Xử lý ngôn ngữ tự nhiên (Natural Language Processing) và thị giác máy tính (Computer Vision) đã có những bước tiến vượt bậc trong những năm gần đây, cho phép máy móc hiểu được cả văn bản và hình ảnh. Sự kết hợp giữa hai công nghệ này đã dẫn đến sự ra đời của mô hình ngôn ngữ thị giác (Vision Language Models – VLMs), giúp AI có khả năng xử lý và hiểu đồng thời dữ liệu hình ảnh và văn bản. Vậy VLM là gì? Hãy cùng FPT.AI tham khảo ngay trong bài viết dưới đây.
VLM là gì?
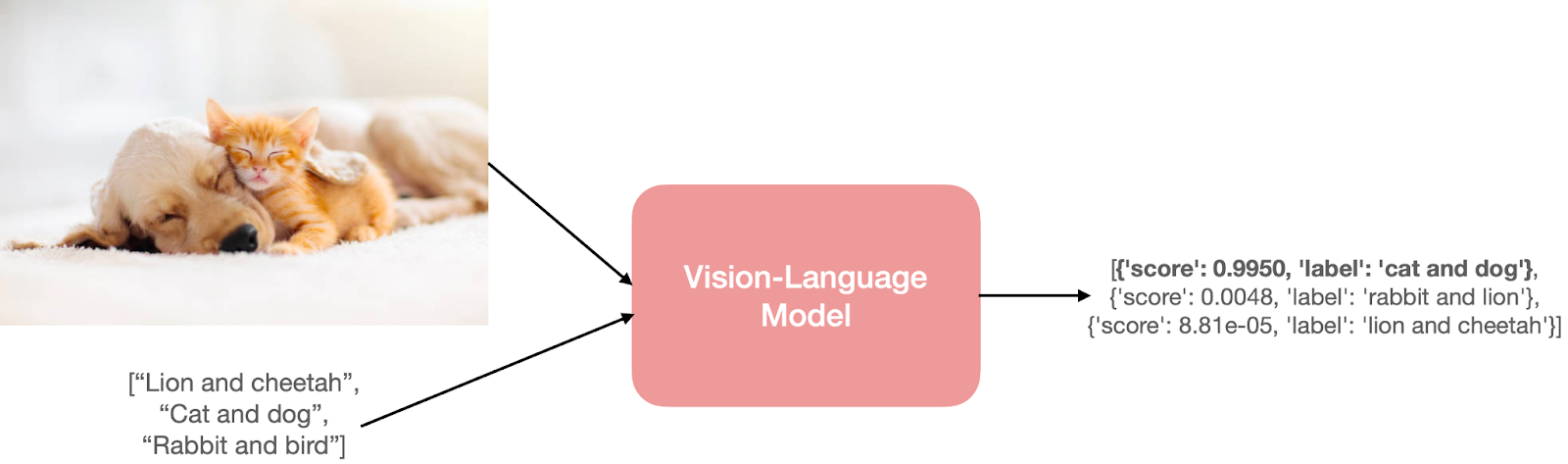
VLM (Vision Language Models) là hệ thống AI kết hợp giữa mô hình ngôn ngữ lớn (LLM) và bộ mã hóa hình ảnh (vision encoder). Nhờ đó, mô hình không chỉ xử lý văn bản mà còn có khả năng “nhìn thấu” hình ảnh, video và đưa ra phản hồi dựa trên cả hai dạng dữ liệu này.
Thay vì chỉ nhận lệnh văn bản như các LLM truyền thống, VLMs cho phép người dùng đưa dữ liệu đầu vào là hình ảnh, video xen kẽ với câu hỏi hoặc yêu cầu. Mô hình sẽ phân tích nội dung thị giác, hiểu ngữ cảnh và phản hồi bằng văn bản một cách tự nhiên.
Đây cũng chính là nền tảng quan trọng thúc đẩy sự phát triển của các hệ thống AI đa phương thức (multimodal AI), mở ra nhiều ứng dụng đột phá trong chăm sóc khách hàng, giáo dục, y tế, sản xuất và tự động hóa.
Tầm quan trọng của Vision Language Models
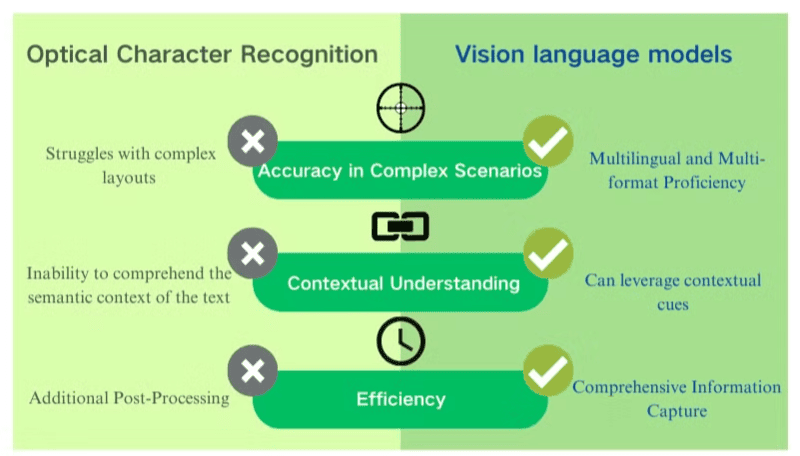
Vision Language Models (VLMs) đánh dấu một bước tiến quan trọng của trí tuệ nhân tạo nhờ khả năng vượt qua những hạn chế cố hữu của Computer Vision truyền thống.
Các mô hình thị giác trước đây, điển hình là Convolutional Neural Network (CNN), thường chỉ giải quyết được những nhiệm vụ cố định như phân loại hình ảnh hay nhận diện ký tự quang học (OCR). Chúng thiếu khả năng mở rộng: khi thêm lớp mới hoặc thay đổi nhiệm vụ, nhà phát triển buộc phải thu thập dữ liệu, gán nhãn và huấn luyện lại toàn bộ mô hình, một quá trình tốn kém thời gian, chi phí và tài nguyên. Quan trọng hơn, chúng hoàn toàn không thể hiểu ngôn ngữ tự nhiên.
Ví dụ:
- Một mô hình phân loại xác định liệu một hình ảnh có chứa mèo hay chó
- Một mô hình nhận dạng ký tự quang học đọc văn bản trong hình ảnh mà không hiểu được định dạng hay bất kỳ y
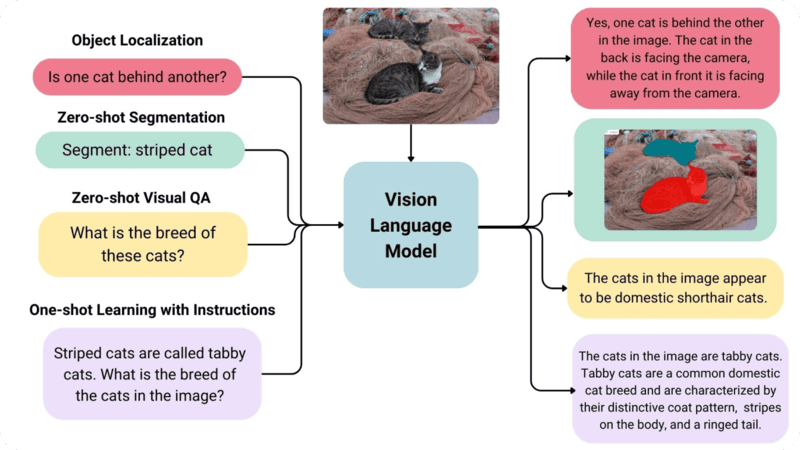
Sự ra đời của VLMs đã thay đổi hoàn toàn bức tranh này. Bằng cách kết hợp foundation models (như CLIP) với mô hình ngôn ngữ lớn (LLMs), VLMs sở hữu đồng thời khả năng xử lý thị giác và ngôn ngữ. Nhờ đó, chúng đạt hiệu suất zero-shot ấn tượng trong nhiều nhiệm vụ thị giác như:
- Trả lời câu hỏi dựa trên hình ảnh/video (Visual Q&A)
- Nhận diện và phân tích nội dung trong ảnh hoặc video dài
- Nhận diện ký tự quang học (OCR)
- Đọc hiểu tài liệu viết tay hoặc in ấn
- Tóm tắt, giải thích hoặc so sánh nhiều ảnh cùng lúc
Điểm đặc biệt của VLMs là không bị giới hạn bởi tập lớp cố định. Chỉ với một prompt văn bản, người dùng có thể linh hoạt thay đổi nhiệm vụ: từ phân loại hình ảnh, giải thích nội dung, đến phân tích video phức tạp. Điều này đưa VLMs tiến gần hơn đến cách con người nhìn – hiểu – đối thoại về thế giới trực quan.
Chính nhờ khả năng này, VLMs trở thành nền tảng quan trọng cho nhiều ứng dụng AI hiện đại, từ các tác vụ thị giác cổ điển đến những giải pháp AI tạo sinh và Visual Agents thông minh có thể tự động hóa quy trình phức tạp.
3 thành phần cốt lõi của Vision Language Models
Một mô hình Vision Language Models điển hình bao gồm 3 thành phần chính:
- Bộ mã hóa thị giác (Vision Encoder): Thường là mô hình dựa trên CLIP – có khả năng ánh xạ hình ảnh và văn bản vào không gian chung.
- Bộ chuyển đổi (Projector): Lớp trung gian giúp chuyển đổi dữ liệu đầu ra từ Vision Encoder thành dạng mà LLM có thể hiểu (gọi là “image tokens”).
- Mô hình ngôn ngữ lớn – LLM (Large Language Model): Mô hình ngôn ngữ lớn (như LLaMA, GPT…) xử lý prompt đầu vào và sinh phản hồi.
Người dùng tương tác với VLM giống như với một chatbot AI, nhưng có thể chèn thêm hình ảnh vào cuộc hội thoại. VLM sẽ phân tích nội dung thị giác cùng ngữ cảnh hội thoại để đưa ra phản hồi.
Quy trình huấn luyện Vision Language Models
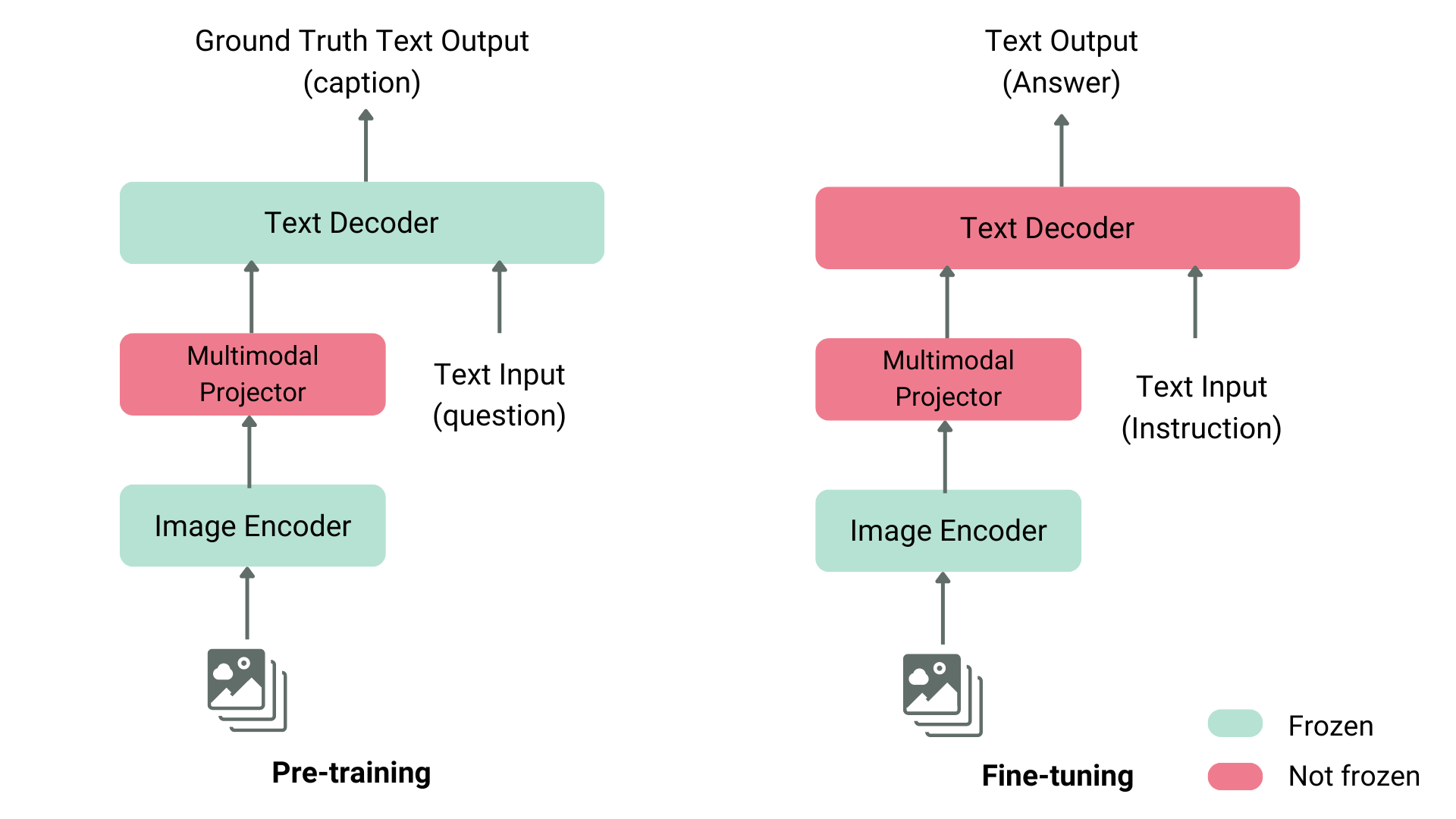
Quá trình huấn luyện VLM bao gồm 3 giai đoạn chính:
- Trước huấn luyện: Huấn luyện trên tập dữ liệu lớn gồm cặp ảnh-văn bản, giúp mô hình đồng bộ hiểu hình ảnh và văn bản.
- Tinh chỉnh có giám sát: Sử dụng các prompt và phản hồi mẫu để huấn luyện mô hình phản hồi đúng theo yêu cầu thực tế.
- Tối ưu hóa hiệu quả tham số – PEFT (Parameter Efficient Fine-Tuning): Tùy chọn cuối giúp tinh chỉnh mô hình nhanh chóng trên dữ liệu riêng biệt của doanh nghiệp.
Các ứng dụng nổi bật của VLM là gì
Nhờ khả năng kết hợp giữa xử lý ngôn ngữ tự nhiên và thị giác máy tính, Vision Language Models (VLMs) đang trở thành công cụ đa năng cho nhiều lĩnh vực. Một số ứng dụng tiêu biểu như:
- Tạo hình ảnh từ văn bản: Các mô hình như DALL-E, Imagen, Midjourney và Stable Diffusion chuyển mô tả ngôn ngữ thành hình ảnh. Doanh nghiệp có thể sử dụng công cụ này trong thiết kế sản phẩm, tạo mẫu và minh họa cho nội dung viết.
- Tạo caption và tóm tắt nội dung hình ảnh/video: VLMs không chỉ nhận diện đối tượng mà còn mô tả chi tiết nội dung hoặc tóm tắt video. Trong giáo dục, khi được cung cấp một hình ảnh của một bài toán viết tay, VLMs có thể sử dụng khả năng nhận dạng ký tự quang học và lý luận để diễn giải bài toán và tạo ra hướng dẫn từng bước về cách giải quyết. Trong lĩnh vực y tế, chúng có thể phân tích hình ảnh y tế, còn trong sản xuất, chúng giúp giải thích biểu đồ sửa chữa thiết bị trong các cơ sở sản xuất.
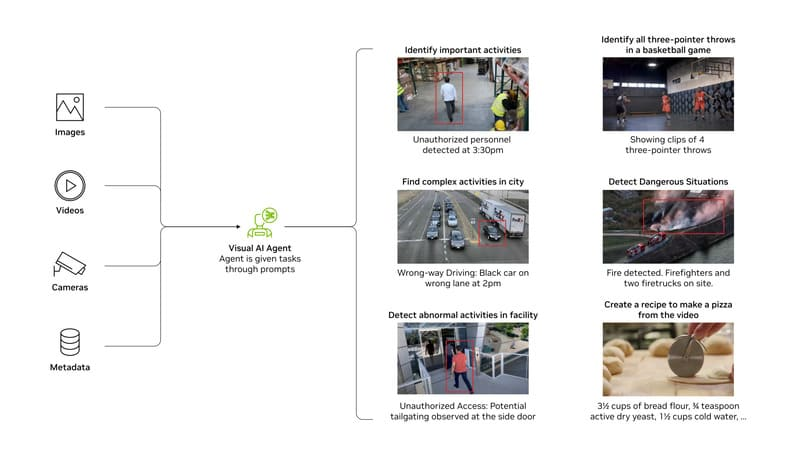
- Phân tích và trả lời câu hỏi về hình ảnh (Visual question answering – VQA): VLMs có khả năng trả lời các câu hỏi cụ thể về nội dung hình ảnh, mở rộng khả năng ứng dụng AI vào các hệ thống tương tác phức tạp. Ví dụ, trong vận tải, VLMs có thể được giao nhiệm vụ phân tích video kiểm tra đường, xác định các mối nguy hiểm như biển báo đường bị hỏng, đèn giao thông bị lỗi và ổ gà sau đó tạo báo cáo bảo trì nêu rõ vị trí và mô tả của những mối nguy hiểm đó.
- Xây dựng Video Analytics AI Agents để phát hiện sự kiện: VLMs có thể được tích hợp vào hệ thống Video Analytics AI Agents để xử lý khối lượng video lớn, phát hiện và phân tích các sự kiện cụ thể. Trong quản lý kho hàng, chúng giúp phát hiện robot hoạt động bất thường hoặc cảnh báo hết hàng khi kệ hàng trống. Trong giao thông, VLMs có thể phát hiện, phân tích và tạo báo cáo tự động về các mối nguy hiểm như cây đổ, xe hỏng hoặc va chạm.
- Phân đoạn hình ảnh và tạo bounding box: VLMs có khả năng chia hình ảnh thành các phần khác nhau dựa trên đặc điểm không gian, cung cấp mô tả cho từng phần và tạo bounding boxes để xác định vị trí đối tượng, cung cấp các nhãn hoặc highlighting màu để chỉ định các phần của hình ảnh liên quan đến truy vấn. Trong bảo trì dự đoán, công nghệ này giúp phân tích hình ảnh sàn nhà máy để phát hiện các khiếm khuyết thiết bị tiềm ẩn theo thời gian thực.
- Tìm kiếm và truy xuất hình ảnh: VLMs có thể tìm kiếm qua thư viện hình ảnh, video lớn dựa trên truy vấn ngôn ngữ tự nhiên. Điều này nâng cao trải nghiệm người dùng trên các trang thương mại điện tử, giúp khách hàng tìm kiếm sản phẩm cụ thể bằng cách mô tả sản phẩm họ muốn.
- Phân tích video dài: Kết hợp với công nghệ như graph databases, VLMs có thể hiểu và phân tích video dài, nắm bắt sự phức tạp của đối tượng và sự kiện trong video. Ứng dụng này giúp tìm ra các nút thắt cổ chai trong hoạt động kho hàng hoặc tạo bình luận tự động cho các trận đấu bóng đá, bóng rổ hoặc bóng đá.
- Hỗ trợ robot hiểu môi trường: VLMs giúp robot hiểu rõ hơn về môi trường xung quanh thông qua khả năng nhận diện đối tượng và hiểu hướng dẫn trực quan, mở rộng khả năng tương tác của robot với thế giới thực.
Các phương pháp đào tạo Vision Language Models
Quá trình đào tạo VLM thường dựa trên sự kết hợp của 4 phương pháp:
Contrastive Learning
Kỹ thuật này ánh xạ image embeddings và text embeddings vào cùng một không gian chung. Mô hình được huấn luyện trên các cặp hình ảnh, văn bản, học cách giảm khoảng cách giữa những cặp liên quan và tăng khoảng cách với các cặp không liên quan. Tiêu biểu là CLIP (Contrastive Language-Image Pretraining), được đào tạo trên 400 triệu cặp hình ảnh, chú thích từ internet, nổi bật với khả năng phân loại zero-shot có độ chính xác cao.
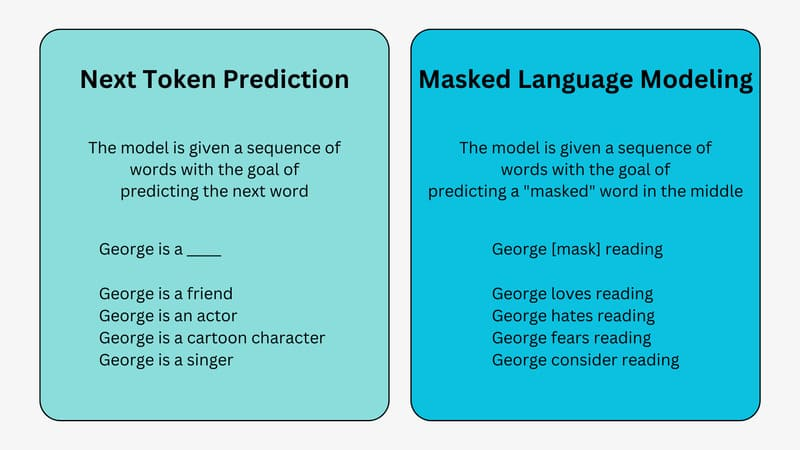
Masking
Masking giúp VLM học cách dự đoán phần bị che khuất trong dữ liệu đầu vào. Gồm hai dạng chính:
- Masked Language Modeling: Mô hình học cách điền các từ bị thiếu trong chú thích văn bản với một hình ảnh không bị che.
- Masked Image Modeling: Mô hình học cách tái tạo các pixel ẩn trong hình ảnh dựa trên một caption không bị che.
Một ví dụ về mô hình sử dụng masking là FLAVA (Foundational Language And Vision Alignment). FLAVA sử dụng Vision Transformer làm Image Encoder và kiến trúc Transformer cho cả Language Encoder và Multimodal Encoder. Multimodal encoder của FLAVA ứng dụng cơ chế cross-attention để kết hợp thông tin đa phương thức.
Generative Model Training
Generative Model Training giúp VLMs học cách tạo ra dữ liệu mới, bao gồm:
- Text-to-image Generation: Tạo ra hình ảnh từ văn bản đầu vào
- Image-to-text Generation: Tạo ra văn bản, chẳng hạn như các caption, mô tả hình ảnh hoặc tóm tắt, từ hình ảnh đầu vào.
Diffusion models, như Imagen của Google, Midjourney, DALL-E của OpenAI (bắt đầu từ DALL-E 2) và Stable Diffusion của Stability AI là các các mô hình Text-to-image phổ biến.
Pretrained models
Việc sử dụng các mô hình pretrained giúp doanh nghiệp tiết kiệm đáng kể chi phí và tài nguyên khi đào tạo Vision Language Models (VLMs). Thay vì huấn luyện từ đầu, có thể kết hợp một LLM pretrained với một Vision Encoder pretrained, sau đó bổ sung lớp mapping (projector) để căn chỉnh biểu diễn hình ảnh vào không gian đầu vào của LLM.
Một ví dụ điển hình là LLaVA (Large Language and Vision Assistant), kết hợp Vicuna LLM và CLIP ViT làm Vision Encoder. Các đầu ra được đưa vào cùng một không gian chiều chung thông qua Linear Projector, giúp mô hình xử lý hiệu quả dữ liệu đa phương thức.
Ngoài ra, để giảm công sức thu thập dữ liệu, doanh nghiệp có thể tận dụng các bộ dữ liệu chuẩn đã có sẵn cho các tác vụ downstream như:
- ImageNet: Hàng triệu hình ảnh có chú thích.
- COCO: Bộ dữ liệu lớn với nhãn cho ghi chú, phát hiện đối tượng và phân đoạn.
- LAION: Hàng tỷ cặp hình ảnh – văn bản đa ngôn ngữ, phù hợp huấn luyện VLM quy mô lớn.
Nhờ mô hình và dữ liệu pretrained, doanh nghiệp có thể rút ngắn đáng kể thời gian huấn luyện, đồng thời nhanh chóng tùy chỉnh VLM cho các lĩnh vực ứng dụng cụ thể.
Các Vision Language Models nổi tiếng
Vision Language Models (VLMs) đang trở thành xu hướng công nghệ AI mạnh mẽ, với tiềm năng cạnh tranh với các LLMs hiện đại. Dưới đây là những mô hình VLM đang dẫn đầu thị trường:
- DeepSeek-VL2: Mô hình VLM mã nguồn mở từ Trung Quốc với 4,5 tỷ tham số, gồm Vision Encoder, Vision Language Adapter và DeepSeekMoE LLM dựa trên kiến trúc Mixture of Experts (MoE). Ngoài ra còn có biến thể tiny (1B) và small (2,8B).
- Gemini 2.5 Pro: Được giới thiệu là mô hình mạnh nhất trong hệ sinh thái Google Gemini, Gemini 2.5 Pro nổi bật với khả năng xử lý các đầu vào đa phương thức như văn bản, hình ảnh, âm thanh và video, đồng thời tạo đầu ra dạng văn bản.
- GPT-5: Ra mắt tháng 8/2025, GPT-5 có khả năng xử lý văn bản, hình ảnh, âm thanh và video với đầu ra đa dạng. Nhờ kiến trúc mới kết hợp mô hình nhanh và suy luận sâu, GPT-5 vượt trội về tốc độ, độ chính xác và khả năng lập luận so với GPT-4o, đồng thời được tích hợp sâu trong hệ sinh thái Microsoft Copilot và Azure AI.
- Llama 3.2: Bộ mô hình mã nguồn mở từ Meta với hai phiên bản 11B và 90B tham số, có thể xử lý văn bản và hình ảnh nhưng chỉ tạo đầu ra văn bản. Kiến trúc bao gồm ViT Image Encoder, Video Adapter và Image Adapter với các lớp cross-attention để tích hợp biểu diễn hình ảnh vào Llama 3.1 đã huấn luyện trước.
- NVLM: Bộ mô hình đa phương thức của NVIDIA với ba biến thể riêng biệt: NVLM-D (decoder-only, đưa trực tiếp image tokens vào LLM decoder), NVLM-X (sử dụng cross-attention, tối ưu cho hình ảnh độ phân giải cao) và NVLM-H (hybrid, kết hợp decoder-only và cross-attention để cân bằng hiệu suất và khả năng lập luận).
- Qwen 2.5-VL: Mô hình của Alibaba Cloud với các phiên bản 3B, 7B và 72B tham số, kết hợp ViT Vision Encoder và Qwen 2.5 LLM. Có khả năng phân tích video dài hơn một giờ và tương tác trực tiếp với giao diện máy tính để bàn và điện thoại thông minh.
Kết luận
Vision Language Models là minh chứng rõ ràng cho bước tiến vượt bậc của trí tuệ nhân tạo – nơi AI không chỉ đọc hiểu mà còn nhìn thấy và suy luận. Với tiềm năng ứng dụng rộng khắp, từ phân tích ảnh y tế, giám sát an ninh, sản xuất thông minh đến sáng tạo nội dung, VLMs đang và sẽ tiếp tục tái định hình cách con người và máy móc tương tác với thế giới trực quan.
Trong tương lai gần, VLMs có thể trở thành nền tảng cho các AI Agent thông minh, tự động hóa hàng loạt quy trình cần đến nhận thức thị giác và hiểu biết ngôn ngữ – từ đó mở ra kỷ nguyên mới cho tự động hóa và trải nghiệm người dùng.
Tài liệu tham khảo
Encord. (2024, March 20). Vision-language models (VLMs): A comprehensive guide. Encord Blog. https://encord.com/blog/vision-language-models-guide/
NVIDIA. (n.d.). What are vision-language models (VLMs)? NVIDIA Glossary. https://www.nvidia.com/en-us/glossary/vision-language-models/
Li, L. H., & Hugging Face Team. (2023, July 13). Pretraining vision-and-language models with masked autoencoders. Hugging Face. https://huggingface.co/blog/vision_language_pretraining