Recurrent Neural Network (RNN) là một thuật toán học sâu mạnh mẽ, được sử dụng rộng rãi trong các bài toán xử lý dữ liệu tuần tự như ngôn ngữ tự nhiên, dự báo chuỗi thời gian và nhận dạng giọng nói. Trong bài viết này, FPT.AI sẽ chia sẻ chi tiết về khái niệm RNN, cách thức hoạt động, các loại RNN phổ biến cùng với những ưu điểm và hạn chế mà RNN mang lại trong các ứng dụng thực tiễn.
Recurrent Neural Network là gì?
Recurrent Neural Network (RNN) là một dạng mạng nơ-ron sâu (Deep Neural Network) được thiết kế để xử lý dữ liệu tuần tự hoặc chuỗi thời gian. Mô hình này cho phép hệ thống học mối quan hệ giữa các bước dữ liệu liên tiếp và đưa ra dự đoán dựa trên ngữ cảnh trước đó.
RNN được ứng dụng rộng rãi trong các bài toán phụ thuộc thứ tự và thời gian như dự báo mực nước lũ, dịch ngôn ngữ, xử lý ngôn ngữ tự nhiên (NLP), phân tích cảm xúc (Sentiment Analysis), nhận dạng giọng nói và tạo mô tả hình ảnh.
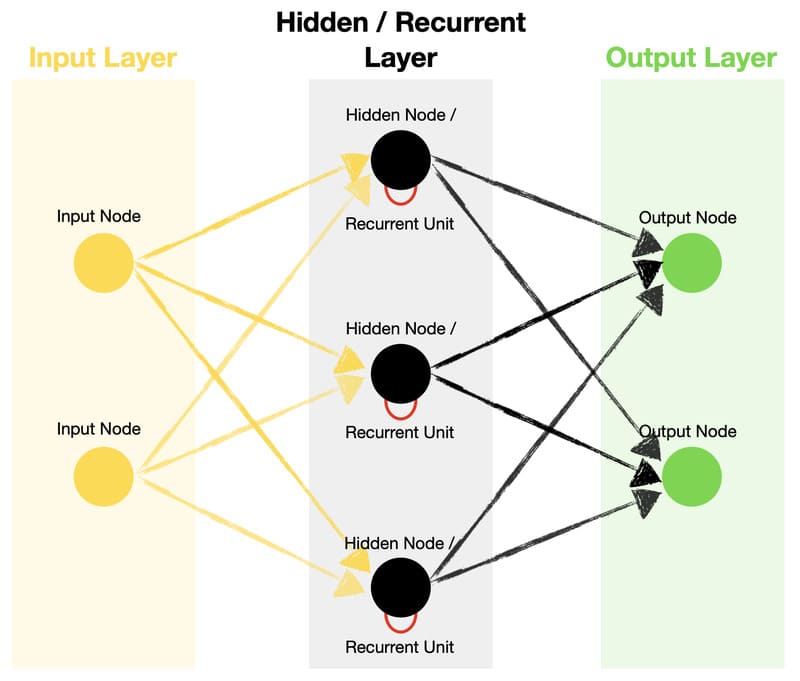
Cơ chế hoạt động của RNN như thế nào?
RNN vận hành dựa trên ba thành phần chính: lớp đầu vào, lớp ẩn và lớp đầu ra. Lớp đầu vào tiếp nhận dữ liệu tuần tự, lớp ẩn xử lý và duy trì trạng thái thông tin từ các bước trước đó, còn lớp đầu ra sẽ tạo ra kết quả dự đoán. Nhờ cơ chế hồi tiếp, RNN có thể ghi nhớ ngữ cảnh theo thời gian và khai thác mối liên hệ giữa các phần tử trong chuỗi dữ liệu.
Lớp ẩn là trung tâm xử lý của RNN, nơi lưu trữ và cập nhật thông tin theo từng bước thời gian thông qua các trọng số có thể học được. Tuy nhiên, với chuỗi dữ liệu dài, RNN truyền thống dễ gặp hiện tượng Vanishing Gradient, khiến việc học thông tin dài hạn kém hiệu quả. Để khắc phục, các kiến trúc mở rộng như LSTM và GRU được phát triển nhằm kiểm soát luồng thông tin tốt hơn và tăng khả năng ghi nhớ dài hạn.
Quá trình đào tạo: RNN được huấn luyện bằng cách tối ưu các trọng số dựa trên sai số giữa kết quả dự đoán và dữ liệu thực tế. Kỹ thuật Backpropagation Through Time (BPTT) được sử dụng để lan truyền sai số ngược qua các bước thời gian, giúp mô hình xác định và điều chỉnh những trạng thái ẩn gây lỗi. Nhờ đó, RNN dần cải thiện khả năng học và dự đoán trên dữ liệu tuần tự.
Ví dụ, khi xử lý thành ngữ “feeling under the weather”, RNN phân tích ngữ cảnh theo từng bước thời gian. Thông tin từ từ “feeling” được lưu vào trạng thái ẩn, sau đó được cập nhật dần khi mô hình đọc các từ “under”, “the” và “weather”. Nhờ cơ chế ghi nhớ ngữ cảnh liên tục, RNN hiểu đây là một cụm mang nghĩa “cảm thấy không khỏe”, thay vì diễn giải theo nghĩa đen liên quan đến thời tiết.
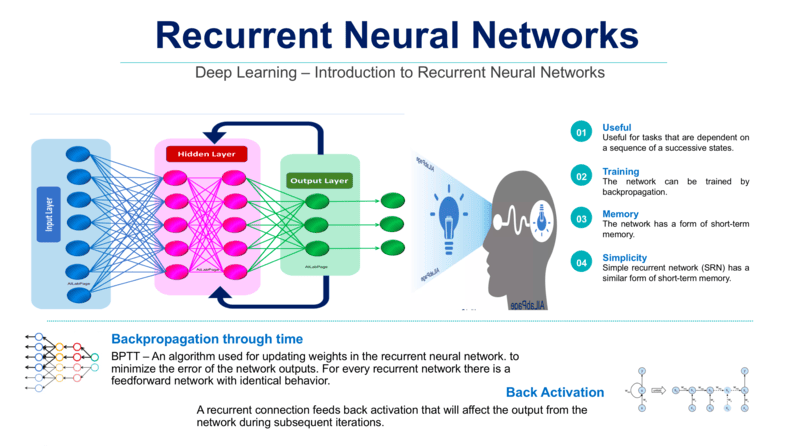
Các hàm kích hoạt phổ biến trong Recurrent Neural Networks
Hàm kích hoạt (Activation Function) là hàm toán học được áp dụng lên đầu ra của mỗi neuron trong RNN nhằm đưa tính phi tuyến vào mô hình, giúp mạng học và biểu diễn các mối quan hệ phức tạp trong dữ liệu. Nếu thiếu hàm kích hoạt, RNN chỉ thực hiện các phép biến đổi tuyến tính và khó xử lý các bài toán như NLP, sentiment analysis (phân tích cảm xúc) hay chuỗi thời gian.
Bên cạnh đó, hàm kích hoạt còn giúp kiểm soát giá trị đầu ra của neuron trong một khoảng xác định (như 0 – 1 hoặc -1 đến 1), hạn chế hiện tượng giá trị bùng nổ hoặc tiêu biến khi huấn luyện. Trong RNN, hàm kích hoạt được áp dụng ở mỗi bước thời gian để điều chỉnh cách trạng thái ẩn được cập nhật, ảnh hưởng trực tiếp đến khả năng ghi nhớ và xử lý thông tin tuần tự của mô hình.
Các hàm kích hoạt phổ biến bao gồm:
- Sigmoid Function: Được sử dụng để biểu diễn đầu ra dưới dạng xác suất và làm hàm điều khiển trong các cơ chế cổng, giúp quyết định lượng thông tin được giữ lại hoặc loại bỏ. Tuy nhiên, do đạo hàm nhỏ ở các vùng bão hòa, Sigmoid dễ gây hiện tượng Vanishing Gradient, khiến hiệu quả huấn luyện giảm khi áp dụng cho các mạng nơ-ron sâu.
- Hàm Tanh (Hyperbolic Tangent): Được ưa chuộng hơn Sigmoid Function vì tạo ra các giá trị tập trung quanh 0, giúp dòng gradient chảy tốt hơn và hỗ trợ việc học các phụ thuộc dài hạn.
- ReLU (Rectified Linear Unit): Giúp tăng tốc quá trình học nhờ hàm phi tuyến đơn giản, nhưng có thể dẫn đến exploding gradient do đầu ra không bị giới hạn. Các biến thể như Leaky ReLU hoặc PReLU được phát triển để khắc phục nhược điểm này.
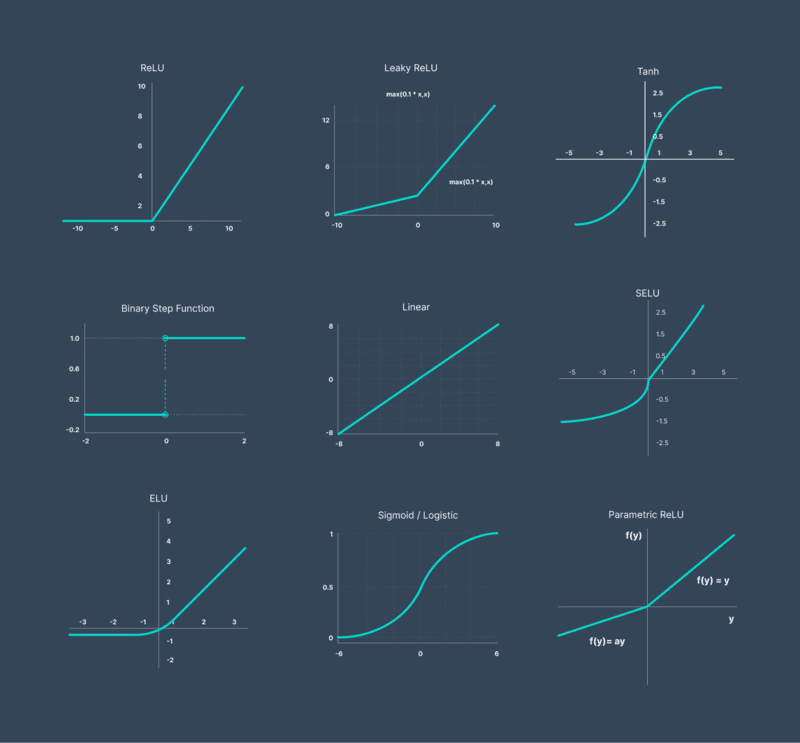
Mạng nơ-ron hồi quy RNN có những loại nào?
Mạng nơ-ron hồi quy có thể được phân loại theo cách tổ chức dữ liệu đầu vào và đầu ra trong quá trình xử lý chuỗi. Mỗi loại RNN phổ biến phù hợp với một dạng bài toán tuần tự khác nhau, tùy thuộc vào mối quan hệ giữa dữ liệu đầu vào và kết quả đầu ra.
Mô hình One-to-One
One-to-One là dạng RNN cơ bản nhất, trong đó mỗi dữ liệu đầu vào chỉ tạo ra một kết quả đầu ra tương ứng. Mô hình này có cấu trúc tương tự mạng nơ-ron truyền thẳng và thường được áp dụng cho các bài toán không yêu cầu xử lý chuỗi, như phân loại hình ảnh hoặc dữ liệu độc lập.
Mô hình One-to-Many
One-to-Many là mô hình RNN có một đầu vào duy nhất nhưng sinh ra chuỗi đầu ra liên tiếp. Cấu trúc này thường được dùng trong các bài toán tạo nội dung như sinh phụ đề cho hình ảnh, tạo văn bản hoặc sáng tác nhạc, khi một dữ kiện ban đầu được mở rộng thành nhiều kết quả theo thời gian.
Mô hình Many-to-One
Many-to-One là mô hình RNN tiếp nhận chuỗi dữ liệu đầu vào và tạo ra một đầu ra duy nhất. Cấu trúc này phù hợp với các bài toán tổng hợp thông tin như phân tích cảm xúc hoặc phân loại văn bản, khi toàn bộ nội dung đầu vào được dùng để đưa ra một kết luận cuối cùng.
Mô hình Many-to-Many
Many-to-Many là một mô hình RNN xử lý chuỗi dữ liệu đầu vào và tạo ra chuỗi đầu ra tương ứng. Kiến trúc này thường được áp dụng trong các bài toán như dịch máy hoặc gán nhãn chuỗi, nơi mỗi phần tử đầu vào được ánh xạ sang một hoặc nhiều đầu ra phù hợp theo ngữ cảnh.
Recurrent Neural Networks có những loại biến thể nào?
Khác với mạng Feedforward chỉ xử lý quan hệ đầu vào – đầu ra cố định, RNN có khả năng làm việc với chuỗi dữ liệu có độ dài linh hoạt. Nhờ đó, RNN được ứng dụng rộng rãi trong các bài toán như tạo nhạc, phân tích cảm xúc và dịch máy. Dưới đây là những dạng RNN phổ biến hiện nay:
Vanilla RNN
Vanilla RNN là dạng đơn giản nhất của mạng nơ-ron hồi quy, sử dụng một lớp ẩn với các trọng số được chia sẻ theo thời gian. Mô hình có thể học được quan hệ ngắn hạn trong chuỗi dữ liệu, nhưng hiệu quả giảm khi xử lý chuỗi dài do hiện tượng suy giảm gradient.
Standard Recurrent Neural Networks
Đây là dạng RNN tiêu chuẩn, trong đó đầu ra ở mỗi bước thời gian được tạo dựa trên đầu vào hiện tại và trạng thái ẩn của bước trước. Mô hình này dễ gặp hiện tượng suy giảm gradient, nên khó học các phụ thuộc dài hạn và chỉ phù hợp với các bài toán có quan hệ ngắn hạn. Standard RNN thường được dùng cho những tác vụ xử lý chuỗi đơn giản hoặc dữ liệu thời gian thực, như dự đoán giá trị tiếp theo hoặc phát hiện bất thường trong dữ liệu cảm biến ngắn hạn.
Bidirectional Recurrent Neural Networks (BRNNs)
Bidirectional RNN (BRNN) mở rộng RNN truyền thống bằng cách xử lý chuỗi dữ liệu theo cả hai chiều: quá khứ – hiện tại và tương lai – hiện tại. Nhờ tận dụng đồng thời ngữ cảnh trước và sau, BRNN cho độ chính xác cao hơn trong các bài toán ngôn ngữ. Chẳng hạn, với cụm “feeling under the weather”, mô hình có thể hiểu đúng nghĩa của từ “under” khi đã biết từ kết thúc là “weather”.
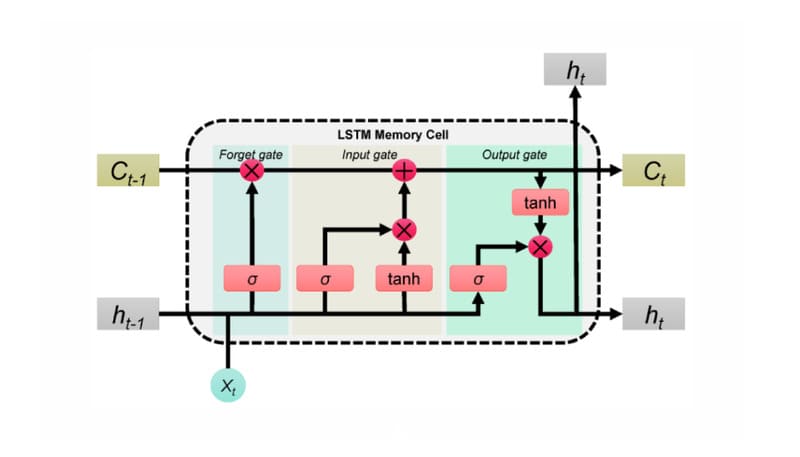
Long short-term memory (LSTM)
LSTM (Long Short-Term Memory) là một kiến trúc RNN phổ biến do Sepp Hochreiter và Jürgen Schmidhuber đề xuất, nhằm khắc phục hạn chế học phụ thuộc dài hạn và hiện tượng vanishing gradient của RNN truyền thống. Không giống Standard RNN vốn khó ghi nhớ thông tin ở xa, LSTM có thể duy trì và khai thác ngữ cảnh dài.
Ví dụ, trong chuỗi câu “Alice bị dị ứng với các loại hạt. Cô ấy không thể ăn bơ đậu phộng”, LSTM vẫn giữ được thông tin về “dị ứng hạt” để suy luận đúng ở câu sau, ngay cả khi khoảng cách ngữ cảnh lớn. Cơ chế này đạt được nhờ cấu trúc tế bào nhớ (cell state) và ba cổng điều khiển gồm input gate, forget gate và output gate, giúp chọn lọc thông tin cần lưu, loại bỏ dữ liệu không quan trọng và quyết định đầu ra phù hợp tại mỗi bước thời gian.
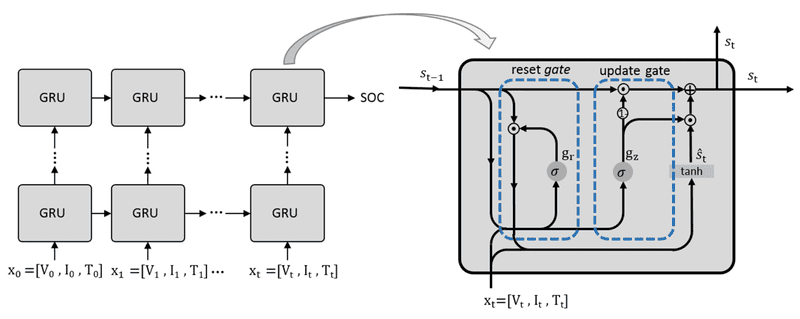
Gated recurrent units (GRUs)
GRU (Gated Recurrent Unit) được thiết kế để khắc phục hạn chế về ghi nhớ ngắn hạn của RNN nhưng có kiến trúc đơn giản hơn. GRU không sử dụng cell state riêng biệt mà làm việc trực tiếp trên hidden state, đồng thời chỉ dùng hai cổng là reset gate và update gate để kiểm soát thông tin cần giữ lại hoặc loại bỏ.
Nhờ giảm số lượng cổng và tham số, GRU có hiệu quả tính toán cao hơn, thời gian huấn luyện ngắn hơn so với LSTM. Vì vậy, mô hình này thường được ưu tiên trong các bài toán thời gian thực hoặc môi trường có tài nguyên tính toán hạn chế.
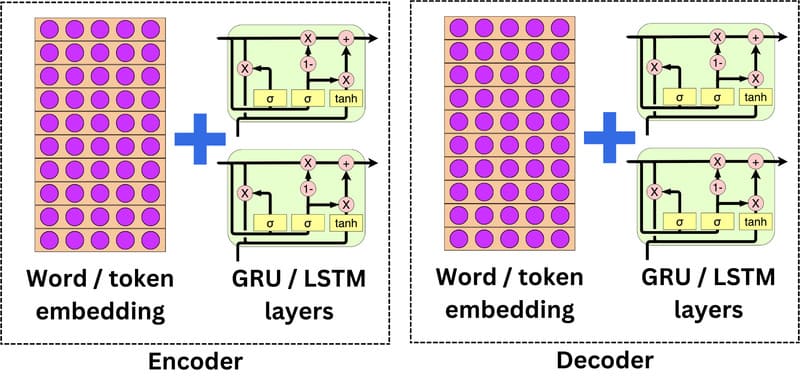
Encoder-decoder RNNs
Encoder-decoder RNNs thường được sử dụng cho các nhiệm vụ sequence-to-sequence, chẳng hạn như dịch máy (Machine Translation). Phần mã hóa (encoder) xử lý chuỗi đầu vào thành một vector có độ dài cố định (gọi là ngữ cảnh), và phần giải mã (decoder) sử dụng ngữ cảnh đó để tạo ra chuỗi đầu ra. Tuy nhiên, vector ngữ cảnh cố định có thể trở thành điểm nghẽn, đặc biệt với các chuỗi đầu vào dài.
Mạng nơ-ron hồi quy có ưu điểm gì?
RNN sở hữu nhiều ưu điểm nổi bật, giúp mô hình này trở thành giải pháp hiệu quả cho các bài toán học sâu liên quan đến dữ liệu tuần tự, cụ thể:
- Xử lý linh hoạt dữ liệu chuỗi: Phù hợp với nhiều dạng dữ liệu như văn bản, âm thanh và chuỗi thời gian.
- Phạm vi ứng dụng rộng: Được triển khai hiệu quả trong NLP, dịch máy, nhận dạng giọng nói và phân tích dữ liệu theo thời gian.
- Nắm bắt ngữ cảnh theo thời gian: Có khả năng học mối quan hệ giữa các phần tử trong chuỗi, giúp hiểu ngữ cảnh tốt hơn.
- Khả năng ghi nhớ được cải thiện: Lưu trữ thông tin từ các bước trước, đặc biệt hiệu quả với các kiến trúc như LSTM và GRU.
- Độ chính xác cao trong bài toán tuần tự: Khai thác thông tin lịch sử để nâng cao chất lượng dự đoán.
Hạn chế của Recurrent Neural Networks ra sao?
Dù hiệu quả trong xử lý dữ liệu tuần tự nhưng RNN vẫn tồn tại một số hạn chế đáng chú ý:
- Huấn luyện phức tạp: Cơ chế hồi quy theo thời gian khiến quá trình đào tạo tốn nhiều tài nguyên và khó tối ưu hơn so với mạng nơ-ron truyền thống.
- Vanishing Gradient: Khi làm việc với chuỗi dài, gradient dễ suy giảm trong quá trình lan truyền ngược, làm giảm khả năng học thông tin ở các bước thời gian xa.
- Hạn chế ghi nhớ dài hạn: RNN thường chỉ nắm bắt tốt ngữ cảnh ngắn hạn, trong khi thông tin dài hạn dễ bị mất, ảnh hưởng đến hiệu suất với chuỗi dữ liệu lớn.
RNN có những ứng dụng phổ biến nào?
RNN được ứng dụng rộng rãi trong các bài toán xử lý dữ liệu tuần tự và phụ thuộc thời gian, tiêu biểu như:
- Dự đoán chuỗi thời gian: Phân tích và dự báo các dữ liệu biến động theo thời gian như giá cổ phiếu, nhu cầu thị trường hoặc xu hướng khí hậu.
- Xử lý ngôn ngữ tự nhiên (NLP): Hỗ trợ các tác vụ như dịch máy, sinh văn bản, tóm tắt nội dung và phân tích cảm xúc nhờ khả năng nắm bắt ngữ cảnh.
- Nhận diện giọng nói: Chuyển đổi tín hiệu âm thanh thành văn bản, nâng cao độ chính xác cho trợ lý ảo và tìm kiếm bằng giọng nói.
- Xử lý hình ảnh và video: Ứng dụng trong phân tích video, mô tả hình ảnh, nhận diện hành động và tạo phụ đề tự động thông qua xử lý dữ liệu theo trình tự thời gian.

Recurrent Neural Networks so với các mạng nơ-ron khác có gì khác nhau?
Nhờ được thiết kế chuyên biệt cho dữ liệu tuần tự, RNN sở hữu những đặc điểm khác biệt rõ rệt so với các kiến trúc mạng nơ-ron truyền thống, cụ thể:
RNN và Feedforward Neural Network (FNN): Cả RNN và FNN đều là mạng nơ-ron nhân tạo, tuy nhiên FNN chỉ xử lý dữ liệu theo một chiều từ đầu vào đến đầu ra và không có khả năng ghi nhớ thông tin trước đó. Ngược lại, RNN có khả năng lưu trữ trạng thái từ các bước trước, giúp mô hình hiểu ngữ cảnh. Ví dụ, trong câu “Tôi thích uống cà phê vì nó giúp tôi tỉnh táo”, RNN có thể liên kết “cà phê” với “tỉnh táo”, trong khi FNN xử lý các từ một cách rời rạc và không nắm được mối quan hệ này.
RNN và Convolutional Neural Network (CNN): CNN và RNN phục vụ các mục tiêu khác nhau. CNN được tối ưu cho dữ liệu không gian như hình ảnh và video, thông qua các lớp tích chập để trích xuất đặc trưng. Trong khi đó, RNN tập trung vào dữ liệu tuần tự, cho phép mô hình học được các mối quan hệ theo thời gian trong văn bản, giọng nói và chuỗi thời gian.
Tóm lại, Recurrent Neural Network (RNN) là một công nghệ mạnh mẽ trong lĩnh vực học máy, đặc biệt hữu ích trong các nhiệm vụ xử lý dữ liệu tuần tự. Tuy sự xuất hiện của các mô hình transformer như BERT và GPT đang dần chiếm ưu thế trong một số bài toán nhưng RNN vẫn giữ được vị trí quan trọng trong các nhiệm vụ yêu cầu bộ nhớ và xử lý tuần tự hiện nay.