Convolutional neural network (CNN) là một loại mạng nơ-ron nhân tạo có khả năng xử lý và phân tích dữ liệu hình ảnh, âm thanh và tín hiệu trong không gian 3 chiều cực kỳ hiệu quả. Trong bài viết này, FPT.AI sẽ trình bày chi tiết về cơ chế hoạt động của CNNs, từ các tầng cơ bản như Convolutional Layer, Pooling Layer, đến các Fully-connected Layers. Bên cạnh đó, bài viết cũng sẽ giới thiệu các loại CNNs nổi bật, cùng với những ứng dụng thực tế mà công nghệ này mang lại.
Convolutional neural network là gì?
Convolutional neural network (CNN) là một dạng của neural networks (mạng nơ-ron), một phần của Machine Learning và là cơ sở của Deep Learning, được thiết kế để tự động và hiệu quả trích xuất các đặc trưng phân cấp từ dữ liệu cấu trúc lưới, đặc biệt là hình ảnh.
Khác với Recurrent Neural Network thường được sử dụng cho xử lý ngôn ngữ tự nhiên (Natural Language Processing) và nhận diện giọng nói tự động (Automatic Speech Recognition), Convolutional neural network (CNNs) được thiết kế cho các tác vụ phân loại hình ảnh và nhận dạng đối tượng trong không gian 3 chiều.
Convolutional neural network tận dụng các nguyên tắc từ đại số tuyến tính, cụ thể là phép nhân ma trận, để xác định các mẫu trong một hình ảnh, khắc phục hạn chế về thời gian khi xác định đối tượng trong hình ảnh của các phương pháp trích xuất đặc trưng thủ công. Tuy nhiên, CNNs yêu cầu tài nguyên tính toán lớn, thường cần sử dụng GPU để huấn luyện mô hình.

Các thành phần chính của Convolutional neural network
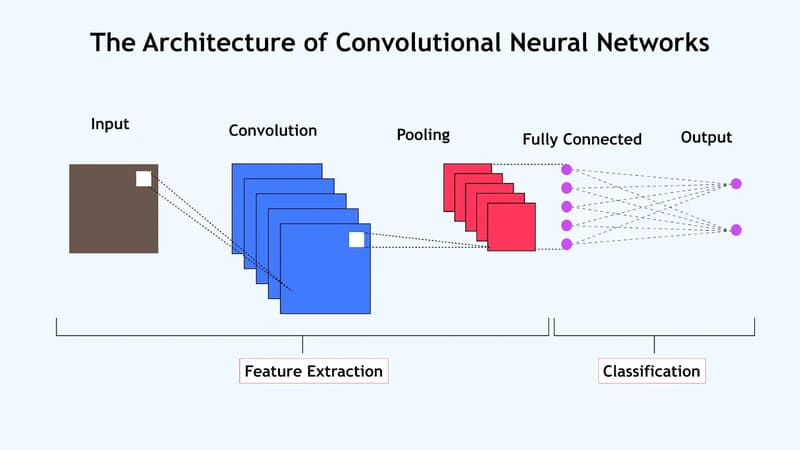
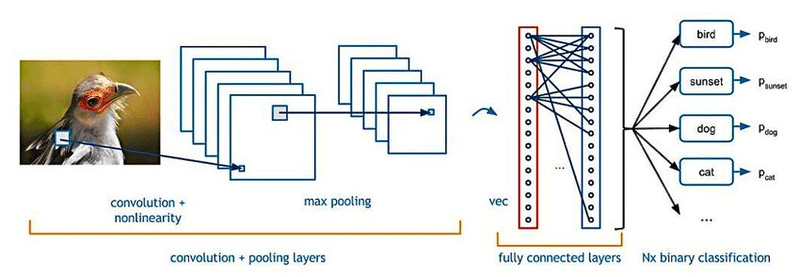
Convolutional neural network (CNNs) có 3 lớp, mỗi tầng đóng vai trò quan trọng trong việc phân tích và nhận diện dữ liệu:
- Convolutional Layer (Tầng tích chập)
- Pooling Layer (Tầng gộp)
- Fully-connected (FC) Layer (Tầng kết nối đầy đủ)
Convolutional layer
Convolutional Layer là nơi thực hiện hầu hết các phép tính quan trọng trong CNNs. Để hiểu cách thức hoạt động của nó, ta cần ba thành phần chính: dữ liệu đầu vào, bộ lọc (filter) và feature map.
Giả sử dữ liệu đầu vào là một hình ảnh màu, nó sẽ được biểu diễn dưới dạng một ma trận các pixel trong không gian ba chiều (3D), với ba chiều tương ứng là chiều cao, chiều rộng và độ sâu (tương ứng với RGB trong hình ảnh).
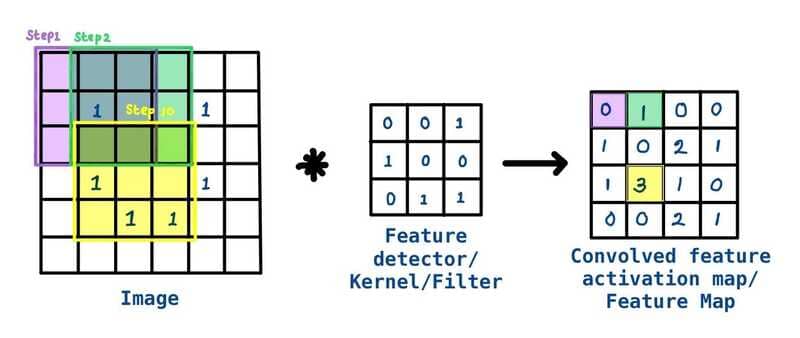
Feature detector (còn gọi là kernel hoặc filter) là một ma trận trọng số hai chiều (2D) giúp phát hiện các đặc trưng trong hình ảnh. Khi filter này di chuyển qua các receptive fields (vùng cảm nhận) của hình ảnh, nó sẽ kiểm tra xem các đặc trưng cần tìm có xuất hiện hay không. Quá trình này được gọi là convolution.
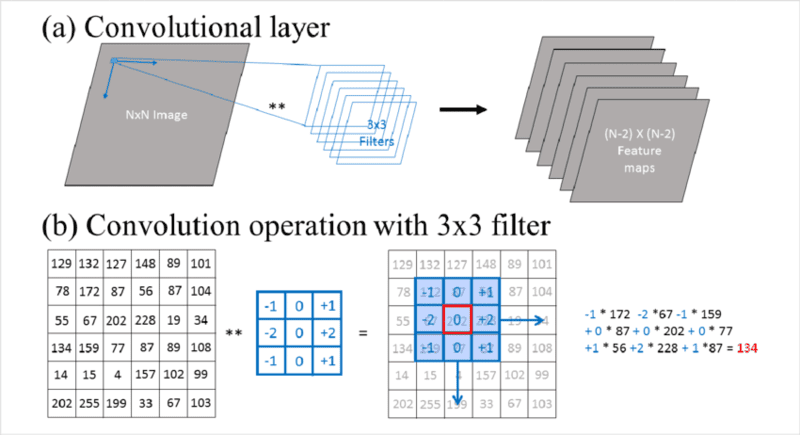
Feature detector thường có kích thước nhỏ, ví dụ như ma trận 3×3, và nó xác định kích thước của receptive field. Khi filter này di chuyển qua hình ảnh, một tích vô hướng (dot product) được tính giữa các giá trị pixel trong vùng quét và filter. Kết quả này sẽ được đưa vào một mảng đầu ra. Sau đó, filter dịch chuyển theo một khoảng cách xác định (gọi là stride) và quá trình được lặp lại cho đến khi filter đã quét qua toàn bộ hình ảnh.
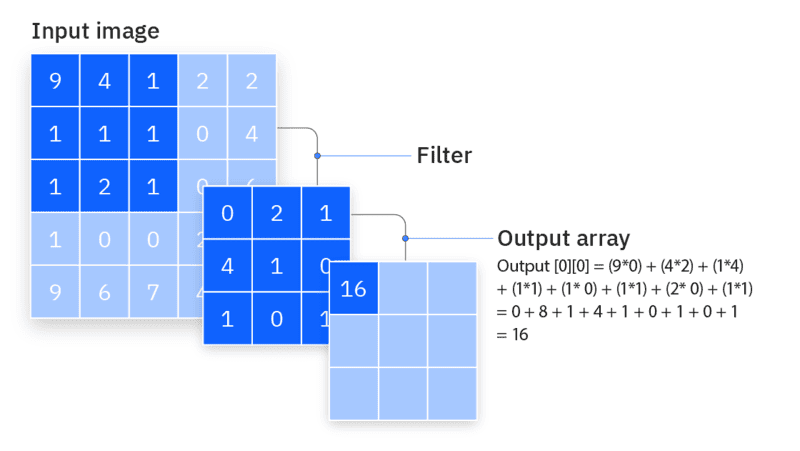
Feature map (hay activation map hoặc convolved feature) chính là kết quả của chuỗi các phép tính tích vô hướng giữa pixel đầu vào và filter.
Một điểm quan trọng là các trọng số trong feature detector không thay đổi khi nó di chuyển qua hình ảnh, đây được gọi là parameter sharing. Trong quá trình huấn luyện, trọng số sẽ được điều chỉnh thông qua backpropagation và gradient descent.
Có ba hyperparameters quan trọng ảnh hưởng đến kích thước của đầu ra và cần được thiết lập trước khi huấn luyện Neural Network:
- Số lượng filters: Quyết định độ sâu của đầu ra. Ví dụ, nếu sử dụng ba filters, sẽ tạo ra ba feature maps, và độ sâu của đầu ra là ba.
- Stride: Là bước di chuyển của kernel trên ma trận đầu vào, xác định khoảng cách giữa các lần quét. Stride lớn sẽ tạo ra đầu ra nhỏ hơn.
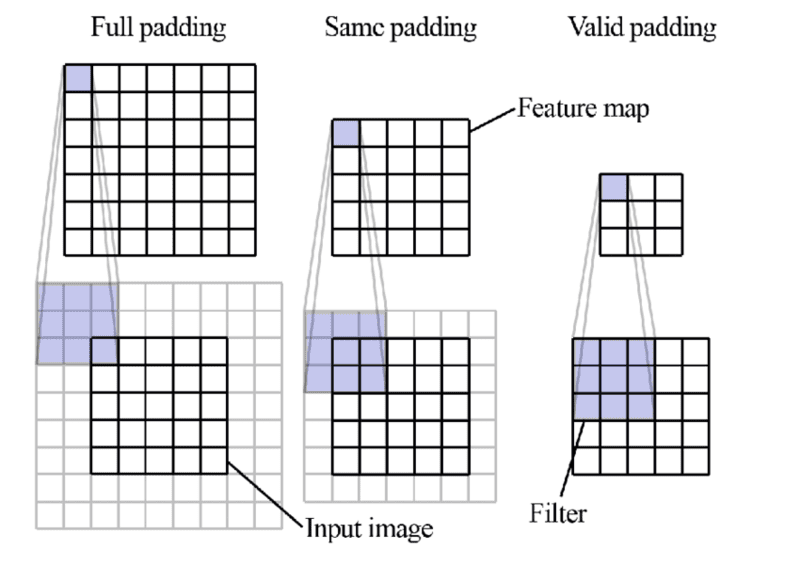
- Zero-padding: Được sử dụng khi kích thước của filter không khớp với kích thước của hình ảnh đầu vào. Padding có thể giúp tạo ra đầu ra lớn hơn hoặc giữ nguyên kích thước đầu ra. Có ba loại padding:
- Valid padding: Không sử dụng padding, dẫn đến một số phép tính bị bỏ qua.
- Same padding: Đảm bảo rằng đầu ra có cùng kích thước với đầu vào.
- Full padding: Thêm số không vào biên của đầu vào, làm tăng kích thước đầu ra.
Sau mỗi phép toán convolution, CNN sẽ áp dụng một phép biến đổi ReLU (Rectified Linear Unit) lên feature map, giúp đưa tính phi tuyến tính vào mô hình và cải thiện khả năng học của mạng nơ-ron.
Additional convolutional layer
Như đã đề cập trước, một Convolutional Layer có thể được thêm vào sau Convolutional Layer đầu tiên trong mạng nơ-ron. Khi có thêm các lớp như vậy, cấu trúc của CNN trở nên phân cấp, tức là các tầng sau có thể nhìn thấy các pixel trong receptive fields (vùng cảm nhận) của các tầng trước đó.
Ví dụ, giả sử chúng ta muốn xác định xem một hình ảnh có chứa xe đạp hay không. Bạn có thể hình dung xe đạp là sự kết hợp của các bộ phận như khung, tay lái, bánh xe, bàn đạp,… Mỗi bộ phận của xe đạp sẽ tạo thành một mẫu nhỏ (mẫu cấp thấp) trong neural network. Sự kết hợp của các bộ phận này tạo thành một mẫu phức tạp hơn (mẫu cấp cao), giúp nhận diện xe đạp trong hình ảnh.
Nhờ vào việc sử dụng nhiều Convolutional Layers, CNN có thể xây dựng một hệ thống phân cấp các đặc trưng, từ các chi tiết nhỏ đến các hình ảnh phức tạp, giúp mạng nơ-ron hiểu và phân tích hình ảnh một cách hiệu quả. Cuối cùng, các Convolutional Layers chuyển hình ảnh thành các giá trị số, giúp Neural Network có thể phân tích và trích xuất các mẫu quan trọng để nhận diện đối tượng.
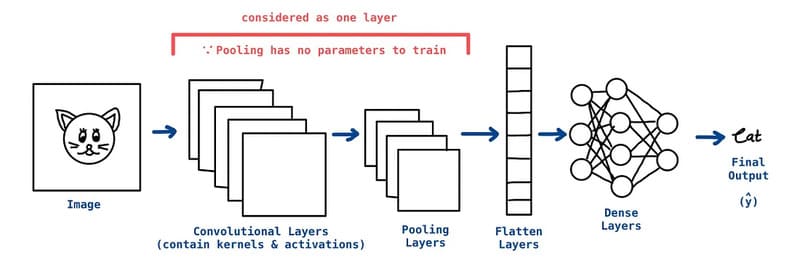
Pooling layer
Pooling Layers, hay còn gọi là downsampling, có nhiệm vụ giảm chiều dữ liệu và giảm số lượng tham số trong đầu vào. Tương tự như Convolutional Layers, Pooling Layers cũng sử dụng một filter (hoặc kernel) để quét qua toàn bộ đầu vào. Tuy nhiên, khác với Convolutional Layers, filter trong Pooling Layers không có trọng số. Thay vào đó, nó áp dụng một phép toán tổng hợp lên các giá trị trong receptive field (vùng cảm nhận) để đưa ra giá trị cho mảng đầu ra.
Có hai loại Pooling chính:
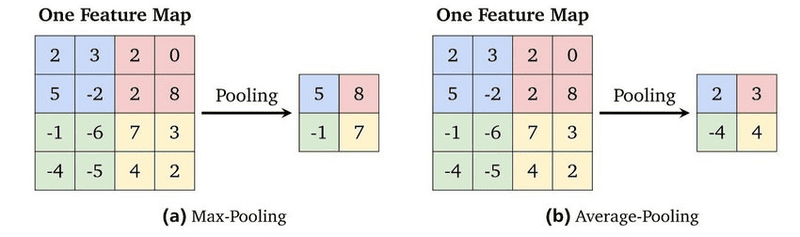
- Max Pooling: Khi filter di chuyển qua đầu vào, nó chọn pixel có giá trị lớn nhất trong vùng quét và đưa giá trị đó vào mảng đầu ra. Đây là phương pháp phổ biến nhất trong các mạng nơ-ron.
- Average Pooling: Khi filter di chuyển qua đầu vào, nó tính giá trị trung bình của các pixel trong vùng quét và đưa giá trị trung bình đó vào mảng đầu ra.
Mặc dù Pooling Layer làm giảm thông tin trong dữ liệu nhưng nó cũng giảm độ phức tạp tính toán, cải thiện hiệu suất và đặc biệt hạn chế hiện tượng overfitting.
Fully-connected layer
Tên của Fully-connected Layer (FC Layer) đã mô tả chính xác vai trò của nó. Khác với các tầng trước trong mạng nơ-ron, nơi các giá trị pixel của hình ảnh đầu vào không được kết nối trực tiếp với tầng đầu ra, trong Fully-connected Layer, mỗi node (nút) trong tầng đầu ra sẽ kết nối trực tiếp với mỗi node trong tầng trước đó.
Tầng này chịu trách nhiệm phân loại dựa trên các đặc trưng mà mạng đã trích xuất từ các tầng trước qua các filters khác nhau. Trong khi Convolutional Layers và Pooling Layers thường sử dụng hàm kích hoạt ReLU, thì Fully-connected Layers chủ yếu sử dụng hàm kích hoạt Softmax để phân loại đầu vào, tạo ra một xác suất từ 0 đến 1 cho mỗi lớp mà nó dự đoán.
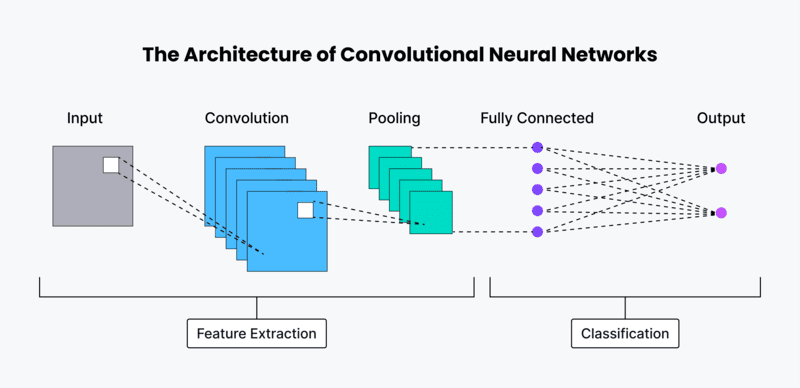
Các loại Convolutional neural network
Mạng nơ-ron tích chập (Convolutional neural network – CNN) đã trở thành nền tảng của công nghệ thị giác máy tính (Computer Vision) hiện đại. Từ nền móng được đặt bởi Kunihiko Fukushima và Yann LeCun vào những năm 1980-1990, CNN đã không ngừng phát triển đột phá về cấu trúc và hiệu suất qua các thế hệ mô hình khác nhau. Dưới đây là tổng quan về các kiến trúc Convolutional neural network nổi bật nhất:
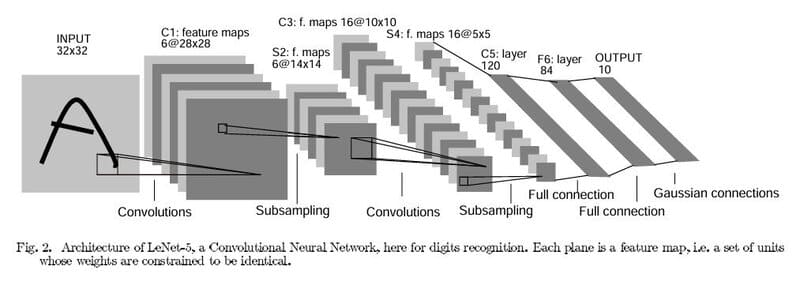
LeNet
LeNet-5 là một trong những kiến trúc CNN đầu tiên và quan trọng nhất, được phát triển bởi Yann LeCun vào cuối những năm 1980. Được thiết kế chủ yếu để nhận diện chữ số viết tay trên bộ dữ liệu MNIST, mô hình này có cấu trúc đơn giản gồm các lớp tích chập xen kẽ với các lớp gộp (pooling), sau đó là các lớp kết nối đầy đủ để phân loại.
Mặc dù tương đối nhỏ so với các mô hình hiện đại, LeNet đã chứng minh hiệu quả vượt trội của CNN trong việc trích xuất đặc trưng từ hình ảnh, đặt nền móng cho mọi kiến trúc CNN sau này và đánh dấu bước ngoặt quan trọng trong lịch sử thị giác máy tính.
AlexNet
AlexNet, được phát triển bởi Alex Krizhevsky, Ilya Sutskever và Geoffrey Hinton vào năm 2012, là mô hình CNN đầu tiên giành chiến thắng trong cuộc thi ImageNet (ILSVRC) và đánh dấu sự bùng nổ của kỷ nguyên học sâu. Cấu trúc của AlexNet gồm năm lớp tích chập xen kẽ với ba lớp gộp, sau đó là ba lớp kết nối đầy đủ. Đột phá lớn nhất của mô hình này là việc sử dụng hàm kích hoạt ReLU giúp tăng tốc độ huấn luyện đáng kể, cùng với kỹ thuật Dropout để giảm overfitting và ứng dụng GPU để tính toán hiệu quả, mở ra thời đại mới cho CNN trong nhận dạng hình ảnh.
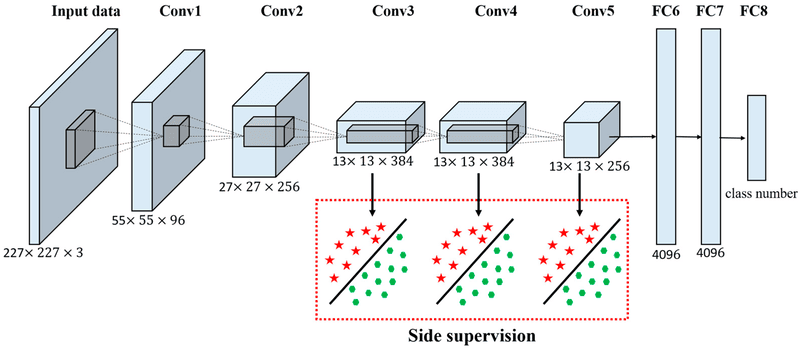
VGGNet
VGGNet, được phát triển bởi nhóm nghiên cứu Visual Geometry Group tại Đại học Oxford, nổi bật với thiết kế đơn giản nhưng cực kỳ hiệu quả. Mô hình này sử dụng các bộ lọc 3×3 được xếp chồng lên nhau một cách đồng nhất, với hai phiên bản phổ biến nhất là VGG-16 và VGG-19 (có 16 và 19 lớp tích chập tương ứng).
Mặc dù VGG đạt kết quả xuất sắc trong nhận diện hình ảnh, nhưng nó cũng nổi tiếng với số lượng tham số khổng lồ (khoảng 138 triệu), làm cho mô hình trở nên nặng nề về mặt tính toán nhưng vẫn được ưa chuộng vì cấu trúc đơn giản, rõ ràng và dễ hiểu.
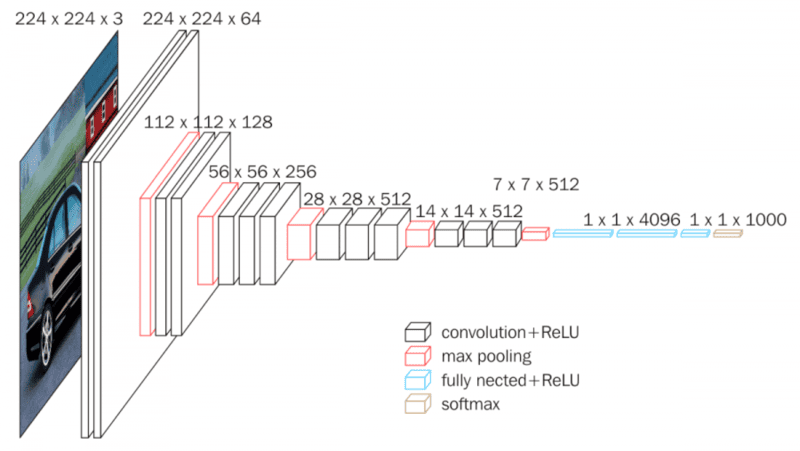
GoogLeNet (Inception)
GoogLeNet, còn được gọi là Inception v1, được phát triển bởi Google và giành chiến thắng trong cuộc thi ImageNet năm 2014. Điểm đặc biệt của mô hình này là sử dụng “Inception Modules” – một cơ chế cho phép mạng học các đặc trưng ở nhiều mức độ khác nhau bằng cách áp dụng đồng thời các bộ lọc có kích thước khác nhau trên cùng một lớp. Với tổng cộng 22 lớp (hoặc 27 lớp nếu tính cả các lớp gộp), GoogLeNet vẫn duy trì số lượng tham số ở mức thấp, giúp giảm đáng kể yêu cầu bộ nhớ và tăng tốc độ huấn luyện mà vẫn đạt được độ chính xác cao.
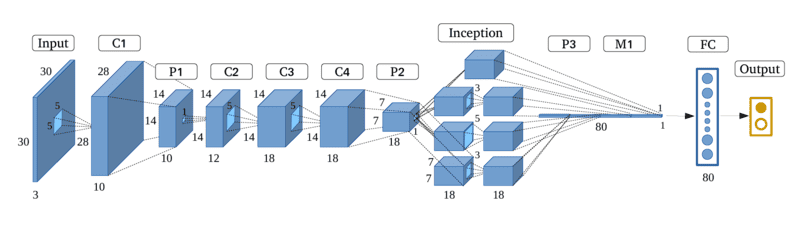
ResNet
ResNet (Residual Network), được giới thiệu bởi nhóm nghiên cứu Microsoft vào năm 2015, đã giải quyết vấn đề nan giải trong việc huấn luyện mạng neuron cực kỳ sâu – vanishing gradient (suy giảm đạo hàm). Bí quyết thành công của ResNet nằm ở việc sử dụng “skip connections” (kết nối tắt), cho phép thông tin đi qua một số lớp mà không bị suy giảm, giúp mạng học được cách tổng quát hoá các biểu diễn tốt hơn.
Với nhiều phiên bản từ ResNet-18 đến ResNet-152, mô hình này đã giành chiến thắng ấn tượng trong cuộc thi ImageNet 2015 với độ lỗi chỉ 3,57% – thấp hơn cả khả năng nhận diện của con người, đánh dấu một bước tiến vượt bậc trong lĩnh vực thị giác máy tính.
Lợi ích của mạng nơ-ron tích chập (CNN)
Khi tìm hiểu CNN là gì, có thể thấy CNN nổi bật nhờ khả năng tự động học và trích xuất đặc trưng từ dữ liệu hình ảnh. Nhờ cơ chế này, mô hình đạt độ chính xác cao và được ứng dụng rộng rãi trong nhiều bài toán thị giác máy tính.
- Độ chính xác cao trong thị giác máy tính: Ưu điểm lớn nhất của CNN là khả năng nhận diện và phân loại hình ảnh với độ chính xác cao. Thông qua cơ chế tích chập, mô hình phân tích dữ liệu theo từng cấp độ: từ đặc trưng cơ bản như cạnh, góc đến đặc điểm phức tạp như hình dạng và kết cấu. Nhờ đó, CNN được sử dụng hiệu quả trong nhận diện khuôn mặt, chẩn đoán hình ảnh y tế, giám sát an ninh và xe tự hành.
- Tự động trích xuất đặc trưng: Trước đây, việc trích xuất đặc trưng từ hình ảnh cần thực hiện thủ công. Với CNN, quá trình này được tự động hóa hoàn toàn. Các lớp tích chập đầu nhận diện đặc trưng đơn giản, trong khi các lớp sâu hơn học các mẫu phức tạp. Từ đó giúp giảm công sức xử lý thủ công và tăng hiệu quả huấn luyện mô hình.
- Tái sử dụng mô hình với Transfer Learning: CNN cho phép áp dụng Transfer Learning, tức là tận dụng các mô hình đã được huấn luyện sẵn trên tập dữ liệu lớn như ImageNet và điều chỉnh cho bài toán mới. Cách tiếp cận này giúp tiết kiệm tài nguyên tính toán, rút ngắn thời gian huấn luyện và đặc biệt hữu ích trong các lĩnh vực có dữ liệu hạn chế như y tế hoặc sản xuất công nghiệp.
- Hiệu suất cao nhờ chia sẻ tham số: Khác với mạng nơ-ron truyền thống, CNN sử dụng cơ chế chia sẻ tham số thông qua các bộ lọc (filters). Nhờ đó, số lượng tham số cần huấn luyện giảm đáng kể, giúp tối ưu tốc độ xử lý và tiết kiệm tài nguyên. CNN có thể triển khai hiệu quả trên nhiều nền tảng, từ máy chủ GPU đến thiết bị di động và hệ thống edge computing.
- Khả năng tổng quát hóa tốt, hạn chế overfitting: CNN cải thiện khả năng tổng quát hóa nhờ Pooling Layer và các kỹ thuật như Dropout. Pooling giúp giảm kích thước dữ liệu và giữ lại thông tin quan trọng, trong khi Dropout vô hiệu hóa ngẫu nhiên một số nơ-ron trong quá trình huấn luyện để tránh học quá mức dữ liệu huấn luyện. Nhờ đó, mô hình hoạt động ổn định hơn khi xử lý dữ liệu mới.
Ứng dụng của mạng nơ-ron tích chập trong thực tế
Nhờ khả năng tự động trích xuất đặc trưng và nhận diện hình ảnh với độ chính xác cao, Convolutional Neural Networks (CNN) được ứng dụng rộng rãi trong nhiều lĩnh vực như y tế, ô tô tự lái, mạng xã hội, thương mại điện tử và trợ lý ảo.
Y tế
Trong lĩnh vực y tế, CNN được sử dụng để phân tích hình ảnh X-quang, MRI, CT scan và ảnh mô bệnh học. Mô hình có thể phát hiện khối u trong ảnh não, xác định tổn thương phổi, hoặc đánh giá bệnh lý võng mạc do tiểu đường. Nhờ khả năng xử lý nhanh và chính xác, CNN hỗ trợ bác sĩ chẩn đoán sớm và nâng cao hiệu quả điều trị.
Ngành ô tô
CNN đóng vai trò cốt lõi trong hệ thống xe tự hành. Thông qua dữ liệu từ camera và cảm biến, mô hình có thể nhận diện làn đường, biển báo giao thông, người đi bộ và phương tiện khác. Ngoài ra, CNN còn được tích hợp trong các tính năng như cảnh báo va chạm, kiểm soát hành trình và hỗ trợ đỗ xe, giúp tăng mức độ an toàn khi vận hành.
Mạng xã hội
Các nền tảng mạng xã hội sử dụng CNN để nhận diện khuôn mặt, hỗ trợ gợi ý gắn thẻ trong ảnh. Đồng thời, mô hình cũng giúp phát hiện và lọc nội dung vi phạm như hình ảnh bạo lực hoặc nội dung không phù hợp, góp phần duy trì môi trường trực tuyến an toàn.
Thương mại điện tử
CNN cho phép người dùng tìm kiếm sản phẩm bằng cách tải lên hình ảnh thay vì nhập từ khóa. Hệ thống phân tích đặc điểm như màu sắc, hình dạng và kết cấu để đề xuất sản phẩm tương tự. Ngoài ra, CNN còn hỗ trợ cá nhân hóa gợi ý sản phẩm dựa trên lịch sử duyệt ảnh, giúp nâng cao trải nghiệm mua sắm và tăng tỷ lệ chuyển đổi.
Trợ lý ảo
Bên cạnh xử lý hình ảnh, CNN cũng được ứng dụng trong nhận diện giọng nói. Các trợ lý ảo như Google Assistant, Siri hay Alexa sử dụng CNN để phân tích âm thanh và nhận diện từ khóa chính xác hơn. Nhờ đó, hệ thống có thể hiểu lệnh người dùng, phản hồi theo ngữ cảnh và cải thiện độ chính xác trong giao tiếp.
Hướng dẫn lựa chọn tham số cho CNN
Hiệu suất của Convolutional Neural Networks (CNN) phụ thuộc lớn vào cách thiết lập các tham số trong quá trình xây dựng và huấn luyện mô hình. Việc lựa chọn tham số phù hợp giúp tăng độ chính xác, tối ưu tài nguyên tính toán và hạn chế tình trạng overfitting hoặc underfitting. Dưới đây là những tham số quan trọng cần lưu ý khi triển khai CNN.
Lựa chọn số lượng Convolution Layer phù hợp
Số lượng lớp tích chập ảnh hưởng trực tiếp đến khả năng học đặc trưng của mô hình. Các lớp đầu tiên thường nhận diện đặc trưng cơ bản như cạnh, góc hoặc đường viền. Các lớp sâu hơn sẽ xử lý đặc trưng phức tạp hơn như hình dạng, cấu trúc hoặc kết cấu của đối tượng.
Nếu CNN có quá ít lớp, mô hình có thể không đủ khả năng trích xuất đặc trưng nâng cao. Ngược lại, nếu số lớp quá nhiều mà không có kỹ thuật hỗ trợ, mô hình có thể gặp vấn đề vanishing gradient hoặc khó hội tụ.
Khuyến nghị thực tế:
- Với bài toán phân loại ảnh thông thường: 3–5 lớp tích chập là hợp lý.
- Với mô hình lớn như ResNet hoặc VGG: có thể sử dụng nhiều lớp hơn, nhưng nên kết hợp Batch Normalization hoặc Skip Connection để ổn định quá trình huấn luyện.
Chọn kích thước bộ lọc (Filter Size)
Kích thước bộ lọc (kernel) quyết định cách CNN quan sát và trích xuất đặc trưng từ hình ảnh. Tùy theo nhu cầu mà có thể lựa chọn các loại Kernel sau:
- Kernel 3×3 là lựa chọn phổ biến nhất vì cân bằng giữa hiệu quả và chi phí tính toán.
- Kernel 5×5 hoặc 7×7 phù hợp khi cần nhận diện đặc trưng lớn hơn, thường áp dụng ở các lớp đầu.
Trong thực tế, nhiều kiến trúc hiện đại ưu tiên sử dụng nhiều kernel 3×3 liên tiếp thay vì một kernel lớn, giúp giảm số lượng tham số nhưng vẫn giữ khả năng học đặc trưng phức tạp.
Xác định kích thước Pooling Layer
Pooling Layer giúp giảm kích thước feature map, từ đó giảm số tham số và tăng tốc độ tính toán. Hiện nay, max Pooling 2×2 là cấu hình phổ biến nhất trong các bài toán thị giác máy tính. Trường hợp ảnh có độ phân giải cao, có thể sử dụng pooling lớn hơn (ví dụ 4×4), nhưng cần kiểm tra xem có làm mất thông tin quan trọng hay không.
Việc lựa chọn kích thước pooling phù hợp giúp CNN hoạt động hiệu quả mà vẫn giữ được đặc trưng quan trọng.
Thiết lập số Epochs và cách chia dữ liệu
Số epoch quyết định số lần mô hình học qua toàn bộ dữ liệu huấn luyện. Nếu quá ít epoch, mô hình sẽ chưa học đủ đặc trưng. Ngược lại nếu quá nhiều epoch, sẽ dễ dẫn đến overfitting.
Cách thiết lập hợp lý:
- Bắt đầu với 10–50 epochs và theo dõi các chỉ số như loss và accuracy.
- Sử dụng Early Stopping nếu hiệu suất trên tập validation giảm.
- Chia dữ liệu theo tỷ lệ 80% train – 20% test hoặc 70% train – 15% validation – 15% test để đánh giá khách quan.
Thách thức và hạn chế của Convolutional neural network
Mặc dù Convolutional Neural Networks (CNN) mang lại độ chính xác cao trong nhiều bài toán thị giác máy tính, mô hình này vẫn tồn tại một số hạn chế cần lưu ý khi triển khai thực tế:
- Yêu cầu tài nguyên tính toán lớn: Huấn luyện CNN, đặc biệt các mô hình sâu như ResNet hay VGG, cần GPU hoặc TPU mạnh để xử lý khối lượng lớn tham số, làm tăng chi phí vận hành.
- Phụ thuộc vào dữ liệu huấn luyện lớn: CNN hoạt động tốt khi có tập dữ liệu lớn và được gán nhãn đầy đủ. Nếu dữ liệu hạn chế hoặc thiếu đa dạng, mô hình dễ bị overfitting và giảm khả năng dự đoán trên dữ liệu mới.
- Cấu trúc phức tạp, khó tối ưu tham số: CNN có nhiều siêu tham số như số lớp, kích thước kernel, learning rate, batch size. Việc tinh chỉnh không đúng có thể khiến mô hình hội tụ chậm hoặc không đạt hiệu suất mong muốn.
- Khó giải thích kết quả (tính minh bạch thấp): CNN thường được xem như “hộp đen”, khó xác định chính xác vì sao mô hình đưa ra một dự đoán cụ thể. Điều này gây trở ngại trong các lĩnh vực yêu cầu giải trình rõ ràng như y tế hoặc tài chính.
- Nguy cơ overfitting cao nếu không kiểm soát tốt: Nếu không áp dụng các kỹ thuật như Dropout, Regularization hoặc Data Augmentation, mô hình có thể học quá kỹ dữ liệu huấn luyện và giảm độ chính xác khi gặp dữ liệu mới.
Tóm lại, Convolutional neural network (CNNs) đã và đang đóng một vai trò quan trọng trong nhận diện và phân tích dữ liệu trực quan. Các kiến trúc CNNs như LeNet, AlexNet, VGGNet, và ResNet đã chứng minh hiệu quả vượt trội trong việc giải quyết các vấn đề về nhận diện hình ảnh. Với khả năng mạnh mẽ và tính linh hoạt, CNNs hiện đang là nền tảng không thể thiếu trong các ứng dụng như thị giác máy tính, y tế, marketing và nhiều lĩnh vực khác. Tuy nhiên, để sử dụng CNN hiệu quả, cần cân đối giữa tài nguyên, dữ liệu và chiến lược tối ưu mô hình.
Có thể bạn quan tâm:
- Callbot là gì? Lợi ích và cách áp dụng callbot vào doanh nghiệp
- TOP 12 phần mềm chuyển văn bản thành giọng nói AI tiếng việt miễn phí