Text to Speech (TTS) là công nghệ chuyển đổi văn bản trên giao diện kỹ thuật số thành âm thanh tự nhiên, giúp máy tính có thể đọc nội dung văn bản một cách gần giống với giọng người thật. Nhu cầu về công nghệ này đang tăng mạnh mẽ, với tốc độ tăng trưởng CAGR của thị trường lên đến 13,7% trong giai đoạn 2024-2029, dự kiến đạt 7,6 tỷ USD vào năm 2029 (theo thống kê từ Markets and Markets).
Trong bài viết sau, FPT.AI sẽ phân tích lịch sử phát triển, cơ chế hoạt động, các ứng dụng thực tế, hạn chế hiện tại cũng như xu hướng phát triển trong tương lai của công nghệ Text to Speech.
Text to Speech là gì?
Text to Speech (TTS) là công nghệ chuyển đổi văn bản trên giao diện kỹ thuật số thành âm thanh tự nhiên, giúp máy tính có thể đọc nội dung văn bản một cách gần giống với giọng người thật. Công nghệ này còn được biết đến với các tên gọi khác như “công nghệ đọc to” hoặc “tổng hợp giọng nói do máy tính tạo ra” (computer-generated speech synthesis). Hầu hết các công ty cung cấp công nghệ Text to Speech dưới dạng API, cho phép các nhà phát triển dễ dàng tích hợp khả năng chuyển văn bản thành giọng nói vào ứng dụng, trang web, hoặc dịch vụ của họ.

Ban đầu, TTS được phát triển như một công nghệ hỗ trợ nhằm giúp người khiếm thị và người mắc chứng khó đọc dễ dàng tiếp cận thông tin và dịch vụ thông qua máy tính và các thiết bị điện tử. Ngày nay, TTS đã trở thành nền tảng quan trọng cho nhiều trợ lý ảo, tổng đài tự động, hệ thống điều hướng GPS, đóng vai trò thiết yếu trong việc cải thiện giao tiếp giữa con người với máy móc và góp phần xây dựng một thế giới kỹ thuật số ngày càng dễ tiếp cận hơn.
>>> XEM NGAY: Review chi tiết 10 phần mềm chuyển văn bản thành giọng nói online miễn phí
Sự phát triển của công nghệ Text to Speech
Bộ tổng hợp giọng nói điện đầu tiên xuất hiện vào khoảng những năm 1930, đánh dấu bước khởi đầu của công nghệ Text to Speech. Những thiết bị này có khả năng chuyển đổi văn bản thành giọng nói rất giới hạn và vận hành phức tạp, chủ yếu phục vụ mục đích nghiên cứu và thử nghiệm.
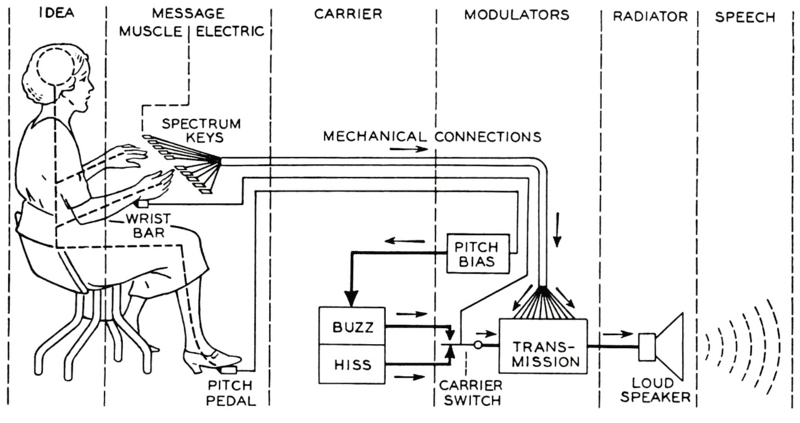
Vào cuối những năm 1950, khi máy tính ra đời, các lập trình viên bắt đầu nghiên cứu các thuật toán có thể truy cập vào cơ sở dữ liệu lớn. Những thuật toán này hoạt động bằng cách tìm kiếm các tệp âm thanh khớp với đơn vị văn bản và ghép các thành phần giọng nói lại với nhau. Trong giai đoạn này, giọng nói được tạo ra thường nghe giống như tiếng máy móc và thiếu tự nhiên.
Bước ngoặt quan trọng diễn ra vào những năm 2000 khi các kỹ thuật Deep Learning và mạng nơ-ron (Neural Network) bắt đầu được ứng dụng. Các lập trình viên đã chuyển từ phương pháp ghép nối đơn vị âm thanh sang mô hình hóa dạng sóng trực tiếp bằng các bản ghi âm giọng nói thực tế.
Phương pháp mới này đã dẫn đến sự ra đời của giọng nói chất lượng cao nghe có vẻ chân thực hơn nhiều so với trước đây. Song song với đó, các nhà khoa học máy tính cũng đạt được những tiến bộ đáng kể trong lĩnh vực nhận diện giọng nói (Automatic Speech Recognition) và xử lý ngôn ngữ tự nhiên (Natural Language Processing).

Trong thập kỷ gần đây, AI và Machine Learning đã giúp việc tạo ra giọng nói nghe tự nhiên trở nên dễ dàng hơn bao giờ hết. Chất lượng của các hệ thống TTS hiện đại đã tiến gần đến mức khó phân biệt với giọng người thật.
Tuy nhiên, những tiến bộ này cũng mở ra những lĩnh vực gây tranh cãi mới, đặc biệt là công nghệ deepfake âm thanh – có thể bắt chước giọng nói của một người cụ thể mà không được sự đồng ý. Nhận thức được những rủi ro tiềm ẩn, các công ty công nghệ đang nỗ lực phát triển các hệ thống phân tích giọng nói theo thời gian thực để phát hiện deepfake, đảm bảo sự phát triển lành mạnh của công nghệ TTS.

>>> XEM THÊM: Conversational AI là gì? So sánh Conversational AI và Generative AI
Cơ chế hoạt động của công nghệ Text to Speech là gì?
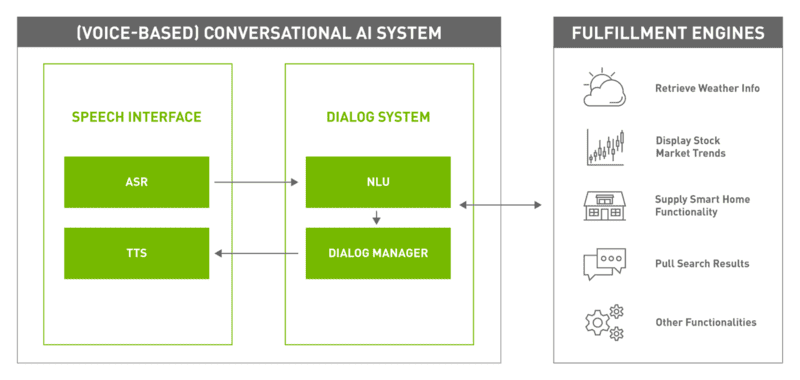
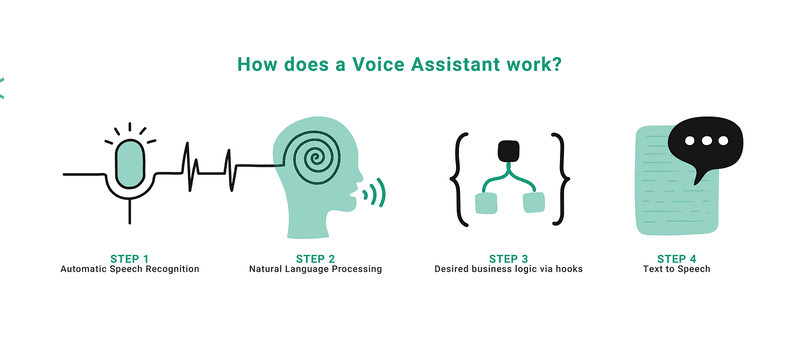
Text to Speech là một quá trình gồm cả phân tích ngôn ngữ và tổng hợp giọng nói. Các kỹ thuật học sâu cho phép các mô hình tổng hợp giọng nói phân tích nhiều dữ liệu và hiểu rõ hơn mối quan hệ giữa các từ và đặc điểm âm thanh của chúng, từ đó tạo ra giọng nói AI chân thực hơn.
Phân tích ngôn ngữ (Linguistic analysis)
Khi nhận được đầu vào văn bản, mô hình TTS trước tiên sử dụng mạng nơ-ron sâu (Deep neural networks) để phân tích các từ, dấu câu và cấu trúc câu, hiểu cách các từ, giọng điệu, cao độ, âm lượng, nhịp điệu,… khớp với giọng nói. Hệ thống mở rộng các từ viết tắt và biểu thức, tính toán độ dài của các từ, tìm cách phát âm phù hợp và lập biểu đồ ngữ điệu của các cụm từ và câu để chuẩn bị cho quá trình chuyển đổi.
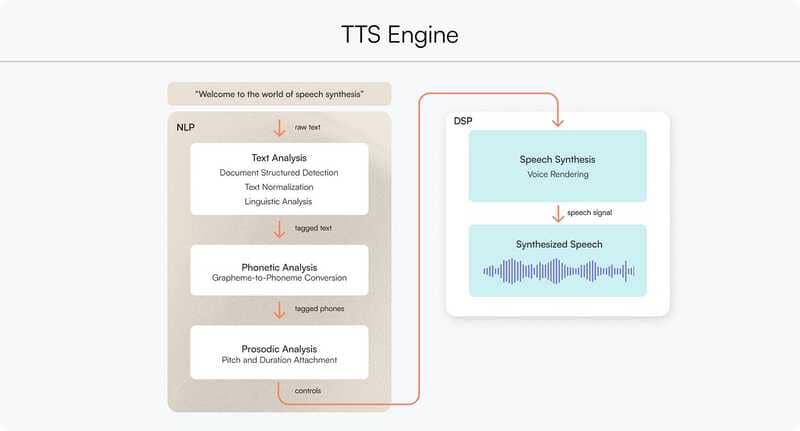
Tổng hợp giọng nói (Speech synthesis)
Sau khi văn bản được phân tích đầy đủ, mô hình sử dụng quy trình hai bước để biến nó thành đầu ra giọng nói:
- Tạo đặc trưng âm thanh: Mô hình chuyển đổi văn bản thành các tính năng được căn chỉnh theo thời gian như phổ đồ (spectrogram – được sử dụng để lập bản đồ biến thể tần số theo thời gian). Spectrogram giúp mô hình nắm bắt được đặc điểm chi tiết trong giọng nói và các yếu tố trong cách phát âm, trọng âm và thời gian của từ phụ thuộc vào ngữ cảnh.
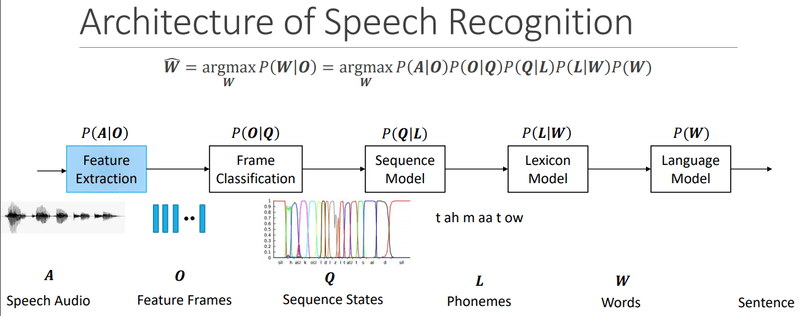
- Chuyển đổi thành sóng âm thanh: Mạng mã hóa giọng nói (vocoder) như WaveNet hoặc WaveGlow biến các mel spectrogram thành dạng sóng âm thanh mà máy tính có thể chuyển đổi thành giọng nói nghe tự nhiên. Một số mô hình chuyển văn bản thành giọng nói cho phép người dùng thay đổi âm lượng, cao độ, tốc độ và lựa chọn giữa các ngôn ngữ, giọng và phong cách nói khác nhau.
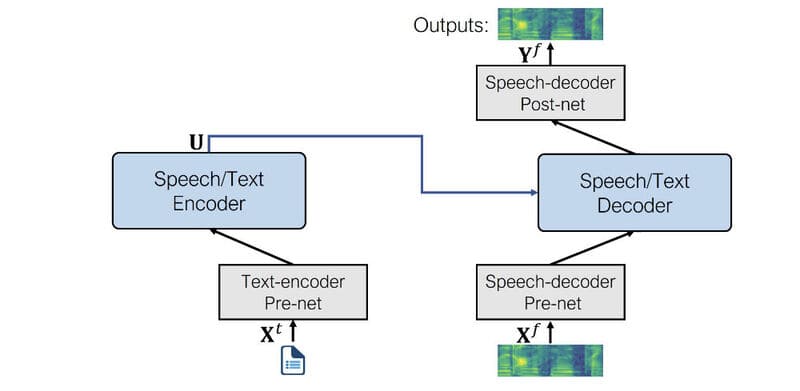
Nhiều thiết bị như điện thoại thông minh có tích hợp sẵn hệ thống chuyển văn bản thành giọng nói. Text to Speech cũng có sẵn dưới dạng các phần mềm, tiện ích mở rộng của trình duyệt, website hoặc ứng dụng có thể tải xuống.
>>> XEM THÊM: Giọng nói AI là gì? Cách tạo giọng nói bằng AI miễn phí
Các trường hợp sử dụng thực tế của công nghệ Text to Speech
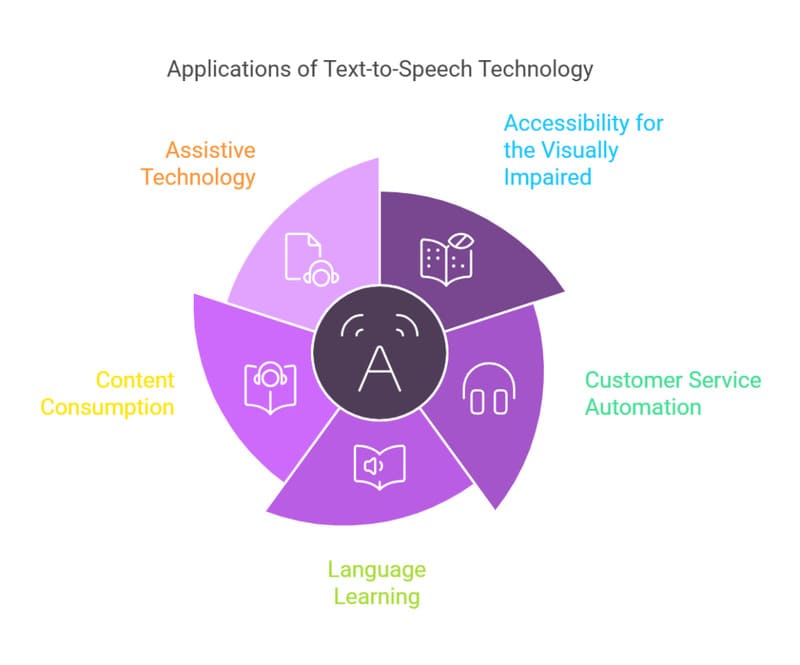
TTS đang được ứng dụng mạnh mẽ trong các hệ thống Conversational AI, đặc biệt là các ứng dụng nhận diện giọng nói tự động (ASR) và Xử lý ngôn ngữ tự nhiên (NLP). Công nghệ này cho phép người bận rộn có thể tiếp cận thông tin nhanh chóng mà không cần dừng lại để đọc, phù hợp cho lối sống hiện đại. Một số ứng dụng nổi bật của Text to Speech bao gồm:
- Audio content: Công nghệ TTS đọc to các văn bản kỹ thuật số, sách, bài học và hướng dẫn. Các tổ chức tin tức cũng sử dụng TTS để chuyển đổi bài viết sang định dạng âm thanh, giúp người dùng tiếp cận thông tin một cách linh hoạt hơn.
- Giáo dục và học tập: TTS giúp học sinh chú ý và đọc theo văn bản, cải thiện cách phát âm và liên kết từ. Công nghệ này hỗ trợ những người gặp khó khăn về thị lực hoặc mắc chứng khó đọc, giúp họ tiếp thu kiến thức tốt hơn. TTS cũng đọc to các tác phẩm do học sinh viết để kiểm tra bài tập luận, cải thiện kỹ năng nghe và giúp ghi nhớ nội dung học tập tốt hơn.
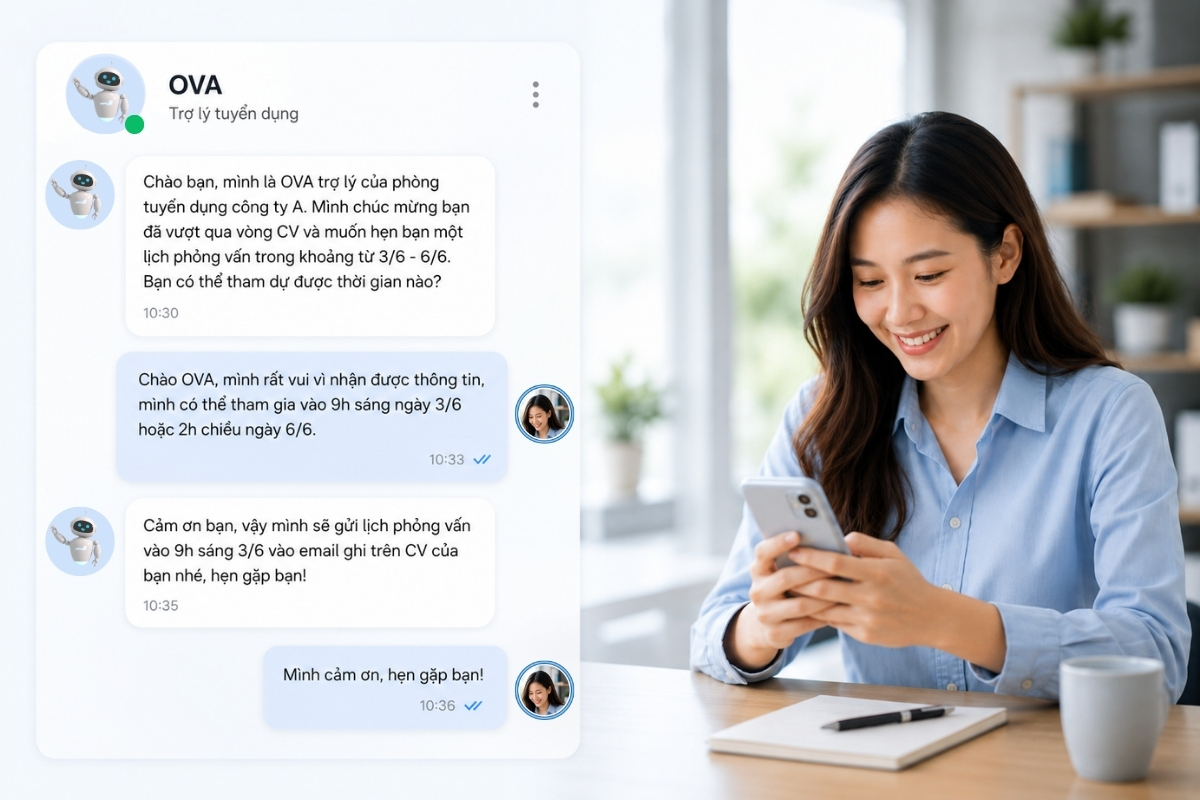
- Trợ lý ảo và Chatbot: Các trợ lý ảo như Siri, Google Assistant và Alexa tích hợp cả công nghệ TTS và STT (Speech-to-Text) để hiểu yêu cầu và tương tác tự nhiên với người dùng. Chúng có thể đọc tin nhắn, thông báo, phát thông tin khi người dùng đang lái xe và hỗ trợ dịch vụ khách hàng 24/7, làm cho trải nghiệm người dùng trở nên tương tác và thân thiện hơn.
- Điều hướng và bản đồ GPS: TTS cho phép GPS và ứng dụng bản đồ cung cấp chỉ đường theo thời gian thực, giúp tài xế tập trung lái xe mà không cần nhìn vào màn hình. Hệ thống có thể đọc tên đường, cảnh báo tình trạng giao thông và đề xuất tuyến đường thay thế, cải thiện an toàn khi di chuyển.
- Giao tiếp đa ngôn ngữ và học ngôn ngữ: TTS hỗ trợ người dùng giao tiếp bằng nhiều ngôn ngữ khác nhau thông qua ứng dụng như Google Dịch. Công nghệ này giúp người học làm quen với giọng nói tự nhiên và hiểu cách phát âm các từ khác nhau, đồng thời có thể được sử dụng để lồng tiếng cho nội dung video.

- Phương tiện truyền thông và giải trí: TTS được sử dụng để tạo bình luận và tường thuật trong trò chơi điện tử, lồng tiếng cho nhân vật và chuyển đổi sách viết thành sách nói. Công nghệ này tiết kiệm chi phí sản xuất phương tiện truyền thông và mở rộng khả năng tiếp cận nội dung cho người dùng.
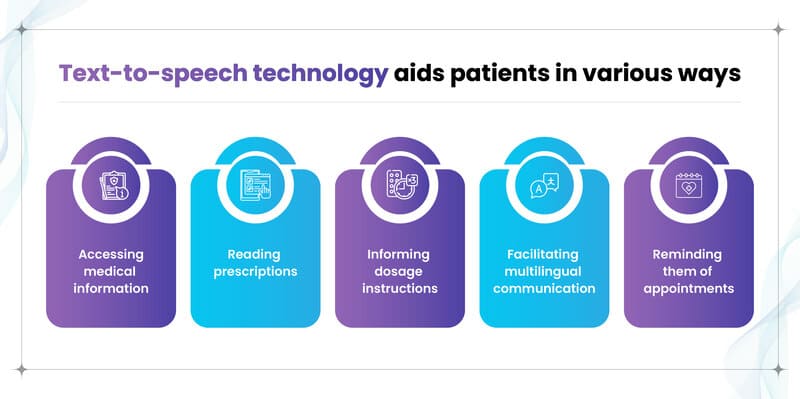
- Chăm sóc sức khỏe: Các tổ chức y tế sử dụng TTS để giao tiếp với bệnh nhân thông qua phiên bản âm thanh của tài liệu y tế, hướng dẫn sử dụng thiết bị và đọc đơn thuốc. Hệ thống TTS cũng giúp nhắc nhở bệnh nhân về lịch hẹn và uống thuốc đúng giờ, đặc biệt hữu ích cho người khiếm thị hoặc có vấn đề về giọng nói.
- Marketing và quảng cáo: TTS giúp tạo nội dung quảng cáo tự động, tối ưu hóa chi phí sản xuất mà không cần thuê diễn viên lồng tiếng. Công nghệ này hỗ trợ cá nhân hóa trải nghiệm khách hàng thông qua email marketing và chatbot giọng nói, làm cho chiến dịch tiếp thị trở nên hiệu quả hơn.
- Thiết bị IoT và nhà thông minh: TTS được tích hợp vào các thiết bị IoT như loa thông minh, đồng hồ thông minh và hệ thống an ninh gia đình. Công nghệ này giúp thiết bị giao tiếp với người dùng thông qua giọng nói, thực hiện các tác vụ như thông báo thời tiết, nhắc lịch trình và cảnh báo an ninh, tạo trải nghiệm tương tác tự nhiên và hiệu quả.
- Dịch vụ khách hàng và hệ thống điện thoại tự động: TTS được sử dụng trong hệ thống điện thoại tự động để trả lời cuộc gọi và cung cấp tùy chọn cho người dùng. Các hệ thống nhận dạng giọng nói kết hợp với TTS có thể xử lý các truy vấn phức tạp, tìm kiếm câu trả lời trong cơ sở dữ liệu và đưa ra phản hồi bằng giọng nói, thay thế tổng đài viên truyền thống.

>>> XEM THÊM: Thông báo giao dịch bằng giọng nói – Xu thế tất yếu của Ngân hàng số
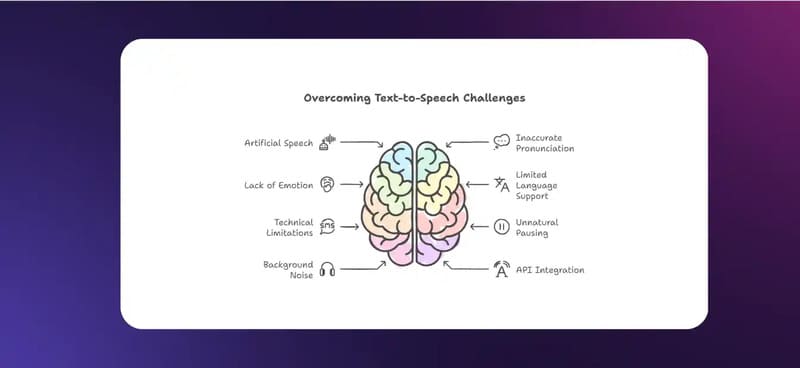
Hạn chế khi triển khai công nghệ Text to Speech là gì?
- Chất lượng giọng nói chưa hoàn toàn tự nhiên: Mặc dù công nghệ TTS hiện đại đã cải thiện đáng kể, nhưng nhiều hệ thống vẫn mắc lỗi tạo ra giọng nói có âm sắc máy móc, đơn điệu và thiếu sự trôi chảy. Điều này gây khó khăn cho người nghe khi tập trung và làm giảm mức độ tương tác với nội dung.
- Thiếu cảm xúc và sắc thái trong giọng nói: Công nghệ TTS gặp khó khăn trong việc truyền tải cảm xúc như vui vẻ, buồn bã, ngạc nhiên – những điều con người thể hiện tự nhiên. Hạn chế này làm cho TTS ít phù hợp với các nội dung đòi hỏi biểu cảm mạnh như đọc truyện, thơ, thoại phim hoặc thuyết minh quảng cáo.
- Lỗi phát âm và đọc sai từ đặc biệt: Hệ thống TTS thường phát âm sai tên riêng, tiếng lóng, thuật ngữ chuyên ngành, từ nước ngoài hoặc các từ đồng âm khác nghĩa. Điều này gây nhầm lẫn cho người nghe, đặc biệt trong các lĩnh vực chuyên môn như y tế, tài chính-ngân hàng và công nghệ.
- Hiểu sai ngữ cảnh dẫn đến ngữ điệu không phù hợp: Công nghệ TTS không có khả năng hiểu sâu ngữ cảnh như con người, dẫn đến sai sót trong nhấn nhá và ngắt nghỉ câu. Điều này làm giảm tính mạch lạc và gây khó khăn cho người dùng khi tiếp thu nội dung.
- Xử lý chữ viết tắt không đồng nhất: Nhiều hệ thống TTS xử lý không nhất quán các chữ viết tắt, đọc theo nhiều cách khác nhau trong cùng một văn bản, gây khó hiểu và làm giảm chất lượng trải nghiệm nghe.
- Hỗ trợ đa ngôn ngữ chưa hoàn thiện: Dù nhiều hệ thống TTS hỗ trợ đa ngôn ngữ, chúng vẫn gặp khó khăn khi xử lý văn bản có nhiều ngôn ngữ pha trộn. Các từ ngoại lai trong một câu thường bị phát âm sai hoặc không tự nhiên, làm giảm tính liên tục của nội dung.
- Khó duy trì giọng điệu mạch lạc trong văn bản dài: TTS thường không duy trì được giọng điệu nhất quán khi xử lý các văn bản dài, dẫn đến những thay đổi bất thường trong ngữ điệu và làm giảm trải nghiệm nghe tổng thể.
- Đặt câu và nhấn nhá chưa chính xác: Hệ thống TTS có xu hướng ngắt câu không đúng vị trí và lên xuống giọng không phù hợp, khiến nội dung trở nên khó hiểu. Vấn đề này đặc biệt nghiêm trọng với các ngôn ngữ giàu sắc thái như tiếng Việt, tiếng Trung, tiếng Hàn và tiếng Nhật.
- Yêu cầu tài nguyên phần cứng mạnh: Một thách thức lớn của công nghệ TTS là các hệ thống dựa trên AI hiện đại đòi hỏi nhiều tài nguyên tính toán, dẫn đến chi phí vận hành cao. Điều này gây khó khăn cho việc triển khai trên các thiết bị di động hoặc hệ thống có hiệu suất thấp.
- Giới hạn trong cá nhân hóa giọng nói: Mặc dù một số công nghệ TTS cho phép người dùng tùy chỉnh giọng đọc, việc tạo ra giọng nói hoàn toàn cá nhân hóa (như mô phỏng giọng của một người cụ thể) vẫn là một thách thức lớn, hạn chế khả năng đáp ứng nhu cầu đa dạng của người dùng.
>>> XEM THÊM: Lưu ngay 8 cách chuyển ghi âm thành văn bản online miễn phí
Xu hướng phát triển của công nghệ TTS trong tương lai
- Tích hợp AI để nâng cao chất lượng giọng nói: Các mô hình AI tiên tiến như Transformers, WaveNet và Tacotron đang được tích hợp mạnh mẽ vào TTS, tạo ra giọng nói ngày càng chân thực. Nhờ học máy, hệ thống TTS sẽ hiểu ngữ cảnh sâu hơn, điều chỉnh ngữ điệu chính xác và tạo giọng nói gần với con người. Công nghệ AI còn cải thiện khả năng hiểu ngôn ngữ và văn hóa, giúp phát âm chính xác hơn trong các tình huống giao tiếp tự nhiên.
- Nhân bản giọng nói (Voice Cloning): Công nghệ này cho phép sao chép và tái tạo giọng nói của một cá nhân cụ thể để sử dụng trong các ứng dụng TTS. Khả năng này mở ra cơ hội cá nhân hóa trải nghiệm người dùng trong nhiều lĩnh vực như sách nói, trợ lý ảo (Voicebot) và tổng đài chăm sóc khách hàng, tạo ra sự kết nối cá nhân mạnh mẽ hơn với người dùng.
- Lồng tiếng bằng AI (AI Dubbing): Công nghệ AI Dubbing sẽ cách mạng hóa nội dung đa phương tiện bằng cách đồng bộ giọng nói với chuyển động miệng trong video một cách tự nhiên. Điều này tối ưu hóa việc lồng tiếng phim, video giáo dục và nội dung trực tuyến, đồng thời tự động chuyển đổi ngôn ngữ tạo ra các bản dịch thoại sát với nguyên bản hơn trước đây.
- Chuyển đổi giọng nói (Voice Conversion): Công nghệ này cho phép chuyển đổi từ giọng nói của một người sang một giọng khác mà không cần thu âm mới. Tính năng này đem lại sự linh hoạt trong sáng tạo nội dung, đặc biệt hữu ích cho phát triển trò chơi điện tử, phim hoạt hình và podcast, giúp đa dạng hóa nhân vật và nội dung.
- Giọng nói với cảm xúc thông minh: Trong tương lai, công nghệ TTS sẽ phát triển khả năng cảm nhận cảm xúc và điều chỉnh giọng nói phù hợp với từng bối cảnh cụ thể. Tính năng này sẽ tạo ra giọng đọc mượt mà và chân thực hơn, nâng cao trải nghiệm người dùng trong các lĩnh vực như trợ lý ảo, chăm sóc khách hàng và sách nói.
- Hỗ trợ đa ngôn ngữ toàn diện: Các hệ thống TTS tương lai sẽ xử lý nhiều ngôn ngữ cùng lúc và chuyển đổi mượt mà giữa các ngôn ngữ trong cùng một văn bản. Công nghệ này cũng sẽ tùy chỉnh giọng đọc theo đặc điểm vùng miền, tạo ra trải nghiệm gần gũi và dễ tiếp nhận hơn cho người dùng toàn cầu, đồng thời giúp phá vỡ rào cản ngôn ngữ trong giao tiếp quốc tế.
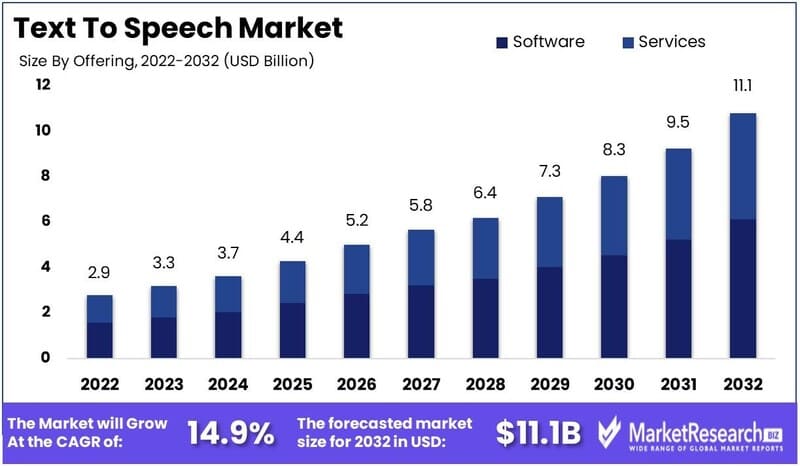
Tóm lại, công nghệ Text to Speech đã trở thành công nghệ thiết yếu trong nhiều lĩnh vực từ giáo dục, y tế, truyền thông đến điều hướng, trợ lý ảo và nhà thông minh. Mặc dù vẫn tồn tại một số hạn chế, TTS đang không ngừng được cải tiến. Sự phát triển mạnh mẽ của thị trường TTS toàn cầu phản ánh vai trò ngày càng quan trọng của công nghệ này trong việc cải thiện giao tiếp giữa con người với máy móc và xây dựng một thế giới kỹ thuật số dễ tiếp cận hơn cho tất cả mọi người.
>>> XEM THÊM: