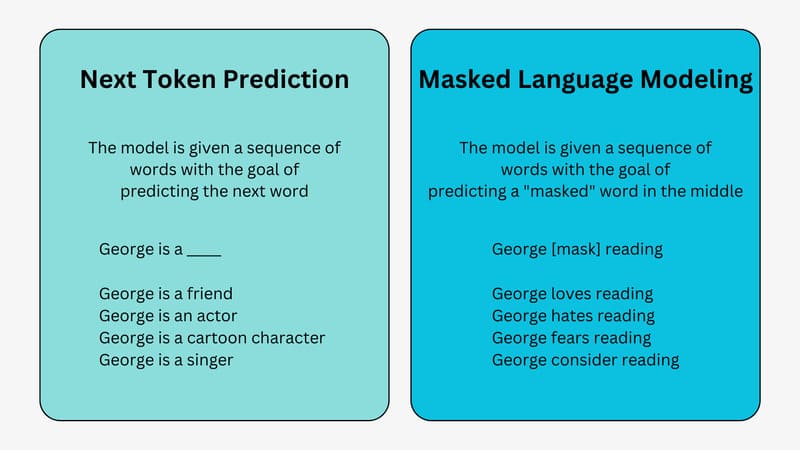
Masked Language Models (MLMs) là các mô hình ngôn ngữ trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP) được thiết kế để dự đoán các từ bị che (masked) trong văn bản dựa trên ngữ cảnh xung quanh. Trong bài viết này, FPT.AI sẽ giới thiệu chi tiết về MLMs, từ cách thức hoạt động, sự khác biệt so với Causal Language Modeling và Word2Vec đến những ứng dụng và lợi ích nổi bật của mô hình trong lĩnh vực xử lý ngôn ngữ tự nhiên hiện đại.
Masked Language Models là gì?
Masked Language Models (MLMs) là một mô hình ngôn ngữ trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP) có khả năng dự đoán các từ bị che (masked) trong văn bản dựa trên ngữ cảnh xung quanh. MLMs thường được sử dụng để tiền huấn luyện (pre-training) các mô hình Transformer.

Các Masked Language Models phổ biến bao gồm:
- Google BERT (Bidirectional Encoder Representations from Transformers): Mô hình MLM được sử dụng rộng rãi nhất. Với kiến trúc transformer hai chiều, BERT xem xét cả ngữ cảnh bên trái và bên phải của mỗi token, giúp nắm bắt tốt hơn các mối quan hệ và tương tác giữa các từ. BERT có hai phiên bản chính: BERTBASE và BERTLARGE, khác nhau về số lượng lớp mã hóa, đầu self-attention và kích thước vector ẩn. Ưu điểm lớn của BERT là khả năng tiền huấn luyện trên dữ liệu không nhãn, sau đó tinh chỉnh cho nhiều tác vụ NLP khác nhau.
- RoBERTa (Robustly Optimized BERT Approach): Một phiên bản cải tiến của BERT, có thể xử lý nhiều tác vụ đánh giá NLP hiệu quả hơn do sử dụng nhiều dữ liệu hơn và loại bỏ một số mục tiêu không cần thiết trong quá trình tiền huấn luyện.
- ALBERT (A Lite BERT): Biến thể có khả năng giải quyết vấn đề về kích thước lớn và nhu cầu tính toán cao của BERT bằng cách áp dụng các kỹ thuật như phân tích tham số hóa nhúng (factorized embedding parameterization) và chia sẻ tham số giữa các lớp.
- GPT (Generative Pre-trained Transformer): Mô hình transformer dự đoán được phát triển bởi OpenAI, bao gồm các phiên bản như GPT-3 và GPT-4. Khác với BERT, GPT sử dụng kiến trúc transformer một chiều (chỉ xem xét ngữ cảnh bên trái). Dù không phải là MLM thuần túy, các mô hình GPT đã đạt được kết quả ấn tượng trong nhiều tác vụ ngôn ngữ, từ tạo văn bản đến trả lời câu hỏi phức tạp.
- T5 (Text-to-Text Transfer Transformer) của Google có cách tiếp cận đặc biệt khi định nghĩa tất cả các tác vụ NLP như các vấn đề chuyển đổi từ văn bản sang văn bản. T5 có tính linh hoạt cao, có thể thích ứng hiệu quả với nhiều tác vụ NLP khác nhau từ dịch máy (Machine Translation) đến tóm tắt văn bản mà không cần thay đổi kiến trúc cơ bản.
Một số nhóm nghiên cứu xem Masked Language Modeling là một phương pháp phương pháp học chuyển giao (transfer learning) sau khi sử dụng nó như một tác vụ cuối cùng (end-task) tự thân cho các tác vụ NLP như phân loại văn bản, phân tích cảm xúc, trả lời câu hỏi và dịch máy.
Các thư viện được ví như “GitHub cho AI” như HuggingFace Transformers và TensorFlow Text đang cung cấp nhiều công cụ, hàm và API để huấn luyện, mã hoá, tinh chỉnh và sử dụng MLMs, dân chủ hóa việc tiếp cận các công nghệ và xu hướng AI tiên tiến, giúp cả chuyên gia lẫn người mới bắt đầu có thể làm việc với các mô hình ngôn ngữ lớn phức tạp.
>>> XEM THÊM: NLU là gì? So sánh hiểu ngôn ngữ tự nhiên NLU vs NLP, NLG
Cách thức hoạt động của Masked Language Models
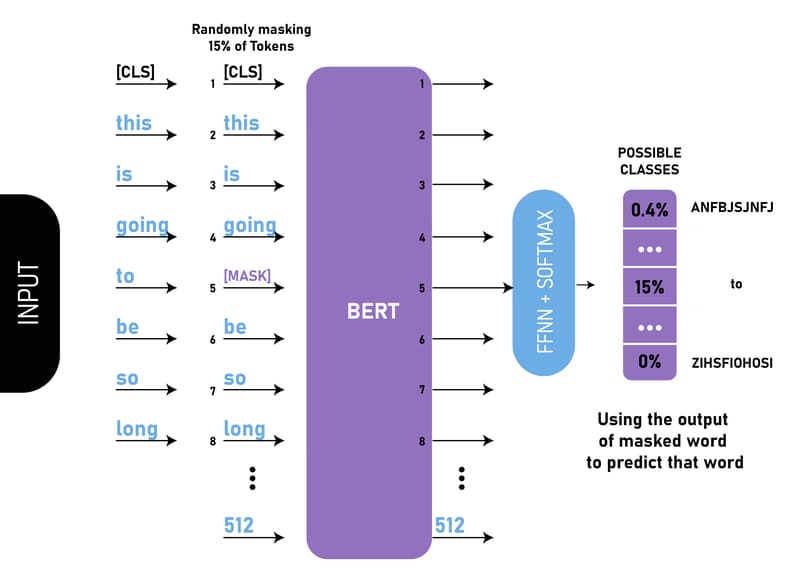
Masked Language Models (MLMs) hoạt động theo một quy trình học máy (Machine Learning) không giám sát đặc trưng, bắt đầu với việc xử lý một kho dữ liệu văn bản lớn chưa gán nhãn. Cốt lõi của phương pháp này là thay thế ngẫu nhiên một số từ trong văn bản đầu vào bằng các token [MASK] hoặc các token từ khác từ vốn từ vựng của văn bản đầu vào, sau đó dự đoán từ nào có khả năng xuất hiện nhất trong văn bản đầu vào ban đầu. Ví dụ, trong câu “The cat [MASK] the tree,” mô hình sẽ dự đoán từ “climbed” (leo trèo) là token bị che.
Tiếp theo, Masked Language Models sẽ chuyển đổi mỗi token từ trong văn bản thành các word embeddings – các vector biểu diễn số học của từ. Các word embeddings này sau đó được kết hợp với positional encodings (mã hóa vị trí) để giúp mô hình nắm bắt mối quan hệ ngữ nghĩa giữa các từ dựa trên vị trí tương đối của chúng..
Điểm đột phá của MLMs nằm ở bộ mã hóa hai chiều (bidirectional encoder) trong kiến trúc Transformer. Mô hình sẽ xem xét toàn bộ ngữ cảnh – cả văn bản đi trước và đi sau từ bị che – để nắm bắt ngữ cảnh toàn diện trước khi đưa ra dự đoán.
Sau đó, Masked Language Models sẽ so sánh những dự đoán này với các từ thực tế trong văn bản gốc và cải thiện khả năng dự đoán bằng cách điều chỉnh các tham số dựa trên sự khác biệt giữa dự đoán và giá trị thực. Thông qua việc xử lý hàng triệu ví dụ, MLMs học được các biểu diễn ngữ cảnh phong phú của ngôn ngữ, nắm bắt được cả cấu trúc ngữ pháp và ý nghĩa ngữ nghĩa.
>>> XEM THÊM: Natural Language Generation là gì? 3 lợi ích chính của NLG
Masked Language Modeling khác với Causal Language Modeling như thế nào?
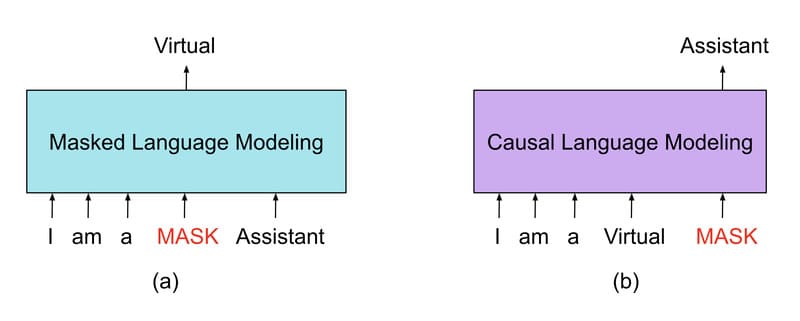
Dù đều là các phương pháp học máy tự giám sát, Masked Language Modeling (MLM) và Causal Language Modeling (CLM) khác nhau về cách thức hoạt động và ứng dụng.
MLM giúp mô hình ngôn ngữ như BERT dự đoán các token bị che ngẫu nhiên trong một chuỗi văn bản dựa trên ngữ cảnh xung quanh trong khi CLM tập trung vào việc dự đoán từ tiếp theo trong chuỗi văn bản dựa trên các từ đã xuất hiện trước đó.
MLM có thể hiểu được mối quan hệ hai chiều giữa các từ trong câu nhờ xem xét cả các từ đứng trước và đứng sau token cần dự đoán. Ngược lại, CLM chỉ nhìn vào quá khứ (các từ đã xuất hiện) để dự đoán tương lai (từ tiếp theo). Cách tiếp cận này đặc trưng cho các mô hình thuộc họ GPT.
MLM phù hợp cho các tác vụ đòi hỏi hiểu biết sâu về ngữ cảnh, trong khi CLM lại xuất sắc trong việc tạo văn bản mạch lạc theo thời gian. Cả hai phương pháp đều đóng vai trò quan trọng trong sự phát triển của các mô hình ngôn ngữ hiện đại và đã được ứng dụng rộng rãi trong nhiều lĩnh vực xử lý ngôn ngữ tự nhiên. Tùy thuộc vào yêu cầu cụ thể của từng tác vụ, các nhà nghiên cứu có thể lựa chọn phương pháp phù hợp hoặc kết hợp cả hai để đạt được hiệu quả tối ưu.
>>> XEM THÊM: ChatGPT là gì? Cách tạo tài khoản Chat GPT free
Sự khác biệt giữa Masked Language Modeling và Word2Vec
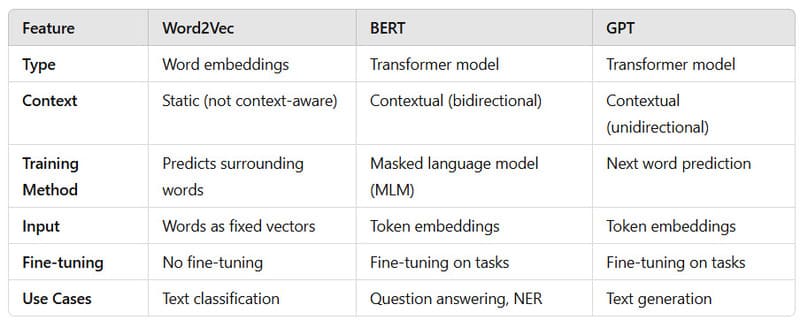
Word2Vec là một phương pháp được sử dụng trong NLP, trong đó các vector nắm bắt ngữ nghĩa của các từ và mối quan hệ giữa chúng bằng cách sử dụng mạng nơ-ron để học các biểu diễn vector. Word2Vec khác với các mô hình huấn luyện tự giám sát như Masked Language Modeling ở những điểm sau:
- Word2Vec là một thuật toán học máy không giám sát được sử dụng để tạo ra các word embeddings – các vector số học đại diện cho từ trong một không gian nhiều chiều.
- Word2Vec nắm bắt mối quan hệ cú pháp và ngữ nghĩa giữa các từ bằng cách biểu diễn chúng dưới dạng các vector dày đặc trong một không gian vector liên tục.
- Khi được huấn luyện trên các kho ngữ liệu lớn, Word2Vec học cách dự đoán ngữ cảnh của từng từ trong một văn bản xác định, bao gồm dự đoán từ mục tiêu hoặc các từ xung quanh.
- Word2Vec có thể được huấn luyện bằng hai thuật toán khác nhau – Continuous Bag of Words và Skip-Gram.
- Các embeddings tạo ra từ Word2Vec thường được sử dụng để đo lường độ tương tự giữa các từ hoặc làm đặc trưng đầu vào cho các nhiệm vụ NLP khác.
>>> XEM THÊM: Text Preprocessing – Kỹ thuật tiền xử lý văn bản trong NLP (Natural Language Processing)
Lợi ích của Masked Language Models
Masked Language Models (MLMs) mang lại nhiều lợi ích quan trọng trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP). Dưới đây là những ưu điểm nổi bật của MLMs:
- Hiểu biết ngữ cảnh sâu sắc: MLMs phát triển khả năng hiểu ngữ cảnh mạnh mẽ thông qua việc dự đoán các token bị che dấu dựa vào môi trường xung quanh. Cơ chế này giúp mô hình nắm bắt được các mối liên hệ phức tạp và quan hệ phụ thuộc giữa các từ trong văn bản, tạo nền tảng cho việc hiểu ngôn ngữ tự nhiên tốt hơn.
- Xử lý thông tin hai chiều: Không giống như các mô hình truyền thống chỉ phân tích ngữ cảnh một chiều, MLMs như BERT xem xét ngữ cảnh từ cả hai hướng (trước và sau) của một token bị che. Phương pháp xử lý này cho phép mô hình rút ra ý nghĩa chính xác hơn, nắm bắt được ngữ cảnh toàn diện từ toàn bộ chuỗi văn bản.
- Nền tảng tiền huấn luyện hiệu quả: MLMs hoạt động như một kỹ thuật tiền huấn luyện mạnh mẽ cho nhiều tác vụ NLP khác nhau. Bằng cách học từ khối lượng dữ liệu không nhãn khổng lồ, MLMs tạo ra các biểu diễn ngôn ngữ phong phú có thể được tinh chỉnh cho các ứng dụng cụ thể như phân tích cảm xúc, phân loại văn bản, nhận dạng thực thể và hệ thống hỏi đáp.
- Khả năng nắm bắt tương đồng ngữ nghĩa: MLMs có khả năng đặc biệt trong việc đo lường và nhận diện sự tương đồng ngữ nghĩa giữa các câu hoặc đoạn văn. Thông qua việc so sánh biểu diễn của các token bị che trong các ngữ cảnh khác nhau, mô hình có thể phát hiện những mối liên hệ ngữ nghĩa tinh tế trong văn bản, hỗ trợ cho các ứng dụng như tìm kiếm ngữ nghĩa và phân tích văn bản.
- Khả năng chuyển giao học tập vượt trội: MLMs thể hiện khả năng transfer learning xuất sắc. Quá trình tiền huấn luyện trên tập dữ liệu lớn giúp mô hình nắm bắt kiến thức ngôn ngữ tổng quát, sau đó chỉ cần tinh chỉnh trên các tập dữ liệu có nhãn nhỏ hơn cho các nhiệm vụ cụ thể, tiết kiệm đáng kể thời gian và tài nguyên tính toán.
>>> XEM THÊM: Dialog Management và vai trò trong việc phát triển chatbot
Các ứng dụng nổi bật của Masked Language Models
Masked Language Models (MLM) đã đóng góp đáng kể vào việc cải thiện hiệu suất của các tác vụ NLP khác nhau, bao gồm:
- Nhận dạng thực thể có tên (Named Entity Recognition – NER): MLM được sử dụng như một phương pháp tăng cường dữ liệu (data augmentation) hiệu quả trong việc xác định các danh mục đối tượng được xác định trước trong văn bản như tên người, địa điểm, tổ chức, loại bỏ các hạn chế về độ chính xác do thiếu dữ liệu huấn luyện phù hợp của NER.
- Phân tích cảm xúc (Sentiment Analysis): Tương tự như nhận dạng thực thể có tên, các nhà nghiên cứu đã tận dụng Masked Language Modeling như một kỹ thuật tăng cường dữ liệu cho phân tích cảm xúc. Phương pháp này cũng cho thấy tiềm năng cho việc thích ứng lĩnh vực (domain adaptation) với khả năn dự đoán các từ có trọng số lớn cho các tác vụ phân loại cảm xúc như phân tích đánh giá của khách hàng trực tuyến.
- Trả lời câu hỏi (Question Answering): MLM giúp các hệ thống trả lời câu hỏi tự động hiểu sâu hơn về ngữ cảnh và mối quan hệ giữa các thông tin trong văn bản, từ đó đưa ra câu trả lời chính xác và phù hợp với câu hỏi được đặt ra.
- Phát triển mô hình đa ngôn ngữ: MLM ban đầu chỉ tập trung vào tiếng Anh và các ngôn ngữ gốc Latin. Gần đây, nghiên cứu đã mở rộng sang tiếng Nhật, tiếng Nga và nhiều ngôn ngữ khác. Kỹ thuật mới trong việc huấn luyện MLM đa ngôn ngữ là sử dụng “token che đặc biệt” – khi huấn luyện mô hình với nhiều ngôn ngữ cùng lúc, một số từ được che đi có chủ đích. Cách này giúp mô hình học cách “chuyển đổi” giữa các ngôn ngữ (forward pass xuyên ngôn ngữ), làm tăng đáng kể hiệu quả khi phân loại văn bản ở nhiều ngôn ngữ khác nhau.
Tóm lại, Masked Language Models đã tạo ra bước đột phá trong lĩnh vực xử lý ngôn ngữ tự nhiên với khả năng hiểu ngữ cảnh hai chiều độc đáo. Với khả năng tiền huấn luyện trên dữ liệu không nhãn và tinh chỉnh linh hoạt, MLMs đang cách mạng hóa cách máy móc nhận dạng thực thể, phân tích cảm xúc, trả lời câu hỏi và xử lý đa ngôn ngữ.
Trong tương lai, khi các công cụ như HuggingFace Transformers và TensorFlow Text tiếp tục dân chủ hóa việc tiếp cận MLMs, chúng ta có thể kỳ vọng vào những đột phá mới, đẩy mạnh khả năng máy tính hiểu và xử lý ngôn ngữ tự nhiên một cách toàn diện và sâu sắc hơn.
>>> XEM THÊM: