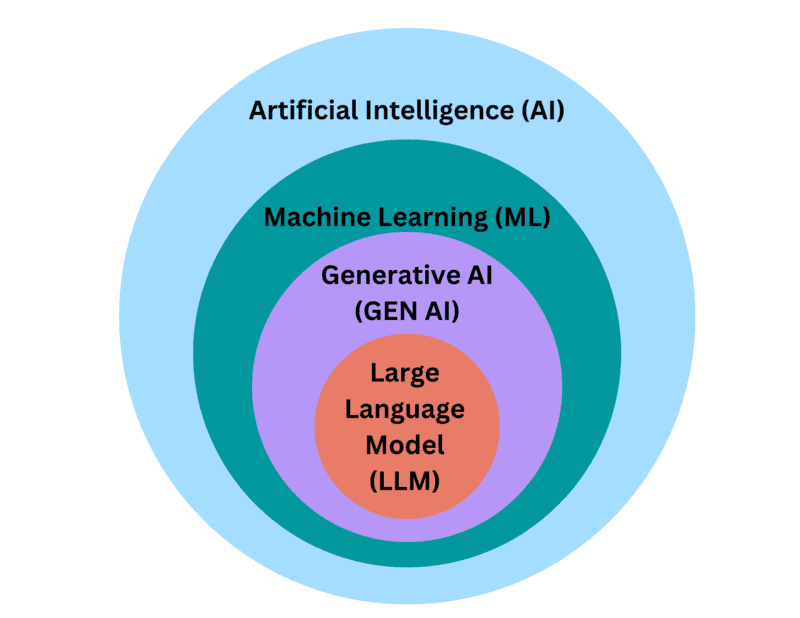
Theo thông tin từ Bloomberg, OpenAI và Microsoft đang đặt ra câu hỏi liệu DeepSeek có sử dụng API của OpenAI để tích hợp các mô hình AI của OpenAI vào các mô hình của DeepSeek hay không? Và liệu DeepSeek có sử dụng phương pháp Distillation để huấn luyện mô hình AI với API của OpenAI hay không?
Câu trả lời vẫn còn bỏ ngỏ, tuy nhiên việc kỹ thuật distillation giúp các nhà phát triển tối ưu trong quá trình huấn luyện các mô hình AI là không thể bàn cãi. Trong bối cảnh đó, FPT.AI phối hợp cùng Viện Khoa học và Công nghệ Tiên tiến Nhật Bản (JAIST) đã tổ chức buổi hội thảo với chủ đề “Tìm hiểu kỹ thuật Distillation trong DeepSeek”, nằm trong khuôn khổ chuỗi hội thảo “Giải mã mô hình AI của DeepSeek” vào ngày 13/2/2025 vừa qua. Bài viết dưới đây tóm tắt các nội dung đã được thảo luận về kỹ thuật distillation nói chung và ứng dụng của kỹ thuật này trong huấn luyện mô hình của DeepSeek nói riêng, được trình bày bởi ông Lưu T. Sơn – Nghiên cứu sinh Tiến sĩ tại Viện Khoa học và Công nghệ Tiên tiến Nhật Bản (JAIST) và ông Nguyễn T. Minh – Master student tại Viện Khoa học và Công nghệ Tiên tiến Nhật Bản (JAIST).
Về Knowledge distillation (KD)
Được giới thiệu bởi Geoffrey Hinton vào năm 2015 [1], Knowledge distillation (tạm dịch: chắt lọc tri thức) là một trong những phương pháp thuộc họ transfer learning. Thuật toán này lấy ý tưởng từ quá trình học tập ở con người khi mà kiến thức được truyền đạt từ giáo viên tới học sinh. Trong kỹ thuật knowledge distillation thì một model lớn hơn sẽ đóng vai trò là teacher (giáo viên) nhằm chuyển giao kiến thức sang model nhỏ hơn đóng vai trò là student (học sinh).
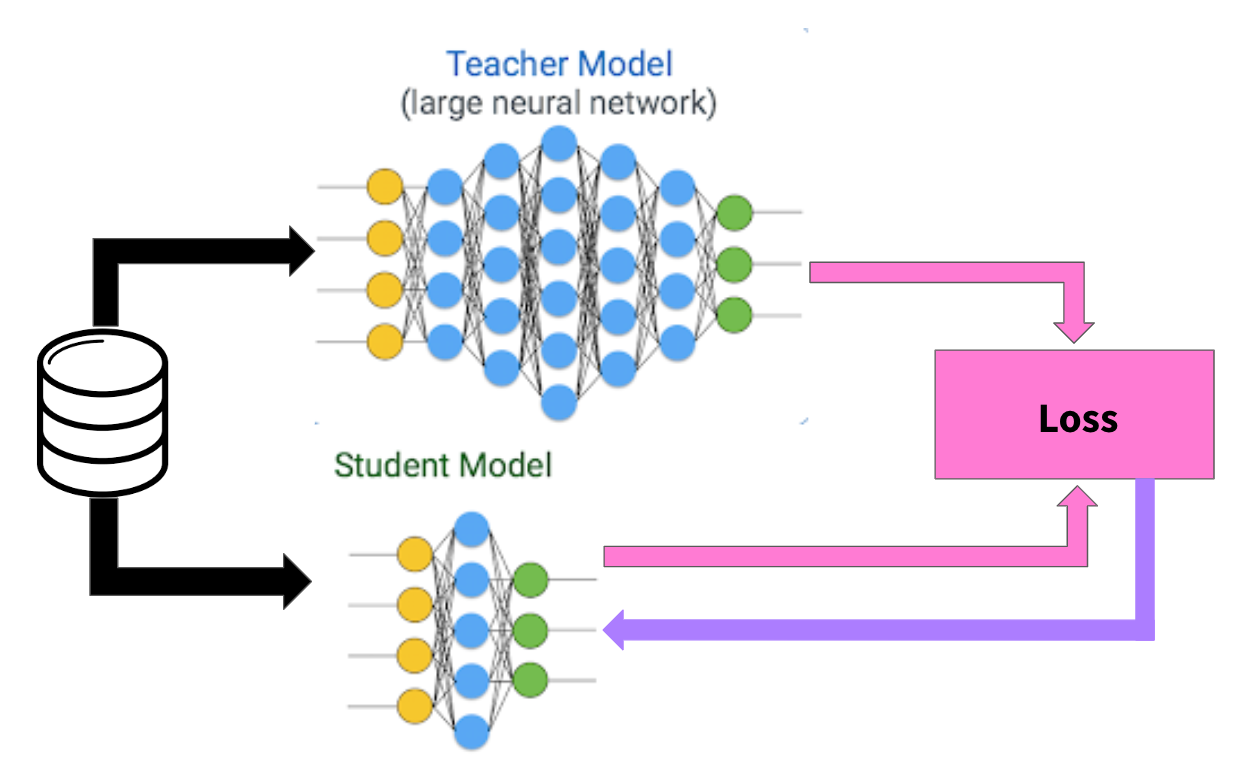
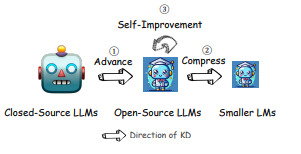
Trong Mô hình ngôn ngữ lớn (LLM), KD đóng ba vai trò chính bao gồm [2]:
- Nâng cao khả năng (đây là vai trò lớn nhất của KD).
- Cung cấp nén truyền thống để tối ưu hóa hiệu quả.
- Tự cải tiến thông qua kiến thức tự tạo ra.
Thông qua các thuật toán, các student model có thể lĩnh hội được những kiến thức tinh tuý nhất của các teacher model. Từ đó tạo ra những mô hình học sinh có khả năng tính toán và giải quyết vấn đề hiệu quả với chi phí và thời gian đào tạo tối ưu hơn.
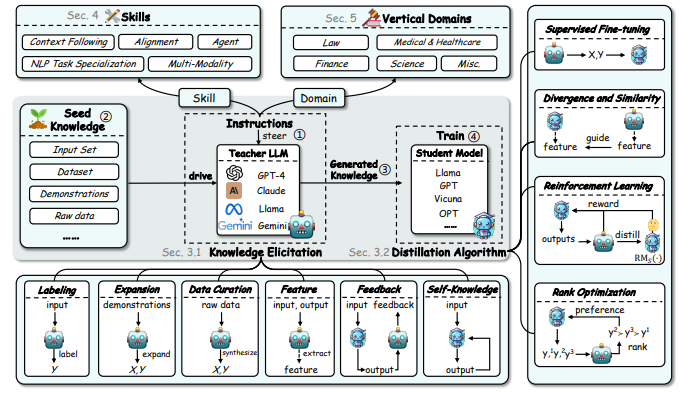
- Mô hình giáo viên được tinh chỉnh theo hướng dẫn.
- Cung cấp dữ liệu hạt giống (seed knowledge) cho mô hình giáo viên.
- Mô hình giáo viên (teacher model) tạo ra tri thức mới, tinh tuý nhất.
- Mô hình học sinh (student model) được đào tạo từ những tri thức thu thập được.
Những thuật toán phổ biến được dùng trong công đoạn này bao gồm:
- Fine-tuning có giám sát (Supervised Fine-tuning): Đào tạo mô hình với dữ liệu có nhãn (X, Y). Điều chỉnh các dự đoán của student model sao cho phù hợp với những dự đoán của teacher model.
- Tối thiểu hoá sự khác biệt (Divergence and Similarity): Giúp đảm bảo đặc trưng học được của mô hình học sinh khớp với mô hình giáo viên.
- Học tăng cường (Reinforcement Learning): Sử dụng mô hình đánh giá phần thưởng (Reward Model – RM) để điều chỉnh mô hình học sinh.
- Tối ưu hóa thứ hạng (Rank Optimization): Xếp hạng các đầu ra dựa trên mức độ ưu tiên và độ chính xác.
Kỹ thuật distillation hoạt động như thế nào?
Quá trình distillation sẽ bao gồm các bước [1]:
- Huấn luyện mô hình teacher: Teacher được huấn luyện trên một tập dữ liệu đã được dán nhãn. Bộ dữ liệu này thường có kích thước vừa đủ để teacher network học được tổng quát các trường hợp. Sau khi teacher đạt đến độ chính xác mong muốn, thì sẽ được sử dụng để huấn luyện student.
- Huấn luyện mô hình student: Quá trình này sẽ sử dụng gợi ý từ teacher để cải thiện student. Nếu huấn luyện theo phương pháp thông thường thì student sẽ áp dụng hàm loss function dạng cross-entropy
Các mạng nơ-ron thường tạo ra xác suất phân lớp bằng cách sử dụng một lớp đầu ra ‘softmax’ để chuyển đổi giá trị logit.

T thường được xét giá trị bằng 1
Giá trị T cao hơn tạo ra một phân phối xác suất mượt hơn trên các classes
(*) T là một tham số thường được sử dụng trong các phân phối xác suất, đặc biệt là trong hàm softmax, để kiểm soát độ sắc nét hoặc độ mượt của phân phối đầu ra
Kiến thức được chuyển giao cho distilled model bằng cách huấn luyện nó trên một bộ dữ liệu chuyển giao và sử dụng phân phối mục tiêu mềm cho mỗi trường hợp trong bộ dữ liệu chuyển giao, được tạo ra bằng cách sử dụng mô hình lớn với nhiệt độ cao trong softmax.
Sau khi được huấn luyện, mô hình đã chưng cất sử dụng T=1.
Loss function (hàm mất mát) trong distillation
Hàm loss 1: tính toán sự chênh lệch giữa đầu ra của distilled model y(x|t) và teacher model dưới dạng mục tiêu mềm yhat(x|t) sử dụng hàm cross-entropy
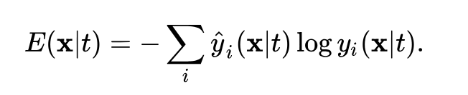
Hàm loss 2: tính toán sự chênh lệch giữa distilled model y(x|t) và known label ytrue(x|t)
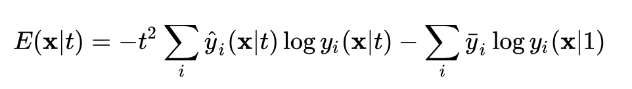
Triển khai kỹ thuật distillation với DeepSeek R1
Đội ngũ của DeepSeek đã áp dụng kỹ thuật distillation để tạo ra một bộ mô hình rút gọn từ R1, sử dụng các kiến trúc Qwen và Llama [3].
+ Teacher models: DeepSeek-R1 (671B tham số)
+ Student models: Qwen (Qwen, 2024b) and Llama (AI@Meta, 2024).
+ Tập dữ liệu chuyển giao (transfer set): 800K mẫu (bao gồm: 600K dữ liệu suy luận, 200K các dữ liệu khác không liên quan đến suy luận)
+ Distilled model: thực hiện Huấn luyện có giám sát (SFT) không bao gồm bước Học tăng cường (RL stage).
Kết quả sau khi ứng dụng kỹ thuật Distillation với bốn tập dữ liệu, được chia thành hai nhóm:
- Nhóm 1: Giải toán: AIME 2024, MATH-500, GPQA.
- Nhóm 2: Lập trình: LiveCodeBench, CodeForces
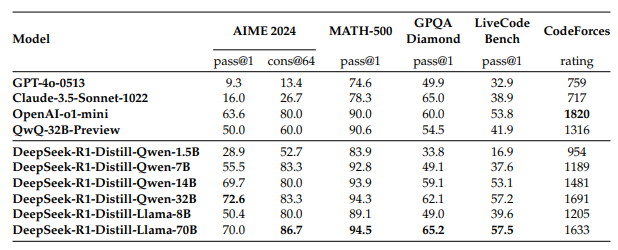
Theo công bố từ DeepSeek [3], các student model được huấn luyện dựa trên teacher model là DeepSeek R1 đều đưa ra những kết quả tương đối ấn tượng. Cụ thể:
DeepSeek-R1-Distill-Qwen-1.5B
Đây là mô hình rút gọn nhỏ nhất, đạt 83.9% trên MATH-500 – một bài kiểm tra đánh giá khả năng giải toán cấp trung học với tư duy logic và nhiều bước giải. Kết quả này cho thấy mô hình có thể xử lý tốt các bài toán cơ bản dù có kích thước nhỏ gọn.
Tuy nhiên, hiệu suất của nó giảm đáng kể trên LiveCodeBench (16.9%), một bài kiểm tra đánh giá khả năng lập trình, cho thấy năng lực hạn chế trong các tác vụ liên quan đến mã hóa.
DeepSeek-R1-Distill-Qwen-7B
Qwen-7B đạt 92.8% trên MATH-500, chứng tỏ khả năng tư duy toán học mạnh mẽ. Hiệu suất trên GPQA Diamond (49.1%) – bài kiểm tra trả lời câu hỏi thực tế cho thấy mô hình có sự cân bằng tốt giữa tư duy toán học và hiểu biết thực tế.
Tuy nhiên, hiệu suất trên LiveCodeBench (37.6%) và CodeForces (xếp hạng 1189) cho thấy mô hình chưa thực sự phù hợp với các nhiệm vụ lập trình phức tạp.
DeepSeek-R1-Distill-Qwen-14B
Mô hình này có kết quả tốt trên MATH-500 (93.9%), cho thấy khả năng xử lý các bài toán phức tạp. Đạt 59.1% trên GPQA Diamond, phản ánh năng lực suy luận thực tế.
Kết quả trên LiveCodeBench (53.1%) và CodeForces (xếp hạng 1481) cho thấy vẫn cần cải thiện trong các nhiệm vụ lập trình.
DeepSeek-R1-Distill-Qwen-32B
Mô hình lớn nhất dựa trên Qwen đạt điểm cao nhất trên AIME 2024 (72.6%), bài kiểm tra đánh giá khả năng suy luận toán học nhiều bước nâng cao. Hiệu suất xuất sắc trên MATH-500 (94.3%) và GPQA Diamond (62.1%), thể hiện sức mạnh cả về tư duy toán học lẫn suy luận thực tế.
Kết quả trên LiveCodeBench (57.2%) và CodeForces (xếp hạng 1691) cho thấy mô hình khá linh hoạt nhưng vẫn chưa được tối ưu hóa hoàn toàn cho lập trình so với các mô hình chuyên biệt về mã hóa.
DeepSeek-R1-Distill-Llama-8B
Llama-8B đạt 89.1% trên MATH-500, cho thấy khả năng xử lý tốt các bài toán toán học. Đạt 49.0% trên GPQA Diamond, phản ánh năng lực suy luận thực tế.
Tuy nhiên, điểm số thấp hơn trên LiveCodeBench (39.6%) và CodeForces (xếp hạng 1205) cho thấy mô hình có hạn chế trong các tác vụ lập trình so với các mô hình dựa trên Qwen.
DeepSeek-R1-Distill-Llama-70B
Đây là mô hình rút gọn lớn nhất, đạt hiệu suất hàng đầu trên MATH-500 (94.5%), cao nhất trong tất cả các mô hình rút gọn. Đạt 86.7% trên AIME 2024, giúp nó trở thành lựa chọn xuất sắc cho tư duy toán học nâng cao.
Hiệu suất trên LiveCodeBench (57.5%) và CodeForces (xếp hạng 1633) cho thấy nó có khả năng lập trình tốt hơn hầu hết các mô hình khác. Trong lĩnh vực này, mô hình tương đương với OpenAI o1-mini hoặc GPT-4o.
Những lợi ích khi ứng dụng kỹ thuật distillation trong kỷ nguyên của các mô hình Ngôn ngữ lớn (LLMs)
Thông qua kỹ thuật distillation, khoảng cách về hiệu suất giữa các mô hình độc quyền và mã nguồn mở được thu hẹp đáng kể. Quá trình này không chỉ tối ưu hóa các yêu cầu tính toán mà còn nâng cao tính bền vững môi trường của các hoạt động AI, khi các mô hình mã nguồn mở trở nên hiệu quả hơn với chi phí tính toán thấp hơn. Hơn nữa, distillation thúc đẩy một bối cảnh AI dễ tiếp cận và công bằng hơn, nơi các tổ chức nhỏ và các nhà nghiên cứu cá nhân có thể tiếp cận các mô hình AI tiên tiến, từ đó thúc đẩy sự đổi mới và tăng trưởng trong nhiều ngành công nghiệp và lĩnh vực nghiên cứu
Tài liệu tham khảo
[1] Hinton, Geoffrey. “Distilling the Knowledge in a Neural Network.” arXiv preprint arXiv:1503.02531 (2015). https://arxiv.org/abs/1503.02531
[2] Xu, Xiaohan, et al. “A survey on knowledge distillation of large language models.” arXiv preprint arXiv:2402.13116 (2024). https://arxiv.org/pdf/2402.13116
[3] Guo, Daya, et al. “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.” arXiv preprint arXiv:2501.12948 (2025). https://arxiv.org/abs/2501.12948