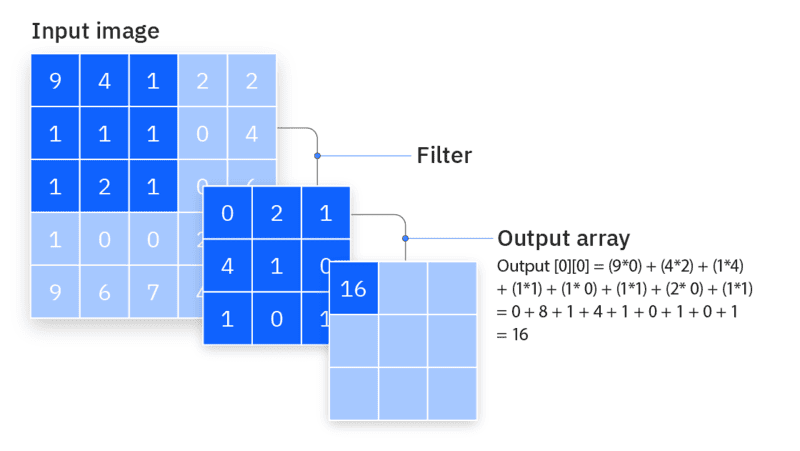
Hiện nay, học máy (Machine Learning) giữ vai trò cốt lõi trong việc xây dựng các hệ thống trí tuệ nhân tạo hiện đại. Trong số các kỹ thuật tối ưu hóa quá trình huấn luyện mô hình, Transfer Learning nổi bật nhờ khả năng tận dụng kiến thức từ các mô hình có sẵn để nâng cao hiệu quả cho những bài toán mới. Cùng FPT.AI tìm hiểu chi tiết cách thức hoạt động, các loại hình, quy trình thực hiện, ưu nhược điểm và các ứng dụng thực tế của Transfer Learning trong nội dung bài viết sau đây.
Transfer Learning là gì?
Transfer Learning (học chuyển giao) là kỹ thuật trong học máy (Machine Learning) cho phép sử dụng lại một mô hình đã được huấn luyện trên tập dữ liệu lớn để áp dụng cho một tác vụ mới có liên quan. Phương pháp này khai thác các đặc trưng và trọng số đã được tối ưu từ mô hình gốc nhằm rút ngắn thời gian huấn luyện, giảm chi phí tính toán và nâng cao hiệu quả mô hình, đặc biệt khi dữ liệu cho bài toán mới còn hạn chế.
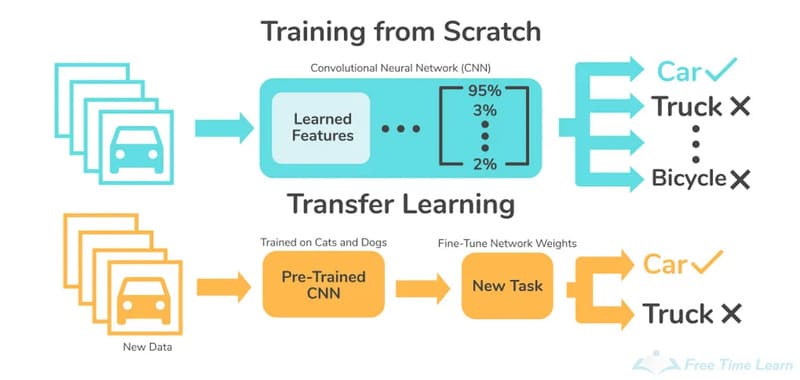
Một ví dụ của Transfer Learning là trong xử lý ngôn ngữ tự nhiên (NLP). Các mô hình như BERT hoặc GPT được huấn luyện trước dựa trên lượng lớn văn bản. Khi áp dụng cho bài toán phân loại cảm xúc bình luận, chỉ cần tinh chỉnh mô hình với tập dữ liệu nhỏ chuyên biệt, thay vì xây dựng mô hình mới hoàn toàn. Điều này giúp tiết kiệm tài nguyên và cải thiện hiệu suất một cách tối đa.
Cơ chế hoạt động của Transfer Learning như thế nào?
Transfer Learning hoạt động bằng cách tái sử dụng kiến thức mà mô hình đã học từ một tập dữ liệu lớn để áp dụng cho một bài toán mới. Mô hình tận dụng các đặc trưng đã được học từ những nhiệm vụ tương tự, nhờ đó rút ngắn thời gian huấn luyện và giảm nhu cầu về dữ liệu mới, thay vì phải xây dựng và huấn luyện lại từ đầu.
Trong quá trình chuyển giao, các đặc trưng của bài toán gốc được điều chỉnh và ánh xạ sang bài toán mới để đảm bảo tính phù hợp. Việc này thường cần sự thiết lập của con người, tuy nhiên nhiều kỹ thuật hiện đại đã cho phép tự động hóa một phần quá trình ánh xạ, giúp triển khai Transfer Learning hiệu quả hơn.
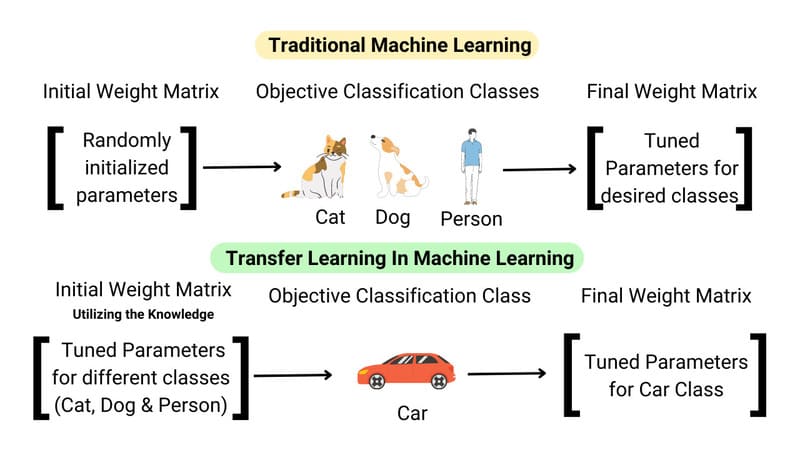
Có những loại hình học chuyển giao – Transfer Learning nào?
Học chuyển giao (Transfer Learning) trong học máy được chia thành 3 loại chính dựa trên mối quan hệ giữa nguồn gốc, đích đến và nhiệm vụ cần thực hiện:
Học chuyển giao quy nạp – Inductive Transfer Learning
Inductive Transfer là một dạng học chuyển giao được sử dụng khi nhiệm vụ nguồn và nhiệm vụ đích khác nhau nhưng có liên quan. Ví dụ, mô hình đã được huấn luyện để trích xuất đặc trưng hình ảnh có thể được tận dụng cho bài toán phát hiện một đối tượng cụ thể. Mục tiêu của phương pháp này là khai thác kiến thức từ nhiệm vụ ban đầu để cải thiện hiệu quả cho nhiệm vụ mới.
Học chuyển giao quy nạp thường triển khai theo hai hướng chính. Multi-task Learning cho phép mô hình học đồng thời nhiều nhiệm vụ trên cùng một tập dữ liệu, chẳng hạn như vừa phân loại vừa phát hiện đối tượng. Trong khi đó, Self-taught Learning sử dụng dữ liệu nguồn không gán nhãn để hỗ trợ học trên dữ liệu đích có gán nhãn.

Học chuyển giao không giám sát – Unsupervised Transfer Learning
Unsupervised Transfer Learning là phương pháp học chuyển giao làm việc với dữ liệu không gán nhãn, thường được áp dụng khi nhiệm vụ nguồn và nhiệm vụ đích khác nhau nhưng vẫn có liên hệ. Khác với Inductive Transfer (học có giám sát), phương pháp này tập trung khai thác cấu trúc tiềm ẩn của dữ liệu để hỗ trợ bài toán mới. Các ứng dụng phổ biến của học chuyển giao không giám sát gồm phát hiện gian lận thông qua nhận diện mẫu bất thường, giảm chiều dữ liệu và phân cụm.
Một ví dụ của Unsupervised Transfer Learning là phát hiện gian lận tài chính. Mô hình được huấn luyện trên lượng lớn dữ liệu giao dịch không gán nhãn để học các mẫu hành vi thông thường, sau đó áp dụng kiến thức này để nhận diện những giao dịch bất thường hoặc đáng ngờ trong tập dữ liệu mục tiêu.

Học chuyển giao suy diễn – Transductive Transfer Learning
Transductive Transfer Learning xảy ra khi nhiệm vụ nguồn và nhiệm vụ đích giống nhau nhưng dữ liệu thuộc các miền khác nhau. Thông thường, dữ liệu nguồn có gán nhãn, trong khi dữ liệu đích không có nhãn. Mục tiêu của phương pháp này là tận dụng kiến thức từ miền nguồn để cải thiện hiệu quả trên miền đích.
Các dạng phổ biến của học chuyển giao suy diễn gồm:
- Domain Adaptation: chuyển kiến thức giữa các miền dữ liệu cho cùng một nhiệm vụ,
- Sample Selection Bias: xử lý khác biệt phân phối giữa dữ liệu huấn luyện và dữ liệu thực tế,
- Covariate Shift: điều chỉnh khi phân phối đầu vào thay đổi nhưng quan hệ đầu vào – đầu ra vẫn giữ nguyên.
Ví dụ như một mô hình có thể được huấn luyện để phân loại cảm xúc trên tập dữ liệu đánh giá nhà hàng đã gán nhãn (tích cực/tiêu cực). Sau đó được áp dụng để phân loại cảm xúc cho các bài đánh giá phim chưa có nhãn bằng cách chuyển giao kiến thức giữa hai miền dữ liệu có liên quan.

Có những bước nào trong quy trình Transfer Learning cơ bản?
Quy trình áp dụng Transfer Learning trong học máy để giải quyết một nhiệm vụ mới thường được triển khai qua các bước chính sau:
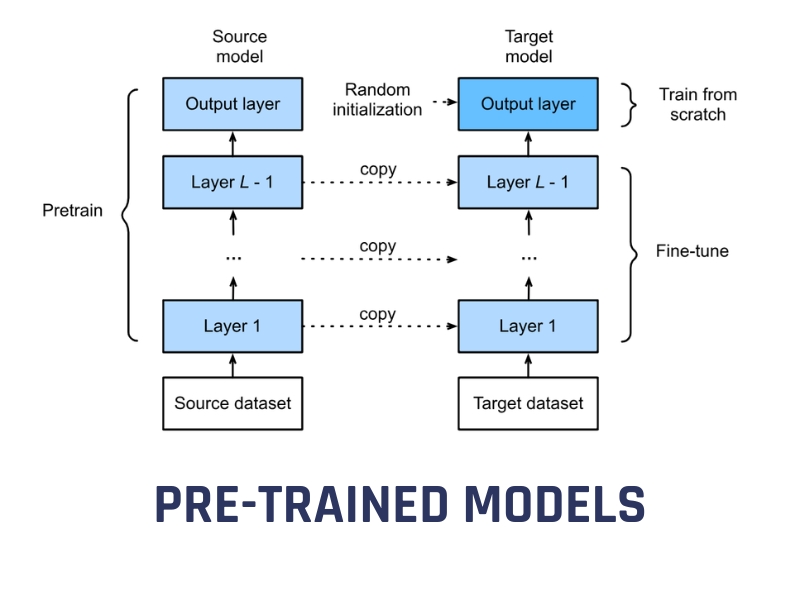
Bước 1 – Chọn mô hình pre-trained phù hợp
Đầu tiên, cần chọn một mô hình đã được huấn luyện sẵn phù hợp với bài toán cần giải quyết. Mô hình này thường được huấn luyện trên các tập dữ liệu lớn như ImageNet và có kiến trúc tối ưu cho từng loại dữ liệu. Việc lựa chọn nên dựa trên sự phù hợp của kiến trúc (chẳng hạn như CNN cho dữ liệu hình ảnh), mức độ liên quan của dữ liệu huấn luyện và yêu cầu về tài nguyên tính toán.
Ví dụ, trong bài thực hành phân loại chó mèo, MobileNet được chọn làm base network vì đã được pre-trained trên bộ dữ liệu ImageNet với 1000 classes khác nhau, bao gồm cả chó và mèo.
Bước 2 – Khởi động (Warm up)
Sau khi chọn mô hình pre-trained, bước tiếp theo là “warm up” bằng cách đóng băng (freeze) các lớp CNN để giữ nguyên trọng số đã học. Việc này giúp bảo toàn các đặc trưng cấp cao mà mô hình đã rút ra từ tập dữ liệu lớn, từ đó duy trì độ ổn định và độ chính xác ban đầu. Trong thực tế, thao tác này được thực hiện bằng cách đặt thuộc tính layer.trainable = False cho các lớp cần đóng băng.
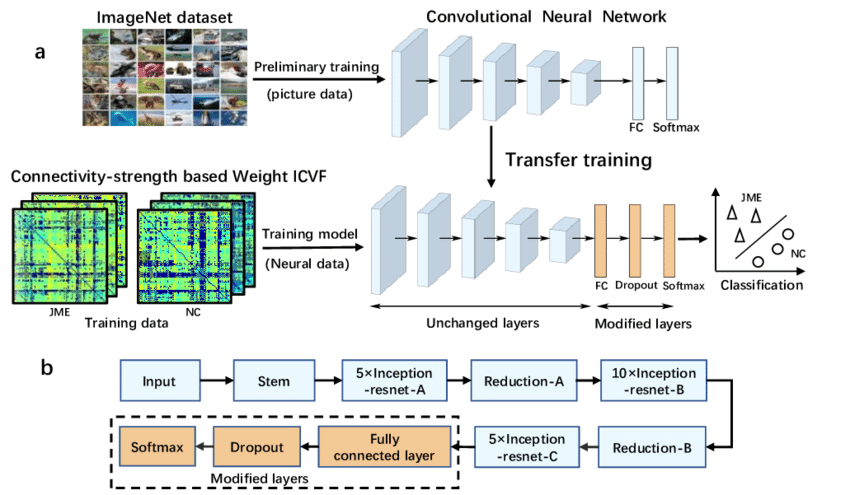
Bước 3 – Thêm các lớp mới
Để thực hiện nhiệm vụ mới, cần bổ sung các lớp Fully Connected (MLP) vào cuối mô hình pre-trained. Các lớp này có nhiệm vụ học những đặc trưng chuyên biệt cho bài toán, trong đó số nút ở lớp đầu ra phải phù hợp với số lượng lớp cần phân loại. Trọng số của các lớp mới được khởi tạo ngẫu nhiên và trong giai đoạn đầu, quá trình huấn luyện nên tập trung vào các lớp này, sử dụng đặc trưng từ mạng nền làm đầu vào để giúp mô hình hội tụ nhanh và đạt hiệu quả tốt.
Bước 4 – Fine-tuning mô hình (huấn luyện lại)
Sau khi các lớp Fully Connected đạt hiệu suất ổn định, bước kế tiếp là Fine-tuning để nâng cao độ chính xác. Ở giai đoạn này, ta mở băng (unfreeze) một phần hoặc toàn bộ các lớp của mạng nền và huấn luyện lại với learning rate thấp, giúp mô hình thích nghi tốt hơn với nhiệm vụ mới và hạn chế overfitting (quá khớp).
Chiến lược fine-tuning cần điều chỉnh theo dữ liệu:
- Với tập dữ liệu nhỏ: chỉ huấn luyện các lớp cuối;
- Với dữ liệu lớn cùng miền: có thể warm up rồi fine-tune toàn bộ;
- Với dữ liệu lớn khác miền: việc huấn luyện mô hình từ đầu thường hiệu quả hơn.
Bước Fine-tuning (huấn luyện lại) nhằm nâng cao độ chính xác
Lưu ý: Transfer Learning chỉ thực sự hiệu quả khi hai mô hình có cùng domain, khi dữ liệu huấn luyện pretrained-model lớn hơn so với mô hình cần xây dựng và khi pretrained-model có chất lượng tốt.
Ưu và nhược điểm của Transfer Learning như thế nào?
Việc áp dụng kỹ thuật học chuyển giao (Transfer Learning) vào các bài toán thực tế mang lại nhiều lợi ích rõ rệt, nhưng đồng thời cũng đặt ra một số thách thức cần được cân nhắc.
Ưu điểm
Giảm chi phí tính toán: Transfer Learning giảm đáng kể chi phí tính toán khi phát triển mô hình cho bài toán mới. Bằng cách tái sử dụng các mô hình, phương pháp này rút ngắn thời gian huấn luyện, giảm nhu cầu dữ liệu và tiết kiệm tài nguyên xử lý. Nhờ đó, mô hình thường cần ít vòng huấn luyện hơn để đạt hiệu quả mong muốn, giúp quá trình triển khai trở nên nhanh và tối ưu hơn.
Đảm bảo tối ưu chất lượng dữ liệu: Học chuyển giao đặc biệt hiệu quả trong các tình huống khó thu thập dữ liệu quy mô lớn. Những mô hình như LLM thường cần lượng dữ liệu huấn luyện rất lớn để đạt hiệu suất cao, trong khi việc gán nhãn dữ liệu thủ công tốn nhiều thời gian và chi phí. Bằng cách tận dụng mô hình đã huấn luyện trước, Transfer Learning giúp giảm đáng kể nhu cầu về dữ liệu mới.
Tăng khả năng tổng quát hóa: Transfer Learning tối ưu hiệu suất, tăng khả năng tổng quát hóa của mô hình. Khi được huấn luyện lại trên dữ liệu mới, mô hình kết hợp kiến thức từ nhiều nguồn khác nhau, nhờ đó hoạt động ổn định trên đa dạng dữ liệu và giảm nguy cơ overfitting so với mô hình chỉ học từ một tập dữ liệu duy nhất.
Cải thiện accuracy (độ chính xác) và tốc độ hội tụ: Transfer Learning cung cấp điểm khởi đầu với độ chính xác cao hơn, giúp mô hình cải thiện hiệu suất nhanh và đạt mức chính xác tối ưu tốt hơn. Nhờ tận dụng kiến thức sẵn có, mô hình thường đạt kết quả cao chỉ sau ít vòng huấn luyện hơn so với việc huấn luyện từ đầu.

Nhược điểm của học chuyển giao
Nguy cơ chuyển giao tiêu cực (negative transfer): Transfer Learning đạt hiệu quả cao nhất khi đáp ứng 3 điều kiện: nhiệm vụ nguồn và đích có tính tương đồng, phân phối dữ liệu giữa hai miền không khác biệt lớn và cùng một kiến trúc mô hình có thể áp dụng cho cả hai. Nếu các điều kiện này không được đảm bảo, việc chuyển giao có thể làm suy giảm hiệu suất mô hình, hiện tượng này được gọi là chuyển giao tiêu cực.
Thiếu tiêu chuẩn đánh giá sự tương đồng: Hiện nay chưa có một tiêu chuẩn chung được công nhận rộng rãi để đo lường mức độ tương đồng giữa các nhiệm vụ trong Transfer Learning. Dù nhiều nghiên cứu đã đề xuất các phương pháp đánh giá sự liên quan giữa tập dữ liệu và bài toán học máy, lĩnh vực này vẫn chưa thống nhất được một tiêu chí chuẩn.
Giới hạn về domain (tên miền): Transfer Learning chỉ nên áp dụng giữa hai mô hình có cùng domain. Nếu pretrained-model và mô hình cần huấn luyện không có chung domain về dữ liệu, các đặc trưng học được từ bộ feature extractor của mô hình gốc sẽ không thực sự hữu ích trong việc phân loại của mô hình mới.
Phụ thuộc vào chất lượng của Pre-trained model: Mô hình pre-trained cần có chất lượng cao và được huấn luyện trên tập dữ liệu đủ lớn so với dữ liệu của bài toán mới. Nếu không, các đặc trưng mà mô hình học được sẽ thiếu tính tổng quát và khó hỗ trợ hiệu quả cho quá trình huấn luyện mô hình mới.
Không thay thế được kỹ thuật xử lý dữ liệu: Transfer Learning không thể khắc phục những hạn chế do dữ liệu kém chất lượng gây ra. Vì vậy, các bước tiền xử lý và kỹ thuật xử lý đặc trưng, như tăng cường dữ liệu và trích xuất đặc trưng, vẫn đóng vai trò quan trọng để đảm bảo hiệu quả mô hình.
Ứng dụng của Transfer Learning là gì?
Transfer Learning được sử dụng rộng rãi trong nhiều lĩnh vực của học máy và trí tuệ nhân tạo. Sau đây là một số ứng dụng tiêu biểu của kỹ thuật này:
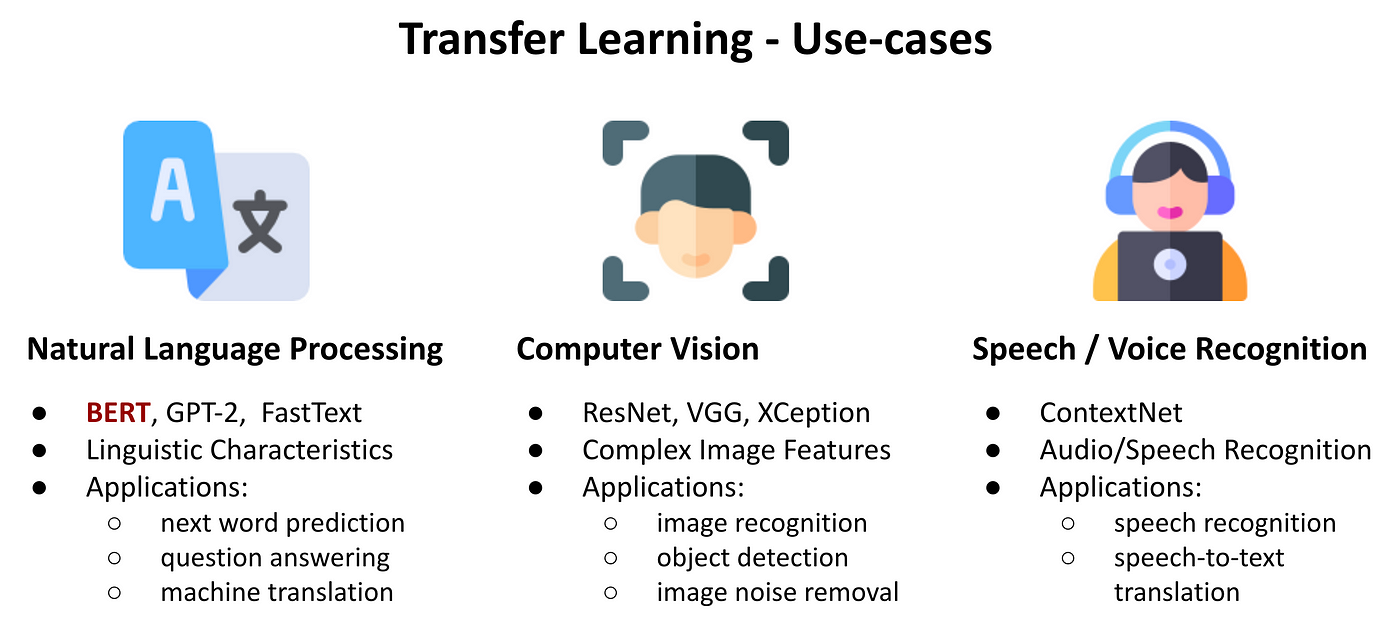
Xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP)
Trong xử lý ngôn ngữ tự nhiên, Transfer Learning được ứng dụng rộng rãi thông qua các mô hình ngôn ngữ lớn như BERT, GPT và T5. Các mô hình này được huấn luyện trên tập dữ liệu văn bản quy mô lớn để nắm bắt cấu trúc và ngữ nghĩa ngôn ngữ. Sau đó có thể được tái sử dụng cho các nhiệm vụ cụ thể như phân loại văn bản, hỏi đáp, dịch hoặc tóm tắt.
Ví dụ, một mô hình BERT sau khi huấn luyện tổng quát có thể được tinh chỉnh để phân loại đánh giá sản phẩm hoặc nhận diện cảm xúc trên mạng xã hội. Cách tiếp cận này giúp nâng cao độ chính xác và giảm đáng kể chi phí huấn luyện so với việc xây dựng mô hình từ đầu.
Thị giác máy tính (Computer Vision)
Nhận diện hình ảnh là một trong những ứng dụng tiêu biểu của Transfer Learning trong học sâu. Các mô hình CNN thường được huấn luyện trên tập dữ liệu lớn như ImageNet để học các đặc trưng hình ảnh cơ bản, sau đó được tái sử dụng cho những bài toán chuyên biệt hơn. Ví dụ, mô hình có thể được tinh chỉnh để phát hiện bệnh trên ảnh y tế hoặc nhận diện khuôn mặt trong các hệ thống an ninh.
Dự báo độ chính xác cao hơn với ít dữ liệu
Transfer Learning phát huy hiệu quả rõ rệt khi làm việc với tập dữ liệu nhỏ. Trong bài toán phân loại chó và mèo, việc huấn luyện mô hình từ đầu thường cần nhiều vòng huấn luyện để đạt độ chính xác cao. Ngược lại, khi sử dụng mô hình pre-trained, mô hình có thể đạt kết quả mong muốn nhanh hơn. So với huấn luyện từ đầu, Transfer Learning mang lại ba lợi thế chính: độ chính xác ban đầu cao hơn, tốc độ cải thiện nhanh hơn và mức chính xác tối ưu đạt được cũng cao hơn.
Cải thiện mô hình với dữ liệu nhỏ không đại diện
Một nguyên nhân phổ biến khiến mô hình dự báo kém là tập dữ liệu quá nhỏ và không đủ tính đại diện. Ví dụ, một bộ dữ liệu chỉ gồm 100 ảnh chó và mèo từ một khu vực không thể phản ánh đầy đủ sự đa dạng của hai loài này. Transfer Learning khắc phục hạn chế đó bằng cách tận dụng các đặc trưng tổng quát học từ tập dữ liệu lớn, giúp mô hình dự đoán tốt hơn trên dữ liệu mới.
Các xu hướng của Transfer Learning trong tương lai
Một số xu hướng đang định hình tương lai của Transfer Learning tập trung vào việc mở rộng khả năng học và thích nghi của mô hình AI.
- Học chuyển giao đa phương thức (Multimodal Transfer Learning) cho phép mô hình học đồng thời từ nhiều loại dữ liệu như văn bản, hình ảnh và âm thanh. Việc kết hợp đa nguồn dữ liệu giúp hệ thống AI hiểu thông tin toàn diện hơn và hoạt động hiệu quả trong các bài toán thực tế phức tạp.
- Học chuyển giao phân tán (Federated Transfer Learning) kết hợp Transfer Learning với học liên kết để chia sẻ kiến thức giữa các nguồn dữ liệu phân tán mà vẫn bảo vệ quyền riêng tư. Cách tiếp cận này cho phép nhiều tổ chức cùng cải thiện mô hình mà không cần trao đổi dữ liệu nhạy cảm.
- Học chuyển giao suốt đời (Lifelong Transfer Learning) hướng tới việc xây dựng mô hình có khả năng học liên tục và thích nghi theo thời gian. Mô hình có thể tích lũy kinh nghiệm từ các nhiệm vụ trước để xử lý hiệu quả những bài toán mới mà không cần huấn luyện lại từ đầu.
- Zero-shot và Few-shot Learning giúp mô hình dự đoán với rất ít hoặc không cần dữ liệu huấn luyện cho lớp mới. Các kỹ thuật này giảm phụ thuộc vào dữ liệu lớn và tăng khả năng tổng quát hóa của hệ thống AI.

Transfer Learning vs Fine-tuning có gì khác nhau?
Transfer Learning và Fine-tuning đều tái sử dụng mô hình đã có nhưng mục đích khác nhau, cụ thể:
| Tiêu chí | Fine-tuning (Tinh chỉnh) | Transfer Learning (Học chuyển giao) |
| Mục đích | Cải thiện hiệu suất cho cùng một nhiệm vụ ban đầu | Áp dụng kiến thức cho một nhiệm vụ mới có liên quan |
| Cách hoạt động | Huấn luyện thêm mô hình trên dữ liệu chuyên biệt để tối ưu kết quả | Điều chỉnh mô hình đã huấn luyện để giải quyết bài toán khác |
| Phạm vi thay đổi | Tinh chỉnh một phần hoặc toàn bộ mô hình cho cùng bài toán | Tái sử dụng đặc trưng và chuyển sang bài toán mới |
| Mục tiêu dữ liệu | Dữ liệu bổ sung cùng lĩnh vực với nhiệm vụ gốc | Dữ liệu thuộc lĩnh vực mới nhưng có liên quan |
| Kết quả mong muốn | Tăng độ chính xác cho nhiệm vụ hiện tại | Giải quyết hiệu quả một nhiệm vụ mới với ít dữ liệu |
| Ví dụ | Tinh chỉnh mô hình phát hiện đối tượng chung để phát hiện ô tô chính xác hơn | Dùng mô hình nhận diện ảnh tổng quát để xây dựng hệ thống phân loại bệnh lá cây |
Một số câu hỏi thường gặp về Transfer Learning
Nên sử dụng Transfer Learning trong trường hợp nào?
Nên sử dụng Transfer Learning khi muốn tận dụng kiến thức từ một mô hình đã được huấn luyện trước để giải quyết bài toán mới, đặc biệt trong các trường hợp:
- Dữ liệu huấn luyện ít: Khi bạn không có đủ dữ liệu để huấn luyện mô hình từ đầu.
- Bài toán tương tự: Khi nhiệm vụ mới có liên quan đến bài toán mà mô hình gốc đã học.
- Tiết kiệm thời gian và tài nguyên: Khi cần rút ngắn thời gian huấn luyện và giảm chi phí tính toán.
- Cần hiệu suất tốt nhanh: Khi muốn đạt độ chính xác cao trong thời gian ngắn.
Cần bao nhiêu dữ liệu để áp dụng Transfer Learning hiệu quả?
Không có một con số dữ liệu cố định để áp dụng Transfer Learning hiệu quả, nhưng phương pháp này thường hoạt động tốt ngay cả với tập dữ liệu nhỏ. Chỉ cần vài trăm đến vài nghìn mẫu có chất lượng và tương đồng với bài toán gốc, mô hình đã có thể cho kết quả khả quan. Khi dữ liệu quá ít, việc tăng cường dữ liệu (data augmentation) sẽ giúp cải thiện hiệu suất. Nhìn chung, trong Transfer Learning, độ phù hợp và chất lượng dữ liệu quan trọng hơn số lượng tuyệt đối.
Những mô hình pretrained phổ biến cho Transfer Learning là gì?
Một số mô hình pretrained phổ biến cho Transfer Learning phụ thuộc vào từng lĩnh vực:
- Thị giác máy tính: ResNet, VGG, Inception, EfficientNet, MobileNet.
- Xử lý ngôn ngữ tự nhiên (NLP): BERT, GPT, RoBERTa, DistilBERT.
- Âm thanh và đa phương thức: Wav2Vec, CLIP.
Các mô hình này đã được huấn luyện trên tập dữ liệu lớn và thường được dùng làm nền tảng để fine-tune cho các bài toán cụ thể.
Transfer Learning có thể áp dụng cho những lĩnh vực nào?
Transfer Learning có thể áp dụng trong nhiều lĩnh vực khác nhau, đặc biệt là những nơi dữ liệu huấn luyện hạn chế. Phổ biến nhất gồm thị giác máy tính (nhận dạng ảnh, phát hiện vật thể), xử lý ngôn ngữ tự nhiên (dịch máy, phân tích cảm xúc, chatbot), xử lý âm thanh (nhận dạng giọng nói) và y sinh học (chẩn đoán hình ảnh, phân tích dữ liệu y tế). Ngoài ra, phương pháp này còn được dùng trong tài chính, giáo dục và các bài toán dự đoán khác.
Transfer Learning có giúp giảm thời gian huấn luyện không?
Có. Transfer Learning giúp giảm đáng kể thời gian huấn luyện vì mô hình đã được học sẵn các đặc trưng từ dữ liệu lớn, nên bạn chỉ cần fine-tune cho bài toán mới thay vì huấn luyện từ đầu. Nhờ đó, quá trình huấn luyện nhanh hơn và tốn ít tài nguyên tính toán hơn.
Những lỗi thường gặp khi triển khai Transfer Learning là gì?
Những lỗi thường gặp khi triển khai Transfer Learning gồm:
- Dữ liệu không tương đồng: Bài toán mới quá khác so với dữ liệu mô hình gốc đã học.
- Fine-tune không phù hợp: Đóng băng hoặc mở quá nhiều tầng làm giảm hiệu suất.
- Overfitting: Dữ liệu ít nhưng huấn luyện quá lâu.
- Tiền xử lý sai: Dữ liệu đầu vào không đúng chuẩn của mô hình pretrained.
- Chọn mô hình không phù hợp: Mô hình quá lớn hoặc không đúng lĩnh vực.
Với khả năng tận dụng tri thức từ các mô hình đã huấn luyện trước đó, Transfer Learning giúp tiết kiệm đáng kể thời gian và tài nguyên tính toán. Dù có nguy cơ chuyển giao tiêu cực và giới hạn về domain, Transfer Learning vẫn là chiến lược hiệu quả trong xử lý ngôn ngữ tự nhiên và thị giác máy tính. Khi AI tiếp tục phát triển, Transfer Learning sẽ càng đóng vai trò quan trọng trong việc tạo ra các giải pháp học máy hiệu quả, đặc biệt trong bối cảnh nguồn dữ liệu có nhãn còn hạn chế.