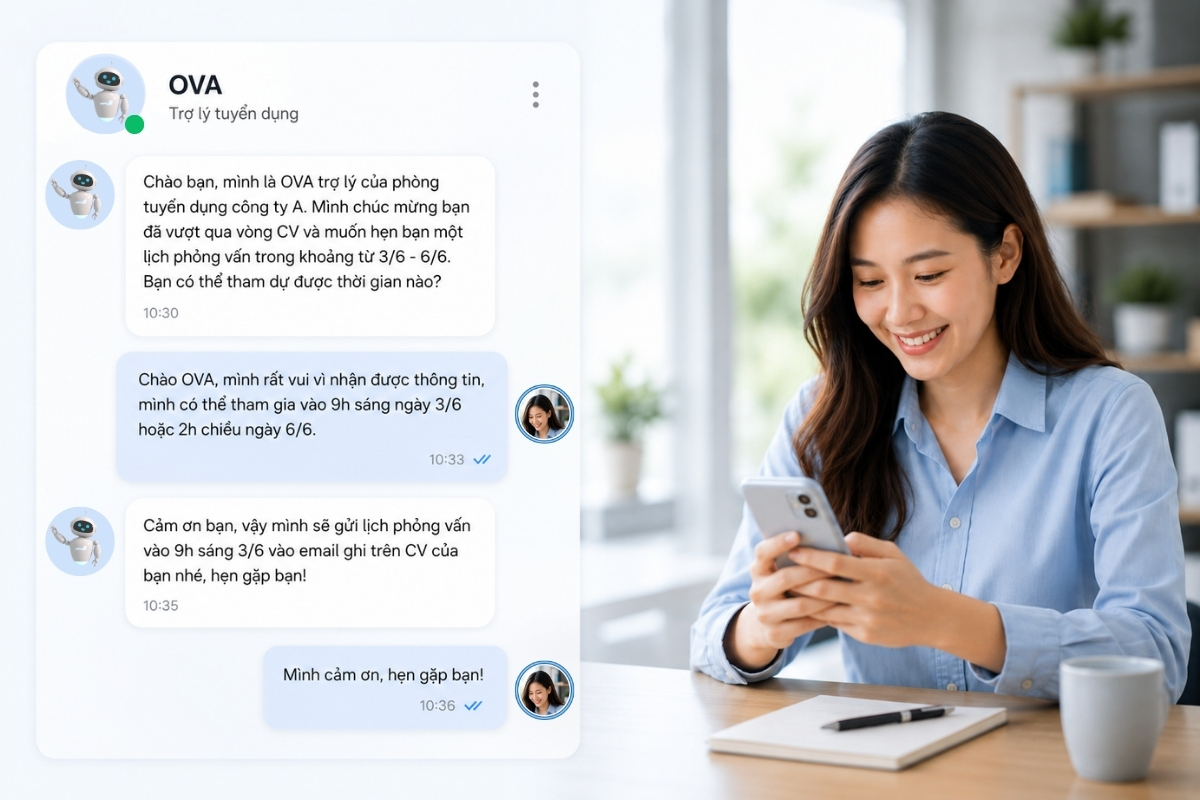
Language Model (mô hình ngôn ngữ) là một dạng mô hình trí tuệ nhân tạo dùng để học xác suất xuất hiện của các chuỗi từ trong ngôn ngữ tự nhiên, từ đó giúp máy tính dự đoán, sinh và hiểu văn bản. Đây là nền tảng của các hệ thống như ChatGPT, Google Translate, Siri và AI chatbot hiện đại. Trong bài viết này, FPT.AI sẽ giúp bạn hiểu rõ cách thức hoạt động, các loại Language Model phổ biến và những ứng dụng thực tế trong AI.
Language Model là gì?
Mô hình ngôn ngữ (Language Model – LM) là một dạng mô hình trí tuệ nhân tạo (AI) được huấn luyện trên khối lượng lớn dữ liệu văn bản nhằm học cách hiểu ngữ cảnh, dự đoán từ tiếp theo và tạo ra ngôn ngữ tự nhiên theo cách tương tự con người.
Language Model chủ yếu dựa trên học sâu (Deep Learning) và kiến trúc Transformer, giúp thực hiện hiệu quả nhiều tác vụ xử lý ngôn ngữ tự nhiên (NLP) như: dịch máy, tóm tắt văn bản, hỏi đáp, phân tích nội dung và tạo nội dung tự động. Đây là nền tảng của các hệ thống như ChatGPT, Google Translate, Siri và các AI chatbot hiện đại.
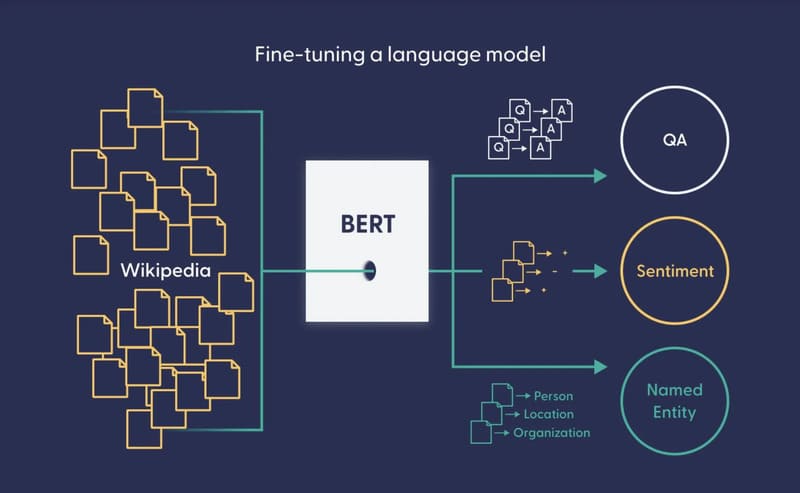
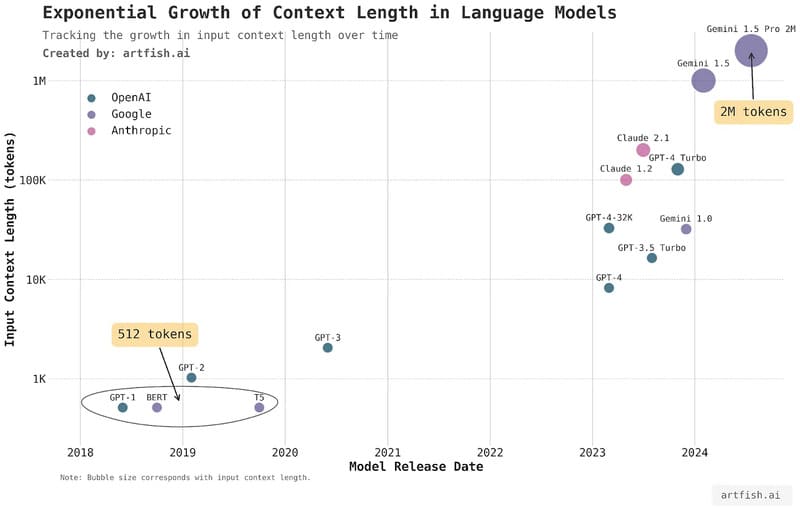
Các mô hình ngôn ngữ lớn (LLMs) như GPT-5 của OpenAI và Palm 2 của Google đã đưa công nghệ này lên tầm cao mới, với hàng tỷ tham số huấn luyện, cho phép chúng thực hiện nhiều tác vụ ngôn ngữ phức tạp và tạo ra văn bản gần giống con người.
>>> XEM THÊM: NLU là gì? So sánh hiểu ngôn ngữ tự nhiên NLU vs NLP, NLG
Cách thức hoạt động của Language Model
Language Model hoạt động bằng cách học xác suất xuất hiện của các chuỗi từ trong tập dữ liệu lớn. Thông qua quá trình huấn luyện, mô hình phân tích cách các từ thường đi cùng nhau, thứ tự xuất hiện và mối quan hệ ngữ nghĩa giữa chúng. Từ đó, Language Model có thể dự đoán từ tiếp theo trong một câu, hoàn thành văn bản hoặc sinh ra câu mới có ngữ cảnh hợp lý. Ở các mô hình hiện đại, quá trình này chủ yếu được thực hiện bằng mạng neural và kiến trúc Transformer, cho phép mô hình không chỉ dựa vào vài từ liền kề mà còn hiểu được ngữ cảnh toàn bộ đoạn văn.
Về mặt kỹ thuật, sự khác biệt giữa các mô hình ngôn ngữ nằm ở:
- Khối lượng dữ liệu văn bản được phân tích
- Phương pháp toán học được sử dụng trong quá trình phân tích
Các Language Model hiện đại có thể tận dụng nhiều lớp ngữ cảnh phức tạp – từ quan hệ giữa các từ liền kề đến việc nắm bắt ý nghĩa tổng thể của toàn bộ đoạn văn, giúp chúng tạo ra kết quả tự nhiên và mạch lạc hơn.
>>> XEM THÊM: Mô hình BERT là gì? Ứng dụng, vai trò của BERT trong NLP
Các loại Language Modeling phổ biến hiện nay
Có nhiều phương pháp để xây dựng mô hình ngôn ngữ. Một số loại Language Modeling phổ biến bao gồm:
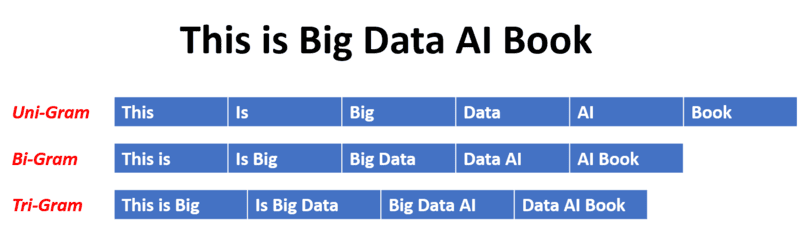
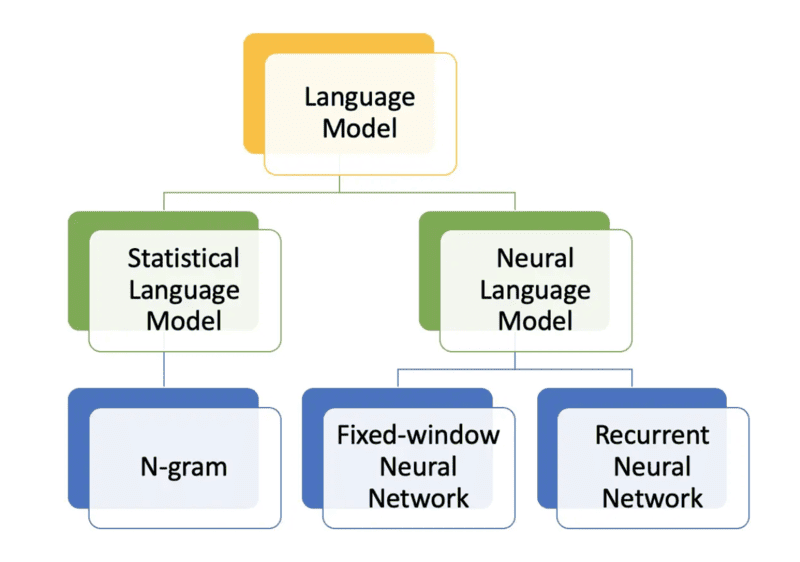
- N-gram: Đây là phương pháp tạo mô hình ngôn ngữ bằng cách tạo phân phối xác suất cho các chuỗi liên tiếp gồm n phần tử (từ, ký tự, biến tự nhiên đã được gán xác xuất). N xác định độ dài của chuỗi và đại diện cho lượng ngữ cảnh mô hình xem xét khi dự đoán. Ví dụ với câu “bạn có thể gọi cho tôi”, nếu n=5, N-gram sẽ là “bạn có thể gọi cho” và mô hình tính xác suất để từ “tôi” xuất hiện tiếp theo dựa trên ngữ cảnh trước đó. Các loại phổ biến N-gram phổ biến gồm Unigram (n=1): xem xét từng từ riêng lẻ, Bigram (n=2): xem xét cặp từ liên tiếp và Trigram (n=3): xem xét bộ ba từ liên tiếp. Ngoài việc dự đoán từ tiếp theo trong văn bản, N-gram còn được sử dụng để phát hiện phần mềm độc hại bằng cách phân tích các chuỗi byte trong tệp thực thi.
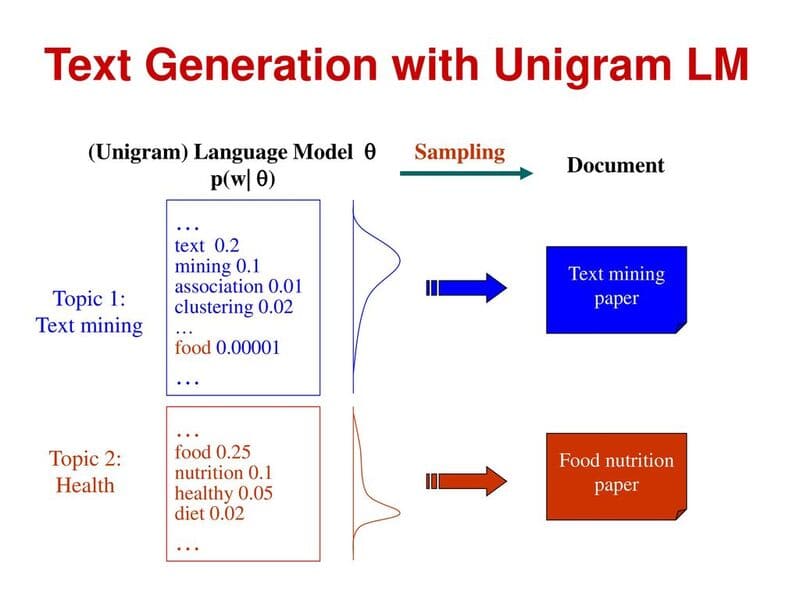
- Unigram: Đây là loại mô hình ngôn ngữ đơn giản nhất, không xem xét ngữ cảnh điều kiện trong các tính toán mà đánh giá mỗi từ hoặc thuật ngữ một cách độc lập. Unigram thường xử lý các tác vụ như truy xuất thông tin và là nền tảng cho mô hình khả năng truy vấn, giúp kiểm tra nhóm tài liệu và khớp tài liệu phù hợp nhất với truy vấn cụ thể.
- Mô hình Hai chiều (Bidirectional): Khác với N-gram chỉ phân tích văn bản theo một hướng, Bidirectional phân tích theo cả hai hướng (ngược và xuôi). Nó có thể dự đoán bất kỳ từ nào trong một câu hoặc khối văn bản bằng cách sử dụng mọi từ khác trong văn bản, giúp tăng độ chính xác. Bidirectional thường được sử dụng trong học máy (Machine Learning) và ứng dụng tạo giọng nói AI. Ví dụ, Google sử dụng mô hình hai chiều để xử lý truy vấn tìm kiếm

-
- Hàm mũ (Exponential): Còn được gọi là mô hình entropy tối đa, phức tạp hơn N-gram. Nó đánh giá văn bản bằng phương trình kết hợp các hàm đặc trưng và N-gram, chỉ định các đặc trưng và tham số của kết quả mong muốn nhưng để lại các tham số phân tích mơ hồ hơn (do không chỉ định kích thước gram riêng lẻ). Exponential dựa trên nguyên tắc entropy: Phân phối xác suất có entropy cao nhất là lựa chọn tốt nhất – Mô hình càng hỗn loạn, ít chỗ cho giả định, càng chính xác. Các mô hình hàm mũ được thiết kế để tối đa hóa cross-entropy, giảm thiểu lượng giả định thống kê được đưa ra.
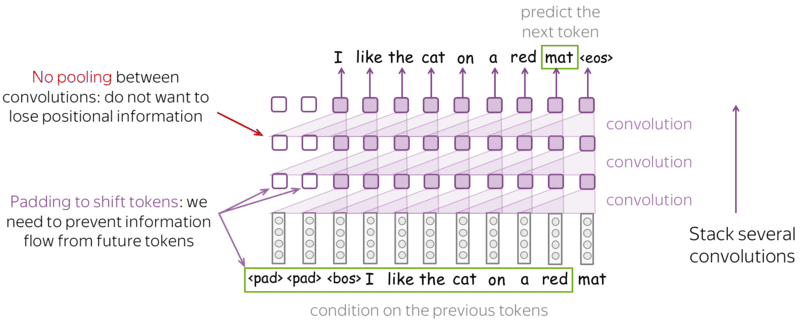
- Mô hình ngôn ngữ Neural: Các mô hình ngôn ngữ Neural sử dụng các kỹ thuật học sâu (Deep Learning) để vượt qua giới hạn của mô hình N-gram. Chúng sử dụng mạng neural như Recurrent Neural Network và transformers để nắm bắt mẫu và phụ thuộc phức tạp trong văn bản. Các mô hình RNN bao gồm LSTM (long short-term memory) và GRU (gated recurrent unit) có thể xem xét tất cả từ trước đó khi dự đoán từ tiếp theo, nắm bắt phụ thuộc phạm vi dài và tạo ra văn bản phù hợp với ngữ cảnh hơn. Transformers sử dụng cơ chế tự chú ý để đánh giá tầm quan trọng của từng từ trong một câu, nắm bắt các phụ thuộc toàn cục. Các mô hình AI tạo sinh như GPT-3 và Palm 2 dựa trên kiến trúc transformer.
- Mô hình Không gian liên tục (Continuous space): Là loại neural network biểu diễn từ như một sự kết hợp phi tuyến tính của trọng số trong mạng neural. Quá trình gán trọng số cho một từ còn gọi là nhúng từ (word embedding). Continuous space đặc biệt hữu ích với tập dữ liệu lớn chứa nhiều từ độc đáo hoặc hiếm khi sử dụng, giải quyết tình trạng các mẫu thông báo kết quả trở nên yếu hơn khi số lượng chuỗi từ tăng lên của các mô hình tuyến tính như N-gram. Bằng cách đặt trọng số phi tuyến tính, phân tán, Continuous space có thể học để xấp xỉ các từ, không gắn chặt sự hiểu biết về một từ với các từ xung quanh và không bị đánh lừa bởi giá trị không xác định như N-gram
>>> XEM THÊM: Masked Language Models là gì? Vai trò của MLMs trong NLP
Tầm quan trọng của Language Model
Mô hình hóa ngôn ngữ đóng vai trò rất quan trọng trong các ứng dụng xử lý ngôn ngữ tự nhiên (NLP) hiện đại. Nhờ các mô hình này, máy móc có thể hiểu được thông tin định tính bằng cách chuyển đổi chúng thành thông tin định lượng, cho phép con người giao tiếp với máy móc gần giống như cách họ tương tác với nhau.
Hầu hết mọi người đều đã tương tác với một mô hình ngôn ngữ trong cuộc sống hàng ngày thông qua:
- Tìm kiếm Google
- Chức năng văn bản tự động hoàn thành
- Trợ lý giọng nói
Nguồn gốc của mô hình hóa ngôn ngữ có thể được truy ngược đến năm 1948, khi Claude Shannon xuất bản bài báo “Lý thuyết toán học về truyền thông”. Trong bài báo này, ông giới thiệu việc sử dụng chuỗi Markov (một mô hình ngẫu nhiên) để tạo mô hình thống kê cho các chuỗi chữ cái trong văn bản tiếng Anh. Công trình này đã có tác động lớn đến ngành viễn thông và đặt nền móng cho lý thuyết thông tin và mô hình hóa ngôn ngữ. Các mô hình Markov vẫn được sử dụng đến ngày nay, và khái niệm N-gram gắn liền chặt chẽ với lý thuyết này.
Các ứng dụng và ví dụ về Language Modeling
Các lĩnh vực ứng dụng của mô hình hóa ngôn ngữ rất đa dạng, bao gồm:
- Công nghệ thông tin
- Tài chính
- Y tế
- Giao thông
- Pháp luật
- Quân sự
- Chính phủ
Các mô hình ngôn ngữ là xương sống của NLP. Dưới đây là một số trường hợp sử dụng và nhiệm vụ NLP sử dụng Language Modeling bao gồm:
- Nhận diện giọng nói: Speech recognition giúp máy tính xử lý âm thanh, thường được ứng dụng trong các trợ lý giọng nói phổ biến như Siri và Alexa.
- Tạo văn bản: Text generation sử dụng dự đoán để tạo ra văn bản mạch lạc và phù hợp với ngữ cảnh, thường được ứng dụng trong viết sáng tạo, tạo nội dung và tóm tắt dữ liệu có cấu trúc.
- AI Chatbot: Những bot này tham gia vào các cuộc trò chuyệi với người dùng và tạo ra các phản hồi tự nhiên, chính xác, được sử dụng trong trợ lý ảo, ứng dụng hỗ trợ khách hàng và hệ thống truy xuất thông tin.
- Dịch máy: Machine translation chuyển đổi nội dung từ một ngôn ngữ sang ngôn ngữ khác. Google Dịch và Microsoft Translator là hai ứng dụng tiêu biểu. Một ứng dụng khác là SDL Government, được sử dụng để dịch các nguồn cấp dữ liệu truyền thông xã hội nước ngoài trong thời gian thực cho chính phủ Hoa Kỳ.
- Gắn thẻ từ loại: Parts-of-speech tagging đánh dấu và phân loại các từ theo đặc điểm ngữ pháp. Nó được sử dụng đầu tiên và nổi tiếng nhất trong nghiên cứu của Brown Corpus. Corpus đã sử dụng một tập hợp các bài văn xuôi tiếng Anh ngẫu nhiên được thiết kế để nghiên cứu bởi máy tính để đào tạo nhiều mô hình ngôn ngữ quan trọng, bao gồm mô hình được Google sử dụng để cải thiện chất lượng tìm kiếm.
- Phân tích cú pháp: Parsing phân tích bất kỳ chuỗi dữ liệu hoặc câu tuân theo các quy tắc ngữ pháp và cú pháp ở dạng sơ đồ câu mô tả mối quan hệ của mỗi từ với các từ khác. Parsing thường được ứng dụng trong các ứng dụng kiểm tra chính tả
- Nhận dạng ký tự quang học: OCR (Optical character recognition) chuyển đổi hình ảnh văn bản (một tài liệu được quét hoặc ảnh chụp của tài liệu) thành văn bản được mã hóa bởi máy tính. Nhận dạng ký tự quang học thường được sử dụng để số hoá các tập tài liệu giấy hoặc nhận dạng chữ viết tay.
- Truy xuất thông tin: Information retrieval liên quan đến việc tìm kiếm thông tin trong một tài liệu hoặc tìm kiếm metadata tương ứng với một tài liệu. Các trình duyệt web là các ứng dụng truy xuất thông tin phổ biến nhất.
- Phân tích dữ liệu quan sát: Các mô hình ngôn ngữ này phân tích dữ liệu quan sát như dữ liệu cảm biến, dữ liệu đo từ xa và dữ liệu từ các thí nghiệm.
- Phân tích tình cảm: Sentiment Analysis xác định tình cảm đằng sau một cụm từ, được sử dụng để hiểu ý kiến và thái độ được thể hiện trong một văn bản. Các doanh nghiệp sử dụng phân tích tình cảm để phân tích dữ liệu không có cấu trúc, chẳng hạn như đánh giá sản phẩm và bài đăng chung về sản phẩm, cũng như phân tích dữ liệu nội bộ như khảo sát nhân viên và trò chuyện hỗ trợ khách hàng. Một số dịch vụ cung cấp công cụ phân tích tình cảm là Repustate và Service Hub của HubSpot. Công cụ NLP Bert của Google cũng được sử dụng để phân tích tình cảm.
Tương lai của Language Modeling
Các LLM tiên tiến, có hàng tỷ tham số và được đào tạo trên một lượng dữ liệu khổng, như ChatGPT và Bard đã thể hiện khả năng ấn tượng trong việc hiểu các mẫu ngôn ngữ phức tạp, và tạo ra văn bản tự nhiên như con người. Thành công của chúng đã dẫn đến việc chúng được triển khai vào các công cụ tìm kiếm Bing và Google, hứa hẹn sẽ thay đổi trải nghiệm tìm kiếm.
Các kỹ thuật khoa học dữ liệu mới, như fine-tuning và transfer learning, đã trở thành yếu tố thiết yếu trong Language Modeling. Thay vì đào tạo một mô hình từ đầu, fine-tuning cho phép các nhà phát triển lấy một Language Model được đào tạo trước và điều chỉnh nó cho một tác vụ hoặc lĩnh vực, giảm lượng dữ liệu được gắn nhãn cho việc đào tạo và cải thiện hiệu suất tổng thể của mô hình.
Tuy nhiên, khi các kỹ thuật và khả năng của Language Model trở nên mạnh mẽ hơn, các vấn đề như thiên kiến trong văn bản được tạo ra, thông tin sai lệch và khả năng lạm dụng mô hình ngôn ngữ dựa trên AI đã khiến nhiều chuyên gia AI và nhà phát triển như Elon Musk cảnh báo chống lại sự phát triển không được kiểm soát của chúng.
Tóm lại, Language Modeling là nền tảng không thể thiếu trong các ứng dụng xử lý ngôn ngữ tự nhiên hiện đại. Từ việc dự đoán từ tiếp theo cho đến việc tạo ra các câu hoàn chỉnh, mô hình ngôn ngữ giúp máy tính hiểu và tương tác với con người một cách tự nhiên hơn.
Mặc dù còn tồn tại một số thách thức liên quan đến sự thiên lệch và khả năng lạm dụng, nhưng tầm quan trọng của mô hình hóa ngôn ngữ trong AI và các lĩnh vựcc vẫn không thể phủ nhận. Với sự phát triển không ngừng của các mô hình ngôn ngữ lớn, tương lai của công nghệ này hứa hẹn sẽ mang lại nhiều tiến bộ vượt bậc.