Trợ lý AI của DeepSeek với khả năng vượt trội so với các mô hình hàng đầu hiện nay đã khiến Silicon Valley dậy sóng, đặc biệt là khi DeepSeek quảng bá rằng mô hình của họ được phát triển với chi phí chỉ bằng một phần nhỏ so với các đối thủ. Chi phí DeekSeek AI công bố cho việc huấn luyện mô hình DeepSeek-V3 là chỉ 5.576 triệu đô la Mỹ. Mặc dù đây là chi phí cho một lần huấn luyện mô hình, chưa tính các chi phí nghiên cứu, thử nghiệm, hay chuẩn bị dữ liệu nhưng vẫn là một con số rất ấn tượng.
Tổng thống Hoa Kỳ Donald Trump cho rằng cuộc đổ bộ của DeepSeek nên là “hồi chuông cảnh tỉnh” (a wake-up call) với các công ty công nghệ Mỹ. Cùng FPT.AI giải mã mô hình AI khiến Thung Lũng Silicon phải khiếp sợ trong bài viết sau.
DeepSeek là gì?
DeepSeek, một start-up về Trí tuệ nhân tạo được thành lập vào năm 2023 có trụ sở tại Hàng Châu, Trung Quốc, gần đây đã khiến ngành công nghệ phải xôn xao sau khi ra mắt một loạt các mô hình ngôn ngữ lớn (LLM). Những mô hình LLM này sở hữu khả năng tương đương với những mô hình độc quyền (như ChatGPT, Claude,..) và vượt trội so với các mô hình opensource hiện có.
DeepSeek đã ra mắt mô hình ngôn ngữ lớn gây chú ý nhất của mình, R1, vào ngày 20/1. Trợ lý AI này đã leo lên vị trí số 1 trên Apple App Store và đẩy ChatGPT của OpenAI, vốn luôn chiếm vị trí dẫn đầu, xuống vị trí số 2.
Gần đây nhất vào ngày 27/1/2025, DeepSeek lại ra mắt một mô hình AI hiệu suất cao khác, Janus-Pro-7B, có khả năng xử lý đa phương thức (multimodal), tức là có thể xử lý nhiều loại dữ liệu khác nhau như văn bản, hình ảnh.
>>> XEM THÊM: ChatGPT là gì? Cách tạo tài khoản Chat GPT free
Sự khác biệt giữa LLM của Trung Quốc và Mỹ
Trước khi bước vào so sánh về mặt công nghệ, các số liệu từ World Economic Forum cho thấy sự chênh lệnh về mức độ đầu tư cho AI của hai cường quốc này là rất lớn trong giai đoạn 2021 – 2023.
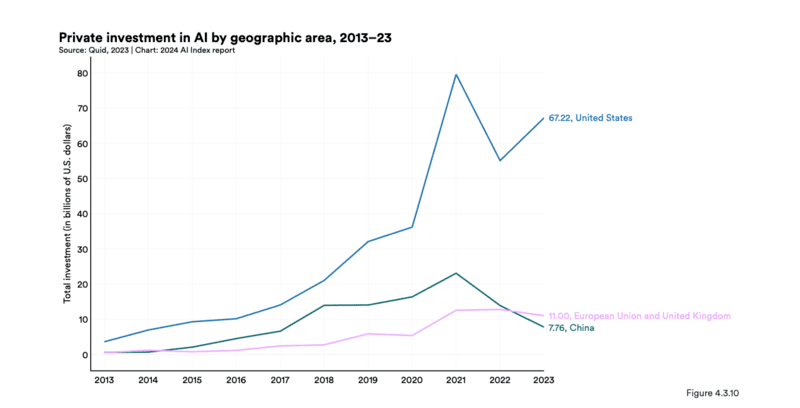
Mức độ đầu tư được xem là một trong những yếu tố then chốt tạo nên những sự khác biệt.
Khác biệt về phần cứng
Các mô hình LLM tại Trung Quốc thường sử dụng phần cứng rẻ hơn và tận dụng kiến trúc mở để giảm chi phí. Các mô hình LLM của Mỹ thường được đào tạo trên các cụm GPU thế hệ mới nhất của NVIDIA. Thêm vào đó, do các biện pháp kiểm soát xuất khẩu đối với chip tiên tiến của Mỹ, hầu hết các LLM của Trung Quốc dựa vào đào tạo phân tán trên nhiều GPUs với hiệu năng thấp hơn.
Tuy nhiên DeepSeek vẫn có thể đưa ra những mô hình LLM có hiệu năng mạnh với chi phí khiêm tốn nhờ hai yếu tố:
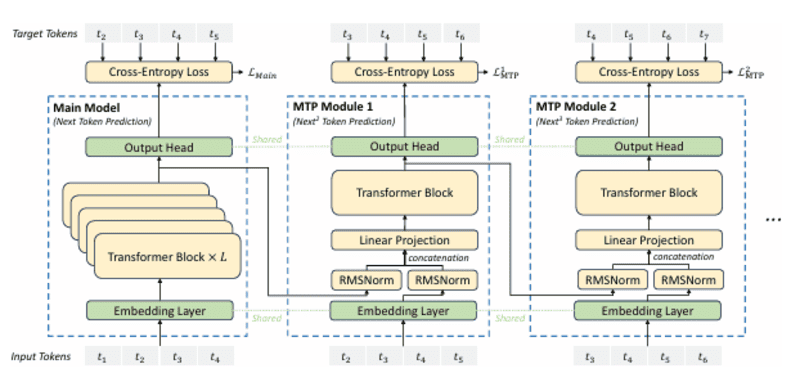
Thứ nhất, về kiến trúc mô hình: DeepSeek cải tiến cơ chế Attention nổi tiếng thành Multi-head Latent Attention (MLA) cho phép tiết kiệm bộ nhớ GPUs. Startup này đã xây dựng kiến trúc DeepSeekMoE và sử dụng mục tiêu huấn luyện Multi-Token Prediction (MTP) nhắm tăng tốc độ huấn luyện.
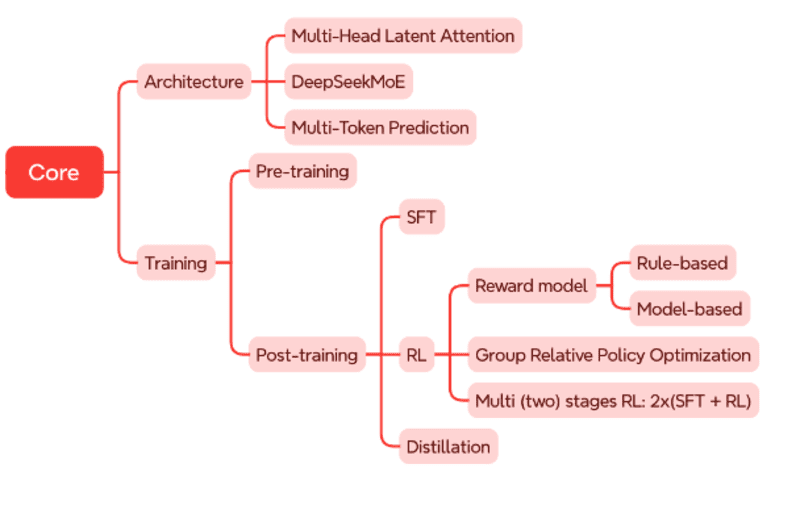
Thứ hai, các kỹ sư của DeepSeek dựa trên nhiều kỹ thuật giúp tạo nên framework dùng để huấn luyện tên là HAI-LLM có thể tận dụng tối ưu hạ tầng mà DeepSeek có. Họ đã khéo léo sắp xếp việc tính toán và truyền dữ liệu một cách hợp lý để GPU không có thời gian nghỉ. Việc truyền dữ liệu giữa các GPU trong một node và giữa các nodes với nhau cũng được tính toán làm sao cho sử dụng hết băng thông NVLink (giữa các GPU trong một node) và InfiniBand (giữa các nodes với nhau).
Thông thường, các mô hình LLM thường được huấn luyện với độ chính xác FP16 (sử dụng 16 bit để lưu trữ trọng số) nhưng framework của DeepSeek kết hợp giữa FP8, BP16, và FP32. Tuỳ từng yêu cầu về độ chính xác của các phép toán mà sử dụng tương ứng.
Các phép tính toán sử dụng nhiều phần lớn sử dụng FP8, còn các biến số quan trọng hơn lại được dùng độ chính xác cao hơn để đảm bảo độ chính xác. Việc này vừa giảm được chi phí lưu trữ và tính toán trên GPU, vừa giảm được chi phí truyền thông tin vốn rất lớn. Các thông tin khác trong quá trình huấn luyện như trạng thái của bộ optimizer cũng được sử dụng BF16 để giảm dung lượng.
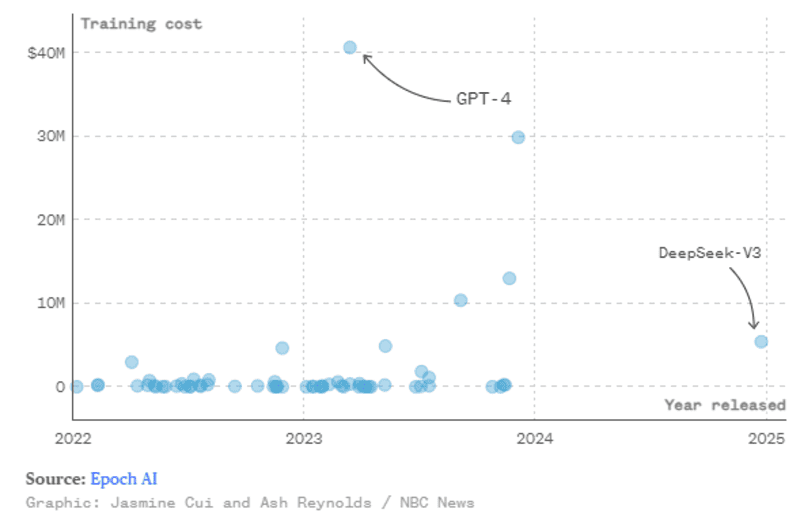
Tất cả những điều trên kết hợp lại đã giúp DeepSeek đạt được chi phí huấn luyện không tưởng, làm dậy sóng cộng đồng sau khi công bố. DeepSeek đưa ra báo cáo họ chỉ tốn chi phí đào tạo mô hình là 5,576 triệu đô la (cho V3) so với 40 triệu đến 200 triệu đô la mà các công ty AI Mỹ như OpenAI và Alphabet đã chi cho các LLM của họ.
>>> XEM THÊM: Retrieval-Augmented Generation nâng cao chất lượng phản hồi cho LLMs như thế nào?
Khác biệt về phạm vi ứng dụng
Điểm khác biệt lớn thứ hai nằm ở phạm vi ứng dụng của các mô hình LLM của Trung Quốc. Các mô hình ngôn ngữ của DeepSeek được huấn luyện để giải quyết các tác vụ chuyên biệt hơn, thay vì giải quyết nhiều tác vụ. Ví dụ mô hình DeepSeek-R1 nổi bật hơn về các tác vụ đòi hỏi năng lực suy luận (reasoning). Trong khi đó, các mô hình như của OpenAI có khả năng giải quyết nhiều bài toán hơn.
Tóm lại, các LLM của Trung Quốc dựa trên phần cứng ít tiên tiến hơn và ban đầu tập trung vào giải quyết các bài toán cụ thể hơn. Điều này cũng có nghĩa là nhiều LLM của Trung Quốc được định giá ở mức thấp hơn. Ví dụ, Qwen plus của Alibaba và Doubao 1.5-pro của ByteDance có giá dưới 0,30 đô la cho mỗi 1 triệu tokens (token là đơn vị dữ liệu nhỏ nhất mô hình xử lý, một token có thể là một chuỗi các ký tự, một từ, hay một phần của từ) đầu ra so với hơn 60 đô la cho OpenAI và Claude 3.5 Opus của Anthropic.
“Năng lực” của DeepSeek có thực sự vượt trội?
Mặc dù có nguồn lực tương đối khiêm tốn, điểm số của DeepSeek trên các bảng đánh giá vẫn theo kịp các mô hình tiên tiến nhất từ các nhà phát triển AI hàng đầu tại Hoa Kỳ.
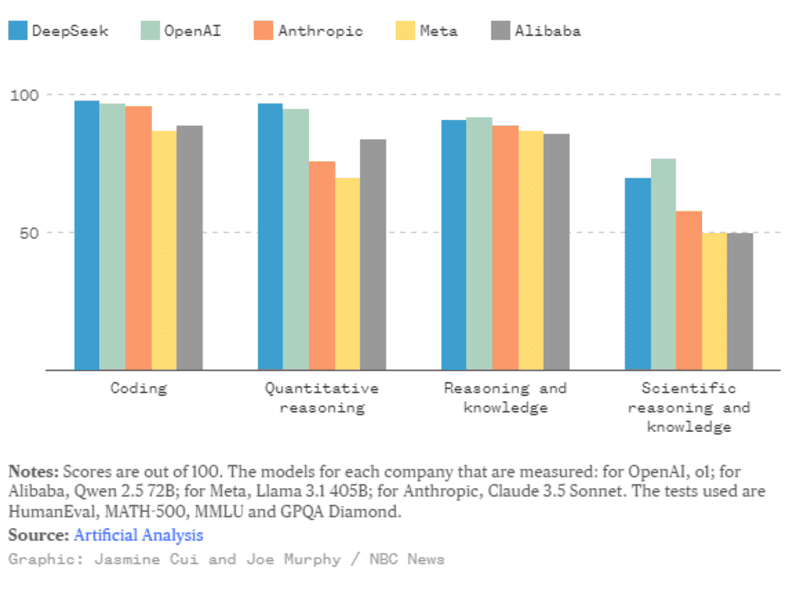
R1 gần như ngang ngửa với mô hình o1 của OpenAI trong bảng xếp hạng do Artificialanalysis.ai công bố với bốn tiêu chí liên quan đến: Lập trình, Tư duy định lượng, Suy luận và Kiến thức, Lý luận và Kiến thức khoa học.
Việc sử dụng phương pháp dự đoán đa token (multi-token prediction) cho phép gia tăng tốc độ và hiệu suất mô hình.
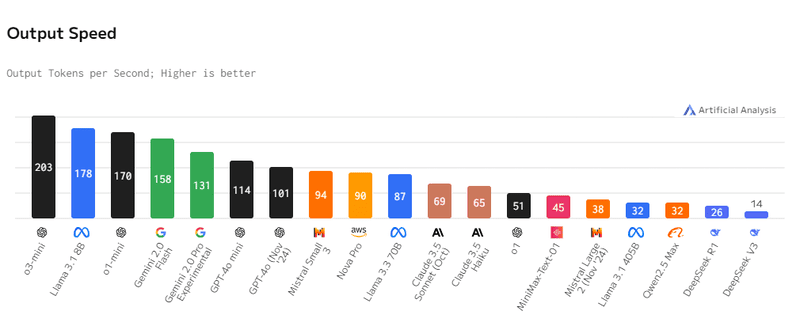
Tuy nhiên, xét về tốc độ xử lý, DeepSeek có phần “chậm” hơn khi chỉ có thể đưa ra 26 tokens trong 1 giây xử lý, thua khá xa so với 203 tokens từ o3-mini của OpenAI hay 158 tokens của Gemini 2.0 Flash của Google.
>>> XEM THÊM: Transformer Model là gì? Kiến trúc Transformer trong NLP
Vậy Deep-Seek tạo ra hai Mô hình V3 và R1 như thế nào?
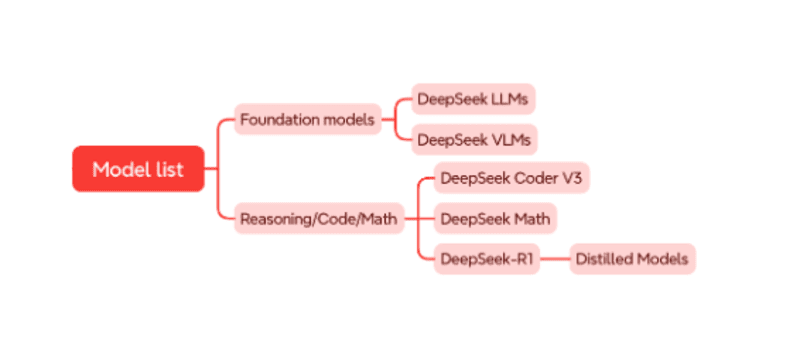
DeepSeek phát triển hai nhóm mô hình chính: mô hình nền tảng (foundation models) ví dụ như DeepSeek-V3. Các mô hình này thường được huấn luyện với lượng dữ liệu rất lớn (hàng nghìn tỉ tokens) mới mục hiểu và sinh ngôn ngữ nói dung. Nhóm mô hình thứ 2 là các mô hình có năng lực cụ thể riêng. Ví dụ như mô hình DeepSeek-R1 giải quyết tốt các bài toán cần khả năng suy luận. Việc xây dựng nhóm mô hình này thường dựa trên các mô hình nền tảng.
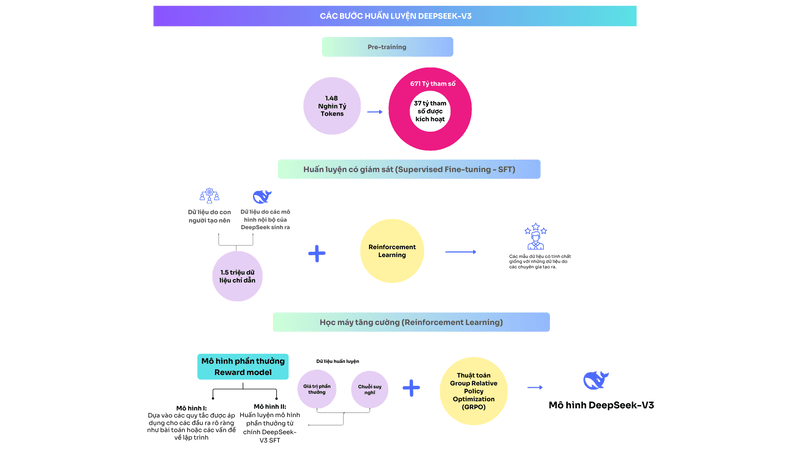
Các bước huấn luyện DeepSeek V3
- Pre-training: DeepSeek-V3 được huấn luyện với 14.8 nghìn tỷ tokens. Kết quả cho ra mô hình với 671 tỷ tham số, trong đó chỉ 37 tỷ tham số được kích hoạt với mỗi token đầu vào. Ban đầu, DeepSeek-V3 có độ dài ngữ cảnh (context length) là 4 nghìn, các nhà nghiên cứu đã áp dụng kỹ thuật mở rộng ngữ cảnh (context extension) để tăng ngữ cảnh lên 128 nghìn.
- Huấn luyện có giám sát (Supervised Fine-tuning – SFT): Để mô hình hoạt động tốt hơn, DeepSeek được huấn luyện thêm với 1.5 triệu dữ liệu có chỉ dẫn (instruction data). Dữ liệu này được kết hợp từ dữ liệu do con người tạo nên và do các mô hình nội bộ của DeepSeek sinh ra. Các mô hình nội bộ này được sử dụng kỹ thuật học máy tăng cường để giúp nó sinh ra các mẫu dữ liệu có tính chất giống với những dữ liệu do các chuyên gia tạo ra.
- Học tăng cường (Reinforcement Learning – RL): Thành phần quan trọng của bước này là mô hình phần thưởng (reward model). DeepSeek sử dụng hai loại mô hình: thứ nhất là mô hình dựa vào các quy tắc (rule-based models) được áp dụng cho các đầu ra rõ ràng như bài toán hay các vấn đề về lập trình; thứ hai là huấn luyện mô hình phần thưởng (model-based models) từ chính DeepSeek-V3. Cuối cùng, các nhà nghiên cứu sử dụng thuật toán học tăng cường Group Relative Policy Optimization (GRPO) để huấn luyện ra mô hình cuối cùng.
>>> XEM THÊM: Fine-tuning là gì? So sánh Fine-tuning vs Transfer Learning
Các bước huấn luyện DeepSeek-R1
Xuất phát từ mô hình DeepSeek-V3-Base, mô hình DeepSeek R1 được huấn luyện khá khác biệt với các bước như sau:
- Khởi động nguội (Cold Start): Nhằm giúp việc huấn luyện ổn định từ đầu và có khả năng suy luận tốt hơn, R1 sử dụng một lượng nhỏ dữ liệu dạng Chain-of-Thoght (CoT) để huấn luyện khởi động cho mô hình của mình.
- Học tăng cường với định hướng suy luận: Bước này tương tự bước 3 khi huấn luyện DeepSeek-V3, chỉ sử dụng mô hình phần thưởng dạng rule-based. Việc huấn luyện được kết thúc khi mô hình hội tụ trên các bài toán về suy luận.
- Tạo dữ liệu suy luận chất lượng cao: Mô hình từ bước 2 sẽ tạo ra và chọn lọc các mẫu dữ liệu suy luận tốt nhất. Các mẫu này sẽ được kết hợp với một phần dữ liệu Supervised Fine-Tuning (SFT) từ DeepSeek-V3 để huấn luyện tiếp với khoảng 800 nghìn dữ liệu.
- Huấn luyện bằng Reinforcement Learning (RL): Cuối cùng, mô hình trải qua một vòng huấn luyện học tăng cường (Reinforcement Learning – RL) để tinh chỉnh kết quả theo mong muốn của người dùng, đồng thời loại bỏ nội dung không mong muốn.
Ngoài ra, để có được các mô hình nhỏ hơn mà vẫn mang khả năng của DeepSeek-R1, các nhà nghiên cứu tại DeepSeekAI đã tinh chỉnh các mô hình mã nguồn mở như Qween, Llama với 800 nghìn mẫu ở trên (bước 3 khi huấn luyện DeepSeek-R1). Kết quả cho thấy các phiên bản nhỏ (từ 1.5 tỷ đến 70 tỷ tham số) được cải thiện đáng kể khả năng suy luận.
>>> XEM THÊM: Vision Language Models là gì? GPT 4o có phải là VLMs không?
Mối lo ngại về bảo mật dữ liệu người dùng
Hiện nay, các cơ quan quản lý đang đặt ra những câu hỏi mới về sự an toàn của dữ liệu người dùng khi sử dụng ứng dụng DeepSeek.
Các cơ quan quản lý ở Ý đã chặn ứng dụng này khỏi các cửa hàng ứng dụng của Apple và Google tại quốc gia này, khi chính phủ điều tra dữ liệu mà công ty đang thu thập và cách thức lưu trữ dữ liệu đó. Tại Pháp và Ireland, các quan chức đang tìm hiểu xem liệu AI chatbot này có gây ra nguy cơ về quyền riêng tư hay không.
Theo chính sách bảo mật của DeepSeek, dịch vụ này thu thập một lượng lớn dữ liệu người dùng, bao gồm lịch sử trò chuyện và tìm kiếm, thiết bị mà người dùng đang sử dụng, các mẫu gõ phím, địa chỉ IP, kết nối internet và hoạt động từ các ứng dụng khác.
Các dịch vụ AI khác, như ChatGPT của OpenAI, Claude của Anthropic cũng thu thập một lượng dữ liệu tương tự từ người dùng. Các ứng dụng mạng xã hội như Facebook, Instagram và X cũng làm điều tương tự.
Theo bà Angela Zhang, Giáo sư luật tại Đại học Southern California cho biết “Mối quan ngại về an ninh dữ liệu luôn là một vấn đề quan trọng khi sử dụng các chatbot AI, và điều này không chỉ riêng DeepSeek.”
Kết luận
Cú sốc trong thế giới công nghệ đã khơi mào một cuộc tranh luận trong ngành, cho thấy có thể các nhà phát triển AI không cần phải tiêu tốn một lượng tiền bạc và tài nguyên khổng lồ để xây dựng mô hình của mình. Thay vào đó, các nhà nghiên cứu đang nhận ra rằng có thể làm cho các quy trình này trở nên hiệu quả, cả về chi phí và năng lượng, mà không làm giảm khả năng của mô hình. Điều này cũng mở ra một tương lai rộng mở hơn trong việc tiếp cận và ứng dụng AI với tất cả mọi người.
Tài liệu tham khảo:
- DeepSeek Team. (2024). DeepSeek-V3 and beyond: Scaling and optimizing open-source LLMs (arXiv:2412.19437). arXiv. https://arxiv.org/pdf/2412.19437
- World Economic Forum. (2025, 2 tháng 2). Open-source AI đang thúc đẩy đổi mới sáng tạo như thế nào? https://www.weforum.org/stories/2025/02/open-source-ai-innovation-deepseek/
- Harvard Business Review. (2025, 1 tháng 1). Tại sao sự xuất hiện của DeepSeek không phải là điều bất ngờ? https://hbr.org/2025/01/why-deepseek-shouldnt-have-been-a-surprise
- NBC News. (2025). So sánh DeepSeek AI với OpenAI ChatGPT, Google Gemini và Meta Llama. https://www.nbcnews.com/data-graphics/deepseek-ai-comparison-openai-chatgpt-google-gemini-meta-llama-rcna189568
>>> XEM THÊM CÁC BÀI VIẾT KHÁC: