Fine-tuning trong Machine Learning là quá trình điều chỉnh một mô hình đã được pre-trained trên một tập dữ liệu nhỏ hơn, có mục tiêu cụ thể nhằm tối ưu hóa hiệu suất cho các tác vụ hoặc trường hợp sử dụng chuyên biệt. Fine-tuning tiết kiệm tài nguyên tính toán và gán nhãn dữ liệu, mang lại hiệu suất xử lý vượt xa so với mô hình pre-trained ban đầu.
Trong bài viết này, FPT.AI sẽ mô tả cụ thể các trường hợp sử dụng phổ biến, phân tích những rủi ro và lợi ích của fine-tuning trong thực tế. Bài viết cũng so sánh fine-tuning với RAG, transfer learning và prompt engineering để giúp bạn lựa chọn phương pháp phù hợp nhất cho nhu cầu cụ thể của mình.
Fine-tuning là gì?
Fine-tuning trong Machine Learning là quá trình điều chỉnh một mô hình đã được pre-trained trên một tập dữ liệu nhỏ hơn, có mục tiêu cụ thể nhằm tối ưu hóa hiệu suất cho các tác vụ hoặc trường hợp sử dụng cụ thể. Fine-tuning có thể được coi là một tập hợp con của Transfer Learning, cho phép tận dụng kiến thức mà mô hình hiện có đã học được làm điểm khởi đầu để tiếp thu kiến thức mới.
Về cơ bản, việc trau dồi khả năng của một base model đã được pre-trained sẽ dễ và rẻ hơn xây dựng và đào tạo một mô hình hoàn toàn mới từ đầu. Điều này đặc biệt hiệu quả với các mô hình Deep Learning phức tạp, có hàng triệu hoặc thậm chí hàng tỷ tham số, như các mô hình ngôn ngữ lớn (LLMs) trong lĩnh vực xử lý ngôn ngữ tự nhiên hoặc các Convolutional Neural Networks (CNNs) và Vision Transformers (ViTs) được sử dụng cho các tác vụ Computer Vision. Vậy Transformer Model là gì? Đây là kiến trúc mạng nơ-ron dựa trên cơ chế self-attention, giúp mô hình hóa quan hệ giữa các token/đặc trưng và hỗ trợ tính toán song song hiệu quả.
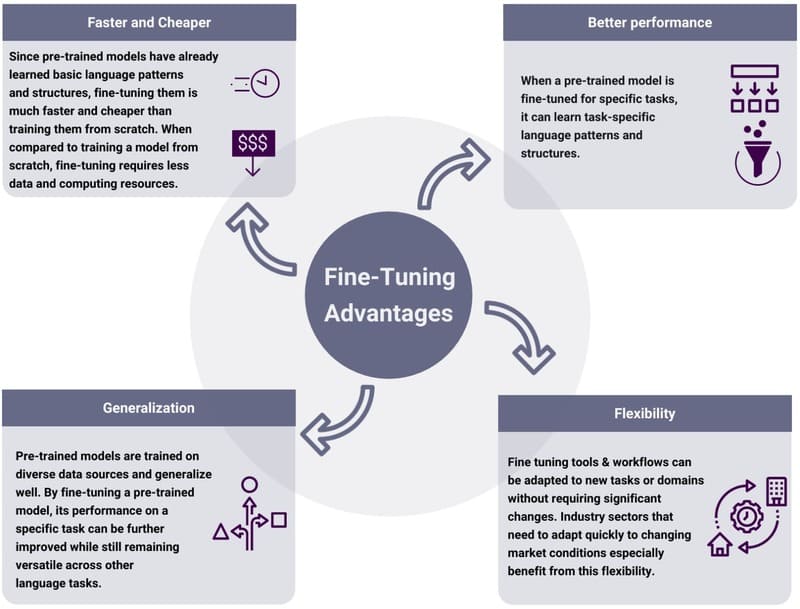
Fine-tuning không chỉ giảm đáng kể lượng sức mạnh tính toán đắt tiền và dữ liệu có nhãn cần thiết để có được các mô hình được điều chỉnh cho các nhu cầu kinh doanh ngách, hiệu suất của một mô hình fine-tuned cũng vượt trội hơn mô hình pre-trained ban đầu. Ví dụ, một doanh nghiệp muốn tích hợp AI tạo sinh vào hệ thống hỗ trợ khách hàng có thể fine-tune một LLM trên dữ liệu về thông tin sản phẩm, chính sách công ty và lịch sử tương tác với khách hàng. Mô hình fine-tuned sẽ cung cấp các phản hồi phù hợp và hữu ích hơn so với mô hình tổng quát ban đầu.
Fine-tuning đặc biệt có giá trị khi tài nguyên tính toán bị hạn chế hoặc dữ liệu liên quan khan hiếm. Phương pháp này cho phép bổ sung kiến thức từ bộ dữ liệu đào tạo ban đầu với dữ liệu độc quyền hoặc kiến thức chuyên ngành. Đây là một kỹ thuật Deep Learning quan trọng trong hành trình phổ biến hóa việc tiếp cận và tùy chỉnh các Foundation Models sử dụng cho Generative AI.
Điểm khác biệt giữa Fine-tuning và Pre-Training là gì?
Pre-training và Fine-tuning là hai giai đoạn khác nhau trong quá trình phát triển mô hình học máy, đặc biệt là các mô hình học sâu.
Pre-training là giai đoạn đầu tiên khi xây dựng một mô hình, bắt đầu với các tham số được khởi tạo ngẫu nhiên. Pre-training áp dụng các trọng số và độ lệch khác nhau cho các phép toán xảy ra tại mỗi node trong neural network. Trong giai đoạn này, mô hình trải qua quá trình huấn luyện trên một tập dữ liệu khổng lồ để học các kiến thức tổng quát.
Quá trình Pre-training diễn ra thông qua nhiều vòng lặp, mỗi vòng gồm hai bước:
- Forward Pass: Mô hình đưa ra dự đoán cho một batch các mẫu đầu vào từ dữ liệu huấn luyện và một hàm loss đo lường sự khác biệt giữa dự đoán và ground truth
- Backpropagation: Một thuật toán tối ưu hóa, thường là gradient descent, được sử dụng để điều chỉnh trọng số mô hình trên toàn mạng để giảm loss
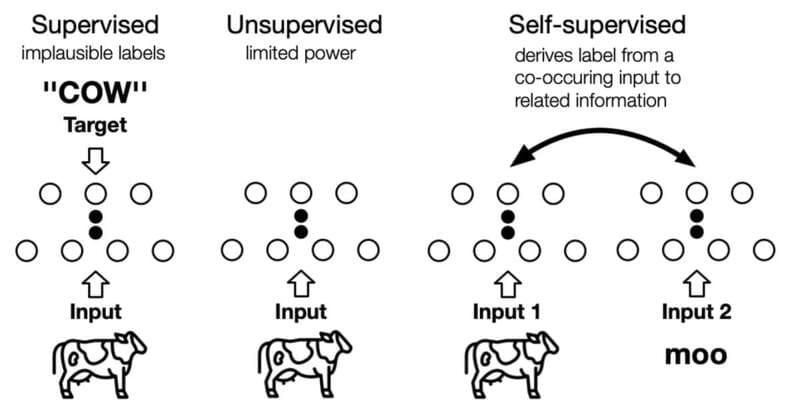
Các mô hình ngôn ngữ lớn (LLMs) thường được tiền huấn luyện thông qua Self-supervised Learning, trong đó các mô hình học thông qua các pretext tasks được thiết kế để lấy ground truth từ cấu trúc vốn có của dữ liệu không nhãn. Các pretext tasks này truyền đạt kiến thức hữu ích cho các downstream tasks qua một trong hai cách tiếp cận:
- Self-prediction: Che một phần đầu vào và yêu cầu mô hình khôi phục
- Contrastive Learning: Dạy mô hình tạo ra các biểu diễn tương tự cho dữ liệu liên quan và khác biệt cho dữ liệu không liên quan
Ngược lại, Fine-tuning là quá trình tiếp theo sau pre-training. Thay vì bắt đầu từ đầu, fine-tuning sử dụng mô hình đã được pre-trained làm điểm xuất phát, sau đó tiếp tục huấn luyện trên một tập dữ liệu nhỏ hơn và cụ thể cho nhiệm vụ đích. Phương pháp này giúp tránh hiện tượng overfitting và dễ dàng thích nghi với nhiệm vụ cụ thể.
Tóm lại, sự khác biệt chính giữa pre-training và fine-tuning nằm ở:
- Điểm khởi đầu: Pre-training bắt đầu với trọng số ngẫu nhiên; fine-tuning bắt đầu với trọng số đã được đào tạo
- Kích thước dữ liệu: Pre-training sử dụng dữ liệu khổng lồ và đa dạng; fine-tuning sử dụng dữ liệu nhỏ hơn và cụ thể hơn
- Mục tiêu: Pre-training nhằm học kiến thức tổng quát; fine-tuning nhằm chuyên biệt hóa cho tác vụ cụ thể
- Trình tự: Pre-training là giai đoạn đầu tiên; fine-tuning là giai đoạn thứ hai, xây dựng trên kết quả của pre-training
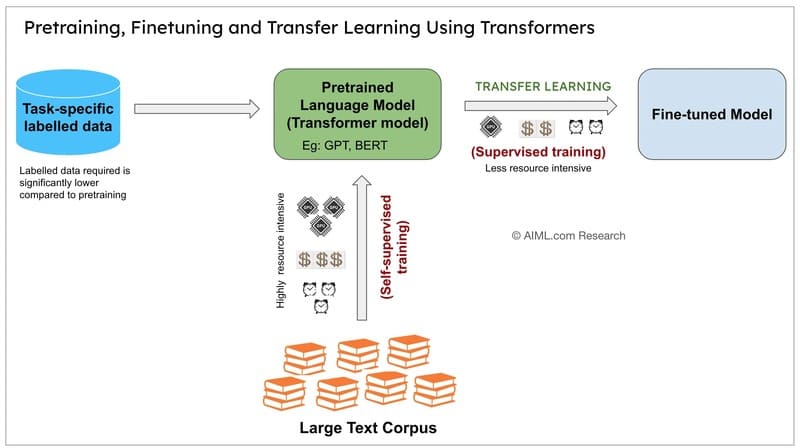
Cách thức hoạt động của Fine-tuning
Fine-tuning bắt đầu với một mô hình pretrained đã được đào tạo trên một tập dữ liệu lớn, đa dạng, học được nhiều đặc điểm và mẫu khác nhau. Trong quá trình tiền huấn luyện, mô hình đã học cách tổng quát hóa bằng cách xác định các mẫu và đặc điểm cơ bản trong dữ liệu đào tạo, giúp nó có thể diễn giải chính xác các đầu vào mới.
Để bắt đầu fine-tuning, nhà phát triển mô hình xây dựng hoặc chọn một tập dữ liệu nhỏ hơn, chuyên biệt nhắm vào trường hợp sử dụng cụ thể. Các bộ dữ liệu này truyền đạt kiến thức miền cụ thể, phong cách hoặc tác vụ mà mô hình đang được fine-tuned. Ví dụ:
- Một LLM pre-trained cho ngôn ngữ chung có thể được fine-tuned cho lập trình với một bộ dữ liệu mới chứa các yêu cầu lập trình và đoạn mã tương ứng
- Một mô hình phân loại hình ảnh có thể học các loài chim mới thông qua các mẫu đào tạo có nhãn bổ sung
- Một LLM có thể học cách bắt chước một phong cách viết cụ thể thông qua self-supervised learning trên các văn bản mẫu
Sau khi thu thập dữ liệu, nhà phát triển tiếp tục đào tạo mô hình pretrained. Thông thường, các lớp đầu của neural network, nắm bắt các đặc điểm cơ bản như kết cấu đơn giản trong hình ảnh hoặc vector embeddings trong văn bản, được “đóng băng” (giữ nguyên). Các lớp sau được điều chỉnh hoặc thêm vào để nắm bắt dữ liệu mới và phù hợp hơn với tác vụ hiện tại.
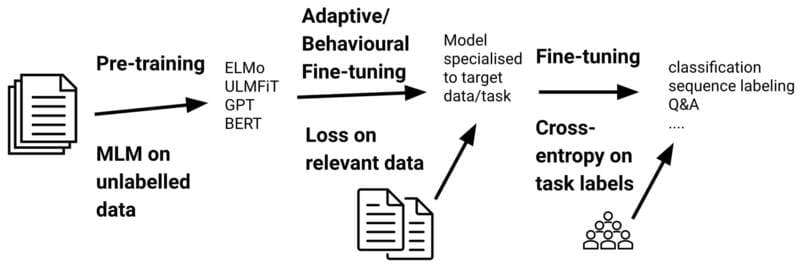
Để cân bằng giữa việc giữ lại kiến thức nền tảng quý giá và cải thiện hiệu suất cho tác vụ cụ thể, các nhà phát triển thường đặt learning rate thấp hơn – một hyperparameter mô tả mức độ điều chỉnh trọng số của mô hình trong quá trình đào tạo. Việc đặt learning rate thấp hơn giúp ngăn chặn những thay đổi mạnh đối với các trọng số đã học, đảm bảo mô hình vẫn giữ được kiến thức hiện có.
Fine-tuning thường liên quan đến supervised learning, nhưng cũng có thể liên quan đến reinforcement learning, self-supervised learning hoặc semi-supervised learning. Đặc biệt, semi-supervised learning kết hợp cả dữ liệu có nhãn và không nhãn, có lợi thế khi các ví dụ có nhãn phù hợp rất khan hiếm, giúp giảm gánh nặng thu thập đủ lượng dữ liệu có nhãn.
Các kỹ thuật Fine-tuning hàng đầu
Fine-tuning có thể được sử dụng để cập nhật trọng số của toàn bộ mạng, nhưng vì lý do thực tế, không phải lúc nào cũng như vậy. Tồn tại nhiều phương pháp fine-tuning thay thế, thường được gọi dưới thuật ngữ chung là parameter-efficient fine-tuning (PEFT), chỉ cập nhật một tập con tham số của mô hình. Các phương pháp PEFT có thể giảm yêu cầu tính toán và giảm catastrophic forgetting (hiện tượng mà fine-tuning gây ra sự mất mát kiến thức cốt lõi của mô hình), thường không có sự thỏa hiệp đáng kể về hiệu suất.
Với sự đa dạng của các kỹ thuật fine-tuning, việc đạt được hiệu suất mô hình lý tưởng thường đòi hỏi nhiều lần lặp lại các chiến lược và thiết lập đào tạo, điều chỉnh các bộ dữ liệu và hyperparameter như batch size, learning rate và các điều khoản regularization.
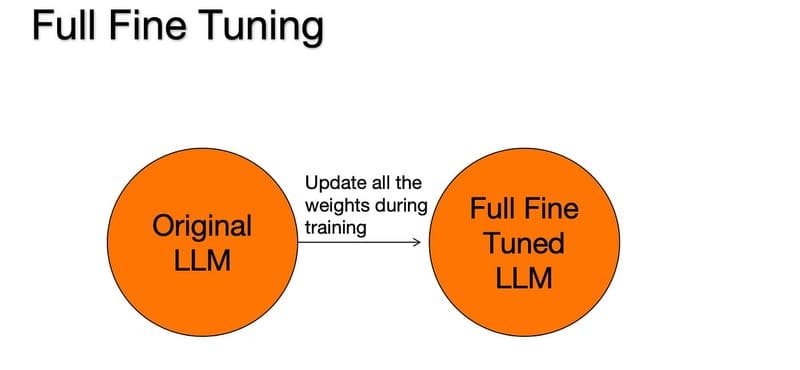
Full fine-tuning
Full fine-tuning là phương pháp đơn giản nhất về mặt khái niệm, đơn giản là cập nhật toàn bộ neural network. Phương pháp này về cơ bản giống quá trình pre-training: sự khác biệt cơ bản duy nhất giữa các quy trình full fine-tuning và pre-training là bộ dữ liệu được sử dụng và trạng thái ban đầu của tham số của mô hình.
Để tránh những thay đổi mất ổn định, một số hyperparameter có thể được điều chỉnh so với thông số kỹ thuật trong quá trình pre-training. Ví dụ, sử dụng learning rate nhỏ hơn (làm giảm độ lớn của mỗi cập nhật đối với trọng số mô hình) ít có khả năng dẫn đến catastrophic forgetting.
Parameter efficient fine-tuning (PEFT)
Full fine-tuning đòi hỏi rất nhiều tính toán, tương tự như quá trình pre-training. Đối với các mô hình deep learning hiện đại với hàng trăm triệu hoặc thậm chí hàng tỷ tham số, phương pháp này thường tốn kém và không thực tế.
Parameter efficient fine-tuning (PEFT) bao gồm một loạt các phương pháp để giảm số lượng tham số cần được cập nhật để thích ứng hiệu quả một mô hình pre-trained lớn cho các ứng dụng downstream cụ thể. PEFT giảm đáng kể tài nguyên tính toán và bộ nhớ lưu trữ cần thiết. Các phương pháp PEFT thường ổn định hơn các phương pháp full fine-tuning, đặc biệt là cho các trường hợp sử dụng NLP.

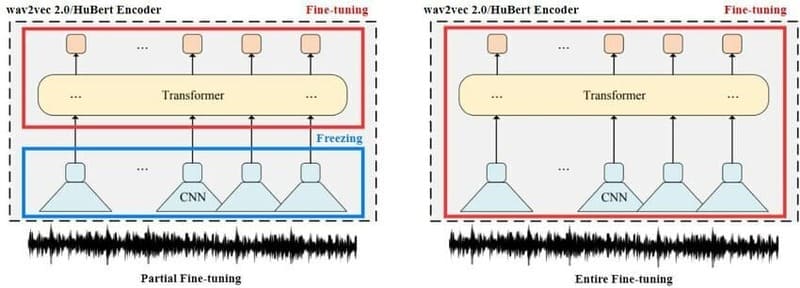
Partial fine-tuning
Còn được gọi là selective fine-tuning, các phương pháp partial fine-tuning nhằm giảm yêu cầu tính toán bằng cách chỉ cập nhật tập con được chọn của các tham số đã pre-trained quan trọng nhất đối với hiệu suất mô hình. Các tham số còn lại được “đóng băng”, đảm bảo rằng chúng sẽ không bị thay đổi.
Cách tiếp cận partial fine-tuning trực quan nhất là chỉ cập nhật các lớp ngoài của neural network. Trong hầu hết các kiến trúc mô hình, các lớp bên trong (gần với lớp đầu vào nhất) chỉ nắm bắt các đặc điểm rộng, chung chung. Ví dụ, trong một CNN được sử dụng để phân loại hình ảnh, các lớp đầu tiên thường phân biệt các cạnh và kết cấu; mỗi lớp tiếp theo phân biệt các đặc điểm ngày càng tinh tế hơn cho đến khi phân loại cuối cùng được dự đoán ở lớp ngoài cùng.
Nói chung, tác vụ mới càng giống với tác vụ ban đầu, trọng số pre-trained của các lớp bên trong sẽ càng hữu ích cho tác vụ này, và càng ít lớp cần được cập nhật.
Các phương pháp partial fine-tuning khác bao gồm chỉ cập nhật các điều khoản bias của toàn bộ lớp của mô hình (thay vì trọng số đặc trưng cho node) và các phương pháp fine-tuning “sparse” chỉ cập nhật một tập hợp con các trọng số được chọn trong toàn bộ mô hình.
Additive fine-tuning
Thay vì fine-tuning các tham số hiện có của một mô hình đã pre-trained, các phương pháp additive thêm tham số hoặc lớp bổ sung vào mô hình, đóng băng các trọng số pre-trained hiện có và chỉ đào tạo các thành phần mới đó. Cách tiếp cận này giúp duy trì sự ổn định của mô hình bằng cách đảm bảo rằng các trọng số pre-trained ban đầu vẫn không thay đổi.
Mặc dù điều này có thể làm tăng thời gian đào tạo, nhưng nó làm giảm đáng kể yêu cầu bộ nhớ vì có ít gradients và trạng thái tối ưu hóa hơn để lưu trữ. Theo Lialin và cộng sự, việc đào tạo tất cả tham số của một mô hình đòi hỏi bộ nhớ GPU nhiều hơn 12–20 lần so với chỉ riêng trọng số mô hình. Tiết kiệm bộ nhớ hơn nữa có thể đạt được thông qua quantization của các trọng số mô hình đã đóng băng, tương tự như việc giảm bitrate của một file âm thanh.
Một nhánh phụ của các phương pháp additive là prompt tuning, tương tự như prompt engineering nhưng giới thiệu soft prompts do AI tạo ra: các vector embeddings có thể học được nối với hard prompt của người dùng. Thay vì đào tạo lại mô hình, prompt tuning bao gồm việc đóng băng trọng số mô hình và thay vào đó đào tạo chính soft prompt.
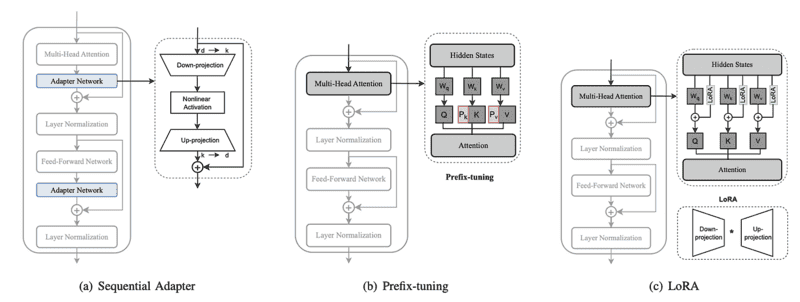
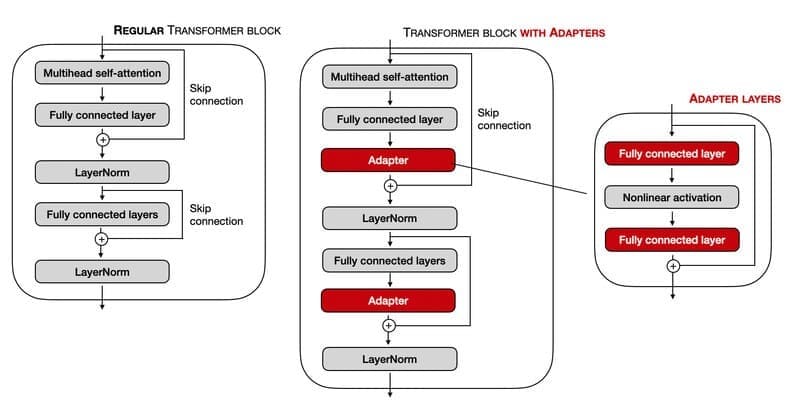
Adapters
Adapter là một tập hợp con của additive fine-tuning, đưa các adapter modules (các lớp mới, cụ thể cho tác vụ) vào neural network và đào tạo các adapter modules này thay vì fine-tuning bất kỳ trọng số mô hình pre-trained nào. Trên thực tế, đo lường kết quả trên Masked Language Model như mô hình BERT, adapters đạt được hiệu suất tương đương với full fine-tuning trong khi chỉ đào tạo 3.6% số lượng tham số.
Reparameterization
Các phương pháp dựa trên reparameterization như Low Rank Adaptation (LoRA) tận dụng low-rank transformation của các ma trận cao chiều (như ma trận khổng lồ của các trọng số mô hình pre-trained trong một transformer model. Các biểu diễn low-rank này bỏ qua thông tin cao chiều không đáng kể để nắm bắt cấu trúc thấp chiều cơ bản của trọng số mô hình, giảm đáng kể số lượng tham số có thể đào tạo.
LoRA từ bỏ việc tối ưu hóa trực tiếp ma trận trọng số mô hình và thay vào đó tối ưu hóa một ma trận cập nhật trọng số mô hình (delta weights), được chèn vào mô hình. Ma trận cập nhật này được biểu diễn dưới dạng hai ma trận nhỏ hơn (lower rank), giảm đáng kể số lượng tham số cần được cập nhật, đẩy nhanh quá trình fine-tuning và giảm bộ nhớ cần thiết.
Một lợi ích bổ sung của LoRA là, vì những gì đang được tối ưu hóa và lưu trữ là sự khác biệt (delta) giữa các trọng số pre-trained ban đầu và các trọng số fine-tuned, các LoRA cụ thể cho tác vụ khác nhau có thể được “hoán đổi” khi cần thiết để điều chỉnh mô hình pre-trained cho một trường hợp sử dụng nhất định.
Một loạt các dẫn xuất của LoRA đã được phát triển, chẳng hạn như QLoRA, làm giảm hơn nữa độ phức tạp tính toán bằng cách lượng tử hóa transformer model trước khi thực hiện LoRA.
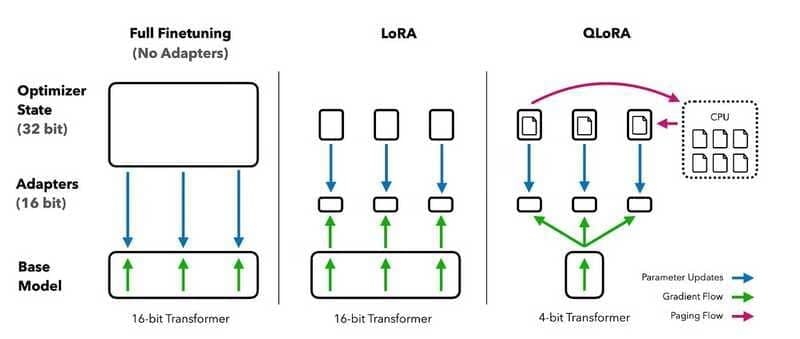
Fine-tuning large language models
Fine-tuning là một phần thiết yếu của chu kỳ phát triển LLM, cho phép các khả năng ngôn ngữ thô của các base foundation models được điều chỉnh cho nhiều trường hợp sử dụng, từ chatbots đến lập trình và các lĩnh vực khác.
Quá trình Fine-tuning Large Language Models
LLMs được pre-train bằng cách sử dụng self-supervised learning trên một kho ngữ liệu khổng lồ của dữ liệu không nhãn. Autoregressive language models, như GPT của OpenAI, Gemini của Google hoặc các mô hình Llama của Meta, được đào tạo để dự đoán từ tiếp theo trong một chuỗi cho đến khi nó hoàn thành.
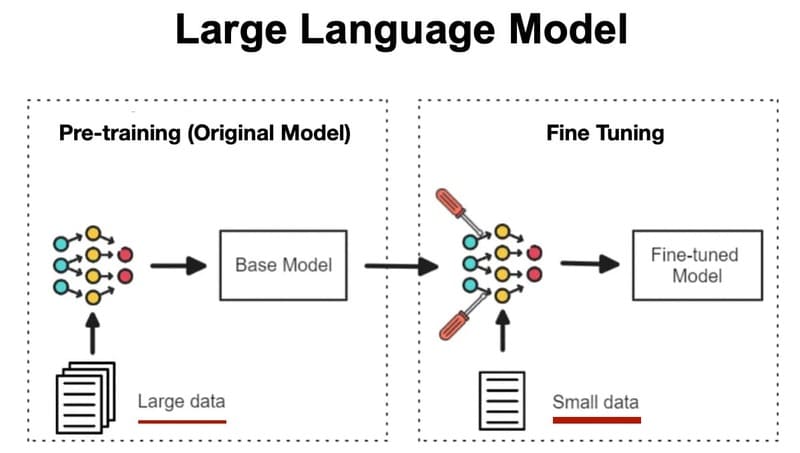
Trong pre-training, các mô hình được cung cấp phần đầu của một câu mẫu lấy từ dữ liệu đào tạo và được giao nhiệm vụ liên tục dự đoán từ tiếp theo trong chuỗi. Đối với mỗi dự đoán, từ tiếp theo thực tế của câu mẫu ban đầu đóng vai trò là ground truth.
Mặc dù pre-training này mang lại khả năng tạo văn bản mạnh mẽ, nhưng không mang lại sự hiểu biết thực sự về ý định của người dùng. Ở mức cơ bản, autoregressive LLMs không thực sự trả lời prompt; chúng chỉ thêm văn bản vào đó. Nếu không có hướng dẫn rất cụ thể dưới dạng prompt engineering, một LLM pre-trained (chưa được fine-tuned) chỉ đơn giản dự đoán từ tiếp theo có thể có trong một chuỗi được bắt đầu bởi prompt.
Ví dụ, nếu được nhắc với “dạy tôi cách tạo một resumé”, một LLM chưa fine-tuned có thể trả lời với “sử dụng Microsoft Word”. Đó là một cách hợp lệ để hoàn thành câu, nhưng không phù hợp với mục tiêu của người dùng. Mô hình có thể đã có kiến thức đáng kể về việc viết resumé, nhưng nếu không fine-tuning, kiến thức này có thể không được truy cập.
Do đó, quá trình fine-tuning đóng vai trò quan trọng không chỉ trong việc điều chỉnh foundation models cho giọng điệu và trường hợp sử dụng độc đáo, mà còn trong việc làm cho chúng hoàn toàn phù hợp cho việc sử dụng thực tế.
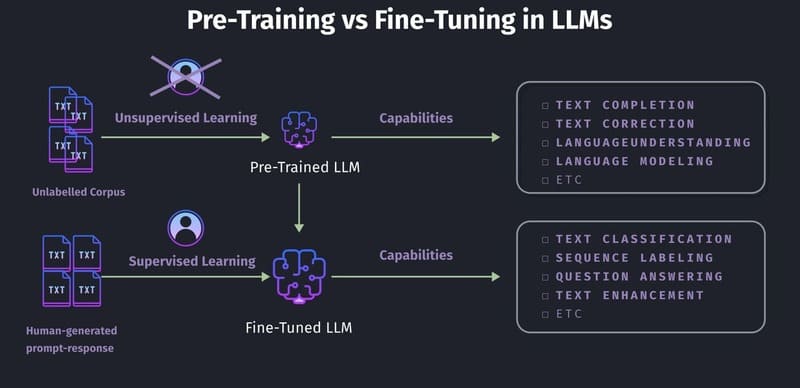
Các phương pháp Fine-tuning large language models
Instruction tuning
Instruction tuning là một tập con của supervised fine-tuning (SFT), thường được sử dụng để fine-tune LLM cho việc sử dụng chatbot, giúp LLM tạo ra các phản hồi giải quyết trực tiếp hơn nhu cầu của người dùng và tuân theo các hướng dẫn tốt hơn.
Các ví dụ đã được gán nhãn, theo định dạng (prompt, response) – trong đó các prompt mẫu bao gồm các tác vụ định hướng hướng dẫn, như “dịch câu sau từ tiếng Anh sang tiếng Tây Ban Nha” hoặc “phân loại câu sau là Tích cực hoặc Tiêu cực” – thể hiện cách phản hồi với các prompt đại diện cho nhiều trường hợp sử dụng, như trả lời câu hỏi, tóm tắt hoặc dịch thuật.
Trong việc cập nhật trọng số mô hình để giảm thiểu loss giữa đầu ra của mô hình và các mẫu đã được gán nhãn, LLM học cách thêm văn bản vào các prompt theo cách hữu ích hơn và tuân theo các hướng dẫn tốt hơn. Tiếp tục ví dụ prompt trước đây về “dạy tôi cách viết một bản lý lịch,” tập dữ liệu được sử dụng cho SFT có thể chứa một số cặp (prompt, response) chứng minh rằng cách mong muốn để phản hồi là cung cấp các gợi ý từng bước, thay vì chỉ hoàn thành câu.
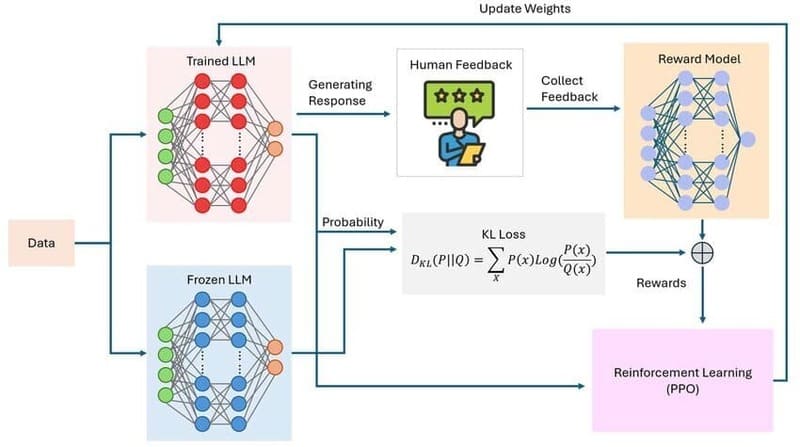
Reinforcement learning from human feedback (RLHF)
Mặc dù instruction tuning có thể dạy mô hình các hành vi hữu hình, đơn giản như cách cấu trúc các phản hồi, nhưng việc dạy các phẩm chất trừu tượng của con người như sự hữu ích, độ chính xác, sự hài hước hoặc sự đồng cảm thông qua các ví dụ đã được gán nhãn có thể rất tốn công sức và khó khăn.
Để điều chỉnh đầu ra của mô hình phù hợp hơn với hành vi con người lý tưởng, đặc biệt là cho các trường hợp sử dụng hội thoại như chatbot, SFT có thể được bổ sung bằng reinforcement learning, cụ thể hơn là RLHF. RLHF (còn được gọi là reinforcement learning from human preferences) giúp fine-tune các mô hình cho các phẩm chất phức tạp, không được định nghĩa rõ ràng hoặc khó xác định thông qua các ví dụ rời rạc.
Ví dụ, để dạy một mô hình trở nên “hài hước” với SFT không chỉ đòi hỏi chi phí và công sức viết đủ trò đùa để tạo thành một mẫu có thể học được, mà còn đòi hỏi những gì một nhà khoa học dữ liệu nhất định cho là hài hước phải phù hợp với những gì cơ sở người dùng sẽ thấy hài hước.
RLHF cung cấp một giải pháp thay thế thu thập từ đám đông theo toán học: gợi ý LLM tạo ra các trò đùa và để người kiểm tra đánh giá chất lượng của chúng. Những đánh giá này có thể được sử dụng để đào tạo một reward model để dự đoán các loại trò đùa sẽ nhận được phản hồi tích cực, và đến lượt nó, reward model đó có thể được sử dụng để đào tạo LLM thông qua reinforcement learning.
Một cách thực tế hơn, RLHF nhằm giải quyết các thách thức hiện sinh của LLM, như hallucination, phản ánh các định kiến xã hội vốn có trong dữ liệu đào tạo hoặc đối phó với đầu vào của người dùng thô lỗ hoặc đối kháng.
Các trường hợp sử dụng fine-tuning phổ biến
Fine-tuning có nhiều ứng dụng thực tế đa dạng trong môi trường kinh doanh và nghiên cứu. Dưới đây là những trường hợp sử dụng phổ biến nhất:
- Dịch vụ khách hàng: Các doanh nghiệp có thể fine-tune một mô hình ngôn ngữ lớn (LLM) tổng quát trên tập dữ liệu tương tác hỗ trợ khách hàng đã có trước đó, giúp AI chatbot phản hồi hiệu quả hơn với các câu hỏi cụ thể về sản phẩm và chính sách của công ty. Ví dụ, một mô hình đã được fine-tune trên dữ liệu về thông tin sản phẩm, chính sách công ty và lịch sử tương tác với khách hàng sẽ cung cấp các phản hồi phù hợp và hữu ích hơn so với mô hình tổng quát ban đầu.
- Bán lẻ và thương mại điện tử: Các nền tảng thương mại điện tử có thể cải thiện công cụ đề xuất sản phẩm bằng cách fine-tune mô hình pretrained trên dữ liệu tương tác người dùng như lịch sử mua hàng và đánh giá. Mô hình sau khi fine-tune sẽ cung cấp đề xuất sản phẩm được cá nhân hóa và chính xác hơn.
- Chăm sóc sức khỏe và y tế: Các nhà nghiên cứu y tế có thể fine-tune mô hình xử lý hình ảnh đã pretrained trên tập dữ liệu hình ảnh CT đặc trưng cho một bệnh lý hiếm. Điều này cho phép mô hình xác định các dấu hiệu của bệnh với độ chính xác cao hơn mà không cần phải đào tạo một mô hình hoàn toàn mới từ đầu.
- Nghiên cứu lịch sử: Các nhà sử học làm việc về việc số hóa văn bản cổ có thể sử dụng fine-tuning để cải thiện nhận dạng ký tự quang học trên ngôn ngữ cổ. Pretraining một mô hình xử lý ngôn ngữ tự nhiên (NLP) trên kho ngữ liệu của các văn bản cổ giúp mô hình nhận ra tốt hơn các đặc điểm ngôn ngữ đặc trưng.
- Bảo tồn và phát triển bền vững: Các nhóm sinh thái theo dõi động vật hoang dã có thể fine-tune mô hình xử lý âm thanh đã pretrained trên tập dữ liệu bản ghi âm thanh rừng để phân biệt âm thanh động vật từ tiếng ồn nền, giúp cô lập và nhận dạng tiếng ồn động vật cụ thể.
- Tùy chỉnh phong cách và giọng điệu: Các mô hình có thể được fine-tune để phản ánh giọng điệu mong muốn của một thương hiệu, từ việc thực hiện các mẫu hành vi phức tạp và phong cách minh họa đặc trưng đến những điều chỉnh đơn giản như bắt đầu mỗi cuộc trao đổi với một lời chào lịch sự nhất định.
- Chuyên môn hóa cho các tác vụ cụ thể: Khả năng ngôn ngữ tổng quát của LLM có thể được mài giũa cho các tác vụ cụ thể. Ví dụ, các mô hình Llama 2 của Meta đã được phát hành dưới dạng các base foundation model, các biến thể được điều chỉnh cho chatbot (Llama-2-chat) và các biến thể được điều chỉnh cho mã (Code Llama).
- Thêm kiến thức chuyên ngành: Fine-tuning giúp bổ sung kiến thức chuyên ngành vào mô hình, đặc biệt hữu ích trong các bối cảnh pháp lý, tài chính hoặc y tế, thường đòi hỏi từ vựng chuyên môn và kiến thức bí truyền mà có thể không có đủ trong quá trình pre-training.
- Few-shot learning: Mô hình có kiến thức tổng quát mạnh mẽ thường có thể được fine-tune cho các tác vụ phân loại cụ thể bằng cách sử dụng số lượng ví dụ tương đối ít, tối ưu hóa hiệu quả nguồn lực.
- Giải quyết các trường hợp ngoại lệ: Fine-tuning giúp mô hình xử lý những tình huống đặc biệt không xuất hiện trong dữ liệu pre-training. Bằng cách học từ các ví dụ đã được gán nhãn về những tình huống này, mô hình có thể phản ứng phù hợp khi gặp chúng trong thực tế.
- Tích hợp dữ liệu độc quyền: Các công ty có thể tận dụng pipeline dữ liệu độc quyền của riêng mình để fine-tune mô hình, tích hợp kiến thức này vào mô hình mà không cần đào tạo từ đầu, giúp tạo ra các giải pháp AI phù hợp với nhu cầu riêng của doanh nghiệp.
>>> XEM THÊM: Cách tạo chatbot đa kênh dễ dàng, thuận tiện
Những rủi ro và lợi ích của fine-tuning là gì?
Fine-tuning mang lại nhiều lợi ích đáng kể, nhưng cũng đi kèm với một số rủi ro và thách thức cần được cân nhắc kỹ lưỡng.
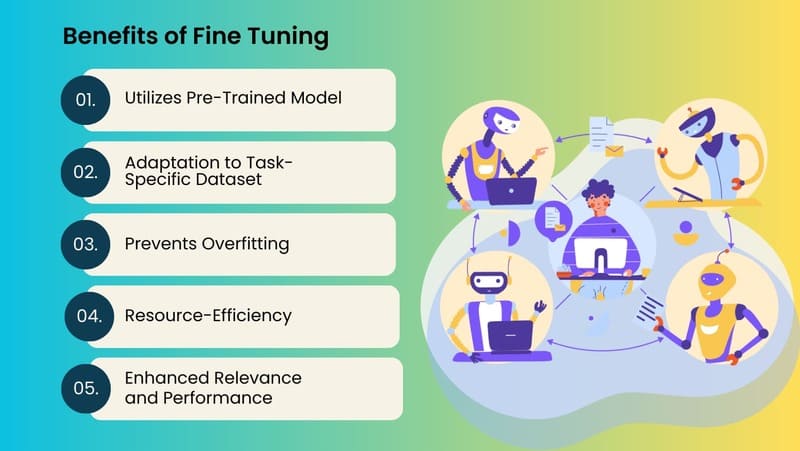
Lợi ích của fine-tuning
- Hiệu quả về chi phí và tài nguyên: Fine-tuning một mô hình pretrained thường nhanh hơn, tiết kiệm chi phí và hiệu quả về mặt tính toán hơn nhiều so với việc huấn luyện một mô hình từ đầu. Điều này dẫn đến chi phí thấp hơn và yêu cầu cơ sở hạ tầng ít nặng nề hơn, giảm đáng kể lượng sức mạnh tính toán đắt tiền và dữ liệu có nhãn cần thiết.
- Hiệu suất tốt hơn trên các trường hợp sử dụng ngách: Mô hình pretrained sau khi fine-tune, với sự kết hợp giữa học nền tảng rộng và đào tạo cụ thể cho tác vụ, có thể đạt được hiệu suất cao trong các trường hợp sử dụng chuyên biệt. Đặc biệt hữu ích trong các tình huống mà dữ liệu cụ thể cho tác vụ bị hạn chế hoặc khan hiếm.
- Dân chủ hóa các khả năng Machine Learning: Fine-tuning giúp làm cho các mô hình Machine Learning tiên tiến dễ tiếp cận hơn cho các cá nhân và tổ chức có hạn chế về tài nguyên tính toán và tài chính. Ngay cả các tổ chức nhỏ không thể xây dựng mô hình từ đầu cũng có thể điều chỉnh mô hình pretrained cho nhiều ứng dụng khác nhau.
- Tận dụng kiến thức đã học: Fine-tuning cho phép tận dụng kiến thức mà mô hình hiện có đã học được, làm điểm khởi đầu để tiếp thu kiến thức mới, giúp bổ sung kiến thức từ bộ dữ liệu ban đầu với dữ liệu độc quyền hoặc kiến thức chuyên ngành.
Rủi ro và thách thức của fine-tuning
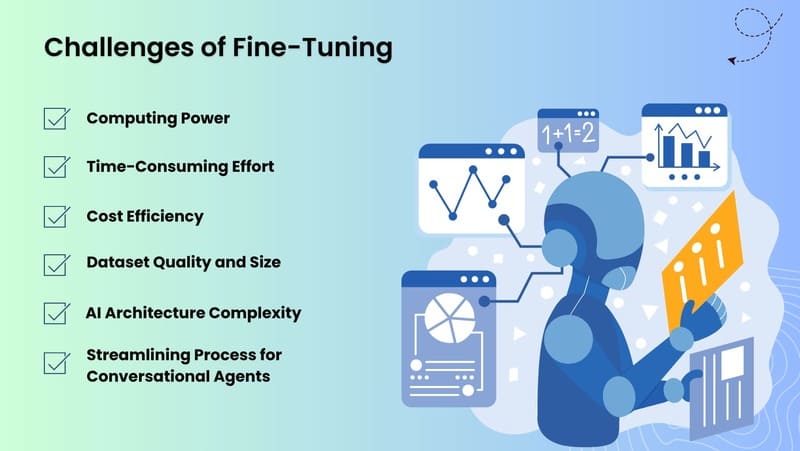
- Overfitting: Một vấn đề phổ biến khi làm việc với các tập dữ liệu nhỏ, overfitting xảy ra khi mô hình bám sát dữ liệu đào tạo quá mức và học các đặc điểm không liên quan (nhiễu), gây ra hiệu suất kém trên dữ liệu mới, chưa từng thấy. Các chiến lược như data augmentation, regularization và kết hợp các lớp dropout có thể giúp giảm thiểu hạn chế này.
- Cân bằng kiến thức mới và đã học trước đó: Có rủi ro là mô hình sau khi fine-tune sẽ quên kiến thức chung thu được trong quá trình pretraining, đặc biệt nếu dữ liệu mới khác biệt đáng kể so với dữ liệu ban đầu. Hiện tượng này được gọi là catastrophic forgetting. Đóng băng quá nhiều lớp có thể ngăn mô hình thích nghi tốt với tác vụ mới, trong khi đóng băng quá ít có nguy cơ mất các đặc điểm pre-learned quan trọng.
- Phụ thuộc vào các mô hình pretrained: Fine-tuning phụ thuộc nhiều vào mô hình pretrained, nên bất kỳ lỗi hoặc hạn chế nào trong mô hình đó có thể ảnh hưởng đến mô hình sau khi fine-tune. Ví dụ, nếu mô hình pretrained thể hiện bias hoặc lỗ hổng bảo mật, những vấn đề đó có thể tồn tại hoặc thậm chí trở nên tệ hơn nếu không được khắc phục trước hoặc trong quá trình fine-tuning.
- Yêu cầu về chuyên môn kỹ thuật: Mặc dù fine-tuning đòi hỏi ít tài nguyên hơn so với đào tạo từ đầu, nó vẫn cần một mức độ chuyên môn về machine learning để thực hiện hiệu quả, đặc biệt khi điều chỉnh hyperparameters như learning rate để cân bằng giữa việc giữ lại kiến thức nền và cải thiện hiệu suất cho tác vụ mới.
- Giới hạn về khả năng mở rộng: Phương pháp fine-tuning truyền thống (full fine-tuning) có thể gặp khó khăn khi áp dụng cho các mô hình rất lớn với hàng tỷ tham số, đòi hỏi các phương pháp PEFT (Parameter-Efficient Fine-Tuning) phức tạp hơn.
So sánh Fine-tuning vs RAG
Không giống như transfer learning và fine-tuning là các phương pháp đào tạo mô hình, Retrieval Augmented Generation (RAG) là một kiến trúc mô hình NLP cụ thể, kết hợp một language model được pretrained với hệ thống truy xuất kiến thức. RAG cho phép nâng cao đầu ra mô hình bằng cách kết hợp thông tin bổ sung từ nguồn dữ liệu bên ngoài.
Cách thức hoạt động của RAG:
- Mô hình truy xuất thông tin ngữ cảnh từ nguồn kiến thức bên ngoài (cơ sở dữ liệu, bộ sưu tập tài liệu)
- Mô hình Generative AI sử dụng dữ liệu đó để cung cấp thông tin cho đầu ra
- Cho phép các mô hình truy cập động các nguồn kiến thức bên ngoài trong thời gian thực
- Nền tảng cho phản hồi AI trong thông tin có thể xác minh
Sự khác biệt chính giữa RAG và Fine-tuning:
| Tiêu chí | RAG | Fine-tuning |
| Cách tiếp cận | Kết hợp truy xuất thông tin với generative AI | Điều chỉnh tham số mô hình |
| Dữ liệu | Truy cập dữ liệu bên ngoài khi cần | Đòi hỏi dữ liệu đào tạo mới |
| Kiến thức cập nhật | Có thể truy cập thông tin mới nhất | Bị giới hạn bởi dữ liệu đào tạo |
| Tính linh hoạt | Dễ thay đổi nguồn dữ liệu | Cần đào tạo lại để thích ứng |
| Yêu cầu tính toán | Yêu cầu ít tài nguyên đào tạo hơn | Cần tài nguyên tính toán đáng kể |
RAG đặc biệt phù hợp khi:
- Cần truy cập thông tin gần đây hoặc được lưu trữ riêng tư
- Muốn giảm nguy cơ hallucination (đầu ra không chính xác từ mô hình)
- Cần cung cấp thông tin có thể xác minh từ các nguồn đáng tin cậy
- Không có đủ tài nguyên để fine-tune lại mô hình thường xuyên
Ví dụ, một công ty công nghệ y tế xây dựng chatbot trả lời câu hỏi của bệnh nhân có thể bắt đầu bằng fine-tuning base LLM cho lĩnh vực y tế, sau đó triển khai RAG để cải thiện độ chính xác và cá nhân hóa phản hồi bằng cách cho phép mô hình truy cập vào cơ sở dữ liệu y tế và hồ sơ sức khỏe.
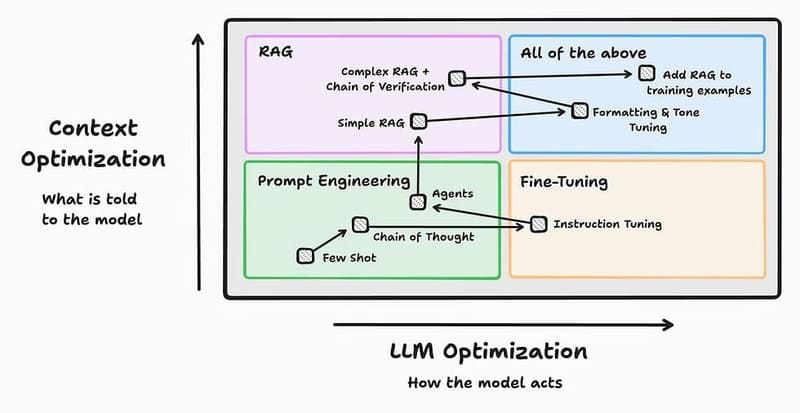
So sánh Fine-tuning vs Prompt engineering
Prompt engineering tối ưu hóa đầu ra của các mô hình Generative AI bằng cách thực hiện các thay đổi chiến lược đối với đầu vào của người dùng (prompts). Trong các kỹ thuật prompting, Zero-shot prompting là cách yêu cầu mô hình thực hiện nhiệm vụ chỉ bằng mô tả/hướng dẫn trong prompt mà không kèm ví dụ minh họa. Kỹ thuật này cho phép thử nghiệm prompt với kết quả mô hình mà không cần đào tạo lại hoặc tài nguyên tính toán bổ sung.
Tuy nhiên thiết kế prompts hiệu quả đòi hỏi một mức độ quen thuộc với cấu trúc, khả năng và hạn chế của mô hình. Prompt engineering tốt nghĩa là viết các prompts rõ ràng, cụ thể và có ngữ cảnh dẫn đến các phản hồi chính xác và phù hợp hơn.
Sự khác biệt chính giữa Prompt Engineering và Fine-tuning:
| Tiêu chí | Prompt Engineering | Fine-tuning |
| Cách tiếp cận tối ưu hóa | Cải thiện đầu ra AI bằng cách điều chỉnh cách người dùng tương tác với mô hình hiện có | Thay đổi chính mô hình bằng cách đào tạo lại nó trên dữ liệu mới |
| Hiệu suất | Giới hạn bởi khả năng của mô hình gốc | Có thể cải thiện hiệu suất lâu dài cho lĩnh vực chuyên biệt |
| Tích hợp kiến thức | Giới hạn trong kiến thức có sẵn của mô hình | Có thể tích hợp kiến thức chuyên ngành hoặc dữ liệu độc quyền |
| Nhất quán | Có thể thay đổi giữa các prompt | Mô hình phản ứng nhất quán với các prompt tương tự |
| Độ phức tạp kỹ thuật | Người dùng cần khả năng viết prompts hiệu quả | Đòi hỏi chuyên môn trong machine learning và quản lý dữ liệu, liên quan đến nhiều lập kế hoạch và phối hợp hơn |
| Yêu cầu tài nguyên | Không đòi hỏi dữ liệu mới hoặc tài nguyên tính toán đắt đỏ, chỉ dựa vào đầu vào của con người | Đòi hỏi sức tính toán đáng kể và các tập dữ liệu chất lượng cao, thời gian và chuyên môn kỹ thuật |
| Tính linh hoạt khi tinh chỉnh | Người dùng có thể thử nghiệm, cải tiến prompt ngay lập tức, tuỳ chỉnh chi tiết để tạo ra các đầu ra cá nhân cho trường hợp sử dụng cụ thể | Mất nhiều thời gian để đào tạo, thử nghiệm và triển khai, tạo ra những thay đổi vĩnh viễn đối với hành vi mô hình nhưng ít thích ứng hơn trong thời gian thực (khi tuỳ chỉnh phải thay đổi toàn diện cho toàn bộ mô hình) |
Tổ chức nên chọn Prompt Engineering khi:
- Cần giải pháp nhanh chóng và linh hoạt
- Ngân sách và tài nguyên tính toán hạn chế
- Không có dữ liệu đào tạo chuyên biệt đủ lớn
- Cần thích ứng liên tục với các yêu cầu đa dạng
- Đội ngũ có kỹ năng thiết kế prompt tốt
Fine-tuning phù hợp hơn khi doanh nghiệp:
- Có thể đầu tư thời gian và tài nguyên dài hạn
- Có lượng dữ liệu chuyên ngành lớn và chất lượng cao
- Cần hiệu suất ổn định và nhất quán cho một lĩnh vực cụ thể
- Muốn tạo ra lợi thế cạnh tranh từ mô hình AI được cá nhân hóa
- Có đội ngũ kỹ thuật với chuyên môn về machine learning
Tuy nhiên, kết hợp cả prompt engineering và fine-tuning thường mang lại kết quả tốt nhất. Doanh nghiệp nên áp dụng chiến lược:
- Sử dụng prompt engineering để thực hiện các điều chỉnh nhanh, linh hoạt cho các tác vụ cá nhân
- Dành các lần chạy fine-tuning cho những thay đổi mô hình sâu hơn, dài hạn hơn
- Áp dụng prompt engineering trên mô hình đã fine-tune để tối ưu hóa hơn nữa kết quả
Ví dụ, một công ty có thể fine-tune LLM cơ bản cho lĩnh vực tài chính, sau đó sử dụng prompt engineering để cá nhân hóa phản hồi cho từng khách hàng cụ thể hoặc tình huống thị trường.
Tóm lại, Fine-tuning đóng vai trò then chốt trong việc biến các mô hình AI tổng quát thành những công cụ tùy chỉnh cho từng lĩnh vực cụ thể. Phương pháp này mang đến hiệu quả về chi phí và tài nguyên, hiệu suất cao hơn trên các trường hợp sử dụng ngách và dân chủ hóa công nghệ AI cho các tổ chức nhỏ. Trong tương lai, Fine-tuning là công nghệ mở ra cánh cửa cho các ứng dụng AI chất lượng cao mà không cần đến nguồn lực khổng lồ để đào tạo mô hình từ đầu.
>>> XEM THÊM: