Trong thời đại AI ngày càng có tầm ảnh hưởng trong cuộc sống, việc đảm bảo các hệ thống trí tuệ nhân tạo hoạt động “có trách nhiệm, công bằng và an toàn” không còn là xu hướng mà là yêu cầu tất yếu. Theo nghiên cứu của Pew Research Center, 57% người Mỹ lo ngại các rủi ro của AI đối với xã hội. Chính vì vậy việc thiết lập các “Hệ thống rào chắn AI (AI Guardrails)” – một mạng lưới các biện pháp kỹ thuật và chính sách giúp ngăn chặn phản hồi sai lệch, nội dung độc hại, thiên vị hay vi phạm đạo đức.
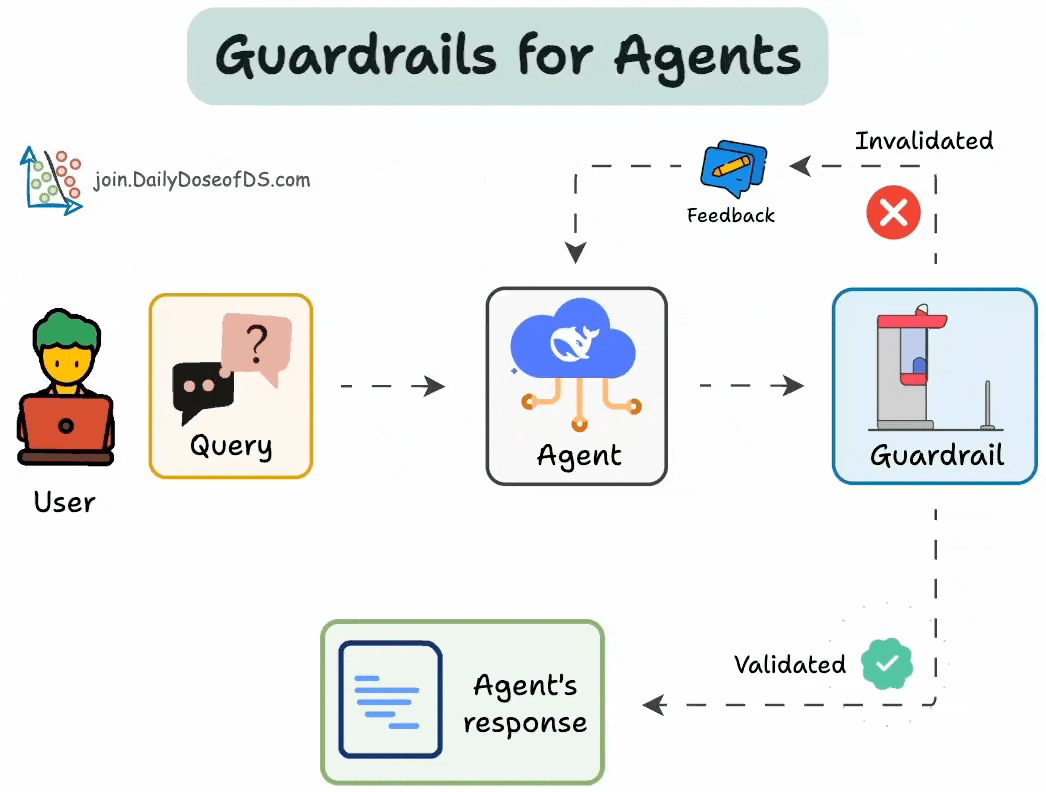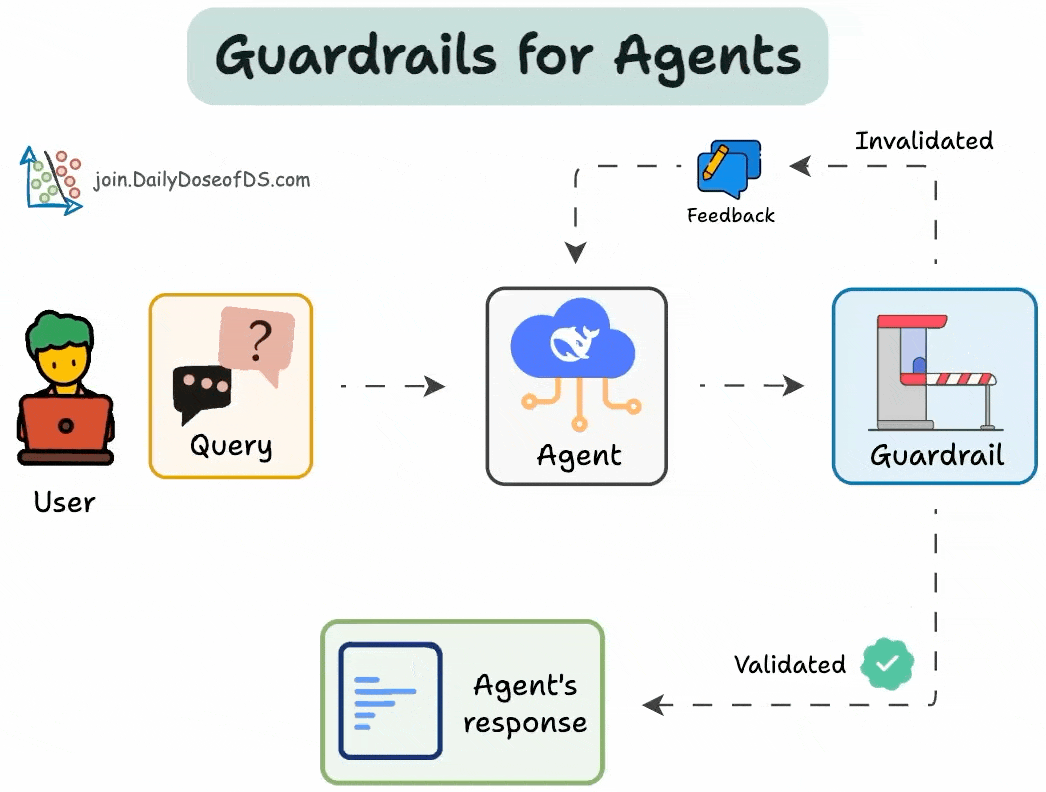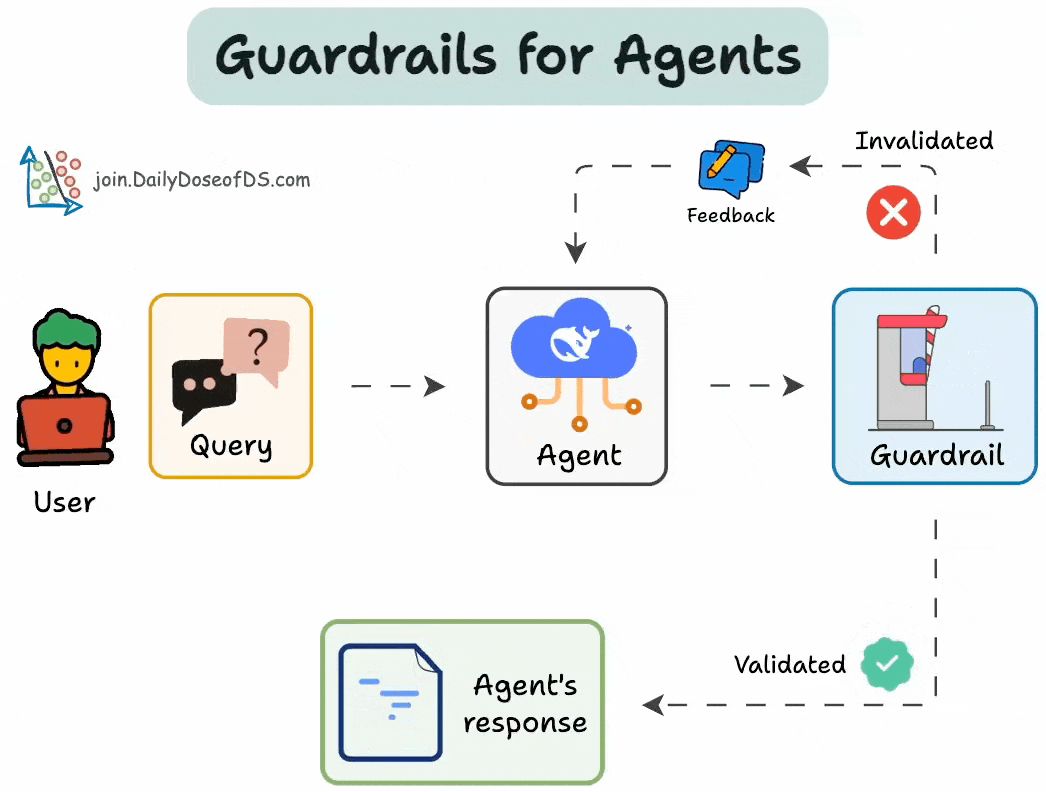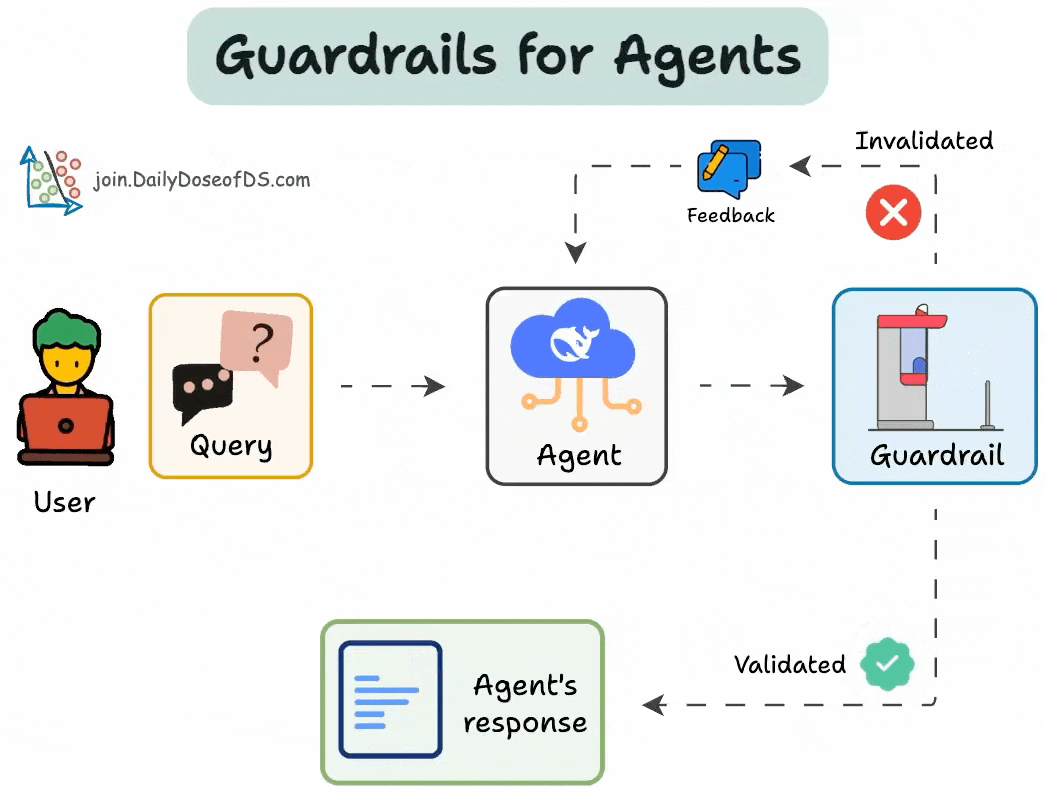
I. AI Guardrails là gì?
Guardrails (Rào chắn bảo vệ) là các biện pháp an toàn và các chính sách được triển khai trong các ứng dụng LLM để ngăn chặn các phản hồi có hại hoặc không mong muốn. Chúng hoạt động như các hàng rào bảo vệ, đảm bảo rằng LLM tuân thủ các nguyên tắc đạo đức và an toàn đã định trước, ngăn chặn việc tạo ra nội dung độc hại, thiên vị hoặc không phù hợp. Guardrails có thể ở dạng các bộ lọc, validators hoặc các cơ chế kiểm duyệt khác, hoạt động trên cả đầu vào và đầu ra của LLM.

II. Các loại AI Guardrails chính và Ứng dụng thực tế
AI Guardrails không phải là một giải pháp đơn lẻ mà là một hệ thống đa lớp với nhiều loại khác nhau, mỗi loại có mục đích và thành phần riêng biệt để bảo vệ AI ở các giai đoạn khác nhau trong vòng đời hoạt động của hệ thống.
Guardrails đầu vào (Input Guardrails)
Guardrails đầu vào là tuyến phòng thủ đầu tiên. Mục đích của chúng là hoạt động như một lớp xác thực, xử lý dữ liệu trước khi nó đến mô hình AI. Chúng bảo vệ hệ thống khỏi các truy vấn sai định dạng, nội dung độc hại và sự không nhất quán về định dạng có thể ảnh hưởng đến hiệu suất mô hình hoặc tạo ra lỗ hổng bảo mật. Các thành phần chính bao gồm xác minh cấu trúc truy vấn cơ bản (kiểm tra các trường bắt buộc, giới hạn độ dài đầu vào, giới hạn tỷ lệ yêu cầu để ngăn chặn lạm dụng), kiểm duyệt nội dung (lọc nội dung có hại, phát hiện PII theo thời gian thực, chặn từ khóa và phát hiện ngôn ngữ cho các ứng dụng chuyên biệt) và tiêu chuẩn hóa định dạng có cấu trúc (chuẩn hóa ngày giờ, thực thi các mẫu cấu trúc và xử lý mã hóa ký tự nhất quán). Chúng đặc biệt quan trọng cho các giao diện AI tương tác với người dùng, trong các lĩnh vực được quản lý như y tế và tài chính để tuân thủ, và trong các hệ thống đa người thuê hoặc môi trường thông lượng cao.
Guardrails đầu ra (Output Guardrails)
Guardrails đầu ra có nhiệm vụ kiểm soát các phản hồi của mô hình. Mục đích của chúng là bắt các vấn đề như ảo giác, nội dung thiên vị hoặc rò rỉ thông tin nhạy cảm trong các phản hồi do AI tạo ra trước khi chúng đến tay người dùng. Các thành phần bao gồm xác thực phản hồi (xác minh tính chính xác thực tế, tính nhất quán logic, kiểm tra sự mâu thuẫn và xác thực các tài liệu tham khảo được tạo ra), lọc nội dung (sàng lọc ngôn ngữ phân biệt đối xử, nội dung xúc phạm và các khuyến nghị không phù hợp để duy trì giọng điệu thương hiệu và tiêu chuẩn đạo đức) và bảo vệ PII (phát hiện và che giấu thông tin cá nhân trong đường dẫn đầu ra). Các guardrails này cần thiết khi độ tin cậy và an toàn là tối quan trọng, như trong chatbot pháp lý yêu cầu độ chính xác thực tế, ứng dụng y tế cần thông tin y tế chính xác, và hệ thống tư vấn tài chính cung cấp hướng dẫn tuân thủ.
Guardrails truy xuất và kiến thức (Retrieval & Knowledge Guardrails)
Những guardrails này quản lý quyền truy cập thông tin. Mục đích của chúng là cung cấp quyền kiểm soát chính xác đối với các nguồn thông tin mà hệ thống AI có thể truy cập và tham chiếu, đảm bảo thông tin có thể xác minh và cập nhật từ các nguồn được ủy quyền. Các thành phần chính bao gồm Tạo sinh tăng cường truy xuất (RAG) để truy xuất và xác minh thông tin theo thời gian thực, ghi nhận nguồn để tạo dấu vết kiểm toán cho nội dung do AI tạo ra, và lọc kiến thức doanh nghiệp để hạn chế quyền truy cập của AI vào các tập dữ liệu nội bộ được phê duyệt. Chúng rất quan trọng đối với các ứng dụng yêu cầu độ chính xác theo thời gian thực, như hỗ trợ khách hàng hoặc tìm kiếm tài liệu nội bộ.
Guardrails chi phí và giới hạn tỷ lệ (Rate Limiting & Cost Guardrails)
Các guardrails này quản lý việc sử dụng tài nguyên. Mục đích của chúng là bảo vệ cơ sở hạ tầng AI khỏi việc sử dụng quá mức và giữ chi phí vận hành có thể dự đoán được, vì các cuộc gọi API đến các mô hình ngôn ngữ lớn có thể nhanh chóng tích lũy chi phí đáng kể. Các thành phần bao gồm giới hạn tỷ lệ cho mỗi người dùng và mỗi điểm cuối, quản lý chi phí (theo dõi việc sử dụng token, chi phí mô hình và chi phí API tích lũy với ngưỡng ngân sách và tự động cắt giảm), và bộ nhớ đệm phản hồi để lưu trữ và sử dụng lại các phản hồi. Chúng rất quan trọng để duy trì hiệu quả hoạt động trong các ứng dụng tiêu dùng có lưu lượng truy cập cao hoặc quản lý triển khai AI trên toàn doanh nghiệp.
Guardrails tuân thủ và bảo mật (Compliance & Security Guardrails)
Đây là các guardrails đảm bảo tuân thủ quy định. Mục đích của chúng là thực hiện một khuôn khổ bảo mật toàn diện đáp ứng các yêu cầu quy định trong khi vẫn duy trì khả năng sử dụng hệ thống, đặc biệt đối với các hệ thống AI trong các ngành được quản lý. Các thành phần bao gồm xử lý PII (xác định và che giấu dữ liệu nhạy cảm), ghi nhật ký kiểm toán (theo dõi mọi tương tác quan trọng với AI để tuân thủ quy định) và kiểm soát truy cập dựa trên vai trò (RBAC) để quản lý quyền truy cập hệ thống AI. Chúng là bắt buộc đối với việc triển khai sản xuất trong các lĩnh vực như y tế, tài chính hoặc các ngành được quản lý khác, và đối với các triển khai cấp doanh nghiệp để cung cấp quản trị và trách nhiệm giải trình.
Bảng 1: Các Loại AI Guardrails chính và chức năng
| Loại Guardrail | Mục Đích | Các Thành Phần Chính |
| Đầu vào (Input) | Xác thực dữ liệu trước khi đến mô hình AI, bảo vệ khỏi truy vấn sai định dạng, nội dung độc hại. | Xác minh cấu trúc truy vấn, kiểm duyệt nội dung (phát hiện độc tính, PII), tiêu chuẩn hóa định dạng. |
| Đầu ra (Output) | Kiểm soát phản hồi của mô hình AI, ngăn chặn ảo giác, nội dung thiên vị, rò rỉ thông tin nhạy cảm. | Xác thực phản hồi (tính chính xác, nhất quán), lọc nội dung (ngôn ngữ phân biệt đối xử), bảo vệ PII. |
| Truy xuất & Kiến thức (Retrieval & Knowledge) | Kiểm soát nguồn thông tin AI có thể truy cập, đảm bảo thông tin xác minh và cập nhật. | Tạo sinh tăng cường truy xuất (RAG), ghi nhận nguồn, lọc kiến thức doanh nghiệp. |
| Chi phí & Giới hạn tỷ lệ (Rate Limiting & Cost) | Bảo vệ hạ tầng AI khỏi sử dụng quá mức, giữ chi phí vận hành có thể dự đoán được. | Giới hạn tỷ lệ cho mỗi người dùng/điểm cuối, quản lý chi phí (theo dõi token), bộ nhớ đệm phản hồi. |
| Tuân thủ & Bảo mật (Compliance & Security) | Thực hiện khung bảo mật toàn diện, đáp ứng yêu cầu quy định và duy trì khả năng sử dụng hệ thống. | Xử lý PII, ghi nhật ký kiểm toán, kiểm soát truy cập dựa trên vai trò (RBAC). |
III. Thách thức trong việc triển khai AI Guardrails
Mặc dù AI Guardrails là không thể thiếu, việc thiết kế và triển khai chúng không hề đơn giản và đi kèm với nhiều thách thức đáng kể.
Sự đánh đổi giữa an toàn và tiện ích (False Positives)
Một trong những thách thức lớn nhất là tìm kiếm sự cân bằng giữa việc đảm bảo an toàn và duy trì khả năng hoạt động hiệu quả của AI. Các guardrails quá nghiêm ngặt có thể hạn chế khả năng của AI trong việc trả lời các câu hỏi hợp pháp hoặc giải quyết các quan điểm đa dạng, dẫn đến “false positives” (dương tính giả) nơi nội dung vô hại bị chặn. Ví dụ, các mô hình được tinh chỉnh quá mức để đảm bảo an toàn có thể trở nên quá thận trọng, từ chối các yêu cầu vô hại hoặc trả về các phản hồi mơ hồ, làm giảm tiện ích tổng thể của hệ thống.
Chi phí và tài nguyên
Phát triển và duy trì các guardrails toàn diện có thể tốn kém và đòi hỏi nhiều tài nguyên. Việc đạt được phạm vi bao phủ rộng khắp tất cả các rủi ro và vectơ tấn công tiềm năng đòi hỏi đầu tư đáng kể vào việc quản lý dữ liệu, thử nghiệm và tinh chỉnh liên tục. Đặc biệt, việc duy trì một nhóm nội bộ để liên tục theo dõi các lỗ hổng jailbreaking và prompt injection đã được ghi nhận và mới nổi có thể tốn kém và khó duy trì, do yêu cầu chuyên môn cao và sự thay đổi liên tục của các kỹ thuật tấn công.
Sự phức tạp của việc xác định giá trị và hành vi mong muốn
Không có một bộ quy tắc đạo đức phổ quát nào, và các giá trị của con người rất linh hoạt, khác nhau giữa các cá nhân, công ty, văn hóa và lục địa. Điều này đặt ra thách thức lớn khi điều chỉnh các hệ thống AI có thể tác động đến hàng triệu người, vì nó đặt ra câu hỏi về việc giá trị của ai sẽ được ưu tiên. Các thuật toán có thể hiểu sai các giá trị của con người, học từ các hành động trong quá khứ thay vì các hành vi mong muốn trong tương lai. Vấn đề “căn chỉnh AI” (AI alignment problem) là thách thức lớn nhất, khi các hệ thống AI trở nên phức tạp và mạnh mẽ hơn, việc dự đoán và điều chỉnh kết quả của chúng với mục tiêu của con người ngày càng khó khăn.
Các cuộc tấn công tinh vi (Adversarial Attacks, Prompt Injection)
Guardrails thường thất bại trước các cuộc tấn công đối kháng vì chúng dựa vào các quy tắc hoặc mẫu được xác định trước, mà kẻ tấn công có thể kiểm tra và vượt qua một cách có hệ thống. Các kỹ thuật như “prompt injection” (tiêm nhắc lệnh) và “jailbreak” có thể được sử dụng để thao túng AI, khiến nó tiết lộ thông tin bí mật hoặc thực hiện các lệnh độc hại. Những lỗ hổng này cho thấy guardrails chỉ giải quyết các triệu chứng (các đầu ra có hại cụ thể) chứ không phải nguyên nhân gốc rễ (khả năng của mô hình không thể diễn giải mạnh mẽ ý định đối kháng).
Những thách thức này dẫn đến một hiện tượng được gọi là “cảm giác an toàn sai lầm” và một “cuộc đua vũ trang” không ngừng. Các tài liệu cảnh báo rằng guardrails có thể tạo ra “cảm giác an toàn sai lầm” vì các hệ thống AI vẫn có thể hoạt động theo những cách không thể đoán trước. Điều này đặc biệt đúng khi đối mặt với các cuộc tấn công đối kháng ngày càng tinh vi. Kẻ tấn công liên tục tìm cách “jailbreak” hoặc “prompt injection”, tạo ra một cuộc đua vũ trang không ngừng giữa việc phát triển guardrails và các kỹ thuật tấn công mới. Điều này nhấn mạnh rằng guardrails không phải là một giải pháp “một lần và mãi mãi” mà là một quá trình liên tục đòi hỏi sự cảnh giác, thử nghiệm thường xuyên (red teaming) và khả năng thích ứng nhanh chóng. Các tổ chức cần phải liên tục cập nhật các biện pháp bảo mật và chiến lược tấn công mới nổi để duy trì hiệu quả phòng thủ.
Trong kỷ nguyên “AI-first”, tốc độ triển khai là quan trọng, nhưng độ tin cậy mới là yếu tố quyết định khả năng giữ chân khách hàng và né tránh rủi ro pháp lý. AI Guardrails không chỉ là một tấm khiên kỹ thuật mà còn là cam kết của doanh nghiệp với khách hàng về thông tin chính xác, an toàn và minh bạch.
Việc đầu tư đúng mức vào guardrails ngay hôm nay chính là bảo hiểm cho thương hiệu ngày mai. Chúng phải đi trước bất kỳ dự án AI nào, đặc biệt là các ứng dụng tương tác trực tiếp với khách hàng hoặc đưa ra các quyết định quan trọng, nơi một sai sót nhỏ cũng có thể gây ra hậu quả lớn. Khi trí tuệ nhân tạo ngày càng trở nên mạnh mẽ và tự chủ, vai trò của guardrails sẽ càng trở nên quan trọng hơn, định hình một tương lai nơi AI có thể phát huy tối đa tiềm năng của mình một cách an toàn, đạo đức và có trách nhiệm.