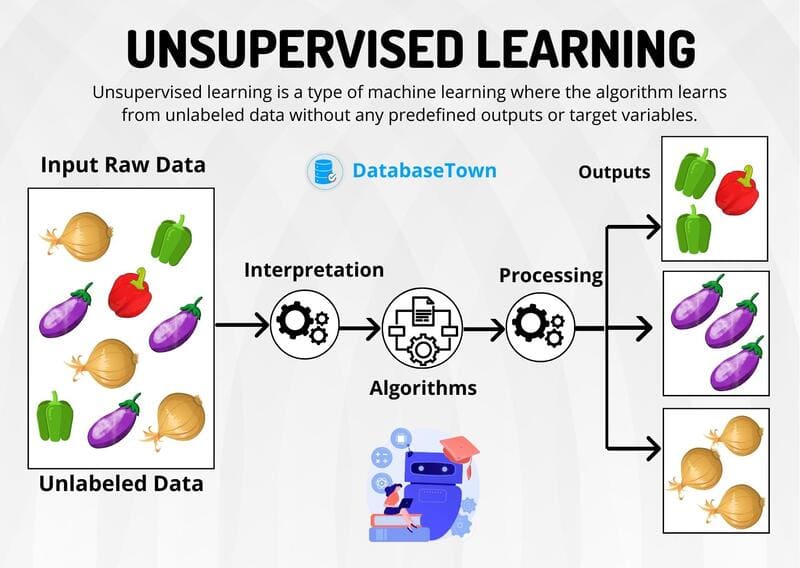
Học không giám sát (Unsupervised Learning) là một nhánh của Machine Learning, trong đó các thuật toán được thiết kế để phân tích và phân cụm các tập dữ liệu chưa được gán nhãn mà không cần sự can thiệp của con người. Không giống như học có giám sát, phương pháp này không dựa vào dữ liệu đã được gán nhãn trước để đào tạo mô hình, mà tập trung vào việc tự động khám phá các mẫu ẩn, cấu trúc và mối quan hệ trong dữ liệu.
Trong bài viết này, FPT.AI sẽ trình bày chi tiết về các phương pháp học không giám sát phổ biến bao gồm phân cụm (clustering), quy tắc liên kết (association rules) và giảm chiều dữ liệu (dimensionality reduction). Ngoài ra, bài viết cũng đề cập đến các ứng dụng quan trọng của Unsupervised Learning trong thực tế, so sánh phương pháp này với học có giám sát và học bán giám sát, đồng thời thảo luận về những thách thức mà học không giám sát phải đối mặt.
Unsupervised Learning là gì?
Học không giám sát (Unsupervised Learning), còn được gọi là học máy không giám sát (Unsupervised Machine Learning), sử dụng các thuật toán Machine Learning để phân tích và phân cụm các tập dữ liệu không được gán nhãn. Các thuật toán này khám phá các mẫu ẩn hoặc nhóm dữ liệu mà không cần sự can thiệp của con người.
Khả năng khám phá các điểm tương đồng và khác biệt trong thông tin của học không giám sát làm cho nó trở thành giải pháp lý tưởng cho phân tích dữ liệu khám phá, chiến lược bán chéo, phân khúc khách hàng và nhận dạng hình ảnh.
>>> XEM THÊM: Top 6 công cụ AI phân tích dữ liệu hàng đầu hiện nay
Các phương pháp học không giám sát phổ biến
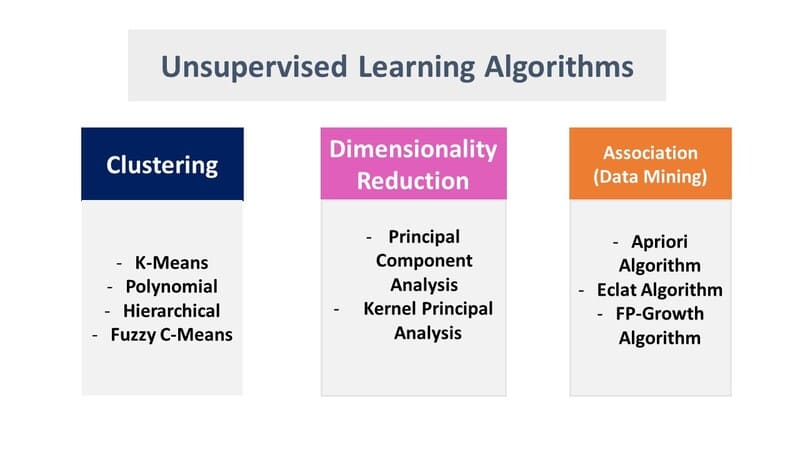
Các mô hình học không giám sát được sử dụng cho ba tác vụ chính—phân cụm, liên kết và giảm chiều dữ liệu. Dưới đây chúng ta sẽ khám phá các thuật toán và phương pháp phổ biến để thực hiện các tác vụ này một cách hiệu quả.
Phân cụm
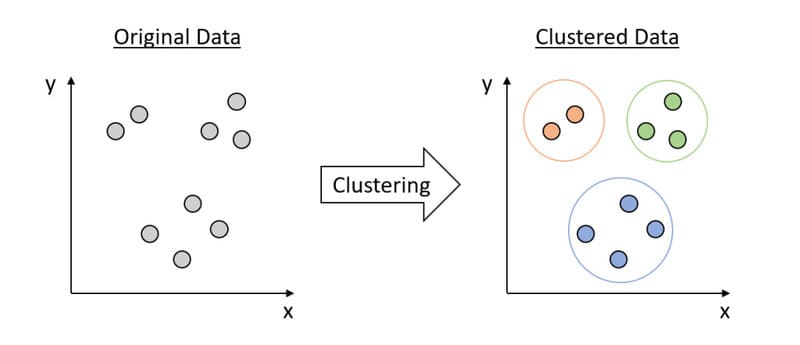
Phân cụm (Clustering) là một kỹ thuật khai thác dữ liệu nhóm dữ liệu không được gán nhãn dựa trên sự tương đồng hoặc khác biệt của chúng. Các thuật toán phân cụm được sử dụng để xử lý các đối tượng dữ liệu thô, chưa được phân loại thành các nhóm được biểu thị bởi cấu trúc hoặc mẫu trong thông tin. Thuật toán phân cụm có thể được phân loại thành một vài loại, cụ thể là loại trừ, chồng chéo, phân cấp và xác suất.
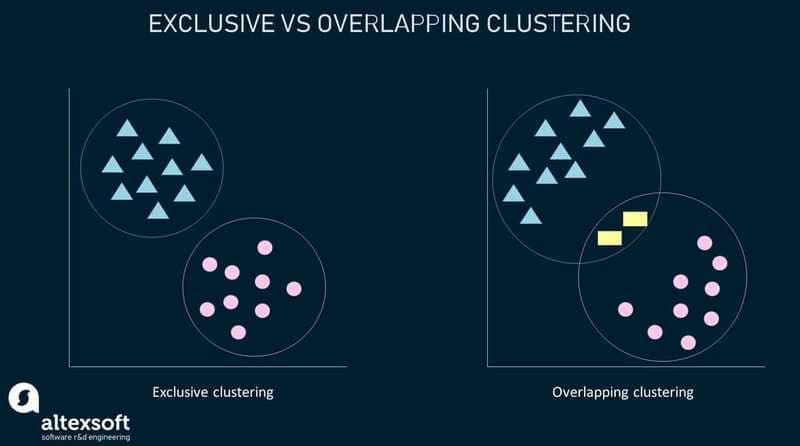
Phân cụm loại trừ và phân cụm chồng chéo
Phân cụm loại trừ (Exclusive Clustering) là một hình thức nhóm quy định một điểm dữ liệu chỉ có thể tồn tại trong một cụm. Điều này cũng có thể được gọi là phân cụm “cứng”. K-means Clustering là một ví dụ phổ biến về phương pháp phân cụm loại trừ, trong đó các điểm dữ liệu được gán vào K nhóm, với K đại diện cho số lượng cụm dựa trên khoảng cách từ tâm của mỗi nhóm.
Các điểm dữ liệu gần nhất với một tâm nhất định sẽ được phân cụm trong cùng một danh mục. Giá trị K lớn hơn sẽ chỉ ra các nhóm nhỏ hơn với nhiều chi tiết hơn, trong khi giá trị K nhỏ hơn sẽ có các nhóm lớn hơn và ít chi tiết hơn. K-means Clustering thường được sử dụng trong phân khúc thị trường, phân cụm tài liệu, phân đoạn hình ảnh và nén hình ảnh.
Phân cụm chồng chéo (Overlapping Clustering) khác với phân cụm loại trừ ở chỗ nó cho phép các điểm dữ liệu thuộc về nhiều cụm với các mức độ thành viên riêng biệt. Phân cụm K-means “mềm” hoặc mờ là một ví dụ về phân cụm chồng chéo.
>>> XEM THÊM: Gán nhãn dữ liệu là gì? Data Labeling trong học máy và AI
Phân cụm phân cấp
Phân cụm phân cấp (Hierarchical Clustering), còn được gọi là phân tích cụm phân cấp (Hierarchical Cluster Analysis – HCA), là một thuật toán phân cụm không giám sát có thể được phân loại theo hai cách: tích tụ hoặc phân chia.
Phân cụm tích tụ (Agglomerative Clustering) được coi là “phương pháp từ dưới lên”. Các điểm dữ liệu của nó ban đầu được cô lập thành các nhóm riêng biệt, và sau đó chúng được hợp nhất lặp đi lặp lại trên cơ sở tương đồng cho đến khi đạt được một cụm. Bốn phương pháp khác nhau thường được sử dụng để đo lường sự tương đồng:
- Ward’s Linkage: Khoảng cách giữa hai cụm được xác định bởi sự gia tăng tổng bình phương sau khi các cụm được hợp nhất.
- Average Linkage: Khoảng cách trung bình giữa hai điểm trong mỗi cụm.
- Complete (hoặc Maximum) Linkage: Khoảng cách tối đa giữa hai điểm trong mỗi cụm.
- Single (hoặc Minimum) Linkage: Khoảng cách tối thiểu giữa hai điểm trong mỗi cụm.
Khoảng cách Euclidean là thước đo phổ biến nhất được sử dụng để tính toán các khoảng cách này; tuy nhiên, các thước đo khác, như khoảng cách Manhattan, cũng được trích dẫn trong tài liệu phân cụm.
Phân cụm phân chia (Divisive Clustering) có thể được định nghĩa là đối lập với phân cụm tích tụ; thay vào đó, nó sử dụng phương pháp “từ trên xuống”. Trong trường hợp này, một cụm dữ liệu đơn lẻ được chia dựa trên sự khác biệt giữa các điểm dữ liệu. Phân cụm phân chia không được sử dụng phổ biến, nhưng nó vẫn đáng chú ý trong bối cảnh phân cụm phân cấp. Các quy trình phân cụm này thường được trực quan hóa bằng cách sử dụng biểu đồ cây (dendrogram), một sơ đồ dạng cây ghi lại việc hợp nhất hoặc tách các điểm dữ liệu ở mỗi lần lặp.
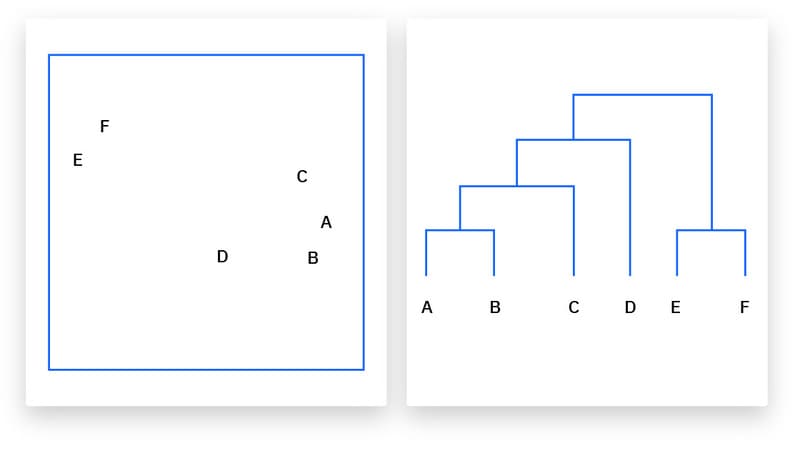
Phân cụm xác suất
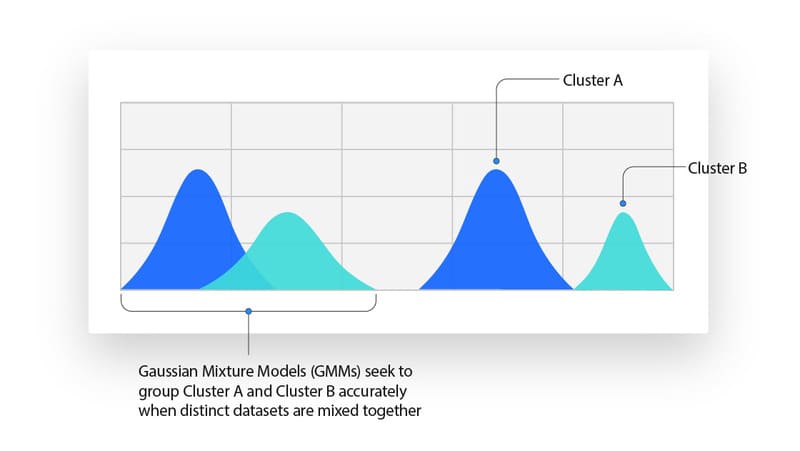
Mô hình xác suất (Probabilistic Model) là một kỹ thuật không giám sát giúp chúng ta giải quyết các vấn đề ước tính mật độ hoặc phân cụm “mềm”. Trong phân cụm xác suất, các điểm dữ liệu được phân cụm dựa trên khả năng chúng thuộc về một phân phối cụ thể. Gaussian Mixture Model (GMM) là một trong những phương pháp phân cụm xác suất được sử dụng phổ biến nhất.
Gaussian Mixture Models được phân loại là mô hình hỗn hợp, có nghĩa là chúng được tạo thành từ một số không xác định các hàm phân phối xác suất. GMMs chủ yếu được tận dụng để xác định một điểm dữ liệu nhất định thuộc về phân phối xác suất Gaussian, hoặc chuẩn, nào. Nếu giá trị trung bình hoặc phương sai được biết, thì chúng ta có thể xác định một điểm dữ liệu nhất định thuộc về phân phối nào.
Tuy nhiên, trong GMMs, các biến này không được biết, vì vậy chúng ta giả định rằng một biến ẩn, hoặc ẩn, tồn tại để phân cụm các điểm dữ liệu một cách thích hợp. Mặc dù không bắt buộc phải sử dụng thuật toán Expectation-Maximization (EM), nhưng nó thường được sử dụng để ước tính xác suất gán cho một điểm dữ liệu nhất định vào một cụm dữ liệu cụ thể.
>>> XEM THÊM: Masked Language Models là gì? Vai trò của MLMs trong NLP
Quy tắc liên kết
Quy tắc liên kết (Association Rule) là một phương pháp dựa trên quy tắc để tìm mối quan hệ giữa các biến trong một tập dữ liệu nhất định. Các phương pháp này thường được sử dụng để phân tích giỏ hàng thị trường, cho phép các công ty hiểu rõ hơn về mối quan hệ giữa các sản phẩm khác nhau. Hiểu thói quen tiêu dùng của khách hàng cho phép doanh nghiệp phát triển chiến lược bán chéo và công cụ đề xuất tốt hơn.
Ví dụ về điều này có thể được thấy trong mục “Khách hàng đã mua mặt hàng này cũng đã mua” của Amazon hoặc danh sách phát “Discover Weekly” của Spotify. Mặc dù có một vài thuật toán khác nhau được sử dụng để tạo ra các quy tắc liên kết, thuật toán Apriori được sử dụng rộng rãi nhất.
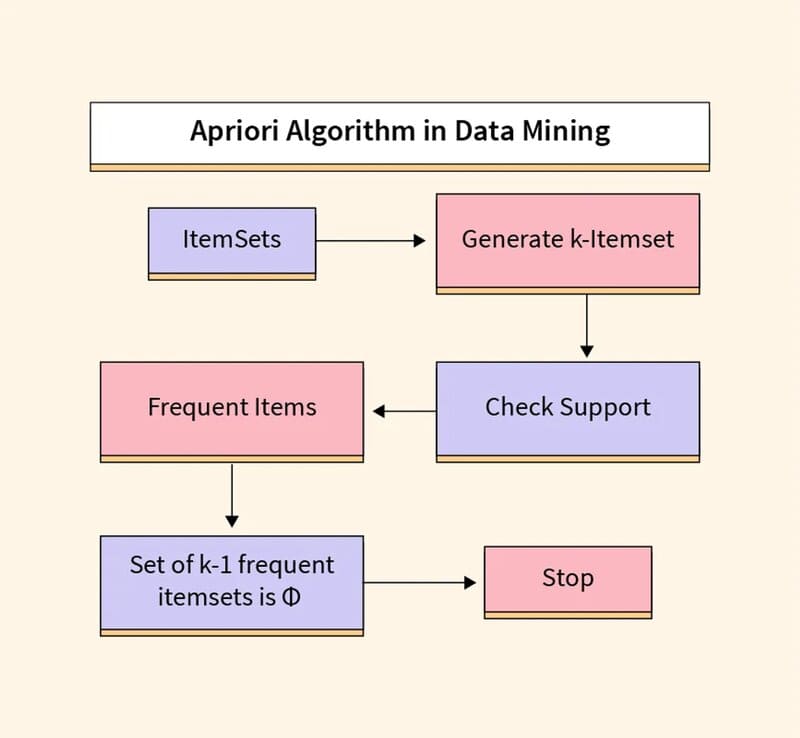
Thuật toán Apriori được phổ biến thông qua phân tích giỏ hàng thị trường, dẫn đến các công cụ đề xuất khác nhau cho các nền tảng âm nhạc và nhà bán lẻ trực tuyến. Chúng được sử dụng trong các tập dữ liệu giao dịch để xác định các tập mục thường xuyên, hoặc bộ sưu tập các mục, để xác định khả năng tiêu thụ một sản phẩm khi đã tiêu thụ sản phẩm khác.
Ví dụ, nếu tôi phát radio của Black Sabbath trên Spotify, bắt đầu với bài hát “Orchid” của họ, một trong những bài hát khác trên kênh này có thể là bài hát của Led Zeppelin, như “Over the Hills and Far Away”. Điều này dựa trên thói quen nghe của tôi trước đây cũng như của những người khác. Thuật toán Apriori sử dụng cây băm để đếm các tập mục, điều hướng qua tập dữ liệu theo cách thức ưu tiên chiều rộng.
>>> XEM THÊM: Text mining là gì? So sánh Text mining và Data Mining
Giảm chiều dữ liệu
Mặc dù nhiều dữ liệu hơn thường mang lại kết quả chính xác hơn, nhưng nó cũng có thể ảnh hưởng đến hiệu suất của các thuật toán Machine Learning (ví dụ: quá khớp) và cũng có thể làm cho việc trực quan hóa tập dữ liệu trở nên khó khăn.
Giảm chiều dữ liệu (Dimensionality Reduction) là một kỹ thuật được sử dụng khi số lượng đặc trưng, hoặc chiều, trong một tập dữ liệu nhất định quá cao. Nó giảm số lượng đầu vào dữ liệu xuống một kích thước có thể quản lý được đồng thời vẫn bảo toàn tính toàn vẹn của tập dữ liệu nhiều nhất có thể.
Nó thường được sử dụng trong giai đoạn tiền xử lý dữ liệu, và có một vài phương pháp giảm chiều dữ liệu khác nhau có thể được sử dụng, chẳng hạn như:
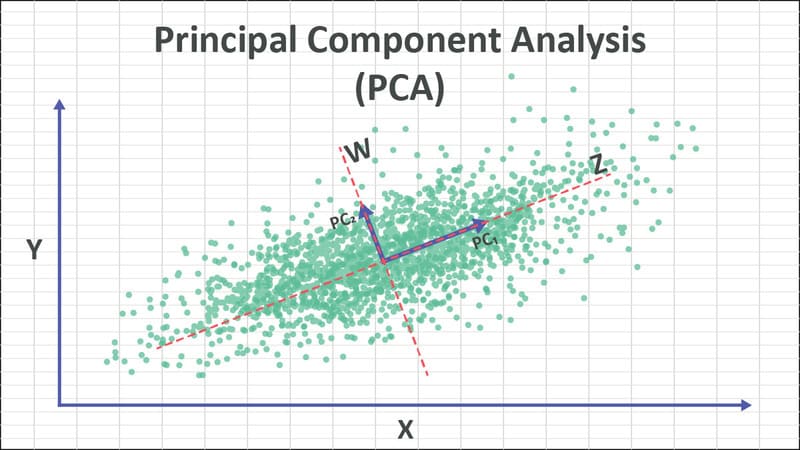
Principal Component Analysis
Principal Component Analysis (PCA) là một loại thuật toán giảm chiều dữ liệu được sử dụng để giảm dư thừa và nén tập dữ liệu thông qua trích xuất đặc trưng. Phương pháp này sử dụng phép biến đổi tuyến tính để tạo ra một biểu diễn dữ liệu mới, tạo ra một tập hợp “thành phần chính”. Thành phần chính đầu tiên là hướng tối đa hóa phương sai của tập dữ liệu.
Trong khi thành phần chính thứ hai cũng tìm phương sai tối đa trong dữ liệu, nó hoàn toàn không tương quan với thành phần chính đầu tiên, tạo ra một hướng vuông góc, hoặc trực giao, với thành phần đầu tiên. Quá trình này lặp lại dựa trên số lượng chiều, trong đó thành phần chính tiếp theo là hướng trực giao với các thành phần trước đó với phương sai lớn nhất.
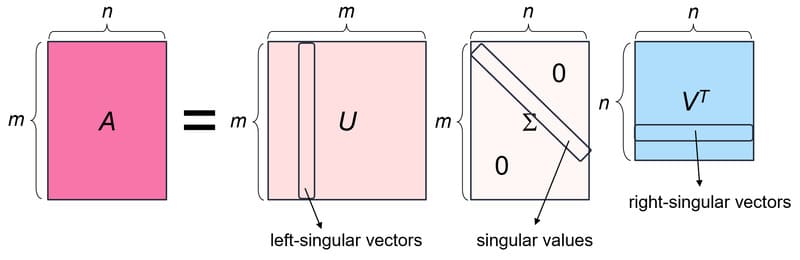
Singular Value Decomposition
Singular Value Decomposition (SVD) là một phương pháp giảm chiều dữ liệu khác phân rã một ma trận, A, thành ba ma trận hạng thấp. SVD được biểu thị bằng công thức, A = USVT, trong đó U và V là các ma trận trực giao. S là một ma trận đường chéo, và các giá trị S được coi là giá trị kỳ dị của ma trận A. Tương tự như PCA, nó thường được sử dụng để giảm nhiễu và nén dữ liệu, chẳng hạn như tệp hình ảnh.
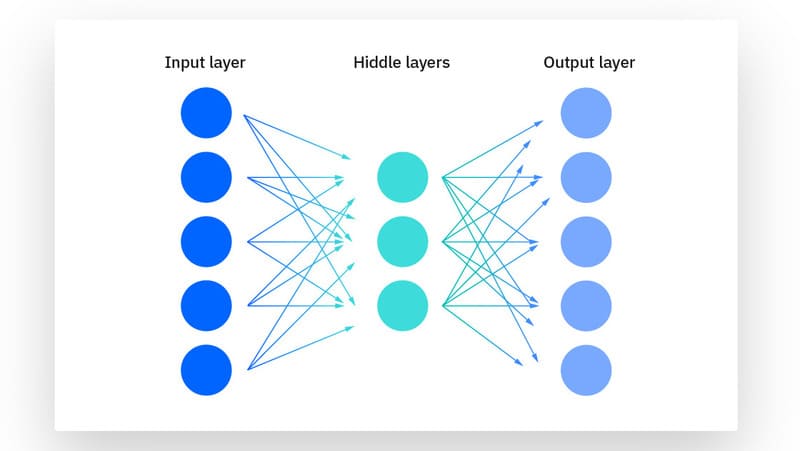
Autoencoders
Autoencoders tận dụng mạng nơ-ron (Neural Network) để nén dữ liệu và sau đó tạo lại một biểu diễn mới của đầu vào dữ liệu gốc. Nhìn vào hình ảnh dưới đây, bạn có thể thấy rằng lớp ẩn cụ thể hoạt động như một nút thắt để nén lớp đầu vào trước khi tái tạo trong lớp đầu ra. Giai đoạn từ lớp đầu vào đến lớp ẩn được gọi là “mã hóa” trong khi giai đoạn từ lớp ẩn đến lớp đầu ra được gọi là “giải mã”.
>>> XEM THÊM: Generative AI vs Machine Learning: Những khác biệt chính
Ứng dụng nổi bật của Unsupervised Learning là gì?
Các kỹ thuật Machine Learning đã trở thành một phương pháp phổ biến để cải thiện trải nghiệm người dùng sản phẩm và kiểm tra hệ thống để đảm bảo chất lượng. Học không giám sát cung cấp một con đường khám phá để xem dữ liệu, cho phép doanh nghiệp xác định mẫu trong khối lượng dữ liệu lớn nhanh hơn so với quan sát thủ công. Một số ứng dụng thực tế phổ biến nhất của học không giám sát là:
- Mục tin tức: Google News sử dụng học không giám sát để phân loại các bài báo về cùng một câu chuyện từ các cơ quan tin tức trực tuyến khác nhau. Ví dụ, kết quả của một cuộc bầu cử tổng thống có thể được phân loại theo nhãn của họ cho tin tức “US”.
- Thị giác máy tính (Computer Vision): Các thuật toán học không giám sát được sử dụng cho các tác vụ nhận thức thị giác, chẳng hạn như nhận dạng đối tượng.
- Hình ảnh y tế: Học máy không giám sát cung cấp các tính năng thiết yếu cho các thiết bị hình ảnh y tế, chẳng hạn như phát hiện hình ảnh, phân loại và phân đoạn, được sử dụng trong chẩn đoán X-quang và bệnh lý để chẩn đoán bệnh nhân nhanh chóng và chính xác.
- Phát hiện bất thường: Các mô hình học không giám sát có thể chải qua một lượng lớn dữ liệu và khám phá các điểm dữ liệu không điển hình trong một tập dữ liệu. Những bất thường này có thể nâng cao nhận thức về thiết bị lỗi, lỗi con người hoặc vi phạm bảo mật.
- Chân dung khách hàng: Xác định chân dung khách hàng giúp dễ dàng hiểu các đặc điểm chung và thói quen mua hàng của khách hàng doanh nghiệp. Học không giám sát cho phép doanh nghiệp xây dựng hồ sơ đại diện người mua tốt hơn, cho phép các tổ chức điều chỉnh thông điệp sản phẩm của họ phù hợp hơn.
- Công cụ đề xuất: Sử dụng dữ liệu hành vi mua hàng trong quá khứ, học không giám sát có thể giúp khám phá xu hướng dữ liệu có thể được sử dụng để phát triển chiến lược bán chéo hiệu quả hơn. Điều này được sử dụng để đưa ra các đề xuất bổ sung phù hợp cho khách hàng trong quá trình thanh toán cho các nhà bán lẻ trực tuyến.
>>> XEM THÊM: Machine Vision là gì? So sánh Machine Vision vs Computer Vision
So sánh học bán giám sát, học có giám sát và học không giám sát
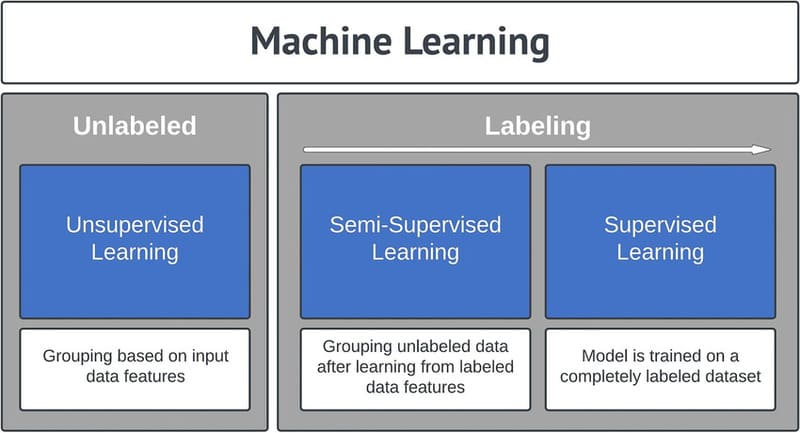
Học không giám sát và học có giám sát thường được thảo luận cùng nhau. Không giống như các thuật toán học không giám sát, các thuật toán học có giám sát sử dụng dữ liệu được gán nhãn. Từ dữ liệu đó, nó dự đoán kết quả trong tương lai hoặc gán dữ liệu vào các danh mục cụ thể dựa trên vấn đề hồi quy hoặc phân loại mà nó đang cố gắng giải quyết.
Trong khi các thuật toán học có giám sát có xu hướng chính xác hơn các mô hình học không giám sát, chúng đòi hỏi sự can thiệp của con người từ đầu để gán nhãn dữ liệu một cách thích hợp. Tuy nhiên, các tập dữ liệu được gán nhãn này cho phép các thuật toán học có giám sát tránh độ phức tạp tính toán vì chúng không cần một tập huấn luyện lớn để tạo ra kết quả dự định. Các kỹ thuật hồi quy và phân loại phổ biến là hồi quy tuyến tính và logistic, Naive Bayes, thuật toán KNN và Random Forest.
Học bán giám sát (Semi-Supervised Learning) xảy ra khi chỉ một phần của dữ liệu đầu vào đã được gán nhãn. Học không giám sát và học bán giám sát có thể là các lựa chọn thay thế hấp dẫn hơn vì có thể tốn thời gian và chi phí để dựa vào chuyên môn lĩnh vực để gán nhãn dữ liệu phù hợp cho học có giám sát.
Thách thức của Unsupervised Learning
Mặc dù học không giám sát có nhiều lợi ích, một số thách thức có thể xảy ra khi nó cho phép các mô hình Machine Learning thực thi mà không có bất kỳ sự can thiệp nào của con người. Một số thách thức này có thể bao gồm:
- Độ phức tạp tính toán do khối lượng lớn dữ liệu đào tạo
- Thời gian đào tạo dài hơn
- Nguy cơ cao hơn về kết quả không chính xác
- Sự can thiệp của con người để xác nhận biến đầu ra
- Thiếu minh bạch về cơ sở dữ liệu được phân cụm
Tóm lại, Unsupervised Learning là một phương pháp Machine Learning mạnh mẽ giúp khám phá cấu trúc và mẫu ẩn trong dữ liệu không được gán nhãn. Trong tương lai, học không giám sát dự kiến sẽ phát triển mạnh mẽ với sự tích hợp các kỹ thuật học sâu tiên tiến, có khả năng xử lý dữ liệu đa phương tiện phức tạp, giúp con người khai thác tối đa tiềm năng và giá trị của dữ liệu lớn.
>>> XEM THÊM: