NER (Named Entity Recognition – Nhận dạng thực thể có tên) là một kỹ thuật cốt lõi trong Xử lý ngôn ngữ tự nhiên (NLP), cho phép hệ thống tự động xác định và phân loại các thực thể xuất hiện trong văn bản, như tên người, tổ chức, địa điểm, thời gian và nhiều nhóm thông tin khác. Trong bài viết này, FPT.AI sẽ giới thiệu NER là gì, các loại thực thể phổ biến, các phương pháp triển khai, công cụ hỗ trợ, ứng dụng thực tiễn cùng những thách thức và xu hướng phát triển trong thời gian tới.
Named Entity Recognition – NER là gì?
NER – Named Entity Recognition hay nhận dạng thực thể có tên là một kỹ thuật trong xử lý ngôn ngữ tự nhiên (NLP), dùng để trích xuất và phân loại các thực thể quan trọng trong văn bản như tên người, địa điểm, tổ chức, thời gian. NER được ứng dụng rộng rãi trong các hệ thống trí tuệ nhân tạo (AI), dựa trên Machine Learning (học máy), Deep Learning (học sâu) và mạng nơ-ron nhân tạo, đóng vai trò nền tảng cho chatbot, công cụ tìm kiếm, phân tích cảm xúc và khai thác thông tin.
Thuật ngữ NER lần đầu được chuẩn hóa tại Hội nghị Message Understanding Conference 6 (MUC-6), nhằm đơn giản hóa việc trích xuất thông tin từ dữ liệu văn bản phi cấu trúc. Từ thời điểm đó đến hiện nay, NER liên tục phát triển và hoàn thiện nhờ những tiến bộ nhanh chóng của học máy và học sâu.
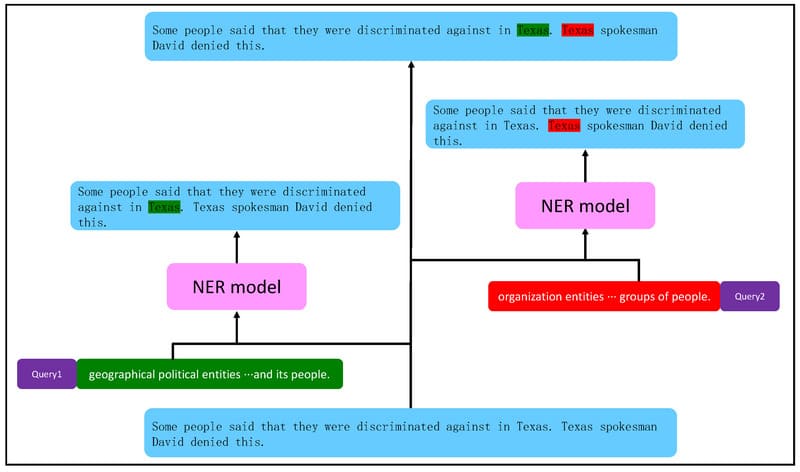
NER có những loại thực thể phổ biến nào?
Về cơ bản, NER là quá trình lấy một chuỗi văn bản (như một câu, đoạn văn hoặc toàn bộ tài liệu), nhận diện và phân loại các thực thể tham chiếu thành những danh mục cụ thể. Một số danh mục thực thể phổ biến nhất trong NER bao gồm:
- Người (PER): Nhận diện danh tính cá nhân, gồm tên đầy đủ, tên đệm, tên họ, biệt danh, chức danh và danh hiệu. Ví dụ: Barack Obama, Giáo sư Marie Curie,…
- Tổ chức (ORG): Xác định công ty, tập đoàn, cơ quan chính phủ, hiệp hội và các nhóm có tổ chức. Ví dụ: Microsoft, Tổ chức Lương thực và Nông nghiệp Liên Hợp Quốc,…
- Vị trí (LOC): Nhận diện các vị trí địa lý như quốc gia, thành phố, tỉnh, địa danh tự nhiên và các điểm tham chiếu không gian. Ví dụ: Paris, Himalaya,…
- Ngày (DATE): Trích xuất các biểu thức về ngày tháng trong nhiều định dạng và cách diễn đạt khác nhau. Ví dụ: cuộc họp sẽ diễn ra vào ngày 15/01/2026, báo cáo này được hoàn thành vào tuần trước,…
- Thời gian (TIME): Nhận diện các biểu thức liên quan đến thời điểm cụ thể trong ngày. Ví dụ: 8:30 sáng, giữa trưa,…
- Số lượng (QUANTITY): Xác định các giá trị đo lường kèm đơn vị. Ví dụ: 25 kilometer, nửa tá,…
- Phần trăm (PERCENT): Nhận diện các biểu thức biểu thị tỷ lệ phần trăm. Ví dụ: 75%, một phần tư,…
- Tiền tệ (MONEY): Trích xuất các giá trị tiền tệ và đơn vị tiền. Ví dụ: 1.000 đồng, 5 triệu euro, €50,…
- Khác (MISC): Danh mục tổng hợp cho các thực thể không thuộc các loại tiêu chuẩn, thường gồm sản phẩm, sự kiện, tác phẩm và hiện tượng. Ví dụ: Thế vận hội Olympic, Galaxy S23,…
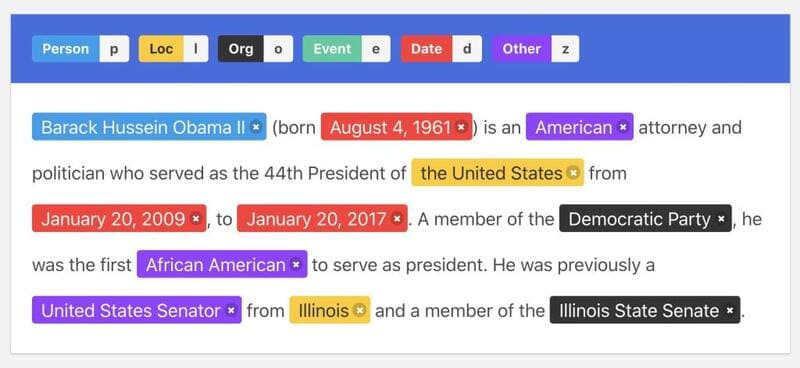
NER và NLP có mối quan hệ như thế nào?
Nhận dạng thực thể có tên (Named Entity Recognition – NER) là một thành phần ngữ nghĩa quan trọng trong Xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP). NER giúp hệ thống hiểu và cấu trúc thông tin từ văn bản, qua đó hỗ trợ các tác vụ phân tích ngôn ngữ ở mức độ sâu hơn.
Trong NLP, các kỹ thuật Machine Learning cho phép mô hình học từ dữ liệu ngôn ngữ quy mô lớn và liên tục nâng cao độ chính xác khi xử lý văn bản và lời nói. Về tổng thể, NLP được chia thành 3 lĩnh vực chính, mỗi lĩnh vực đảm nhiệm một vai trò khác nhau trong quá trình hiểu và tạo ngôn ngữ tự nhiên, cụ thể:
- Cú pháp: Tập trung vào việc hiểu cấu trúc và quy tắc của ngôn ngữ, giúp máy tính nắm bắt được cách thức tổ chức các từ trong câu và đoạn văn.
- Ngữ nghĩa: Hướng đến việc tìm ra ý nghĩa của các từ, văn bản và lời nói, xác định các mối quan hệ của chúng trong ngữ cảnh cụ thể.
- Nhận diện giọng nói: Tập trung vào nhận diện các từ đã nói và chuyển chúng thành văn bản để máy tính có thể xử lý.
Trong 3 lĩnh vực của NLP, NER đóng vai trò nổi bật ở tầng ngữ nghĩa khi giúp hệ thống trích xuất ý nghĩa của từ và xác định vị trí, vai trò của chúng trong từng ngữ cảnh cụ thể. Nhờ tích hợp NER, hệ thống NLP không chỉ phân tích được cấu trúc ngữ pháp mà còn nhận diện và phân loại chính xác các thực thể quan trọng như tên người, tổ chức và địa điểm trong văn bản.
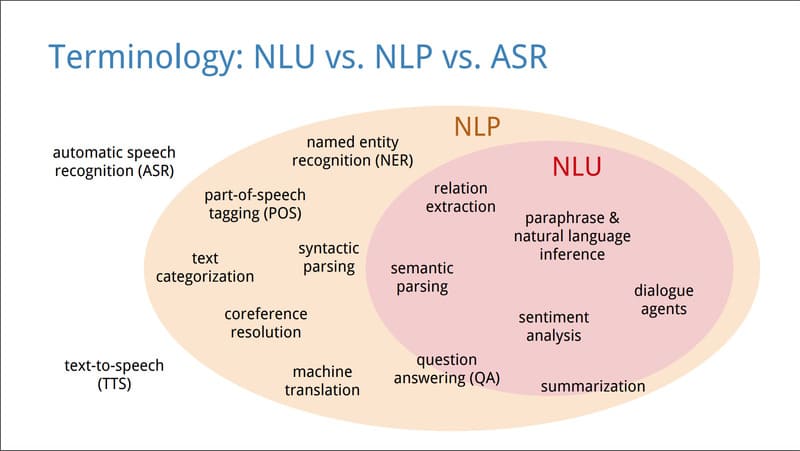
5 kỹ thuật Named Entity Recognition cơ bản hiện nay
Các tổ chức thường áp dụng NER để khai thác dữ liệu phi cấu trúc thông qua 5 hướng tiếp cận chính, mỗi phương pháp phù hợp với những bối cảnh khác nhau:
Dựa trên từ điển (Dictionary-based): Sử dụng tập từ vựng, từ đồng nghĩa và danh sách thực thể để so khớp chuỗi trong văn bản. Cách này dễ triển khai nhưng phụ thuộc nhiều vào việc cập nhật từ điển, nên khó mở rộng và kém linh hoạt.
Dựa trên quy tắc (Rule-based): Xây dựng các quy tắc ngữ pháp và ngữ cảnh để nhận diện thực thể, gồm quy tắc theo mẫu và theo ngữ nghĩa. Phương pháp này cho độ chính xác cao trong phạm vi hẹp nhưng tốn công xây dựng và khó thích ứng với dữ liệu mới.
Dựa trên Machine Learning: Huấn luyện mô hình trên dữ liệu đã gán nhãn để tự động phát hiện thực thể, sử dụng các thuật toán như CRF, Maximum Entropy, Decision Tree hoặc SVM. Cách tiếp cận này có khả năng tổng quát hóa tốt hơn nhưng đòi hỏi lượng dữ liệu huấn luyện lớn và chi phí cao.
Dựa trên Deep Learning: Ứng dụng các kiến trúc như RNN – Recurrent Neural Networks hoặc Transformer Model để học quan hệ ngữ cảnh dài hạn và các mẫu phức tạp trong dữ liệu. Phương pháp này phù hợp cho bài toán NER quy mô lớn nhưng sẽ yêu cầu tài nguyên tính toán đáng kể.
Phương pháp lai (Hybrid): Kết hợp nhiều kỹ thuật nhằm tận dụng ưu điểm của từng phương pháp, chẳng hạn dùng quy tắc cho thực thể đơn giản và mô hình học máy cho thực thể phức tạp. Cách này linh hoạt và hiệu quả hơn, nhưng hệ thống triển khai thường phức tạp.
Việc lựa chọn phương pháp NER phụ thuộc vào đặc điểm dữ liệu, quy mô triển khai, nguồn lực và mức độ chính xác mong muốn. Trong thực tế, nhiều tổ chức ưu tiên kết hợp các kỹ thuật để tối ưu hiệu quả trích xuất thông tin từ dữ liệu phi cấu trúc.
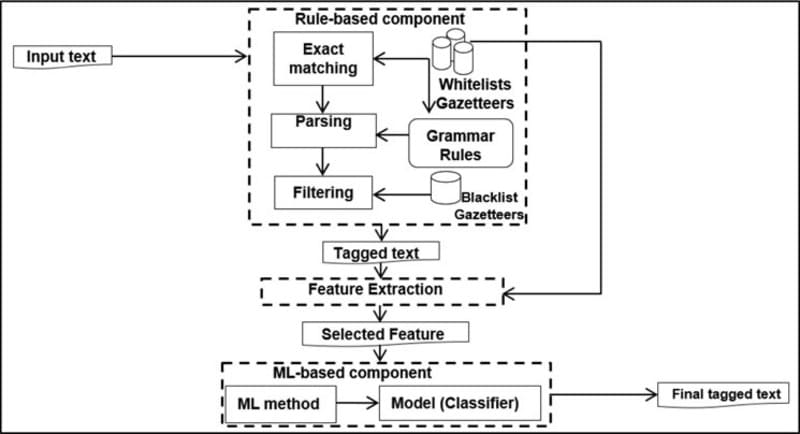
Các phương pháp luận phổ biến của NER
Kể từ khi xuất hiện, NER đã phát triển mạnh mẽ, trong đó các kỹ thuật Deep Learning đóng vai trò then chốt trong việc nâng cao hiệu quả nhận dạng thực thể. Hiện nay, một số phương pháp NER tiêu biểu được sử dụng rộng rãi gồm:
Recurrent Neural Networks (RNN) và Long Short-Term Memory (LSTM): RNN được thiết kế để xử lý dữ liệu dạng chuỗi, còn LSTM, một biến thể của RNN có khả năng ghi nhớ thông tin dài hạn. Nhờ đó, mô hình có thể nắm bắt ngữ cảnh xuyên suốt văn bản, giúp nhận diện thực thể chính xác hơn dựa trên thông tin xuất hiện trước đó.
Conditional Random Fields (CRF): CRF thường được kết hợp với LSTM để tối ưu kết quả NER. Thay vì dự đoán từng nhãn riêng lẻ, CRF mô hình hóa toàn bộ chuỗi nhãn, qua đó tận dụng mối quan hệ giữa các từ liền kề và cải thiện độ chính xác khi nhận dạng các thực thể liên tục.
Transformer và BERT: Kiến trúc Transformer, đặc biệt là mô hình BERT, đã tạo bước tiến lớn cho NER. BERT là mô hình ngôn ngữ tiền huấn luyện, cho phép hiểu ngữ cảnh hai chiều bằng cách xem xét đồng thời các từ đứng trước và sau một từ, nâng cao khả năng gán nhãn thực thể trong các ngữ cảnh phức tạp.
Những phương pháp này đánh dấu các cột mốc quan trọng trong quá trình phát triển của NER, giúp hệ thống hiểu ngữ cảnh sâu hơn, nhận diện quan hệ giữa các từ tốt hơn và mở rộng khả năng ứng dụng trong nhiều lĩnh vực khác nhau.
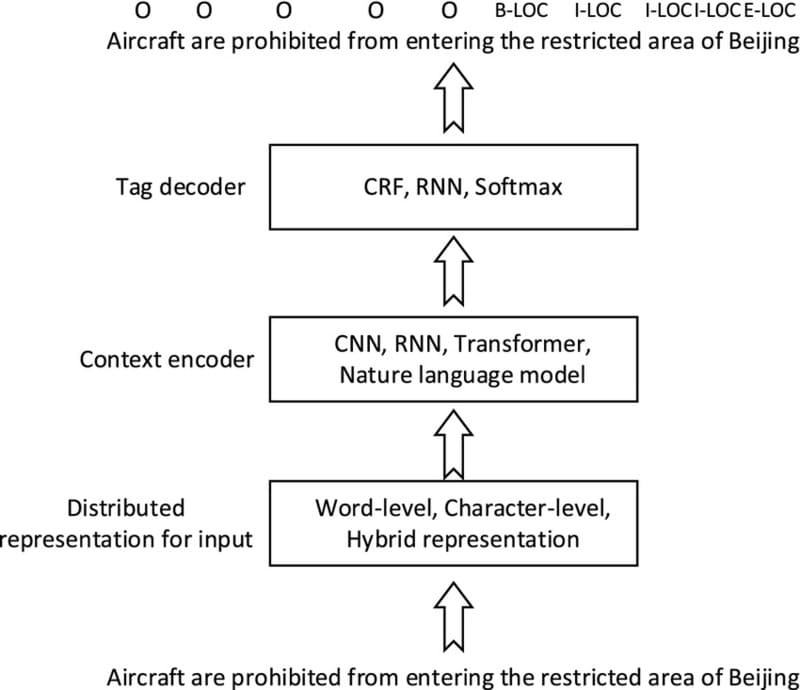
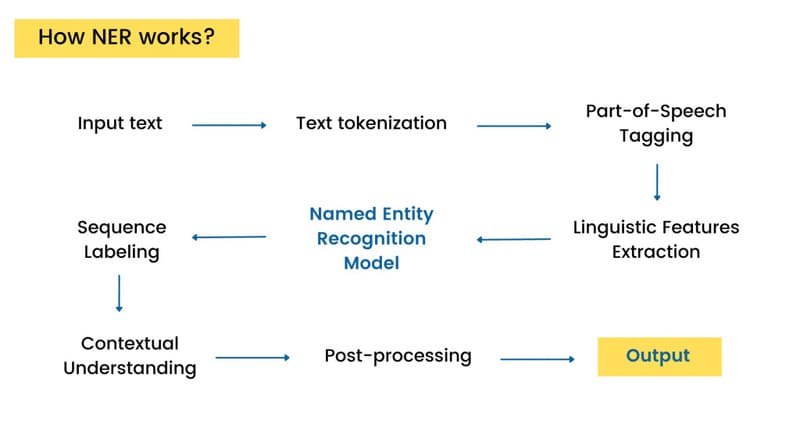
Quy trình NER gồm những bước nào?
Quá trình NER về cơ bản gồm hai hoạt động song song: Nhận dạng/phát hiện thực thể có tên (xác định một từ hoặc một chuỗi từ trong tài liệu) và Phân loại thực thể có tên (phân loại mỗi thực thể được phát hiện vào các danh mục phù hợp). Quy trình Named Entity Recognition đầy đủ thường gồm các bước sau:
- Thu thập dữ liệu: Xây dựng tập dữ liệu văn bản đã được gán nhãn thực thể rõ ràng. Dữ liệu có thể được chú thích thủ công hoặc tạo tự động tùy theo quy mô và mục tiêu bài toán.
- Tiền xử lý dữ liệu: Làm sạch và chuẩn hóa văn bản bằng cách loại bỏ ký tự dư thừa, chuẩn định dạng và tách văn bản thành câu hoặc đơn vị xử lý phù hợp.
- Tokenization: Chia văn bản thành các token như từ hoặc cụm từ để phục vụ quá trình phân tích. Ví dụ, câu “Elon Musk thành lập SpaceX năm 2002” được tách thành các token riêng biệt. Cụ thể “Elon Musk” (Người), “SpaceX” (Tổ chức) và “2002” (Thời gian).
- Trích xuất đặc trưng: Khai thác các đặc trưng ngôn ngữ như POS tagging, embedding từ và thông tin ngữ cảnh, tùy thuộc vào mô hình NER được sử dụng.
- Huấn luyện mô hình: Sử dụng dữ liệu đã gán nhãn để huấn luyện mô hình Machine Learning hoặc Deep Learning, giúp mô hình học mối quan hệ giữa từ ngữ và nhãn thực thể.
- Nhận diện và phân loại thực thể: Mô hình phát hiện các thực thể tiềm năng và gán chúng vào các nhóm như người, tổ chức, địa điểm hoặc thời gian dựa trên ngữ cảnh.
- Phân tích ngữ cảnh: Đánh giá thông tin xung quanh thực thể nhằm tăng độ chính xác, đặc biệt với các trường hợp dễ gây nhầm lẫn.
- Đánh giá và tinh chỉnh mô hình: Đo lường hiệu quả bằng các chỉ số như Precision, Recall và F1-score, sau đó điều chỉnh tham số và dữ liệu để cải thiện kết quả.
- Triển khai và hậu xử lý: Áp dụng mô hình cho dữ liệu mới và hoàn thiện đầu ra bằng cách liên kết thực thể với nguồn tri thức bên ngoài, xử lý mơ hồ và bổ sung thông tin cần thiết.
Các công cụ và thư viện hỗ trợ quá trình triển khai NER
Cách đơn giản và nhanh nhất để triển khai hệ thống Named Entity Recognition (NER) là thông qua giao diện lập trình ứng dụng (API). NER API thường được cung cấp dưới dạng dịch vụ web hoặc chạy cục bộ, cho phép hệ thống gọi trực tiếp các chức năng nhận dạng và phân loại thực thể mà không cần xây dựng mô hình từ đầu. Một số Named Entity Recognition API phổ biến hiện nay gồm:
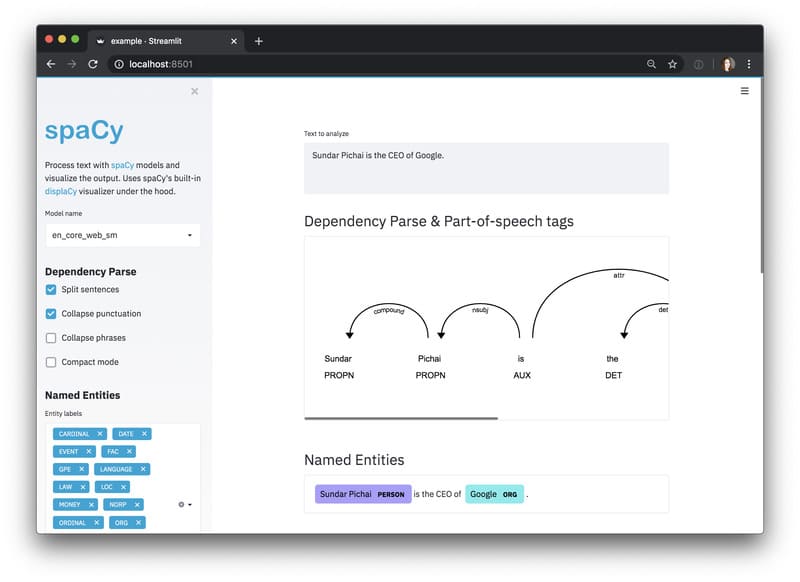
SpaCy
SpaCy là thư viện mã nguồn mở viết bằng Python, nổi bật với tốc độ xử lý cao và giao diện thân thiện, chuyên phục vụ các tác vụ NLP nâng cao. Thư viện được phát triển dựa trên những nghiên cứu mới nhất và tối ưu cho các ứng dụng thực tế, đồng thời cung cấp hệ thống thống kê mạnh mẽ để xây dựng và tùy chỉnh mô hình NER.
Ưu điểm của SpaCy là hiệu năng ổn định, dễ triển khai và có sẵn nhiều mô hình huấn luyện trước. Tuy nhiên, khả năng hỗ trợ các ngôn ngữ ngoài tiếng Anh vẫn còn hạn chế.
Natural Language Toolkit (NLTK)
NLTK là thư viện mã nguồn mở phổ biến trong Python, được thiết kế để xây dựng các ứng dụng xử lý ngôn ngữ tự nhiên. Thư viện cung cấp giao diện trực quan cho hơn 100 mô hình và tài nguyên đã được huấn luyện sẵn, cùng hệ thống công cụ đầy đủ cho các tác vụ như phân loại văn bản, tokenization, stemming, tagging, phân tích cú pháp và suy luận ngữ nghĩa.
Trong NER, NLTK hỗ trợ nhận dạng thực thể thông qua bộ phân loại ne_chunk và cho phép tích hợp Stanford NER Tagger bằng Python. Ưu điểm của NLTK nằm ở tính toàn diện và giá trị học thuật cao, phù hợp cho nghiên cứu và đào tạo, tuy nhiên hiệu suất xử lý thường chậm hơn so với SpaCy.

Stanford Named Entity Recognizer
Stanford NER là bộ công cụ NLP do Đại học Stanford phát triển, được xây dựng trên nền tảng Java và là một trong những thư viện chuẩn cho bài toán nhận dạng thực thể. Công cụ này sử dụng mô hình Conditional Random Fields (CRF) và cung cấp sẵn các mô hình đã được huấn luyện để trích xuất thực thể có tên. Stanford NER nổi bật với độ chính xác cao và khả năng hỗ trợ đa ngôn ngữ, tuy nhiên việc triển khai thường đòi hỏi nhiều tài nguyên tính toán hơn so với một số giải pháp NER khác.
OpenNLP
Là bộ công cụ dựa trên Machine Learning dành cho Xử lý ngôn ngữ tự nhiên, OpenNLP cung cấp các giải pháp NER linh hoạt và có thể tùy chỉnh. Công cụ này hỗ trợ nhiều ngôn ngữ và cho phép người dùng điều chỉnh theo nhu cầu cụ thể. Tuy nhiên, OpenNLP có thể phức tạp hơn trong quá trình thiết lập ban đầu so với các giải pháp khác.
Stanford CoreNLP
CoreNLP là bộ công cụ xử lý ngôn ngữ tự nhiên dựa trên Java, cung cấp giải pháp NER có độ chính xác cao. Thư viện này được đánh giá cao nhờ khả năng hỗ trợ đa ngôn ngữ và mức độ ổn định trong cả môi trường học thuật lẫn ứng dụng thương mại. Tuy nhiên, tương tự Stanford NER, CoreNLP yêu cầu tài nguyên tính toán lớn hơn so với nhiều giải pháp NER khác.
NER có ưu điểm và hạn chế gì khi sử dụng?
NER giúp tự động trích xuất thông tin quan trọng từ văn bản, nhưng vẫn có những điểm mạnh và hạn chế nhất định. Hiểu rõ ưu và nhược điểm của Named Entity Recognition sẽ lựa chọn và ứng dụng công nghệ này một cách hiệu quả hơn.
Ưu điểm của NER
NER giúp hệ thống tự động nhận diện và trích xuất các thông tin quan trọng từ văn bản, từ đó biến dữ liệu phi cấu trúc thành dữ liệu có giá trị và dễ khai thác. Nhờ vậy, doanh nghiệp có thể xử lý thông tin nhanh hơn, chính xác hơn và tối ưu nhiều quy trình thông minh. Cụ thể, NER mang lại các lợi ích nổi bật sau:
- Hỗ trợ khai thác thông tin: Xác định nhanh các dữ liệu quan trọng, giúp truy xuất và tìm kiếm hiệu quả.
- Tổ chức nội dung tốt hơn: Phân loại thông tin rõ ràng, phù hợp cho cơ sở dữ liệu và công cụ tìm kiếm.
- Nâng cao trải nghiệm người dùng: Cải thiện độ chính xác của kết quả tìm kiếm và cá nhân hóa gợi ý nội dung.
- Phân tích chuyên sâu: Hỗ trợ phân tích cảm xúc và phát hiện xu hướng từ dữ liệu văn bản.
- Tự động hóa quy trình: Giảm thao tác thủ công, tiết kiệm thời gian và nguồn lực vận hành.
Hạn chế của NER
Có một số hạn chế đáng chú ý cần xem xét khi sử dụng công nghệ NER như sau:
- Rào cản ngôn ngữ: NER đạt độ chính xác cao với các ngôn ngữ phổ biến như tiếng Anh, nhưng hiệu quả giảm đáng kể ở những ngôn ngữ thiếu dữ liệu gán nhãn. NER đa ngôn ngữ, với mục tiêu chuyển giao tri thức giữa các ngôn ngữ, đang là hướng nghiên cứu nhằm thu hẹp khoảng cách này.
- Thực thể lồng nhau: Trong nhiều trường hợp, các thực thể có thể xuất hiện lồng ghép, khiến việc nhận dạng trở nên phức tạp. Ví dụ, cùng một đoạn văn có thể chứa cả tên tổ chức tổng thể và tên đơn vị cụ thể bên trong.
- Thực thể chuyên ngành: Các mô hình NER tổng quát thường xử lý tốt thực thể phổ biến nhưng gặp khó khăn với thuật ngữ đặc thù theo lĩnh vực, như y tế hoặc pháp lý. Việc xây dựng mô hình chuyên biệt đòi hỏi dữ liệu huấn luyện chất lượng cao, vốn khó thu thập.
- Tính mơ hồ ngữ nghĩa: NER khó phân loại chính xác các thực thể đa nghĩa hoặc có nhiều cách biểu đạt. Một từ có thể đại diện cho nhiều khái niệm khác nhau tùy ngữ cảnh, hoặc cùng một thực thể có nhiều cách viết khác nhau, trong khi văn bản không phải lúc nào cũng cung cấp đủ thông tin để phân biệt rõ ràng.
Ứng dụng nổi bật của Named Entity Recognition là gì?
Cùng với sự phát triển của công nghệ, các hệ thống NER ngày càng được ứng dụng rộng rãi, hỗ trợ tổ chức hiểu và khai thác hiệu quả khối lượng dữ liệu phát sinh mỗi ngày. Hiện nay, Named Entity Recognition đã hiện diện trong nhiều lĩnh vực như y tế, tài chính, dịch vụ khách hàng và an ninh mạng, góp phần nâng cao năng lực phân tích và ra quyết định dựa trên dữ liệu. Những ứng dụng nổi bật nhất của NER trong thực tế gồm:
- Trích xuất thông tin: NER là nền tảng của các hệ thống khai thác dữ liệu, giúp công cụ tìm kiếm như Google hay Bing nhận diện thực thể trong nội dung web và truy vấn. Từ đó cải thiện độ chính xác và mức độ liên quan của kết quả tìm kiếm.
- Tổng hợp tin tức tự động: Các nền tảng tin tức sử dụng NER để nhận diện người, tổ chức, địa điểm và sự kiện, hỗ trợ phân nhóm bài viết, theo dõi chủ đề và cung cấp góc nhìn toàn diện về các diễn biến quan trọng.
- Giám sát mạng xã hội: NER phân tích bài đăng và bình luận để xác định thực thể chính, phục vụ phân tích cảm xúc, phát hiện xu hướng và hỗ trợ xây dựng chiến lược marketing hoặc chăm sóc khách hàng.
- Chatbot và trợ lý ảo: NER giúp hệ thống hiểu đúng ý định và ngữ cảnh truy vấn của người dùng, đưa ra phản hồi chính xác và phù hợp.
- An ninh mạng: Công nghệ này hỗ trợ phát hiện thực thể đáng ngờ như địa chỉ IP, URL hay tên tệp trong log bảo mật, góp phần nâng cao khả năng giám sát và xử lý sự cố.
- Báo chí điều tra: NER được dùng để phân tích khối lượng lớn tài liệu phi cấu trúc, tự động phát hiện mối liên hệ giữa cá nhân, tổ chức và địa điểm trong các vụ điều tra quy mô lớn
- Tin sinh học và y tế: NER trích xuất gen, protein, thuốc, bệnh từ tài liệu nghiên cứu và hồ sơ y tế, giúp đẩy nhanh nghiên cứu và hỗ trợ chẩn đoán.
- Quảng cáo theo ngữ cảnh: Hệ thống nhận diện các thực thể chính trong nội dung để hiển thị quảng cáo phù hợp, qua đó cải thiện hiệu quả tiếp thị.
- Tuyển dụng: NER hỗ trợ sàng lọc hồ sơ ứng viên bằng cách tự động trích xuất thông tin quan trọng như kỹ năng, trình độ và kinh nghiệm.
- Hỗ trợ khách hàng: Công nghệ này giúp phân loại khiếu nại và yêu cầu dựa trên sản phẩm, dịch vụ hoặc địa điểm, rút ngắn thời gian phản hồi.
- Hệ thống gợi ý và phân tích cảm xúc (Sentiment Analysis): NER được sử dụng để cá nhân hóa đề xuất nội dung và phân tích cảm nhận của người dùng đối với thương hiệu, sản phẩm hoặc dịch vụ.
>>> XEM THÊM: Cách tạo chatbot đa kênh dễ dàng, thuận tiện
Tương lai của NER như thế nào?
Trong tương lai, học không giám sát (Unsupervised Learning) được xem là hướng phát triển nhiều tiềm năng cho NER. Khác với học có giám sát vốn phụ thuộc vào lượng lớn dữ liệu đã gán nhãn và tốn kém chi phí, các phương pháp không giám sát có thể khai thác trực tiếp dữ liệu thô. Cách tiếp cận này giúp giảm rào cản về dữ liệu, đặc biệt hiệu quả với các lĩnh vực chuyên biệt hoặc ngôn ngữ ít tài nguyên.
Bên cạnh đó, xu hướng kết hợp NER với các tác vụ NLP khác đang ngày càng rõ nét. Việc tích hợp NER với entity linking hoặc giải quyết đồng tham chiếu cho phép hệ thống không chỉ nhận diện thực thể mà còn hiểu mối quan hệ và sự liên kết giữa chúng trong toàn bộ văn bản.
Ngoài ra, Few-shot Learning và Multimodal NER cũng mở rộng đáng kể khả năng của Named Entity Recognition. Few-shot Learning giúp mô hình học hiệu quả ngay cả khi chỉ có rất ít dữ liệu gán nhãn, trong khi Multimodal NER kết hợp văn bản với hình ảnh hoặc âm thanh để bổ sung ngữ cảnh, từ đó nâng cao độ chính xác trong nhận dạng thực thể.
FPT.AI đã tổng hợp thông tin về NER là gì, các phương pháp luận, quy trình, công cụ hỗ trợ, lợi ích và hạn chế cùng những ứng dụng và tương lai của NER. Named Entity Recognition (NER) đóng vai trò thiết yếu trong việc chuyển đổi dữ liệu phi cấu trúc thành thông tin có cấu trúc, mang lại giá trị to lớn cho các tổ chức trong kỷ nguyên dữ liệu số. Sự xuất hiện của các phương pháp học không giám sát, few-shot learning và NER đa phương thức hứa hẹn sẽ mở rộng khả năng của công nghệ này, giúp các hệ thống xử lý ngôn ngữ tự nhiên ngày càng tiến gần hơn đến khả năng hiểu ngôn ngữ của con người.