngày như chatbot chăm sóc khách hàng, việc triển khai các mô hình lớn đôi khi không phải lựa chọn tối ưu.
Một câu hỏi quan trọng được đặt ra: Liệu có thể tạo ra những mô hình AI nhỏ gọn hơn, chạy nhanh và tiết kiệm tài nguyên, nhưng vẫn giữ được chất lượng trả lời tốt như các mô hình lớn? Đó cũng chính là bài toán mà nhóm nghiên cứu tại Trung tâm GenAI, FPT Smart Cloud – Tập đoàn FPT tìm cách giải quyết.
Tải bài nghiên cứu tại: https://arxiv.org/abs/2601.11865

Khi mô hình nhỏ học từ mô hình lớn
Trong nghiên cứu “CTPD: Cross Tokenizer Preference Distillation”, kỹ sư AI Nguyễn Thị Ngân và các cộng sự đã đề xuất một phương pháp mới giúp mô hình nhỏ học được cách trả lời “hợp ý người dùng” từ mô hình lớn. Ý tưởng cốt lõi của nghiên cứu dựa trên một kỹ thuật phổ biến trong AI gọi là distillation (chưng cất). Hiểu đơn giản, thay vì huấn luyện một mô hình nhỏ hoàn toàn từ đầu, ta có thể để mô hình nhỏ học lại cách trả lời từ một mô hình lớn đã được huấn luyện tốt. Nhờ vậy, mô hình nhỏ có thể kế thừa nhiều năng lực của mô hình lớn nhưng với chi phí vận hành thấp hơn đáng kể.
Vấn đề “cắt chữ” khác nhau giữa các mô hình
Một rào cản lớn khi chuyển tri thức giữa các mô hình là tokenizer – công cụ chia câu thành các đơn vị nhỏ để mô hình xử lý. Mỗi mô hình AI có thể sử dụng một tokenizer khác nhau. Điều này dẫn đến tình huống: cùng một câu văn Nhưng mỗi mô hình lại chia thành các phần khác nhau.
Khi hai mô hình “cắt chữ” khác nhau như vậy, việc truyền các tín hiệu huấn luyện chi tiết từ mô hình lớn sang mô hình nhỏ trở nên khó khăn. Nhiều phương pháp distillation trước đây vì thế bị hạn chế khi áp dụng giữa các mô hình khác hệ.
Để giải quyết vấn đề này, nhóm nghiên cứu đề xuất framework CTPD (Cross Tokenizer Preference Distillation). Thay vì cố ép hai mô hình phải sử dụng cùng cách tách từ, CTPD chọn một cách tiếp cận khác: sử dụng vị trí ký tự trong câu gốc làm mốc căn chỉnh chung. Nói một cách đơn giản, phương pháp này không yêu cầu hai mô hình phải “cắt câu giống nhau”; thay vào đó, việc căn chỉnh được thực hiện dựa trên vị trí ký tự trong câu gốc. Nhờ vậy, mô hình nhỏ vẫn có thể học được các tín hiệu huấn luyện từ mô hình lớn một cách chính xác và ổn định, ngay cả khi hai mô hình có kiến trúc hoặc tokenizer khác nhau.
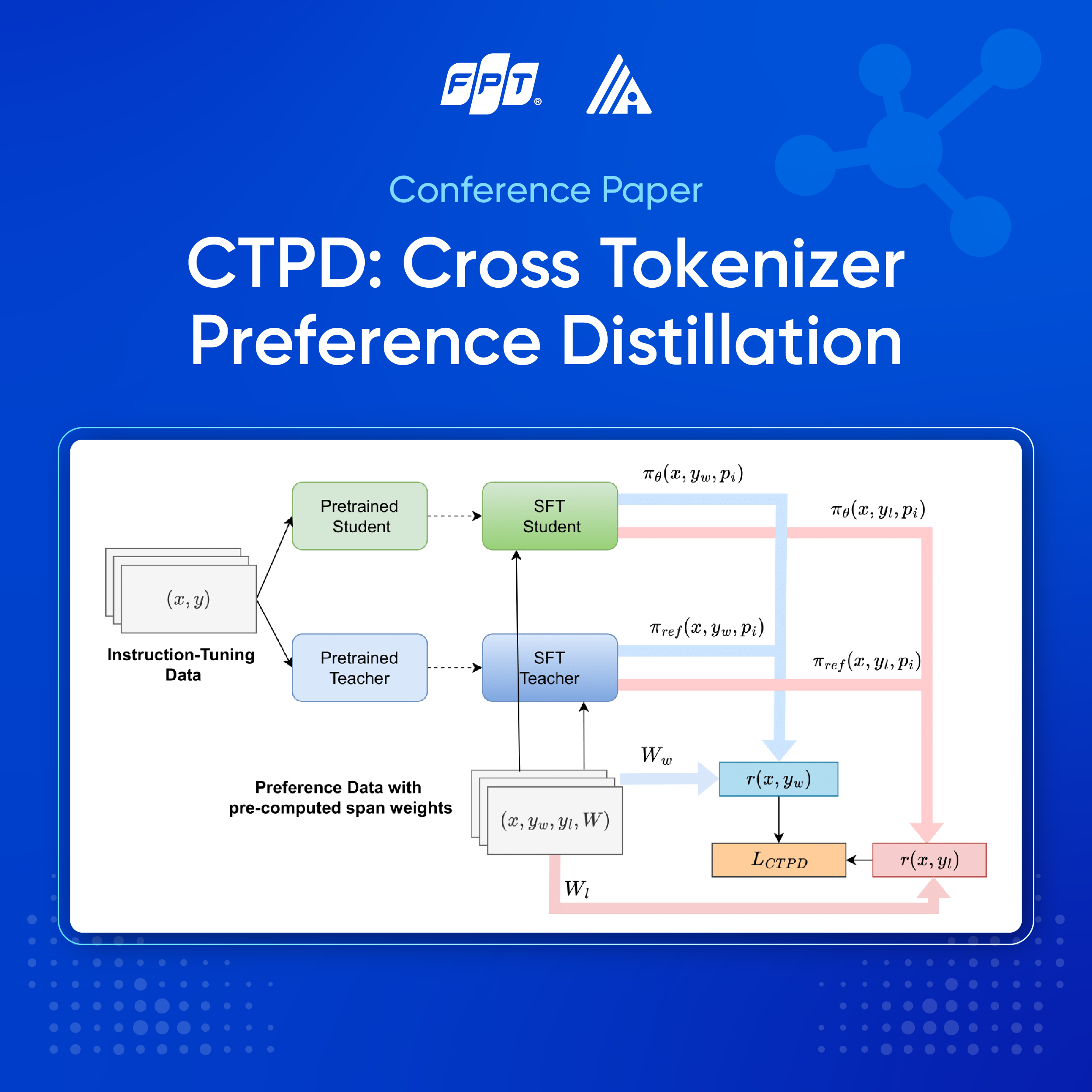
Giữ chất lượng trả lời nhưng tiết kiệm chi phí
Kết quả của phương pháp này là một hướng tiếp cận giúp tạo ra các mô hình “vừa nhỏ vừa tốt”:
💡 Giữ được khả năng trả lời theo đúng kỳ vọng của người dùng
⚡ Gọn nhẹ, chạy nhanh hơn
💰 Tiết kiệm tài nguyên và chi phí vận hành
Điều này đặc biệt quan trọng đối với các hệ thống AI cần hoạt động ở quy mô lớn trong môi trường doanh nghiệp.
Ứng dụng thực tế trong doanh nghiệp
Theo nhóm nghiên cứu, CTPD có thể được áp dụng cho nhiều lĩnh vực khác nhau miễn là có dạng dữ liệu gồm một câu hỏi, hai câu trả lời và thông tin về câu trả lời nào được đánh giá là tốt hơn. Từ những dữ liệu so sánh như vậy, mô hình có thể học cách đưa ra câu trả lời phù hợp hơn với các tiêu chí và đánh giá của con người.
Ví dụ trong chăm sóc khách hàng, doanh nghiệp có thể xây dựng nhiều tình huống thực tế như giao hàng trễ, đổi trả sản phẩm, hoàn tiền hoặc tra cứu đơn hàng. Từ đó, họ tạo ra các cặp câu trả lời theo dạng “tốt hơn – kém hơn”, được thiết kế dựa trên chính sách dịch vụ và giọng điệu thương hiệu, giúp mô hình học cách phản hồi phù hợp với tiêu chuẩn mà doanh nghiệp mong muốn. Mô hình gọn sau khi được huấn luyện có thể: trả lời lịch sự tuân thủ chính sách tránh đưa ra cam kết sai khi thiếu thông tin.
Để đánh giá hiệu quả của phương pháp, nhóm nghiên cứu đã thử nghiệm chuyển giao giữa hai họ mô hình phổ biến, từ Qwen sang Llama. Các mô hình sau khi huấn luyện được đánh giá trên nhiều bộ benchmark quen thuộc trong lĩnh vực AI như ARC, HellaSwag, Winogrande, MMLU, TruthfulQA và GSM8K. Kết quả cho thấy CTPD mang lại sự cải thiện ổn định so với các phương pháp nền tảng, đặc biệt trong những kịch bản mà hai mô hình sử dụng tokenizer khác nhau – một tình huống khá phổ biến khi doanh nghiệp thay đổi hoặc kết hợp nhiều hệ mô hình.
Từ áp lực deadline đến hội nghị AI hàng đầu
Nghiên cứu được thực hiện trong khoảng 3 tháng. Theo chia sẻ từ đại diện nhóm nghiên cứu, trước hạn nộp bài một tuần, kết quả thử nghiệm vẫn chưa đạt như kỳ vọng, khiến cả nhóm chịu áp lực lớn. Tuy nhiên chỉ ba ngày trước deadline, kết quả đã cải thiện rõ rệt và đủ tiêu chuẩn để nộp bài. Niềm vui càng lớn hơn khi nhóm nhận được thông báo rằng bài nghiên cứu không chỉ được chấp thuận mà còn được lựa chọn trình bày trực tiếp tại AI Alignment Track (AIA) của hội nghị AAAI-26 – một trong những hội nghị uy tín hàng đầu thế giới trong lĩnh vực trí tuệ nhân tạo.

Nhóm nghiên cứu cho biết mục tiêu lâu dài của hướng tiếp cận này là giúp cộng đồng tận dụng lại các mô hình mạnh sẵn có để tạo ra những mô hình nhỏ hơn, chi phí thấp hơn và dễ triển khai hơn trong thực tế. Trong tương lai, phương pháp này có thể được phát triển sâu hơn ở các lĩnh vực có tiêu chuẩn trả lời rõ ràng và yêu cầu độ an toàn cao như y tế hoặc giáo dục. Với cách tiếp cận đó, các mô hình AI gọn nhẹ nhưng thông minh có thể giúp rút ngắn khoảng cách giữa nghiên cứu AI và việc triển khai thực tế trong doanh nghiệp.