Trong lĩnh vực Trí tuệ Nhân tạo Tạo sinh (Generative AI), mỗi loại mô hình tạo sinh (Generative Models) đều mang đến cách tiếp cận độc đáo và ứng dụng riêng biệt. Từ GANs, VAEs, Transformer đến Diffusion Models và Autoregressive Models, mỗi mô hình không chỉ phản ánh tiến bộ công nghệ mà còn mở ra các giải pháp sáng tạo vượt bậc trong nhiều lĩnh vực. Bài viết này sẽ khám phá chi tiết các Generative Models nổi bật, cách hoạt động, cũng như ứng dụng tiềm năng của chúng trong thực tiễn. Tiếp theo, FPT.AI sẽ phổ biến 5 loại Generative Models nổi bật, hãy cùng theo dõi nội dung dưới đây.
Generative Adversarial Networks (GANs – Mạng Sinh Đối Kháng)
Generative Adversarial Networks là gì?
Được giới thiệu bởi Ian Goodfellow và các cộng sự vào năm 2014, Mạng Sinh Đối Kháng (Generative Adversarial Networks – GANs) là một trong những mô hình phổ biến nhất trong Generative AI. GANs bao gồm hai mạng nơ-ron đối kháng nhau: Mạng tạo (Generator) và Mạng phân biệt (Discriminator).
Generator cố gắng tạo ra dữ liệu giả, trong khi Discriminator học cách phân biệt giữa dữ liệu thật và giả. Quá trình đối kháng này diễn ra liên tục cho đến khi cả hai mạng đạt đến trạng thái cân bằng: dữ liệu do Generator tạo ra đủ giống với dữ liệu thật để “đánh lừa” được Discriminator.
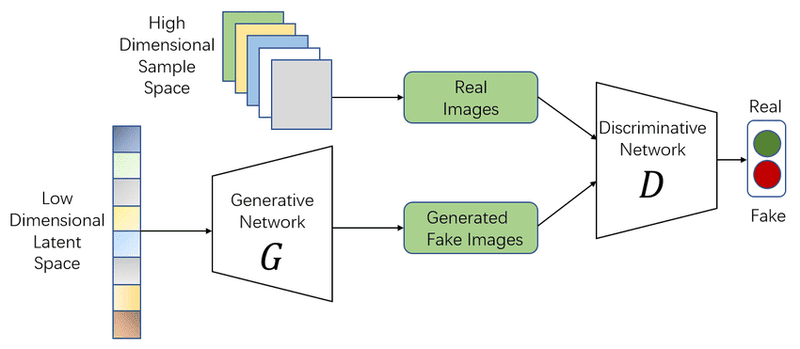
Chẳng hạn, để tạo hình ảnh khuôn mặt người, generator nhận một vector ngẫu nhiên làm đầu vào và tạo ra một hình ảnh khuôn mặt giả. Discriminator sau đó so sánh hình ảnh này với các hình ảnh khuôn mặt thật trong tập dữ liệu và xác định xem nó là thật hay giả. Dựa vào kết quả phân loại, generator được cải thiện để tạo ra hình ảnh khuôn mặt chân thực hơn, trong khi discriminator cũng học cách phân biệt chính xác hơn. Hai mô hình này liên tục cạnh tranh, giúp hệ thống tạo ra hình ảnh giống thật nhất.
Quá trình đào tạo mô hình GANs
Quá trình đào tạo mô hình Generative Adversarial Networks bao gồm các bước chính sau:
- Khởi tạo (Initialization): Generator và Discriminator được thiết lập với các trọng số ngẫu nhiên.
- Vòng lặp huấn luyện (Training Loop): Generator tạo dữ liệu giả, trong khi Discriminator xác định dữ liệu là thật hay giả dựa trên xác suất từ 0 đến 1.
- Lan truyền ngược (Backpropagation): Discriminator sử dụng tín hiệu lỗi để cập nhật trọng số, sau đó lỗi này cũng được truyền ngược để điều chỉnh trọng số của Generator.
- Tạo mẫu (Sampling): Sau khi huấn luyện, Generator có thể tạo dữ liệu mới dựa trên phân phối mà nó đã học.
Generative Adversarial Networks có thể học từ các phân phối dữ liệu phức tạp, đa phương thức để tạo ra các mẫu đa dạng và chất lượng cao. Tuy nhiên, việc đào tạo GAN có thể gặp khó khăn, chẳng hạn như Generator chỉ tạo ra các mẫu lặp lại. StyleGAN là biến thể của GANS được NVIDIA phát triển để giải quyết các vấn đề này.
Mô hình học sâu (Deep learning) này có khả năng tạo ra các hình ảnh chân dung con người với độ chân thực cao. Năm 2019, một kỹ sư của Uber đã sử dụng StyleGAN để tạo các khuôn mặt mới cho trang web “This Person Does Not Exist”. Wang đã bày tỏ sự kinh ngạc vì khả năng phân tích tất cả các đặc điểm có liên quan trên khuôn mặt của con người để tạo các ảnh chân dung giống như thật mỗi khi tải lại trang của Generative Models này.
Ứng dụng tiềm năng của Generative Adversarial Networks là gì?
Generative Adversarial Networks đã trở thành công cụ quan trọng trong nhiều lĩnh vực nhờ khả năng tạo ra dữ liệu chất lượng cao và học các phân phối phức tạp. Các ứng dụng của GANs mang lại giá trị vượt trội trong sáng tạo, tự động hóa và nghiên cứu, cụ thể như sau:
- Tạo hình ảnh và video: Phát triển hình ảnh chân thực, video và deepfake.
- Chuyển đổi phong cách hình ảnh: Biến ảnh ban ngày thành ban đêm, hoặc phong cách hoạt hình hóa.
- Tăng cường và tổng hợp dữ liệu: Cải thiện hiệu suất cho các mô hình học có giám sát.
- Chú thích và tổng hợp hình ảnh: Tạo hình ảnh từ văn bản hoặc thêm chú thích tự động.
- Thiết kế 3D: Phát triển các mô hình 3D mới.
- Chuyển đổi giọng nói và âm thanh: Biến đổi giọng nói hoặc tổng hợp âm thanh.
- Phát triển trò chơi: Sáng tạo nhân vật và nội dung game.
- Sáng tạo nghệ thuật: Hỗ trợ sáng tác nhạc, văn học, và nghệ thuật thị giác.
- Bảo mật và quyền riêng tư: Tạo dữ liệu giả để bảo vệ thông tin nhạy cảm và phát hiện deepfake.
- Mô phỏng khoa học: Dự đoán và mô phỏng trong nghiên cứu khoa học.
Hiệu quả ứng dụng GANs phụ thuộc vào chất lượng dữ liệu đầu vào, cấu trúc mô hình, mức độ phức tạp của phân phối, kiến trúc mô hình và các tham số huấn luyện.
Variational Autoencoder (VAEs)
Variational Autoencoder là gì?
So với Generative Adversarial Networks, Variational Autoencoder (VAEs) là một mô hình tạo sinh dễ kiểm soát đầu ra hơn. Là một dạng mở rộng của Autoencoder, VAEs không chỉ có khả năng tái tạo dữ liệu mà còn có thể biểu diễn dữ liệu trong không gian tiềm ẩn dưới dạng phân phối xác suất. Ý tưởng cốt lõi của Variational Autoencoders là mã hóa đầu vào thành một phân phối Gaussian, với các tham số trung bình (Mean) và phương sai (Variance).
Variational Autoencoders hoạt động dựa trên hai mạng chính: Encoder và Decoder. Encoder đảm nhận vai trò mã hóa dữ liệu đầu vào thành tham số của phân phối xác suất trong không gian tiềm ẩn. Decoder sử dụng các mẫu từ phân phối này để tái tạo lại dữ liệu đầu vào.
Mục tiêu chính của Variational Autoencoders là giảm lỗi tái tạo (Reconstruction Loss) và đảm bảo rằng các biểu diễn trong không gian tiềm ẩn liên tục và đầy đủ. Điều này mang lại lợi thế lớn khi ứng dụng vào các bài toán sinh dữ liệu và giảm chiều dữ liệu.
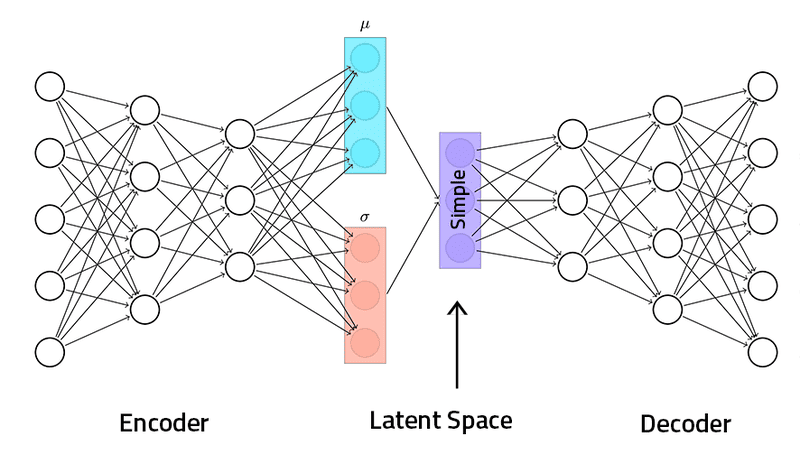
Quá trình đào tạo Variational Autoencoders
Quá trình huấn luyện VAE có thể được mô tả qua các bước sau:
- Mã hóa (Encoding): Dữ liệu đầu vào được đưa vào bộ mã hóa, nơi dữ liệu được nén vào một không gian latent được giả định tuân theo phân phối Gaussian, bao gồm trung bình (μ) và độ lệch chuẩn (σ). Encoder được xây dựng bằng mạng nơ-ron sâu, học cách nén dữ liệu đầu vào thành các biểu diễn tiềm ẩn. VAEs biểu diễn dữ liệu thành một vùng không gian xác suất (tập hợp các phân phối cho mỗi mẫu đầu vào
- Lấy mẫu (Sampling): Thay vì trực tiếp lấy mẫu từ phân phối xác suất, VAEs áp dụng một kỹ thuật đặc biệt gọi là Reparameterization Trick để giữ tính khả vi trong quá trình lan truyền ngược. Bằng cách biểu diễn z = μ + σ * ε, trong đó ε là nhiễu được lấy mẫu từ Gaussian chuẩn, mô hình đảm bảo rằng gradient có thể được lan truyền ngược một cách chính xác.
- Giải mã (Decoding): Decoder sử dụng điểm được lấy mẫu trong không gian tiềm ẩn (z) để tái tạo lại dữ liệu mới. Mục tiêu của giải mã là tái tạo dữ liệu đầu vào từ biểu diễn trong không gian latent.
- Tính toán hàm loss: Hàm loss của Variational Autoencoders bao gồm:
- Reconstruction loss: Đo lường mức độ mà decoder tái tạo chính xác dữ liệu đầu vào để đánh giá độ giống giữa dữ liệu đầu vào và đầu ra.
- KL-divergence loss: Đo lường sự khác biệt giữa phân phối Gaussian đã học và phân phối thực tế trong không gian latent để đảm bảo phân phối trong không gian tiềm ẩn gần với Gaussian chuẩn.
- Lan truyền ngược (Backpropagation): Dựa vào tín hiệu lỗi từ hàm loss, các trọng số của bộ mã hóa và bộ giải mã được cập nhật thông qua lan truyền ngược.
Sau khi được huấn luyện, Variational Autoencoders có thể mẫu lấy mẫu từ phân phối Gaussian để tạo dữ liệu mới, có cấu trúc chặt chẽ với , nén thông tin thành các biểu diễn có chiều thấp trong không gian latent hoặc Trích xuất đặc trưng quan trọng từ dữ liệu đầu vào. Tuy nhiên, do bản chất xác suất của mô hình, VAE có thể tạo ra các mẫu mờ, chất lượng thấp hoặc bị nhiễu.
Để cải thiện chất lượng, các phương pháp như đào tạo đối nghịch (adversarial training) và flow-based models đã được đề xuất nhằm tăng hiệu suất của VAE trong việc tạo dữ liệu rõ nét hơn.
Một số ứng dụng nổi bật của VAE
- Xử lý và tạo hình ảnh: Tái tạo hoặc sáng tạo hình ảnh mới với các đặc điểm đặc trưng từ dữ liệu gốc.
- Dự đoán và tạo video: Hỗ trợ dự đoán các khung hình tiếp theo hoặc tạo video mới từ dữ liệu huấn luyện.
- Nén và khử nhiễu dữ liệu: Giảm kích thước dữ liệu và loại bỏ nhiễu để cải thiện chất lượng.
- Phát hiện bất thường: Tìm và loại bỏ các giá trị ngoại lệ trong tập dữ liệu.
- Hệ thống khuyến nghị và cá nhân hóa: Nâng cao trải nghiệm khách hàng trong thời đại số thông qua việc học và đề xuất nội dung phù hợp.
- Trích xuất đặc trưng: Tự động rút trích các đặc điểm chính của dữ liệu để sử dụng trong các mô hình khác.
- Tạo mô hình và môi trường 3D: Hỗ trợ phát triển các mô hình và môi trường 3D thực tế hơn.
- Xử lý ngôn ngữ tự nhiên: Tạo văn bản, dịch máy, hoặc mô phỏng ngôn ngữ.
- Phân tích dữ liệu y sinh và nghiên cứu thuốc: Tạo dữ liệu mô phỏng hoặc dự đoán trong lĩnh vực y sinh.
- Mô phỏng và dự đoán khoa học: Hỗ trợ các nghiên cứu và dự đoán trong vật lý và các lĩnh vực khoa học khác.
Mô Hình Transformer
Các kiến trúc dựa trên Transformer Models, đặc biệt là những mô hình ngôn ngữ lớn như GPT (Generative Pretrained Transformer), đã trở thành trung tâm của sự phát triển trong Generative AI. Khác với GANs và VAEs, các mô hình Transformer sử dụng cơ chế tự chú ý (self-attention) để xử lý dữ liệu tuần tự.
Khi nhận chuỗi đầu vào, cơ chế này cho phép mô hình phân bổ trọng số cho từng phần của chuỗi, xác định mối quan hệ giữa chúng và tạo ra đầu ra tương ứng với đầu vào đó. Transformer Models đặc biệt hiệu quả trong việc tạo ra văn bản và các tác vụ xử lý ngôn ngữ tự nhiên (NLP) như dịch ngôn ngữ (Machine Translation), tạo văn bản và trả lời câu hỏi.
Chẳng hạn, các mô hình Transformer như GPT-3, GPT-4 và T5 được huấn luyện trên một kho dữ liệu văn bản khổng lồ, có khả năng tạo ra văn bản mạch lạc, hợp lý, liên quan đến ngữ cảnh, trả lời câu hỏi, viết bài luận, thậm chí là sáng tác thơ.
Diffusion Models (Mô Hình Khuếch Tán)
Trong lĩnh vực tạo hình ảnh, các Diffusion Models (mô hình khuếch tán) đã nổi lên như một sự thay thế mạnh mẽ cho Generative Adversarial Networks nhờ khả năng nắm bắt mối quan hệ phức tạp giữa các pixel trong hình ảnh thông qua việc thêm và loại bỏ nhiễu.
Quá trình khuếch tán bắt đầu bằng việc liên tục thêm nhiễu vào dữ liệu cơ sở qua nhiều vòng lặp, tăng dần mức độ nhiễu ở mỗi lần. Sau đó, Diffusion Models học cách khử nhiễu bằng cách áp dụng quy trình loại bỏ nhiễu từng bước, từ đó tái tạo lại dữ liệu gốc.
Diffusion Models có thể áp dụng quy trình khử nhiễu đã học để tạo ra dữ liệu mới từ các đầu vào khác. Qua thời gian, mô hình ngày càng hiểu rõ hơn về các mẫu và cấu trúc dữ liệu, đồng thời tối ưu hóa khả năng loại bỏ nhiễu, cho phép tạo ra kết quả chính xác hơn.
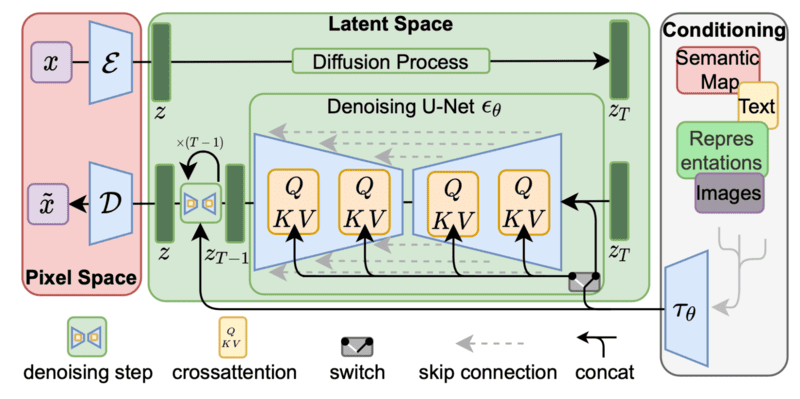
Có thể dễ dàng huấn luyện Diffusion Models với hàm contrastive loss để làm cho chúng ít phức tạp hơn so với các mô hình tạo sinh khác như GAN và VAE. Mô hình này cũng có thể được áp dụng cho nhiều tác vụ tạo sinh khác nhau, bao gồm tổng hợp hình ảnh, dự đoán video, và tạo văn bản.
DALL-E, một mạng thần kinh do OpenAI phát triển, dựa trên diffusion models để nhân bản từng pixel và tạo hình ảnh chi tiết và phức tạp từ các mô tả văn bản. Người dùng chỉ cần nhập mô tả văn bản mong muốn, và DALL-E sẽ tạo ra hình ảnh tương ứng một cách chính xác.
Autoregressive Models
Autoregressive Models tạo dữ liệu dạng chuỗi bằng cách dự đoán từng phần tử trong chuỗi dựa trên các phần tử trước đó thông qua mô hình xác suất có điều kiện. Những mô hình này thường được ứng dụng trong xử lý ngôn ngữ tự nhiên (NLP), như tạo văn bản hoặc dịch thuật.
Nói một cách dễ hiểu, Autoregressive Models dự đoán giá trị tiếp theo trong chuỗi bằng cách phân tích các giá trị trước đó. Ví dụ, trong một chuỗi giá cổ phiếu, mô hình có thể dự đoán giá ngày kế tiếp dựa trên dữ liệu từ các ngày trước đó.
Các mô hình ngôn ngữ lớn (LLM) hiện nay cũng sử dụng kiến trúc Autoregressive để tạo ra phản hồi tự nhiên, giống như con người. Được huấn luyện trên lượng lớn dữ liệu văn bản như bài báo, sách, và nội dung từ các trang web, những mô hình này có khả năng tạo văn bản mới mang phong cách và nội dung tương đồng với dữ liệu gốc.
LLM đã đạt được sự chú ý lớn trong những năm gần đây, với các mô hình nổi bật như GPT (Generative Pre-trained Transformer) của OpenAI và BERT của Google. Những mô hình này đạt hiệu suất vượt trội trong nhiều tác vụ ngôn ngữ như mô hình hóa ngôn ngữ, dịch máy, trả lời câu hỏi và tóm tắt văn bản. Đặc biệt, khả năng tạo văn bản chất lượng cao của LLM đã mở ra nhiều ứng dụng sáng tạo, từ xây dựng AI chatbot, viết thơ, đến tạo bài viết cho mạng xã hội hoặc báo chí.
Tóm lại, những Generative Models như GANs, VAEs, Transformers, Diffusion Models và Autoregressive Models đang định hình lại cách chúng ta sáng tạo và xử lý dữ liệu. Mỗi mô hình mang đến những cách tiếp cận và ứng dụng đặc thù, từ sáng tạo nội dung, xử lý ngôn ngữ tự nhiên, đến phát triển hình ảnh và mô phỏng khoa học. Với tiềm năng vượt trội, Generative AI không chỉ hỗ trợ tự động hóa mà còn thúc đẩy sự đổi mới trong nhiều ngành nghề, trở thành công cụ quan trọng giúp doanh nghiệp và các tổ chức vượt qua giới hạn sáng tạo và hiệu suất.
>>> XEM THÊM: