




Trong thời đại mà giọng nói nhân tạo ngày càng len lỏi vào đời sống hiện đại – từ trợ lý ảo, tổng đài thông minh đến podcast AI – công nghệ Text to Speech (TTS) đã trở thành một trụ cột trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP). Nhưng để tạo ra một giọng đọc mượt mà, truyền cảm như người thật, TTS hiện đại không còn đơn giản là “ghép chữ thành âm thanh” như thuở sơ khai. Đằng sau mỗi đoạn âm thanh là cả một chuỗi xử lý phức tạp, tinh vi và ngày càng thông minh hơn.
Nguyên lý hoạt động của công nghệ Text to speech
Text to Speech (TTS) là công nghệ chuyển đổi văn bản thành giọng nói tự nhiên. Đây là một nhánh quan trọng trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP) và có vai trò then chốt trong các ứng dụng như trợ lý ảo, voicebot, đọc sách nói, hỗ trợ người khiếm thị, dịch ngôn ngữ thời gian thực… Công nghệ Text to speech hiện nay chủ yếu dựa trên học sâu (deep learning) và được chia thành 3 giai đoạn chính:
Giai đoạn 1: Phân tích ngôn ngữ đầu vào, “đọc hiểu” văn bản như con người
Quá trình bắt đầu từ một đoạn văn bản thuần túy. Trước khi có thể “nói”, hệ thống Text to Speech cần hiểu ngữ nghĩa và cấu trúc của văn bản giống như một người đọc lành nghề. Giai đoạn này bao gồm việc chuẩn hóa văn bản (text normalization): biến các ký hiệu như “1kg” thành “một ki-lô-gam”, “25/12” thành “hai mươi lăm tháng mười hai”, và xử lý các yếu tố đặc biệt như viết tắt, dấu câu, từ ngoại lai. Tiếp đến, văn bản được phân tách thành các đơn vị âm vị (phonemes), đồng thời xác định các yếu tố ngữ điệu như nhấn trọng âm, ngắt nghỉ và độ dài âm tiết. Mục tiêu là để hệ thống biết nên nói chỗ nào nhanh – chậm, cao – thấp, nhấn mạnh hay dịu lại. Đây là bước quyết định “giọng” sẽ nghe tự nhiên hay robot hóa.
Giai đoạn 2: Dự đoán đặc trưng âm thanh
Sau khi hiểu văn bản, hệ thống cần chuyển những thông tin ngôn ngữ thành đặc trưng âm học, hay nói cách khác, tạo ra một “bản nhạc vô hình” cho giọng nói. Công đoạn này sử dụng các mô hình học sâu như Tacotron, FastSpeech hoặc các biến thể hiện đại hơn. Thay vì tạo sóng âm trực tiếp, các mô hình này sinh ra mel-spectrogram, một biểu diễn trực quan thể hiện cường độ âm thanh ở các dải tần số khác nhau theo thời gian. Mỗi biểu đồ mel chính là một tấm bản đồ chi tiết cho biết giọng nói đó sẽ “nghe” như thế nào: khi nào cao độ thay đổi, khi nào âm thanh tăng vọt hoặc dịu lại. Đây là điểm đột phá của Text to Speech hiện đại so với Text to Speech truyền thống đó là, thay vì nối các đoạn âm thanh đã ghi âm sẵn, giờ đây giọng nói được sinh ra theo thời gian thực dựa trên mô hình học sâu, cho phép linh hoạt hơn rất nhiều về cảm xúc và tốc độ.
Giai đoạn 3: Tổng hợp tín hiệu âm thanh
Từ mel-spectrogram, hệ thống sẽ sử dụng một thành phần gọi là vocoder để biến biểu đồ này thành tín hiệu âm thanh thực sự – tức là những gì mà tai người nghe được. Một số vocoder nổi bật hiện nay bao gồm WaveNet (DeepMind), HiFi-GAN, Parallel WaveGAN. Các vocoder này hoạt động như những nhạc công: nhìn bản nhạc (mel-spectrogram) và “chơi” ra giọng nói với độ chi tiết cao, mượt mà và giàu cảm xúc. Nhờ những tiến bộ về kiến trúc mạng nơ-ron và GPU chuyên dụng, quá trình này hiện có thể diễn ra trong thời gian thực (real-time) với chất lượng gần như không phân biệt được với giọng người.
Không dừng lại ở việc đọc văn bản, công nghệ Text to Speech hiện đại còn có thể được tùy biến theo cảm xúc, ngữ điệu, độ tuổi, giới tính, và thậm chí mô phỏng giọng nói cụ thể của một cá nhân nếu có đủ dữ liệu (voice cloning). Nhờ đó, người dùng có thể chọn giọng nữ nhẹ nhàng để kể chuyện, giọng nam nghiêm túc để đọc tin tức, hoặc giọng trẻ con đáng yêu cho truyện thiếu nhi. Khả năng điều chỉnh này không chỉ tạo nên trải nghiệm người dùng tốt hơn, mà còn mở ra một thế giới mới cho truyền thông cá nhân hóa, chăm sóc khách hàng tự động, và sản xuất nội dung sáng tạo không giới hạn.
Hiện nay, Text to Speech không còn là việc “chuyển chữ thành âm” đơn thuần. Đó là một quá trình ba tầng: Hiểu ngôn ngữ, dự đoán giọng điệu, và tổng hợp âm thanh, được dẫn dắt bởi những mạng nơ-ron phức tạp, mô phỏng cách con người nói chuyện. Với tốc độ phát triển của trí tuệ nhân tạo, tương lai của Text to Speech sẽ không chỉ dừng lại ở việc “đọc”, mà còn là biết nói đúng lúc, đúng cách và đúng cảm xúc, giúp cho AI trở thành người bạn đồng hành thân thiện hơn bao giờ hết.
Ứng dụng của Text to Speech trong cuộc sống hiện đại
Ứng dụng trong sáng tạo nội dung
Text to Speech đã tạo ra những cú hích cho video triệu view trên các nền tảng TikTok, YouTube Shorts hay Facebook Reels, nội dung “voice-over” đóng vai trò cực kỳ quan trọng. Người sáng tạo không cần lên hình, không cần thu âm, chỉ cần một kịch bản tốt – phần còn lại do Text to Speech đảm nhiệm. Những năm 2020-2023, giọng chị Ban Mai của FPT AI Voicemaker từng tạo trào lưu với các video “review phim”, kể chuyện “drama”, chuyện tình cảm hack não – thu hút hàng triệu lượt xem. Không chỉ tạo cảm giác chuyên nghiệp, giọng AI giúp nội dung giữ nhịp đều, sắc nét và dễ “viral”, lại không lệ thuộc vào thời gian, cảm xúc, sức khỏe của con người. Text to Speech giúp các nhà sáng tạo cá nhân, giáo viên, tác giả sách hoặc doanh nghiệp chuyển đổi bài viết, nội dung chuyên môn, tin tức hàng ngày thành podcast chất lượng cao chỉ trong phút chốc. Điều này không chỉ tiết kiệm chi phí sản xuất mà còn mở rộng đối tượng tiếp cận, đặc biệt với người bận rộn hoặc không có thói quen đọc. Nhiều kênh podcast hiện nay chỉ cần: Soạn văn bản → chọn giọng → chèn nhạc nền → xuất bản. Giọng đọc của FPT AI Voicemaker được sử dụng cho nhiều mục đích nội dung video với những cảm xúc khác nhau, từ giọng dõng dạc đọc tin tức, giọng mềm mại trầm ấm độc tản văn chữa lành, truyền cảm, hài hước, đáng tin cậy.
Đặc biệt, Text to Speech là một công cụ trợ đắc lực có tính cá nhân hóa, không chỉ hỗ trợ người sáng tạo nội dung, mà còn mở ra hướng đi mới cho những ai muốn xây dựng thương hiệu cá nhân bằng giọng nói riêng. Với khả năng clone giọng (voice cloning) hoặc tạo chất giọng đặc trưng theo phong cách (trẻ trung – trưởng thành – sang trọng – dễ thương…), người sáng tạo có thể tạo ra một “chữ ký âm thanh” độc nhất, ghi dấu trong tâm trí người nghe.
Ứng dụng trong thương mại điện tử và marketing
Trong các chiến dịch truyền thông, quảng cáo sản phẩm, Text to Speech trở thành công cụ bán hàng, giúp các thương hiệu tạo video voice-over chuyên nghiệp, đều nhịp, dễ chỉnh sửa. Các video giới thiệu sản phẩm, “review” mỹ phẩm, kể chuyện khách hàng hay quảng cáo nhắm mục tiêu, giọng nói AI giúp cá nhân hóa và tăng độ tin cậy. Không ít nhãn hàng hiện nay sử dụng Text to Speech để làm voice cho video TikTok bán hàng, giúp nội dung vừa đều nhịp, vừa dễ chỉnh sửa, vừa chuyên nghiệp. Bạn muốn thử nghiệm phương án mới mẻ này với các kiểu giọng khác nhau để xem cái nào có tỷ lệ chuyển đổi cao hơn? Với Text to Speech, điều này vô cùng đơn giản và tiết kiệm chi phí, nhanh dễ thực hiện.
Text to Speech không chỉ hiện diện trong video hay podcast bằng cách chuyển văn bản thành âm thanh khô khan, Text to Speech hiện đại đã tiến hóa thành một công nghệ cho phép Chatbot và AI Agents “cất tiếng nói” như người thật, góp phần tạo nên trải nghiệm liền mạch, thuyết phục và gần gũi hơn bao giờ hết. Trong một hệ thống giao tiếp bằng giọng nói, quy trình hoạt động thường bắt đầu từ người dùng – có thể nhập văn bản (chat) hoặc nói trực tiếp (voice). Nếu là giọng nói, hệ thống sẽ sử dụng công nghệ nhận diện tiếng nói (ASR – Automatic Speech Recognition) để chuyển thành văn bản. Văn bản sau đó được xử lý bởi các mô hình NLP (Xử lý ngôn ngữ tự nhiên) nhằm hiểu được ý định, cảm xúc, và ngữ cảnh hội thoại. Chatbot hoặc AI Agent sẽ đưa ra phản hồi phù hợp, và cuối cùng, Text to Speech đảm nhận nhiệm vụ chuyển phản hồi đó thành giọng nói mượt mà, truyền cảm để gửi ngược lại cho người dùng.
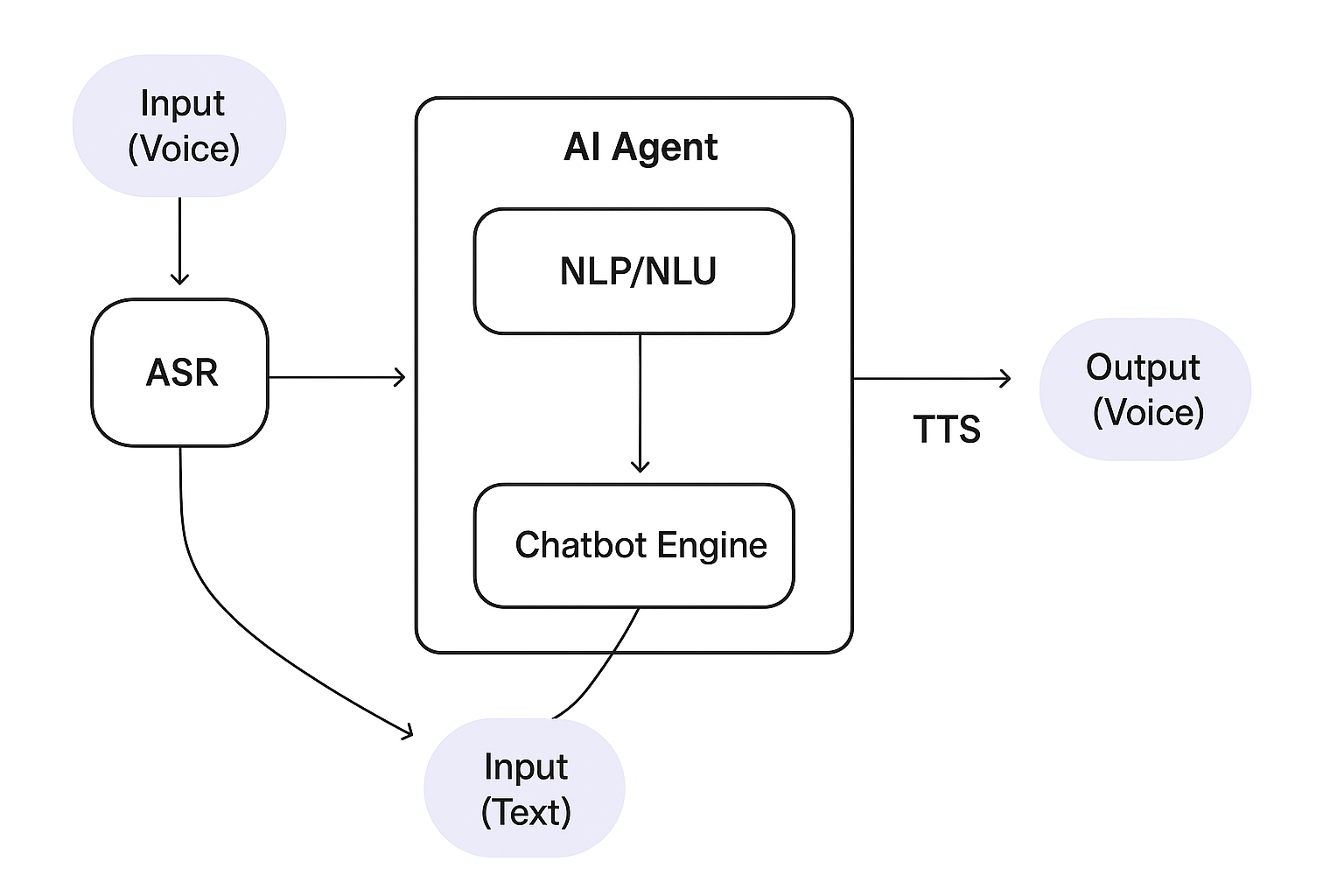
Sơ đồ kiến trúc tổng thể cho AI Agent tích hợp Text to SpeechTexxt to Speech giúp các AI Agent không chỉ trả lời đúng, mà còn trả lời “giống người”, bằng một giọng nói có cảm xúc, tạo cảm giác tin cậy. Ở Việt Nam, FPT AI Voicemaker đã được tích hợp vào nhiều hệ thống tổng đài AI, trợ lý ảo và robot tiếp tân – không chỉ tạo ra trải nghiệm mượt mà mà còn góp phần xây dựng “giọng nói thương hiệu” cho doanh nghiệp. Dù đạt được nhiều bước tiến, Text to Speech vẫn đang đối mặt với các thách thức như: truyền tải cảm xúc chân thực trong hội thoại dài, thích ứng theo ngữ cảnh thay đổi, giảm độ trễ xử lý. Hành trình phát triển Text to Speech cũng gặp nhiều thách thức lớn, như truyền tải cảm xúc đa dạng, thích ứng theo ngữ cảnh hội thoại, hoặc tối ưu tốc độ phản hồi real-time vẫn còn là bài toán mở. Bên cạnh đó, nguy cơ bị lợi dụng để deepfake giọng nói cũng đặt ra yêu cầu về các chuẩn mực đạo đức và công nghệ đối ứng đi kèm.