Foundation Models là các mô hình Trí Tuệ Nhân Tạo (AI) được huấn luyện trên các tập dữ liệu khổng lồ, có khả năng thực hiện nhiều loại tác vụ tổng quát, đóng vai trò nền tảng để phát triển các ứng dụng AI chuyên biệt. Thuật ngữ này được các nhà nghiên cứu tại Trung tâm Nghiên cứu về Foundation Models và Viện Trí Tuệ Nhân Tạo hướng đến con người của Đại học Stanford đặt ra trong một bài báo năm 2021.
Trong bài viết này, FPT.AI sẽ giới thiệu chi tiết về bản chất và quá trình xây dựng Foundation Models, phương pháp điều chỉnh, các ứng dụng nổi bật cũng như những lợi ích và thách thức mà chúng mang lại. Đọc ngay để nắm bắt xu hướng phát triển của AI hiện đại và tiềm năng ứng dụng của Foundation Models trong tương lai.
Foundation Models là gì?
Foundation Models là các mô hình Trí Tuệ Nhân Tạo (AI) được huấn luyện trên các tập dữ liệu khổng lồ, có khả năng thực hiện nhiều loại tác vụ tổng quát, là nền tảng để phát triển các ứng dụng AI chuyên biệt. Thuật ngữ “Foundation Models” được các nhà nghiên cứu tại Trung tâm Nghiên cứu về Foundation Models và Viện Trí Tuệ Nhân Tạo hướng đến con người của Đại học Stanford đặt ra trong một bài báo năm 2021.
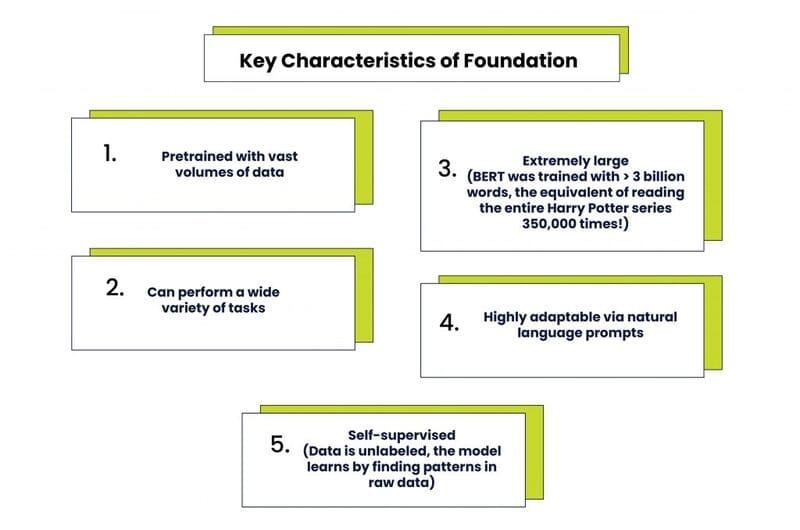
Về bản chất, Foundation Models là các Neural Network (mạng nơ-ron) được huấn luyện với lượng dữ liệu thô rất lớn, thường là dữ liệu không được gán nhãn thông qua phương pháp Unsupervised Learning (học không giám sát). Cách tiếp cận này mang lại lợi ích lớn về thời gian và chi phí, vì không cần phải mô tả thủ công từng mục trong các bộ sưu tập dữ liệu lớn.
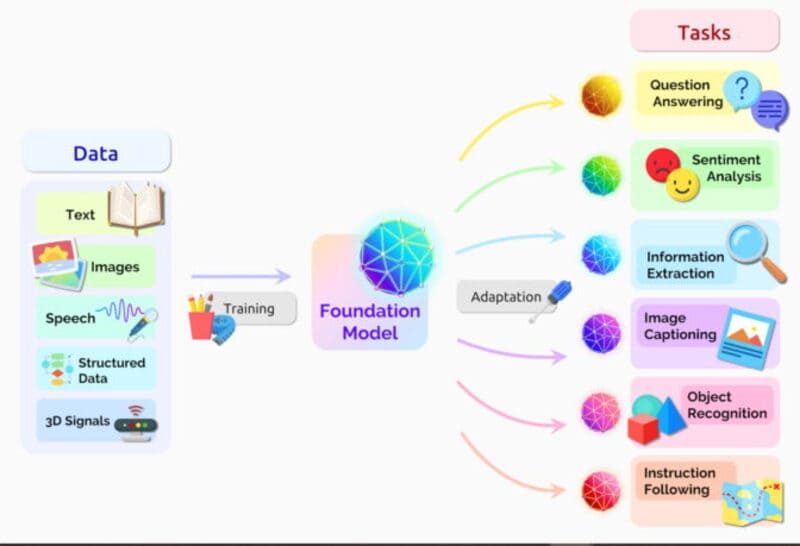
So với các mô hình Machine Learning truyền thống vốn chỉ được huấn luyện trên các tập dữ liệu nhỏ để thực hiện các tác vụ cụ thể như phát hiện đối tượng hoặc dự báo xu hướng, Foundation Models sử dụng kỹ thuật Transfer Learning (học chuyển giao) để áp dụng kiến thức từ tác vụ này sang tác vụ khác. Chỉ cần một chút Fine-tuning (tinh chỉnh), chúng có thể xử lý nhiều công việc khác nhau: từ dịch văn bản, phân tích hình ảnh y tế đến thực hiện các hành vi dựa trên agent.
Các nhà nghiên cứu Stanford đã mô tả Foundation Models như một “sự thay đổi mô hình” trong lĩnh vực AI. Họ giải thích lý do đằng sau cách đặt tên: “Một Foundation Model tự nó không hoàn chỉnh nhưng đóng vai trò là nền tảng chung để xây dựng nhiều mô hình dành riêng cho các tác vụ cụ thể thông qua sự thích ứng. Chúng tôi cũng chọn thuật ngữ ‘foundation’ để gợi lên ý nghĩa của sự ổn định kiến trúc, an toàn và bảo mật: Những nền tảng được xây dựng kém chắc chắn là công thức cho thảm họa, và những nền tảng được thực hiện tốt là nền móng đáng tin cậy cho các ứng dụng trong tương lai.”
Foundation Models phù hợp với nhiều lĩnh vực rộng lớn, bao gồm Computer Vision, Xử Lý Ngôn Ngữ Tự Nhiên (Natural – Language Processing – NLP) và nhận diện giọng nói. Percy Liang, giám đốc Trung tâm nghiên cứu mô hình nền tảng HAI của Stanford, đã nhận định: “Tôi nghĩ rằng chúng ta đã khám phá một phần rất nhỏ khả năng của Foundation Models hiện tại, chứ chưa nói đến các mô hình trong tương lai.”
Quá trình xây dựng một Foundation Model
Quá trình xây dựng một Foundation Model tương tự như quá trình phát triển một mô hình Machine Learning thông thường:
Thu thập dữ liệu
Bước đầu tiên là tập hợp một kho dữ liệu khổng lồ từ nhiều nguồn đa dạng. Dữ liệu này thường không có nhãn và không có cấu trúc cố định. Điều này cho phép Foundation Models:
- Nhận diện các mẫu dữ liệu tự nhiên
- Hiểu mối quan hệ giữa các thành phần
- Phân biệt các ngữ cảnh khác nhau
- Khái quát hóa kiến thức để áp dụng vào tình huống mới
Lựa chọn loại dữ liệu (Modality)
Modality đề cập đến loại dữ liệu mà một mô hình có thể xử lý, bao gồm âm thanh, hình ảnh, mã phần mềm, văn bản và video. Foundation Models được chia thành hai loại chính:
- Mô hình đơn phương thức (Unimodal): Xử lý một loại dữ liệu duy nhất, như đầu vào văn bản và tạo ra đầu ra văn bản.
- Mô hình đa phương thức (Multimodal): Kết hợp nhiều loại dữ liệu, như nhận văn bản và tạo hình ảnh, hoặc chuyển đổi âm thanh thành văn bản.
Xác định kiến trúc mô hình
Nhiều Foundation Models sử dụng Deep Learning, với Neural Network nhiều lớp để mô phỏng quá trình ra quyết định của bộ não con người. Hai kiến trúc phổ biến nhất của Foundation Models là: Transformer Models và Diffusion Models. Trong đó:
Transformer Models là kiến trúc phổ biến nhất cho các mô hình NLP như GPT (Generative Pre-trained Transformer). Đặc trưng cơ bản của Transformer Models bao gồm:
- Encoders: Chuyển đổi dữ liệu đầu vào thành các biểu diễn số (embeddings), nắm bắt ngữ nghĩa và vị trí của các token trong chuỗi đầu vào.
- Cơ chế Self-attention: Cho phép mô hình tập trung vào các phần quan trọng nhất trong dữ liệu đầu vào, bất kể vị trí.
- Decoders: Sử dụng self-attention và embeddings của encoders để tạo ra chuỗi đầu ra có xác suất thống kê cao nhất.
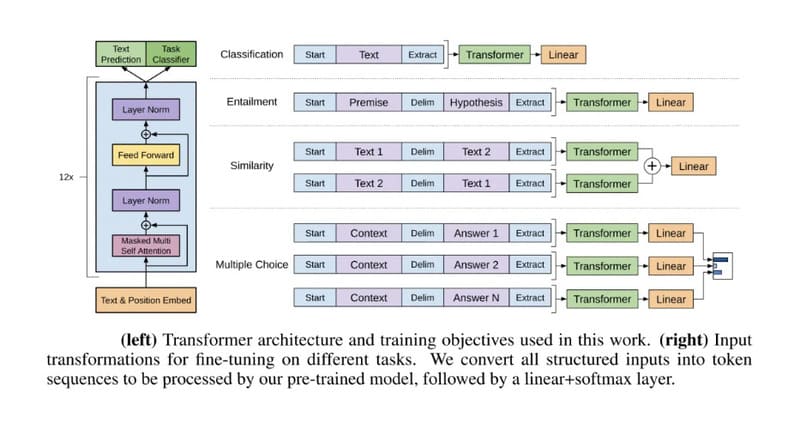
Diffusion Models là kiến trúc phổ biến trong các mô hình chuyển đổi text-to-image như Imagen của Google, DALL-E của OpenAI (bắt đầu từ DALL-E 2) và Stable Diffusion của Stability AI. Diffusion Models hoạt động bằng cách dần dần thêm nhiễu ngẫu nhiên vào dữ liệu huấn luyện, sau đó học cách đảo ngược quá trình khuếch tán đó để tái tạo dữ liệu gốc.
>>> XEM THÊM: Khám phá AI tạo sinh hình ảnh: Cơ chế và công nghệ lõi
Huấn luyện
Quá trình huấn luyện Foundation Models thường sử dụng phương pháp self-supervised learning, trong đó mô hình học các tương quan vốn có trong dữ liệu không có nhãn. Quá trình này lặp đi lặp lại nhiều lần, với trọng số được điều chỉnh liên tục để giảm thiểu lỗi dự đoán và Hyperparameters (siêu tham số) được tinh chỉnh để tìm ra các biến cấu hình tối ưu. Các phương pháp regularization cũng được áp dụng để khắc phục overfitting (khi mô hình quá khớp với dữ liệu huấn luyện) và cải thiện khả năng tổng quát hóa.
Đánh giá
Hiệu suất của một Foundation Model có thể được xác thực bằng cách sử dụng các benchmark tiêu chuẩn. Kết quả từ các đánh giá này giúp xác định những điểm cần cải tiến và tối ưu hóa mô hình.
Quá trình điều chỉnh Foundation Models
Phát triển một Foundation Model từ đầu là quá trình đòi hỏi nguồn lực tính toán lớn, tốn kém và mất nhiều thời gian. Chính vì vậy, nhiều doanh nghiệp lựa chọn điều chỉnh các Foundation Models đã có sẵn để đáp ứng nhu cầu cụ thể của họ. Các mô hình này có thể được truy cập thông qua Application Programming Interface (API) hoặc bằng cách sử dụng bản sao cục bộ của mô hình.
Dưới đây là hai phương pháp điều chỉnh phổ biến:
Fine-tuning
Trong quá trình fine-tuning, một Foundation Model đã được huấn luyện trước sẽ điều chỉnh kiến thức chung của nó cho một tác vụ cụ thể. Quá trình này bao gồm việc sử dụng supervised learning trên một tập dữ liệu nhỏ hơn, dành riêng cho miền hoặc tác vụ cụ thể, bao gồm các ví dụ có nhãn. Các tham số của mô hình được cập nhật để tối ưu hóa hiệu suất của nó trên tác vụ.
Mặc dù Fine-tuning mang lại hiệu quả cao, phương pháp này có một số hạn chế:
- Thay đổi tham số của mô hình có thể ảnh hưởng đến hiệu suất của nó trên các tác vụ khác
- Việc tạo một tập dữ liệu có nhãn thường là quy trình tốn thời gian và công sức.
Prompting
Prompting à phương pháp điều chỉnh không can thiệp vào cấu trúc tham số của Foundation Model. Thay vào đó, phương pháp này dựa vào việc cung cấp chỉ dẫn (Prompt) cho mô hình để hướng dẫn nó thực hiện tác vụ cụ thể.
Prompt có thể ở dạng hướng dẫn liên quan đến tác vụ hoặc các ví dụ minh họa, giúp mô hình hiểu ngữ cảnh và tạo ra đầu ra khả thi thông qua khả năng In-context Learning (học trong ngữ cảnh)
Mặc dù Prompting không yêu cầu huấn luyện mô hình hoặc thay đổi tham số, có thể mất nhiều lần thử để có được prompt phù hợp và hiệu quả của phương pháp phụ thuộc vào khả năng hiểu ngữ cảnh và đưa ra dự đoán phù hợp của mô hình.
Các ứng dụng nổi bật của Foundation Models
Với khả năng thích ứng và bản chất đa dụng, Foundation Models chúng có thể được triển khai cho nhiều ứng dụng thực tế:
Computer Vision
Foundation Models có thể được sử dụng trong các tác vụ Computer Vision như tạo và phân loại hình ảnh, phát hiện, nhận dạng và mô tả đối tượng. DALL-E, Imagen và Stable Diffusion là những ví dụ về Foundation Models chuyển đổi text-to-image.
Xử lý ngôn ngữ tự nhiên (Natural language processing)
LLMs là một loại Foundation Models xuất sắc trong Xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) và hiểu ngôn ngữ tự nhiên (Natural Language Understanding – NLU) với các khả năng nổi bật bao gồm trả lời câu hỏi, tóm tắt văn bản, phiên âm, dịch thuật, tạo phụ đề video,….
Dưới đây là một số Foundation Models phổ biến trong lĩnh vực NLP:
- BERT (Bidirectional Encoder Representations from Transformers): Một trong những Foundation Models đầu tiên được Google phát hành vào năm 2018. BERT là hệ thống AI mã nguồn mở được huấn luyện thuần túy trên tập dữ liệu văn bản, nổi bật với kiến trúc mã hóa hai chiều giúp hiểu ngôn ngữ trong ngữ cảnh.
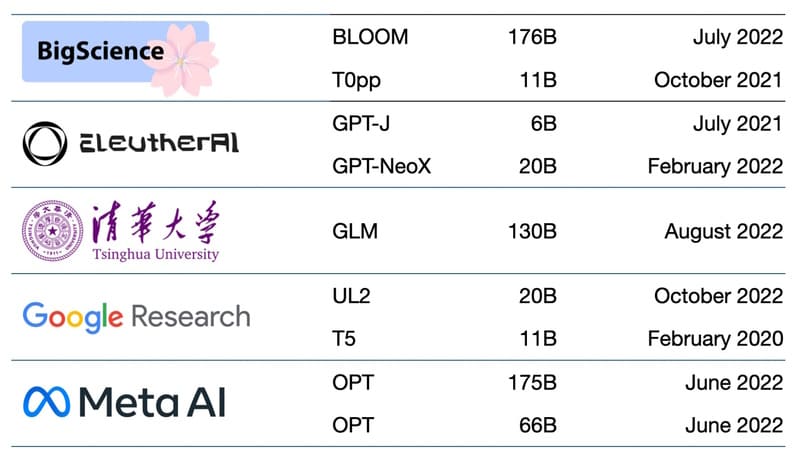
- BLOOM: Một multimodal language model truy cập mở được huấn luyện trên 46 ngôn ngữ. Đây là kết quả của nỗ lực hợp tác giữa Hugging Face và BigScience – một cộng đồng các nhà nghiên cứu AI, nhằm tạo ra mô hình ngôn ngữ có tính đa dạng và bao trùm.
- Claude: Foundation Models của Anthropic với khả năng lập luận nâng cao và xử lý đa ngôn ngữ.
- GPT (Generative Pre-trained Transformer): Foundation Model của OpenAI, là nền tảng của ChatGPT. GPT-3.5 cung cấp năng lượng cho phiên bản miễn phí của ChatGPT, trong khi GPT-4 đứng sau phiên bản cao cấp. Dòng GPT-4 cũng là mô hình AI tạo sinh hỗ trợ trợ lý AI Microsoft’s Copilot.
- Granite: Dòng flagship của IBM® về Foundation Models LLM dựa trên kiến trúc Decoder – Only Transformer. Mô hình Granite 13b chat được tối ưu hóa cho các trường hợp sử dụng hội thoại và hoạt động tốt với các ứng dụng đại lý ảo và trò chuyện. Granite còn cung cấp mô hình đa ngôn ngữ được huấn luyện để hiểu và tạo văn bản trong năm ngôn ngữ: tiếng Anh, Đức, Tây Ban Nha, Pháp và Bồ Đào Nha.
- PaLM 2: Mô hình ngôn ngữ thế hệ tiếp theo của Google với khả năng đa ngôn ngữ và lập luận nâng cao.
Y tế
Trong y tế, Foundation Models có thể hỗ trợ một loạt các tác vụ y khoa. Từ việc tạo tóm tắt về lần thăm khám của bệnh nhân và tìm kiếm tài liệu y tế đến việc trả lời câu hỏi của bệnh nhân, kết nối bệnh nhân với các thử nghiệm lâm sàng và tạo điều kiện cho việc khám phá thuốc. Ví dụ, mô hình ngôn ngữ Med-PaLM 2 có thể trả lời các câu hỏi y tế, và Google đang thiết kế phiên bản multimodal có thể tổng hợp thông tin từ hình ảnh y tế như X-quang, MRI và CT scan.
Robotics
Trong lĩnh vực robotics, Foundation Models có thể giúp robot nhanh chóng thích nghi với môi trường mới và khái quát hóa qua nhiều tác vụ, kịch bản và hình thái máy móc khác nhau. Ví dụ, mô hình ngôn ngữ đa phương thức nhập thể PaLM-E chuyển kiến thức từ lĩnh vực ngôn ngữ và thị giác của PaLM sang hệ thống robotics và được huấn luyện trên dữ liệu cảm biến robot.
Tạo mã phần mềm
Foundation Models có thể hỗ trợ việc hoàn thành, gỡ lỗi, giải thích và tạo code trong các ngôn ngữ lập trình khác nhau. Các Foundation Models text-to-code này bao gồm Claude của Anthropic, Codey và PaLM 2 của Google, và gia đình mô hình Granite Code của IBM được huấn luyện trên 116 ngôn ngữ lập trình.
Lợi ích của Foundation Models
Foundation Models thúc đẩy tự động hóa và đổi mới cho doanh nghiệp, với các lợi ích cốt lõi gồm:
- Thời gian tạo giá trị và mở rộng nhanh hơn: Việc áp dụng các mô hình hiện có loại bỏ các giai đoạn phát triển và huấn luyện trước, cho phép các công ty nhanh chóng tùy chỉnh và triển khai các mô hình đã được fine-tuned.
- Truy cập dữ liệu phong phú: Foundation Models đã được huấn luyện trên các tập dữ liệu khổng lồ, đa dạng, các tổ chức không cần phải biên soạn lượng lớn dữ liệu để pretrain mô hình – một nhiệm vụ mà nhiều doanh nghiệp có thể không có đủ phương tiện hoặc nguồn lực để thực hiện.
- Độ chính xác và hiệu suất cơ bản cao: Foundation Models đã trải qua quá trình đánh giá kỹ lưỡng về độ chính xác và hiệu suất, cung cấp một điểm khởi đầu chất lượng cao cho các ứng dụng AI.
- Giảm chi phí: Các doanh nghiệp sẽ không cần phải chi tiêu cho các nguồn lực cần thiết để tạo ra một Foundation Model từ đầu.
>>> XEM THÊM: Retrieval-Augmented Generation nâng cao chất lượng phản hồi cho LLMs như thế nào?
Thách thức của Foundation Models
Giống như mọi công nghệ mới, Foundation Models cũng đối mặt với nhiều thách thức đáng kể. Các doanh nghiệp đang xem xét Foundation Models làm nền tảng cho quy trình làm việc nội bộ hoặc ứng dụng AI thương mại cần lưu ý những rủi ro sau:
- Bias (Thiên kiến): Foundation Models có thể tiếp nhận và khuếch đại các thiên kiến ngầm có trong dữ liệu huấn luyện. Những thiên kiến này sau đó có thể lan truyền xuống các mô hình đã được Fine-tuned, dẫn đến các kết quả thiên lệch hoặc phân biệt đối xử. Điều này đặc biệt nguy hiểm khi các mô hình được sử dụng trong các quyết định quan trọng liên quan đến con người.
- Chi phí tính toán cao: Dù chỉ sử dụng các Foundation Models hiện có, vẫn cần lượng bộ nhớ đáng kể và phần cứng tiên tiến như Graphics Processing Units (GPUs) để Fine-tuning, triển khai và duy trì. Điều này tạo ra rào cản đáng kể về mặt tài chính cho các tổ chức nhỏ hơn muốn áp dụng công nghệ này.
- Quyền riêng tư dữ liệu và sở hữu trí tuệ: Nhiều Foundation Models được huấn luyện trên dữ liệu thu thập mà không có sự đồng ý hoặc hiểu biết của chủ sở hữu. Khi sử dụng các mô hình này, tổ chức cần thận trọng để tránh vi phạm bản quyền hoặc tiết lộ thông tin nhận dạng cá nhân hay thông tin kinh doanh độc quyền.
- Chi phí môi trường: Quá trình huấn luyện và vận hành Foundation Models quy mô lớn tiêu tốn rất nhiều năng lượng, góp phần vào việc tăng phát thải carbon và tiêu thụ nước. Tác động môi trường này đang ngày càng trở thành mối quan tâm lớn trong bối cảnh biến đổi khí hậu toàn cầu.
- Hallucination (Ảo giác): Foundation Models có thể tạo ra nội dung sai lệch về mặt xã hội và chính trị trong thực tế nhưng nghe có vẻ đúng và thuyết phục, đặc biệt là các mô hình tạo hình ảnh hoặc video. Việc xác minh kết quả từ các mô hình này là rất quan trọng để đảm bảo độ chính xác, đặc biệt trong các ứng dụng yêu cầu thông tin đáng tin cậy.
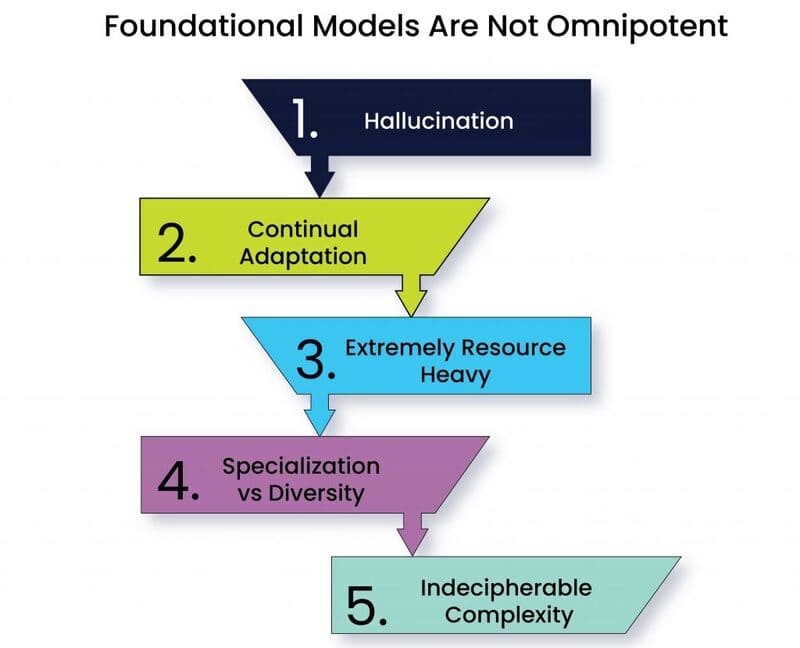
Cộng đồng nghiên cứu AI nhận thức rõ về những thách thức này. Bài báo của Stanford về Foundation Models đã nhấn mạnh: “Với việc các hệ thống AI trong tương lai có khả năng sẽ phụ thuộc nhiều vào Foundation Models, điều cấp thiết là chúng ta, với tư cách là một cộng đồng, cùng nhau phát triển các nguyên tắc chặt chẽ hơn cho Foundation Models và hướng dẫn cho việc phát triển và triển khai có trách nhiệm.”
Hiện nay, các biện pháp bảo vệ đang được phát triển bao gồm lọc prompt và đầu ra, hiệu chỉnh lại mô hình ngay lập tức và làm sạch các tập dữ liệu khổng lồ. Bryan Catanzaro, Phó Chủ tịch nghiên cứu Deep Learning ứng dụng tại NVIDIA, khẳng định: “Đây là những vấn đề mà chúng tôi đang làm việc với tư cách là một cộng đồng nghiên cứu. Để các mô hình này thực sự được triển khai rộng rãi, chúng ta phải đầu tư rất nhiều vào vấn đề an toàn.”
>>> XEM THÊM: Data Leakage là gì? Cách ngăn chặn rò rỉ dữ liệu khi triển khai Generative AI cho doanh nghiệp
Sự phát triển của Foundation Models theo dòng thời gian
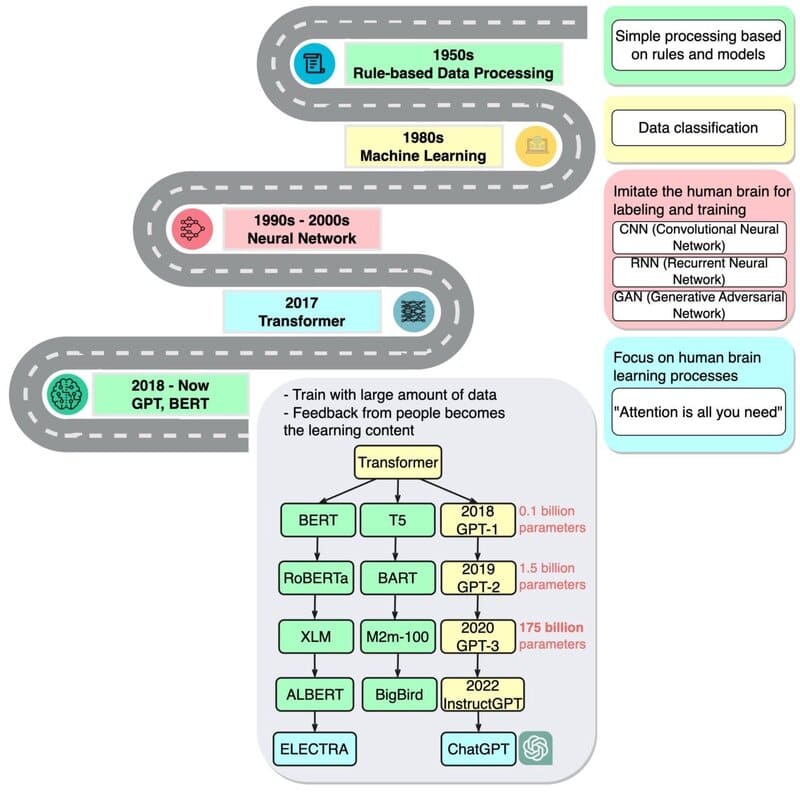
Khởi đầu với Transformers (2017)
Foundation Models bắt đầu với công trình nghiên cứu mang tính đột phá về Transformers vào năm 2017. Ashish Vaswani, một cựu nhà khoa học nghiên cứu cấp cao tại Google Brain, đã dẫn đầu nghiên cứu này và nhận xét: “Chúng ta đang trong thời đại mà những phương pháp đơn giản như neural networks đang mang lại sự bùng nổ về khả năng mới.”
Sự xuất hiện của BERT (2018)
Công trình của Vaswani đã truyền cảm hứng cho các nhà nghiên cứu tạo ra BERT và nhiều mô hình ngôn ngữ lớn khác, biến năm 2018 thành “thời điểm bước ngoặt” cho xử lý ngôn ngữ tự nhiên. Google đã phát hành BERT dưới dạng phần mềm mã nguồn mở, tạo ra một gia đình các mô hình kế tiếp và khởi động cuộc đua xây dựng các LLMs ngày càng lớn và mạnh mẽ hơn. Sau đó, Google đã ứng dụng công nghệ này vào công cụ tìm kiếm, cho phép người dùng đặt câu hỏi bằng câu đơn giản.
Bước tiến với GPT-3 (2020)
Năm 2020, các nhà nghiên cứu tại OpenAI công bố một Transformer quan trọng khác – GPT-3. Trong vòng vài tuần, người dùng đã sử dụng nó để sáng tạo thơ, chương trình, bài hát, trang web và nhiều nội dung khác. Các nhà nghiên cứu ghi nhận: “Các mô hình ngôn ngữ có nhiều ứng dụng có lợi cho xã hội.”
GPT-3 cũng cho thấy quy mô và nhu cầu tính toán khổng lồ của các mô hình này. Nó được huấn luyện trên tập dữ liệu gần một nghìn tỷ từ, với 175 tỷ tham số – một thước đo quan trọng về sức mạnh và độ phức tạp của neural networks.
Percy Liang, Giám đốc Trung tâm Nghiên cứu về Foundation Models tại Stanford, nhớ lại: “Tôi thực sự kinh ngạc về những điều mà nó có thể làm.”
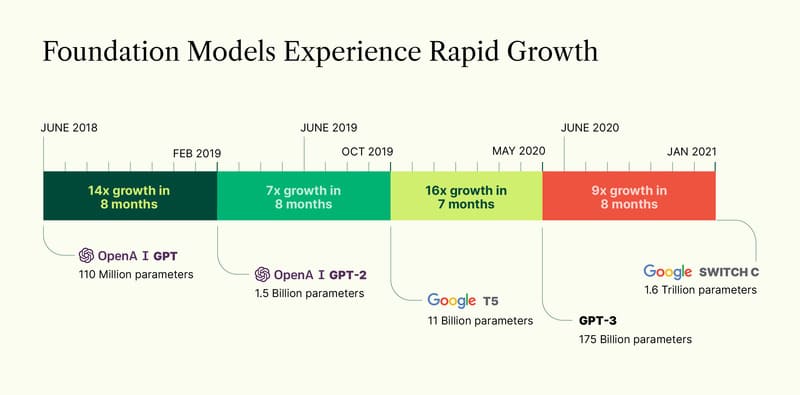
Sự ra đời của khái niệm Foundation Models (2021)
Từ năm 2021, các nhà nghiên cứu đã xác định một loạt ứng dụng cho mô hình nền tảng. Họ xác định rằng các Transformer models, large language models (LLMs), vision language models (VLMs) và các neural networks khác đang được xây dựng thuộc về một danh mục mới quan trọng mà họ gọi là Foundation Models.
Trong bài thuyết trình tại hội thảo đầu tiên về Foundation Models, Percy Liang đã đưa ra hai thuật ngữ quan trọng:
- Emergence (sự nổi lên): đề cập đến các tính năng AI vẫn đang được khám phá, như nhiều kỹ năng mới trong Foundation Models.
- Homogenization (đồng nhất hóa): xu hướng kết hợp các thuật toán AI và kiến trúc mô hình đã giúp hình thành nên Foundation Models.
Sự xuất hiện của Generative AI (2022)
Một năm sau khi nhóm định nghĩa Foundation Models, các chuyên gia công nghệ đã đặt ra một thuật ngữ liên quan – Generative AI. Đây là thuật ngữ chung cho transformers, large language models, diffusion models và các neural networks khác thu hút trí tưởng tượng của mọi người vì chúng có thể tạo ra văn bản, hình ảnh, âm nhạc, phần mềm, video và nhiều thứ khác.
Các giám đốc từ công ty đầu tư mạo hiểm Sequoia Capital đánh giá Generative AI có tiềm năng mang lại giá trị kinh tế hàng nghìn tỷ đô la.
Kỷ nguyên ChatGPT và Diffusion Models (2022-2023)
ChatGPT – được huấn luyện trên 10.000 GPU của NVIDIA – thậm chí còn thu hút hơn GPT-3, với hơn 100 triệu người dùng chỉ trong hai tháng. Sự ra mắt của nó đã được gọi là “khoảnh khắc iPhone” cho AI vì nó giúp rất nhiều người thấy cách họ có thể sử dụng công nghệ này.
Cùng thời điểm ChatGPT ra mắt, một lớp neural network khác, gọi là diffusion models, cũng tạo tiếng vang lớn. Khả năng biến mô tả văn bản thành hình ảnh nghệ thuật đã thu hút người dùng phổ thông tạo ra những hình ảnh ấn tượng lan truyền trên mạng xã hội.
Bài báo đầu tiên mô tả diffusion model xuất hiện không gây nhiều chú ý vào năm 2015. Nhưng giống như transformers, kỹ thuật mới này sớm trở nên phổ biến. David Holz, CEO của Midjourney, tiết lộ dịch vụ text-to-image dựa trên diffusion của ông có hơn 4,4 triệu người dùng, đòi hỏi hơn 10.000 GPU của NVIDIA chủ yếu cho AI inference.
>>> XEM THÊM: 10 Cách viết prompt ChatGPT hiệu quả cho người mới sử dụng
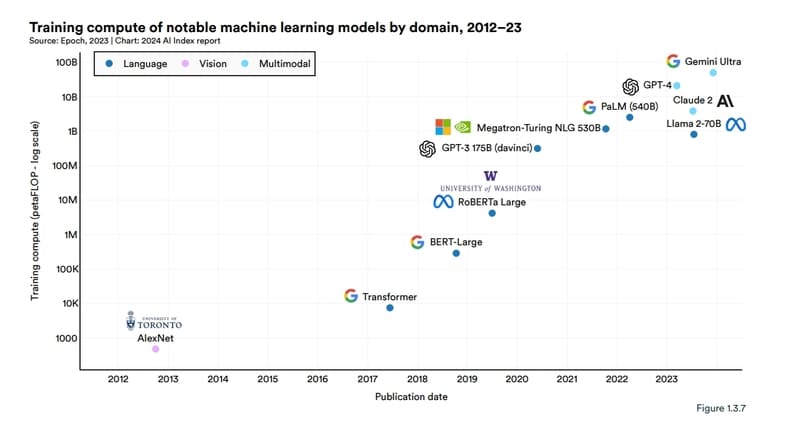
Sự bùng nổ của Foundation Models (2023)
Theo báo cáo AI Index 2024 từ Viện Trí tuệ nhân tạo hướng tới con người của Stanford, 149 Foundation Models đã được công bố trong năm 2023, nhiều hơn gấp đôi số lượng được phát hành vào năm 2022.
Hiện nay có hàng trăm Foundation Models. Một nghiên cứu đã phân loại hơn 50 Transformer models chính. Nhóm Stanford đã đánh giá 30 Foundation Models, lưu ý rằng lĩnh vực này đang phát triển nhanh đến mức họ không xem xét một số mô hình mới và nổi bật.
Startup NLP Cloud, thành viên của chương trình NVIDIA Inception, cho biết họ sử dụng khoảng 25 large language models trong dịch vụ thương mại phục vụ các hãng hàng không, hiệu thuốc và người dùng khác. Các chuyên gia dự đoán tỷ lệ ngày càng tăng các mô hình sẽ được cung cấp dưới dạng mã nguồn mở trên các trang web như model hub của Hugging Face.
Xu hướng Multimodal và Physical AI (2023-2024)
Foundation Models đã mở rộng để xử lý và tạo ra nhiều loại dữ liệu, hay modalities, như văn bản, hình ảnh, âm thanh và video. VLMs là một loại multimodal models có thể hiểu đầu vào video, hình ảnh và văn bản trong khi tạo ra đầu ra văn bản hoặc hình ảnh.
Cosmos Nemotron 34B, được huấn luyện trên 355.000 video và 2,8 triệu hình ảnh, là một VLM hàng đầu cho phép khả năng truy vấn và tóm tắt hình ảnh và video từ thế giới vật lý hoặc ảo.
Biên giới tiếp theo của trí tuệ nhân tạo là physical AI, cho phép các máy tự động như robot và xe tự lái tương tác với thế giới thực. World foundation models, có thể mô phỏng môi trường thế giới thực và dự đoán kết quả chính xác dựa trên đầu vào văn bản, hình ảnh hoặc video, cung cấp một giải pháp đầy hứa hẹn.
Hiện tại và tương lai
Năm 2024, Google đã phát hành Gemini Ultra, một Foundation Model tiên tiến đòi hỏi 50 tỷ petaflops.
Các nhóm phát triển physical AI đang sử dụng NVIDIA Cosmos world foundation models, một bộ các autoregressive và diffusion models được huấn luyện trước trên 20 triệu giờ dữ liệu lái xe và robotics, với nền tảng NVIDIA Omniverse. Cosmos world foundation models, được trao giải thưởng AI tốt nhất và giải thưởng tổng thể tốt nhất tại CES 2025, là các mô hình mở có thể được tùy chỉnh cho các trường hợp sử dụng downstream.
NVIDIA NeMo framework nhằm mục đích cho phép bất kỳ doanh nghiệp nào tạo ra transformer của riêng mình với hàng tỷ hoặc nghìn tỷ tham số để cung cấp năng lượng cho chatbot tùy chỉnh, trợ lý cá nhân và các ứng dụng AI khác. Nó đã tạo ra mô hình Megatron-Turing Natural Language Generation (MT-NLG) với 530 tỷ tham số.
Foundation Models kết nối với nền tảng 3D như NVIDIA Omniverse sẽ là chìa khóa để đơn giản hóa việc phát triển metaverse. Nhà máy và kho hàng đã áp dụng Foundation Models bên trong digital twins, các mô phỏng thực tế giúp tìm ra cách làm việc hiệu quả hơn.
Tóm lại, Foundation Models đã tạo ra một cuộc cách mạng trong lĩnh vực AI, giúp doanh nghiệp tạo giá trị nhanh hơn, truy cập dữ liệu phong phú và giảm chi phí. Trong tương lai, Foundation Models có khả năng tiếp tục phát triển theo hướng đa phương thức (multimodal) và Physical AI, cho phép tương tác sâu hơn với thế giới thực.
Cùng với việc hoàn thiện các nguyên tắc và biện pháp bảo vệ, Foundation Models hứa hẹn sẽ mở ra một kỷ nguyên mới của AI có trách nhiệm, góp phần thúc đẩy sự phát triển và đổi mới trong nhiều lĩnh vực của xã hội.
>>> XEM THÊM: