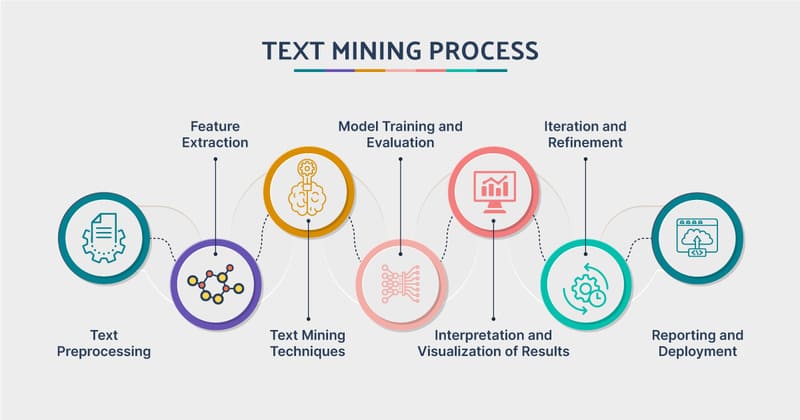
Text Mining, hay còn gọi là khai thác văn bản, là quá trình chuyển đổi văn bản phi cấu trúc thành định dạng có cấu trúc nhằm xác định các mẫu có ý nghĩa và khám phá các khái niệm, xu hướng và các mối quan hệ ẩn giữa dữ liệu. Trong thế giới số hóa hiện nay, khi khoảng 80% dữ liệu toàn cầu tồn tại dưới dạng phi cấu trúc, text mining đã trở thành công cụ vô cùng giá trị đối với các tổ chức.
Trong bài viết này, FPT.AI sẽ làm rõ khái niệm Text Mining, phân biệt nó với Data Mining và Text Analytics, giới thiệu các kỹ thuật Text Mining phổ biến cũng như những ứng dụng thiết thực của công nghệ này trong nhiều lĩnh vực, từ dịch vụ khách hàng, quản lý rủi ro đến chăm sóc sức khỏe và bảo mật thông tin.
Text Mining là gì?
Text Mining, còn được gọi là khai thác văn bản, là quá trình chuyển đổi văn bản phi cấu trúc thành định dạng có cấu trúc để xác định các mẫu có ý nghĩa và những hiểu biết mới. Đây là một công nghệ quan trọng cho phép phân tích các tài liệu văn bản khổng lồ để nắm bắt các khái niệm, xu hướng chính và các mối quan hệ ẩn giữa dữ liệu.
Trong thực tế, văn bản là một trong những loại dữ liệu phổ biến nhất trong cơ sở dữ liệu hiện nay. Tùy thuộc vào cơ sở dữ liệu, dữ liệu văn bản có thể được phân loại thành ba nhóm chính.
- Dữ liệu có cấu trúc (Structured Data): Dữ liệu đã được chuẩn hóa thành định dạng bảng với nhiều hàng và cột, chẳng hạn như tên, địa chỉ và số điện thoại. Structured Data tạo sự tiện lợi cho quá trình lưu trữ, xử lý, phân tích và áp dụng thuật toán Machine Learning,
- Dữ liệu phi cấu trúc (Unstructured Data): Unstructured Data không có định dạng dữ liệu được xác định trước, bao gồm văn bản từ các nguồn như mạng xã hội hoặc đánh giá sản phẩm hoặc các định dạng phương tiện như video và tệp âm thanh.
- Dữ liệu bán cấu trúc (Semi-structured Data): Dữ liệu bán cấu trúc là sự kết hợp giữa định dạng dữ liệu có cấu trúc và phi cấu trúc, gồm các tệp XML, JSON và HTML.
Điều đáng chú ý là khoảng 80% dữ liệu trên thế giới tồn tại ở dạng phi cấu trúc. Điều này làm cho Text Mining trở thành một thực tiễn cực kỳ có giá trị trong các tổ chức. Các công cụ Text Mining và kỹ thuật xử lý ngôn ngữ tự nhiên (NLP), như Information Extraction, cho phép chúng ta chuyển đổi các tài liệu phi cấu trúc thành định dạng có cấu trúc để phân tích và tạo ra những hiểu biết chất lượng cao.
Để thực hiện Text Mining hiệu quả, các chuyên gia áp dụng nhiều kỹ thuật phân tích nâng cao như Naïve Bayes, Support Vector Machines (SVM) và các thuật toán Deep Learning. Những công cụ này giúp các công ty có thể khám phá và khai thác giá trị từ khối lượng dữ liệu văn bản khổng lồ mà họ sở hữu, cải thiện việc ra quyết định cũng như đạt được các kết quả kinh doanh tốt hơn.
>>> XEM THÊM: OCR là gì? Text Mining được ứng dụng trong công nghệ OCR tiếng Việt như thế nào?
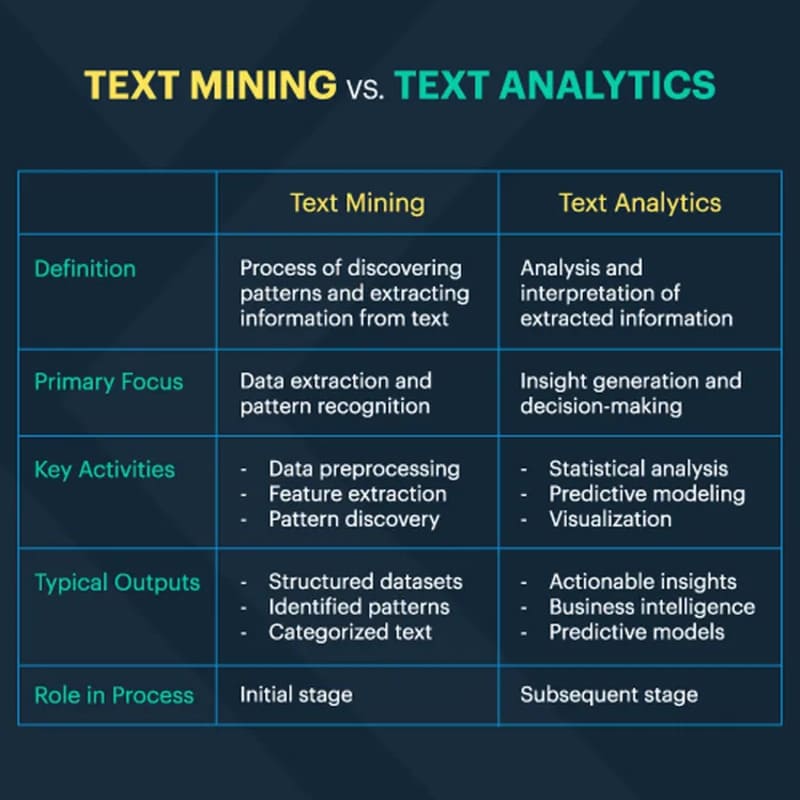
So sánh Text Mining vs Text Analytics
Tuy thường được sử dụng thay thế nhau trong nhiều cuộc trò chuyện, Text Mining và Text Analytics có những khác biệt đáng kể. Về cơ bản, cả Text Mining và Text Analytics đều tập trung vào việc xác định các mẫu và xu hướng trong dữ liệu văn bản phi cấu trúc thông qua việc áp dụng các phương pháp Machine Learning, thống kê và ngôn ngữ học. Tuy nhiên, Text Analytics đi xa hơn bằng cách sử dụng các dữ liệu đã được cấu trúc này để rút ra những hiểu biết định lượng sâu sắc, có tính phân tích cao.
Ngoài ra, Text Analytics có khả năng truyền đạt kết quả phân tích đến đối tượng rộng hơn thông qua các kỹ thuật Visualization dữ liệu. Các biểu đồ, đồ thị và các hình thức trực quan hóa khác giúp người dùng không chuyên về kỹ thuật có thể hiểu được các xu hướng và mẫu phức tạp được phát hiện từ dữ liệu văn bản. Điều này làm cho Text Analytics trở thành một công cụ mạnh mẽ trong việc khám phá thông tin và chia sẻ những phát hiện này với các bên liên quan khác nhau, từ đó hỗ trợ quá trình ra quyết định dựa trên dữ liệu.
>>> XEM THÊM: Text Preprocessing – Kỹ thuật tiền xử lý văn bản trong NLP (Natural Language Processing)
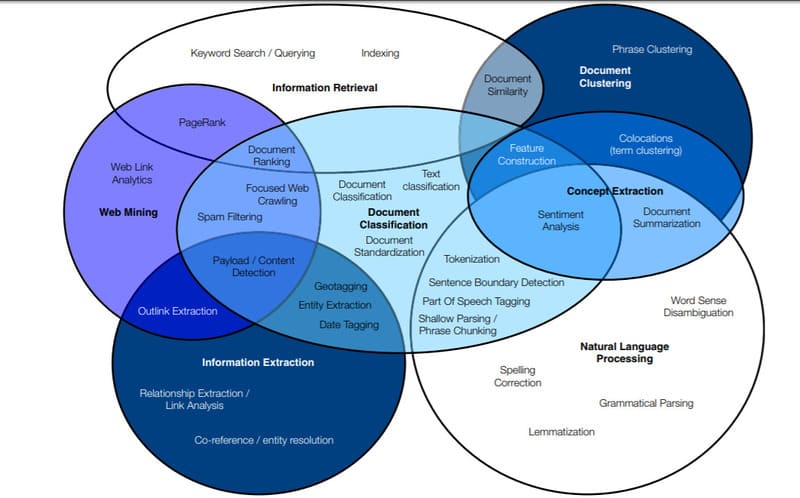
Các kỹ thuật Text Mining phổ biến
Các kỹ thuật Text Mining phổ biến bao gồm:
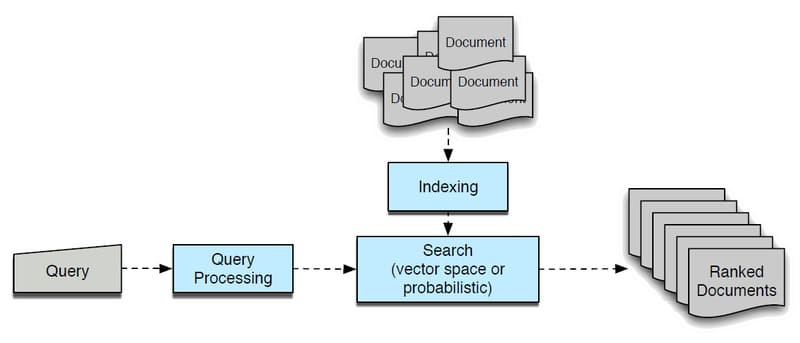
Information Retrieval
Information Retrieval (IR) là quá trình trả về thông tin hoặc tài liệu liên quan dựa trên một tập hợp các truy vấn hoặc cụm từ được xác định trước. Đây là nền tảng cốt lõi cho các công cụ tìm kiếm phổ biến như Google và hệ thống danh mục thư viện, nơi người dùng có thể tìm kiếm thông tin mà không cần biết chính xác vị trí lưu trữ của nó.
Hệ thống IR sử dụng thuật toán tinh vi để theo dõi hành vi người dùng và xác định dữ liệu liên quan đến truy vấn. Quá trình này không chỉ đơn thuần là tìm kiếm sự trùng khớp chính xác mà còn phải hiểu được ngữ cảnh và ý định của người dùng để cung cấp kết quả phù hợp nhất.
Để tăng hiệu quả tìm kiếm, IR sử dụng 2 kỹ thuật xử lý ngôn ngữ tự nhiên chính:
- Tokenization: Đây là quá trình chia văn bản dài thành các câu và từ được gọi là “tokens”. Sau đó, chúng được sử dụng trong các mô hình, như bag-of-words, cho các nhiệm vụ phân cụm văn bản và so khớp tài liệu.
- Stemming: Đây là quá trình tách các tiền tố và hậu tố khỏi các từ để có được dạng và nghĩa của từ gốc. Ví dụ, các từ “running”, “runner” và “runs” đều có thể được quy về từ gốc “run”. Kỹ thuật này cải thiện hiệu suất của information retrieval bằng cách giảm kích thước của các tệp indexing.
>>> XEM THÊM: NLU là gì? So sánh hiểu ngôn ngữ tự nhiên NLU vs NLP, NLG
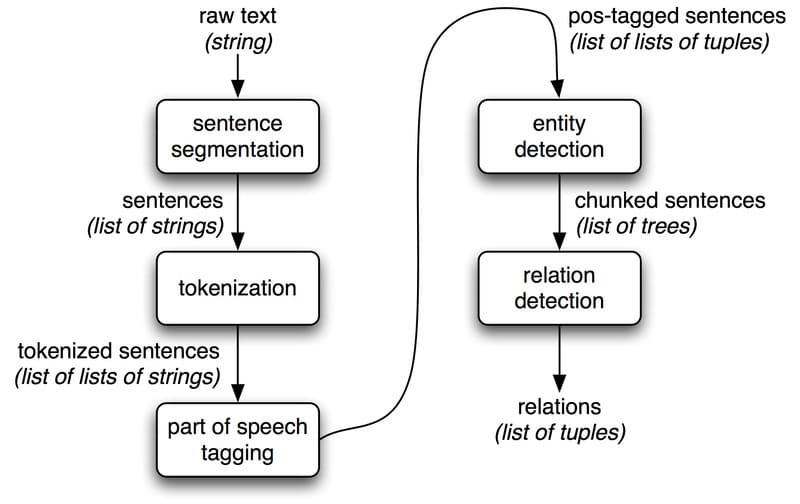
Natural language processing (NLP)
Natural language processing, phát triển từ computational linguistics, sử dụng các phương pháp từ nhiều ngành khác nhau, chẳng hạn như khoa học máy tính, trí tuệ nhân tạo, ngôn ngữ học và khoa học dữ liệu.Mục tiêu chính của NLP là tạo ra khả năng hiểu và xử lý ngôn ngữ của con người cho cho máy tính, bao gồm cả hình thức viết và lời nói, thông qua việc phân tích cấu trúc câu và ngữ pháp.
Các tác vụ NLP phổ biến bao gồm:
- Summarization: Kỹ thuật cung cấp bản tóm tắt súc tích, mạch lạc về các điểm chính trong các đoạn văn bản dài.
- Part-of-Speech (PoS) tagging: Kỹ thuật gán một thẻ cho mỗi token trong tài liệu dựa trên loại từ (danh từ, động từ, tính từ,…), giúp mô hình ngôn ngữ phân tích ngữ nghĩa trên văn bản phi cấu trúc.
- Text categorization: Text categorization, còn được gọi là text classification, chịu trách nhiệm phân tích các tài liệu văn bản và phân loại chúng dựa trên các chủ đề hoặc danh mục được xác định trước. Nhiệm vụ phụ này đặc biệt hữu ích khi phân loại các từ đồng nghĩa và các từ viết tắt.
- Sentiment Analysis: Nhiệm vụ phát hiện tình cảm tích cực hoặc tiêu cực từ các nguồn dữ liệu nội bộ hoặc bên ngoài, cho phép bạn theo dõi những thay đổi trong thái độ của khách hàng theo thời gian. Nó thường được sử dụng để cung cấp thông tin về nhận thức về thương hiệu, sản phẩm và dịch vụ, thúc đẩy sự tương tác giữa doanh nghiệp – khách hàng và cải thiện quy trình và trải nghiệm người dùng.
>>> XEM THÊM: Natural Language Generation là gì? 3 lợi ích chính của NLG
Information Extraction
Information Extraction (IE) là quá trình trích xuất thông tin có cấu trúc từ các văn bản phi cấu trúc hoặc tự do. Mục tiêu chính của IE là đưa ra các phần dữ liệu liên quan khi tìm kiếm qua các tài liệu khác nhau, đồng thời lưu trữ thông tin về thực thể, thuộc tính và mối quan hệ giữa chúng trong cơ sở dữ liệu để có thể sử dụng sau này. Các nhiệm vụ information extraction phổ biến bao gồm:
- Feature selection, hay attribute selection, là quá trình chọn các tính năng (chiều) quan trọng để đóng góp nhiều nhất vào đầu ra của mô hình phân tích dự đoán.
- Feature extraction là quá trình chọn một tập hợp con của các tính năng để cải thiện độ chính xác của nhiệm vụ phân loại. Điều này đặc biệt quan trọng đối với dimensionality reduction.
- Named-entity recognition (NER) còn được gọi là entity identification hoặc entity extraction, nhằm mục đích tìm và phân loại các thực thể cụ thể trong văn bản, chẳng hạn như tên hoặc địa điểm. Ví dụ, NER xác định “California” là một địa điểm và “Mary” là tên của một người phụ nữ.
>>> XEM THÊM: Xu hướng ứng dụng công nghệ OCR trong ngành bảo hiểm tại Việt Nam
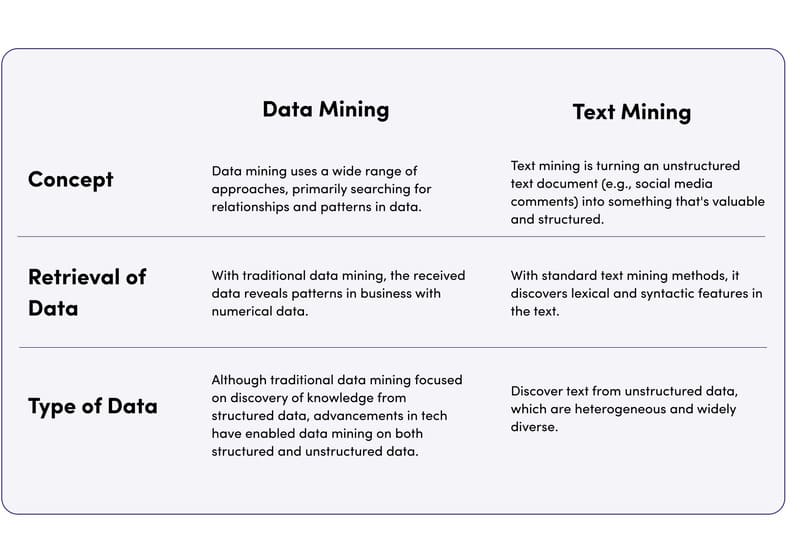
Data Mining
Data Mining là quá trình xác định các mẫu và trích xuất những hiểu biết hữu ích từ các tập dữ liệu lớn. Data mining đánh giá cả dữ liệu có cấu trúc và phi cấu trúc, gồm số liệu, hình ảnh, âm thanh và đa phương tiện, để xác định thông tin mới, thường được sử dụng để phân tích hành vi của người tiêu dùng trong marketing và bán hàng nhằm đưa ra các quyết định chiến lược.
Text mining về cơ bản là một lĩnh vực con của Data Mining, tập trung vào việc đưa cấu trúc vào dữ liệu văn bản phi cấu trúc như bài viết, email, trang web và tài liệu học thuật. Text Mining sử dụng các kỹ thuật xử lý ngôn ngữ tự nhiên (NLP) để hiểu ngữ nghĩa và trích xuất tri thức từ văn bản, biến đổi dữ liệu văn bản thành thông tin có giá trị và có thể phân tích được.
Các kỹ thuật như phân loại văn bản, phân tích ý kiến, và trích xuất thông tin đều là những hình thức của Data Mining nhưng được áp dụng đặc biệt trong phạm vi phân tích dữ liệu văn bản.
>>> XEM THÊM: Top 6 công cụ AI phân tích dữ liệu hàng đầu hiện nay
Ứng dụng của Text Mining
Phần mềm text mining đã tác động đến cách thức hoạt động của nhiều ngành công nghiệp, cho phép họ cải thiện trải nghiệm người dùng sản phẩm cũng như đưa ra quyết định kinh doanh nhanh hơn và tốt hơn. Một số trường hợp sử dụng bao gồm:
- Dịch vụ khách hàng: Khi kết hợp với các công cụ text analytics, các hệ thống phản hồi, chẳng hạn như chatbot, khảo sát khách hàng, NPS (Net-Promoter Scores), đánh giá trực tuyến, vé hỗ trợ và hồ sơ mạng xã hội, các công ty có thể cải thiện trải nghiệm khách hàng một cách nhanh chóng. Bằng cách phân tích văn bản và cảm xúc (Sentiment Analysis), các công ty có thể xác định và ưu tiên giải quyết các điểm đau chính của khách hàng, phản hồi các vấn đề khẩn cấp theo thời gian thực và nâng cao sự hài lòng của khách hàng.
- Quản lý rủi ro: Text mining cũng cung cấp những hiểu biết quý giá về xu hướng ngành và thị trường tài chính thông qua việc theo dõi thay đổi cảm xúc và trích xuất thông tin từ báo cáo của nhà phân tích cũng như các tài liệu chuyên môn. Các tổ chức ngân hàng đặc biệt hưởng lợi từ những dữ liệu này khi xem xét đầu tư kinh doanh trên nhiều lĩnh vực khác nhau. CIBC và EquBot là những ví dụ về tổ chức đang sử dụng text analytics để giảm thiểu rủi ro trong hoạt động kinh doanh của họ.
- Bảo trì: Text mining tạo ra bức tranh toàn diện về hoạt động và chức năng của sản phẩm cùng máy móc. Theo thời gian, việc phân tích văn bản tự động hóa quá trình ra quyết định bằng cách phát hiện các mẫu tương quan với các vấn đề, từ đó xây dựng các thủ tục bảo trì phòng ngừa và phản ứng hiệu quả. Text analytics giúp các chuyên gia bảo trì nhanh chóng xác định nguyên nhân gốc rễ của các thách thức và sự cố, nâng cao hiệu quả và giảm thiểu thời gian chết của hệ thống.
- Chăm sóc sức khỏe: Các kỹ thuật text mining ngày càng có giá trị đối với các nhà nghiên cứu trong lĩnh vực y sinh, đặc biệt là để phân cụm thông tin. Việc điều tra thủ công về nghiên cứu y tế có thể tốn kém và tốn thời gian; text mining cung cấp một phương pháp tự động hóa để trích xuất thông tin có giá trị từ tài liệu y học.
- Lọc thư rác: Text mining cung cấp phương pháp hiệu quả để nhận diện và loại bỏ các email không mong muốn khỏi hộp thư đến của người dùng. Điều này không chỉ cải thiện trải nghiệm người dùng tổng thể mà còn giảm thiểu rủi ro tấn công mạng, đặc biệt khi thư rác thường được tin tặc sử dụng như điểm khởi đầu để lây nhiễm malware vào hệ thống máy tính của người dùng cuối.
Tóm lại, là một nhánh chuyên biệt của data mining, text mining cung cấp các phương pháp và công cụ mạnh mẽ để biến đổi thông tin phi cấu trúc thành dữ liệu có cấu trúc, giúp các tổ chức cải thiện trải nghiệm người dùng, đưa ra quyết định nhanh chóng và chính xác hơn, đồng thời thúc đẩy hiệu quả hoạt động tổng thể. Khi thế giới tiếp tục sản sinh ra lượng dữ liệu văn bản khổng lồ, text mining sẽ ngày càng trở nên quan trọng, định hình cách thức các tổ chức khai thác và tận dụng thông tin quý giá từ nguồn dữ liệu dồi dào này.
>>> XEM THÊM: