Được phát triển bởi Google, BERT là một trong những mô hình ngôn ngữ tiêu biểu trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP), tạo ra bước tiến lớn về khả năng hiểu ngữ nghĩa văn bản. Nhờ cơ chế phân tích ngữ cảnh hai chiều, BERT giúp hệ thống AI cải thiện đáng kể hiệu quả trong các tác vụ như tìm kiếm thông tin, trả lời câu hỏi và phân loại văn bản. Để tìm hiểu chi tiết về khái niệm, nguyên lý hoạt động, lợi ích và ứng dụng của mô hình BERT, hãy cùng FPT.AI theo dõi ngay nội dung bài viết dưới đây.
Mô hình BERT là gì?
BERT (Bidirectional Encoder Representations from Transformers) là mô hình học sâu do Google phát triển, nổi bật trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP). Mô hình này dựa trên kiến trúc Transformer và cơ chế attention để phân tích ngữ nghĩa từ trong toàn bộ ngữ cảnh hai chiều của câu. Nhờ đó, BERT hiểu văn bản chính xác hơn và đạt hiệu quả cao trong các bài toán NLP.

Mô hình BERT có cấu trúc ra sao?
Cấu trúc của BERT là một bộ mã hóa Transformer đa lớp có khả năng xử lý ngữ cảnh hai chiều và kế thừa kiến trúc Transformer gốc. Mặc dù Transformer tiêu chuẩn gồm encoder và decoder, BERT chỉ sử dụng phần encoder với cơ chế self-attention để thực hiện các tác vụ xử lý ngôn ngữ tự nhiên. BERT hiện có 2 phiên bản chính:
- BERTBASE: Gồm 12 lớp encoder, mỗi lớp có 12 đầu attention, 768 đơn vị ẩn và khoảng 110 triệu tham số.
- BERTLARGE: Gồm 24 lớp encoder, mỗi lớp có 16 đầu attention, 1024 đơn vị ẩn và khoảng 340 triệu tham số.
So với Transformer nguyên bản có ít lớp và đầu attention hơn, hai phiên bản của BERT sở hữu kiến trúc mạnh hơn, giúp mô hình biểu diễn và xử lý ngữ nghĩa hiệu quả hơn.
Nguyên lý hoạt động của mô hình BERT như thế nào?
BERT sử dụng kiến trúc Transformer với cơ chế self-attention, cho phép mô hình xử lý toàn bộ câu đồng thời thay vì theo từng bước tuần tự. Nhờ đó, BERT nắm bắt được quan hệ giữa các từ ở cả hai chiều và hiểu chính xác ngữ nghĩa của từng từ trong ngữ cảnh đầy đủ của câu.
Tiền huấn luyện (Pre-training)
Mục tiêu của bất kỳ kỹ thuật NLP nào là hiểu ngôn ngữ tự nhiên con người. Trong trường hợp của BERT, điều này có nghĩa là dự đoán một từ trong chỗ trống. Để làm được điều này, BERT được tiền huấn luyện trên tập dữ liệu văn bản thuần túy, không gắn nhãn, bao gồm:
- Toàn bộ Wikipedia tiếng Anh (~2,5 tỷ từ)
- BooksCorpus của Google (~800 triệu từ)
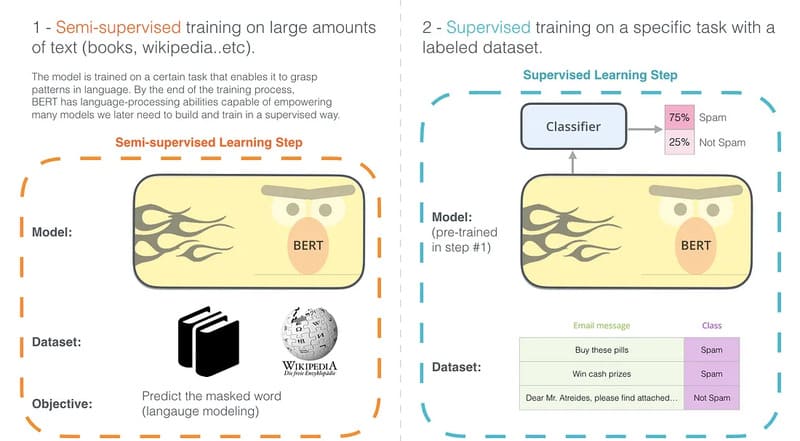
Sau đó, BERT model tiếp tục học hỏi và cải thiện khả năng xử lý ngôn ngữ thông qua hai kỹ thuật chính:
- Masked Language Modeling (MLM): BERT được huấn luyện để dự đoán các từ bị che đi trong câu. Mô hình sẽ ngẫu nhiên che đi một số từ trong văn bản và cố gắng dự đoán những từ này dựa vào ngữ cảnh xung quanh. Điều này buộc BERT phải hiểu từng từ trong ngữ cảnh thay vì gán cho từ một nghĩa hoặc vector cố định như các mô hình nhúng truyền thống.
- Next Sentence Prediction (NSP): BERT được cung cấp cả các cặp câu được ghép đúng và các cặp được ghép sai để hiểu sự khác biệt và mối quan hệ giữa các câu (logic, tuần tự hay chỉ đơn thuần là ngẫu nhiên). Điều này giúp mô hình hiểu rõ bối cảnh rộng hơn của văn bản để dự đoán liệu một câu có phải là câu tiếp theo hợp lý của câu trước đó hay không một cách chính xác.
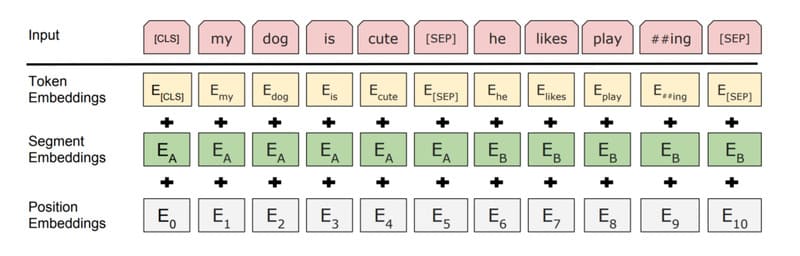
Tinh chỉnh (Fine-tuning)
Sau khi hoàn thành giai đoạn tiền huấn luyện, BERT đã có lớp kiến thức nền tảng và có thể được tinh chỉnh cho các nhiệm vụ cụ thể như:
- Phân loại văn bản
- Trả lời câu hỏi
- Nhận diện thực thể
- Phân tích cảm xúc
Quá trình tinh chỉnh này yêu cầu ít dữ liệu hơn và có thể được thực hiện nhanh chóng hơn so với việc huấn luyện từ đầu. Google đã áp dụng kỹ thuật học chuyển giao (transfer learning) để tận dụng kiến thức đã học từ giai đoạn tiền huấn luyện, giúp tiết kiệm thời gian và tài nguyên tính toán.
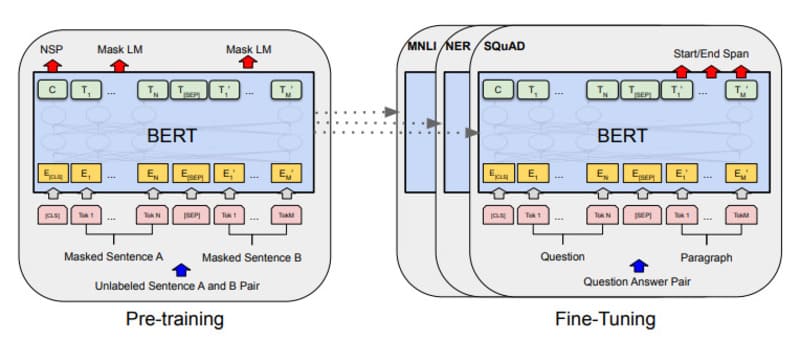
BERT vs GPT (Generative Pre-Training) có điểm khác biệt nào?
BERT và GPT là những mô hình ngôn ngữ tiên tiến dựa trên kiến trúc Transformer nhưng được thiết kế với những mục đích và cách thức hoạt động khác nhau. Tìm hiểu chi tiết hơn sự khác biệt giữa BERT và GPT thông qua bảng so sánh dưới đây:
| Tiêu chí | BERT | GPT |
| Nhà phát triển | OpenAI | |
| Quy mô (BERT vs GPT-3) | 340 triệu tham số | 175 tỷ tham số |
| Mục tiêu thiết kế | Hiểu ngôn ngữ (Understand) | Sinh ngôn ngữ (Generate) |
| Kiến trúc cơ bản | Mô hình hai chiều (Bidirectional) sử dụng phần Encoder của Transformer | Mô hình một chiều (Unidirectional) sử dụng phần Decoder của Transformer |
| Phương pháp huấn luyện chính | Masked Language Model (MLM) và Next Sentence Prediction (NSP) | Autoregressive: Dự đoán từ tiếp theo dựa trên chuỗi từ trước đó |
| Cách xử lý ngữ cảnh | Phân tích ngữ cảnh từ cả hai hướng (trái-phải và phải-trái) đồng thời | Phân tích ngữ cảnh chỉ theo một hướng (trái sang phải) |
| Minh họa cơ chế hoạt động | “Tôi đang [MASK] sách ở [MASK]”
↑ ↑ BERT xem xét cả văn bản trước và sau để dự đoán: ↓ ↓ “Tôi đang đọc sách ở thư viện” |
“Tôi đang” → GPT dự đoán: “đọc”
“Tôi đang đọc” → GPT dự đoán: “sách” “Tôi đang đọc sách” → GPT dự đoán: “ở” “Tôi đang đọc sách ở” → GPT dự đoán: “thư viện” |
| Khả năng học | Fine-tuning: cần dữ liệu có nhãn cho từng tác vụ cụ thể | Few-shot learning: có thể thực hiện tác vụ mới với rất ít dữ liệu (viết một bài luận về lý do tại sao con người không nên sợ AI chỉ với 10 câu ví dụ) |
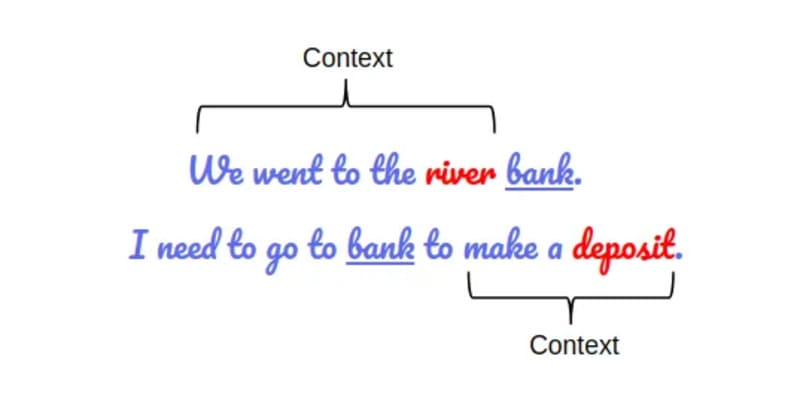
| Điểm mạnh | Hiểu ngữ cảnh sâu, phân biệt nghĩa của từ đa nghĩa (“bank” trong “Nâng mái chèo khi bạn đến bờ sông (river bank)” và “Ngân hàng (bank) đang gửi một thẻ ghi nợ mới”) | Khả năng sinh văn bản tự nhiên, sáng tạo, và đa dạng |
| Tác vụ phù hợp | Phân loại văn bản, nhận diện thực thể, trả lời câu hỏi, phân tích cảm xúc | Sinh văn bản (Natural Language Generation), viết sáng tạo, dịch thuật, tóm tắt, phát triển mã nguồn, xây dựng hệ thống đối thoại |
| Ứng dụng thực tế | Tìm kiếm Google, Gmail, Google Docs, trợ lý giọng nói, phân tích phản hồi khách hàng | ChatGPT, GitHub Copilot, viết nội dung, tạo mã nguồn |
| Hiệu suất | Đạt điểm số GLUE là 80.4% và độ chính xác 93.3% trên bộ dữ liệu SQuAD | Đạt độ chính xác 76.2% trên LAMBADA với zero-shot learning và 64.3% trên bộ dữ liệu TriviaQA |
Nhìn chung, sự khác biệt cơ bản giữa BERT và GPT nằm ở cách tiếp cận: BERT là mô hình hai chiều tập trung vào việc hiểu ngôn ngữ, trong khi GPT là mô hình một chiều chuyên về sinh ngôn ngữ. Việc lựa chọn giữa hai mô hình này phụ thuộc vào loại ứng dụng cụ thể mà chúng ta muốn phát triển.
Mô hình BERT mang đến lợi ích gì?
BERT là một bước tiến quan trọng trong xử lý ngôn ngữ tự nhiên, mang lại nhiều lợi ích thiết thực cho các hệ thống AI hiện đại, cụ thể:
Phân loại và biểu diễn văn bản: BERT tạo vector biểu diễn văn bản chất lượng cao nhờ encoder Transformer hai chiều, giúp mô hình hiểu tốt ngữ cảnh và cấu trúc ngôn ngữ. Vì vậy, BERT được dùng hiệu quả trong các tác vụ như phân loại văn bản, nhận diện thực thể và phân tích cảm xúc.
Gán nhãn dữ liệu: BERT hỗ trợ dự đoán nhãn cho dữ liệu chưa gán nhãn bằng cách tinh chỉnh trên tập dữ liệu sẵn có. Mô hình pretrained có thể kết hợp với lớp phân loại để tạo nhãn tự động, sau đó dùng các nhãn này để huấn luyện những mô hình nhỏ hơn cho hệ thống doanh nghiệp.
Xếp hạng và khuyến nghị: BERT cải thiện độ chính xác của hệ thống tìm kiếm và gợi ý nhờ khả năng hiểu ngữ cảnh truy vấn. Ví dụ, Amazon đã ứng dụng BERT để tối ưu xếp hạng kết quả và đề xuất sản phẩm phù hợp hơn cho người dùng.
Hiệu quả tính toán: So với các mô hình lớn như GPT-4, BERT có thể huấn luyện và suy luận với tài nguyên thấp hơn. Một số biến thể rút gọn như DistilBERT còn có thể chạy trên thiết bị di động hoặc hệ thống nhúng.
Đẩy nhanh triển khai ứng dụng: BERT là mô hình đã được huấn luyện trước nên chỉ cần tinh chỉnh cho từng bài toán cụ thể. Điều này giúp tổ chức rút ngắn thời gian phát triển, giảm chi phí dữ liệu và nhanh chóng triển khai vào các ứng dụng thực tế.

Các hạn chế chính của mô hình BERT là gì?
Mặc dù BERT đạt hiệu quả cao trong nhiều bài toán NLP nhưng mô hình này không phải là giải pháp hoàn hảo cho mọi trường hợp. Trong quá trình triển khai thực tế, BERT vẫn tồn tại một số hạn chế nhất định, cụ thể:
- Năng lực suy luận logic kém: BERT còn hạn chế trong các tác vụ suy luận và xử lý thông tin mơ hồ. Mô hình khó đạt hiệu quả cao với những bài toán đòi hỏi kiến thức nền rộng hoặc tư duy phân tích phức tạp, vì nó chủ yếu dựa vào mẫu dữ liệu đã học thay vì khả năng suy luận như con người.
- Thiếu sáng tạo và độc đáo: Mặc dù BERT có thể tạo văn bản trông tự nhiên, thiết kế của mô hình chủ yếu tập trung vào dự đoán từ theo ngữ cảnh nên không hỗ trợ sáng tạo ý tưởng mới. BERT chỉ tái sử dụng các mẫu kiến thức đã học từ dữ liệu huấn luyện, thay vì tự hình thành các khái niệm hoặc giải pháp mang tính đổi mới.
- Vấn đề thiên lệch và thiếu công bằng: Khi được huấn luyện trên dữ liệu thiếu đại diện hoặc chứa thiên lệch xã hội, BERT có thể học và khuếch đại các thiên lệch đó trong quá trình suy luận. Điều này khiến mô hình đôi khi tạo ra kết quả thiếu khách quan, đặc biệt trong các ngữ cảnh nhạy cảm liên quan đến giới tính hoặc vấn đề xã hội.
- Đòi hỏi tài nguyên lớn và thiếu linh hoạt: Quá trình triển khai BERT yêu cầu tài nguyên tính toán lớn cho cả huấn luyện và suy luận. Ngoài ra, khi áp dụng cho các lĩnh vực chuyên biệt, mô hình thường phải tinh chỉnh hoặc huấn luyện lại, làm tăng chi phí và giảm hiệu quả khi mở rộng sang nhiều ứng dụng thực tế.
Ứng dụng của mô hình BERT trong thực tế thế nào?
BERT đã tạo ra cuộc cách mạng trong lĩnh vực xử lý ngôn ngữ tự nhiên với nhiều ứng dụng đa dạng và tiện ích, cụ thể:
Tìm kiếm và trả lời câu hỏi: Google ứng dụng BERT để nâng cao khả năng hiểu truy vấn tìm kiếm bằng cách phân tích ngữ cảnh câu hỏi và xác định thông tin liên quan trong văn bản. Mô hình có thể nhận diện chính xác vị trí bắt đầu và kết thúc của câu trả lời, từ đó cung cấp kết quả tìm kiếm và phản hồi chính xác hơn cho người dùng.
Phân tích cảm xúc và phân loại văn bản: BERT hoạt động hiệu quả trong các tác vụ phân loại văn bản như xác định chủ đề, mục đích hoặc cảm xúc. Từ lọc thư rác và phân loại tin tức đến phân tích đánh giá sản phẩm, mô hình giúp nhận diện chính xác thái độ của người viết, qua đó hỗ trợ doanh nghiệp hiểu phản hồi khách hàng và cải thiện sản phẩm, dịch vụ.
Tóm tắt và tạo văn bản: BERT có khả năng đọc hiểu và tóm tắt các văn bản phức tạp, kể cả trong các lĩnh vực chuyên ngành như pháp lý và y tế. Mô hình này cũng có thể tạo ra các phản hồi trò chuyện và sinh văn bản mạch lạc, liên kết chặt chẽ dựa trên gợi ý đầu vào, nhờ vào hiểu biết ngữ nghĩa tiên tiến.
Suy luận ngôn ngữ tự nhiên: BERT có thể đánh giá mối quan hệ logic giữa các câu, xác định liệu một tuyên bố là đúng, sai hay không xác định dựa trên thông tin đã cho. Ví dụ, từ tiền đề “cà chua ngọt”, BERT có thể xác định rằng tuyên bố “cà chua là trái cây” là không xác định.
Giải quyết đa nghĩa và đồng tham chiếu: BERT hiểu chính xác ý nghĩa của từ trong câu, giải quyết hiệu quả các vấn đề về từ đồng âm khác nghĩa và từ có nhiều nghĩa khác nhau tùy theo ngữ cảnh.
Nhận diện thực thể: BERT có thể xác định và phân loại các thực thể như tên người, tổ chức, địa điểm, ngày tháng trong văn bản, làm cho việc quản lý thông tin và phân tích văn bản trở nên hiệu quả hơn.

Xếp hạng và khuyến nghị: Trong lĩnh vực thương mại điện tử, BERT cải thiện đáng kể hệ thống gợi ý sản phẩm bằng cách hiểu sâu hơn về ngữ cảnh và mối quan hệ giữa các từ.
Dịch ngôn ngữ và hỗ trợ đa ngôn ngữ: Được huấn luyện với dữ liệu từ nhiều ngôn ngữ, BERT có thể hỗ trợ dịch thuật và xử lý thông tin cho người dùng toàn cầu, phá vỡ rào cản ngôn ngữ trong giao tiếp và tiếp cận thông tin.
Tự động hóa tác vụ văn phòng: BERT giúp doanh nghiệp tự động hóa các công việc thường ngày như soạn thảo email, tin nhắn và các dịch vụ giao tiếp khác, tiết kiệm thời gian và tăng năng suất.
Gán nhãn dữ liệu thông minh: Các nhà khoa học dữ liệu có thể dùng BERT để gán nhãn cho dữ liệu chưa phân loại bằng cách tinh chỉnh mô hình pretrained và kết hợp với lớp phân loại. Cách tiếp cận này giúp tạo ra tập nhãn chất lượng cao cho các tác vụ như phân tích cảm xúc, đồng thời hỗ trợ huấn luyện những mô hình nhỏ hơn và nhẹ hơn.
So với các mô hình NLP lớn như GPT-4 hay Palm 2, BERT yêu cầu ít tài nguyên tính toán hơn và có thể huấn luyện trên một GPU. Các biến thể rút gọn còn có thể chạy trên thiết bị di động. Do mô hình đã được huấn luyện trước, BERT chỉ cần tinh chỉnh với lượng dữ liệu nhỏ, giúp rút ngắn thời gian triển khai và hỗ trợ tổ chức nhanh chóng đưa ứng dụng AI vào thực tế.

Các phiên bản nâng cấp của Google BERT
BERT là mô hình ngôn ngữ mã nguồn mở tiên tiến, cho phép nhà phát triển nhanh chóng huấn luyện hệ thống hỏi đáp trên hạ tầng điện toán đám mây như TPU hoặc GPU của Google Cloud. Nhờ tính linh hoạt và hiệu quả cao, nhiều tổ chức và nhóm nghiên cứu đã xây dựng các biến thể mở rộng của BERT, mỗi phiên bản được tối ưu cho những mục đích sử dụng cụ thể:
- BioBERT là mô hình biểu diễn ngôn ngữ sinh học chuyên dụng được thiết kế để khai thác và phân tích văn bản y học, giúp nâng cao hiệu quả trong các ứng dụng y sinh.
- SciBERT được điều chỉnh đặc biệt cho việc xử lý văn bản khoa học, mang lại hiệu suất cao hơn cho các tác vụ liên quan đến tài liệu học thuật và nghiên cứu.
- PatentBERT là phiên bản được tinh chỉnh để thực hiện các tác vụ phân loại bằng sáng chế, giúp cải thiện hiệu quả trong lĩnh vực sở hữu trí tuệ và nghiên cứu bằng sáng chế.
- DocBERT được tối ưu hóa cho các tác vụ phân loại tài liệu, giúp nâng cao khả năng phân tích và sắp xếp các loại văn bản khác nhau.
- VideoBERT là mô hình kết hợp ngôn ngữ – hình ảnh, được sử dụng trong việc học không giám sát từ dữ liệu chưa gắn nhãn trên YouTube, mở rộng khả năng của BERT sang lĩnh vực đa phương tiện.
- G-BERT sử dụng mã y tế với biểu diễn phân cấp thông qua mạng nơ-ron đồ thị, được tinh chỉnh để đưa ra các khuyến nghị y tế, đóng góp vào ứng dụng AI trong lĩnh vực chăm sóc sức khỏe.
- TinyBERT do Huawei phát triển là phiên bản nhỏ gọn hơn, áp dụng phương pháp học từ “thầy” BERT gốc và chưng cất transformer để cải thiện hiệu quả. TinyBERT nhỏ hơn 7,5 lần và nhanh hơn 9,4 lần so với BERT-base.
- DistilBERT của Hugging Face là phiên bản nhỏ hơn, nhanh hơn và tiết kiệm hơn so với mô hình BERT gốc, đạt được hiệu suất tương đương nhưng loại bỏ một số khía cạnh kiến trúc để tăng tốc độ xử lý.
- ALBERT (A Lite BERT) là phiên bản nhẹ hơn giúp giảm đáng kể mức tiêu thụ bộ nhớ và tăng tốc độ huấn luyện mô hình, mang lại lợi ích về hiệu suất và tài nguyên.
- SpanBERT tập trung vào việc cải tiến khả năng dự đoán các đoạn văn bản, nâng cao hiệu quả trong các tác vụ đòi hỏi sự hiểu biết sâu về ngữ cảnh.
- RoBERTa được huấn luyện trên bộ dữ liệu lớn hơn và trong thời gian dài hơn với các phương pháp tiên tiến, giúp cải thiện đáng kể hiệu suất so với BERT gốc.
- ELECTRA được điều chỉnh để tạo ra các biểu diễn văn bản chất lượng cao hơn, mang lại hiệu quả vượt trội trong nhiều tác vụ xử lý ngôn ngữ tự nhiên.
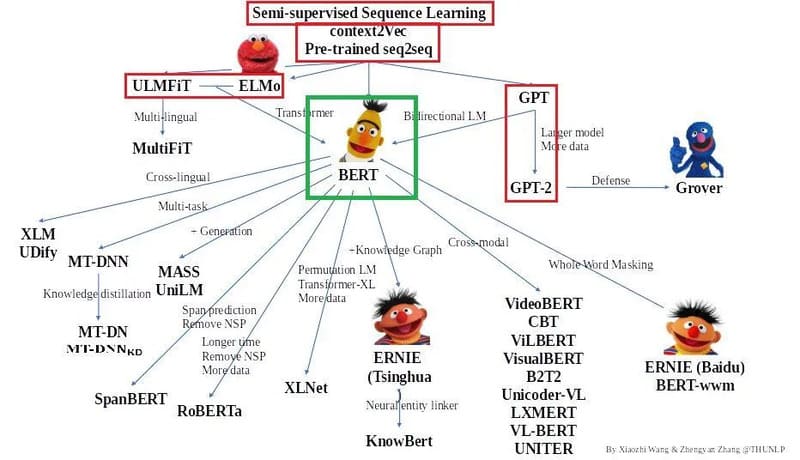
Xu hướng phát triển các mô hình BERT nhỏ hơn đang ngày càng phổ biến, đáp ứng nhu cầu về hiệu quả xử lý, tiết kiệm tài nguyên trong khi vẫn duy trì hiệu suất cao cho các ứng dụng cụ thể.
>>> XEM THÊM: Cách tạo chatbot đa kênh dễ dàng, thuận tiện
Những câu hỏi thường gặp về BERT
Người mới bắt đầu học BERT nên làm gì?
Người mới học BERT nên bắt đầu bằng việc nắm vững kiến thức nền về NLP và kiến trúc Transformer, sau đó thực hành tinh chỉnh BERT trên các bài toán đơn giản. Việc học qua dự án thực tế và thử nghiệm với mô hình pretrained sẽ giúp hiểu nhanh và áp dụng hiệu quả hơn.
Có cần nhiều dữ liệu để huấn luyện BERT không?
Không. Khi sử dụng BERT, thường chỉ cần một lượng dữ liệu vừa phải để tinh chỉnh (fine-tune) vì mô hình đã được huấn luyện trước trên tập dữ liệu rất lớn. Tuy nhiên, nếu muốn huấn luyện BERT từ đầu thì sẽ cần dữ liệu và tài nguyên tính toán rất lớn.
BERT có hỗ trợ nhiều ngôn ngữ không?
Có. BERT có phiên bản đa ngôn ngữ do Google phát triển, hỗ trợ hàng trăm ngôn ngữ khác nhau. Nhờ đó, mô hình có thể xử lý văn bản đa ngôn ngữ và áp dụng cho nhiều bài toán NLP trên phạm vi toàn cầu.
Mô hình BERT đã đánh dấu bước tiến lớn trong xử lý ngôn ngữ tự nhiên nhờ khả năng phân tích ngữ cảnh hai chiều hiệu quả. Các phiên bản cải tiến sau này như RoBERTa, ALBERT và DistilBERT tiếp tục tối ưu mô hình về hiệu năng và chi phí tính toán. Dù công nghệ AI không ngừng phát triển, BERT vẫn giữ vai trò nền tảng quan trọng cho các mô hình ngôn ngữ hiện đại, góp phần nâng cao khả năng máy tính hiểu và xử lý ngôn ngữ con người.