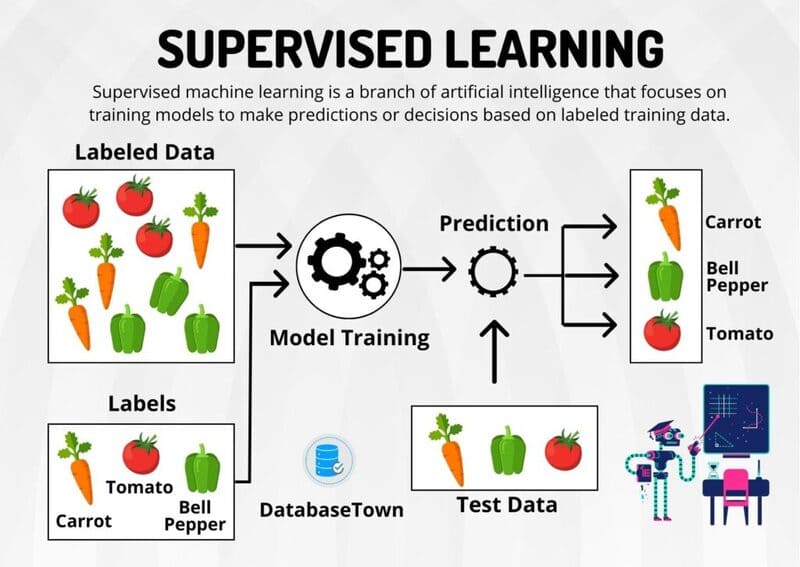
Trong lĩnh vực Machine Learning, Supervised Learning là một trong những phương pháp được ứng dụng để xây dựng mô hình dự đoán dựa trên dữ liệu đã có sẵn kết quả tham chiếu. Cách tiếp cận này đóng vai trò quan trọng trong nhiều bài toán thực tế như phân loại, dự báo và nhận diện mẫu.
Trong bài viết này, FPT.AI sẽ giới thiệu chi tiết về học có giám sát, từ cơ chế hoạt động, các loại chính đến sự khác biệt với các phương pháp học máy khác, ứng dụng thực tế và những thách thức mà phương pháp này đang đối mặt. Từ đó, người đọc sẽ có cái nhìn toàn diện về sức mạnh và giới hạn của Supervised Learning trong kỷ nguyên trí tuệ nhân tạo hiện nay.
Supervised Learning là gì?
Học có giám sát (Supervised Learning) là một kỹ thuật Machine Learning trong đó mô hình được huấn luyện thông qua tập dữ liệu đã được gán nhãn. Phương pháp này tập trung vào việc tạo mối liên hệ giữa đầu vào và đầu ra dựa trên các ví dụ có sẵn, nhằm phát triển khả năng dự đoán chính xác khi đối mặt với dữ liệu mới trong thực tế.
Trong Supervised Learning, mỗi dữ liệu đầu vào đều có sẵn nhãn đầu ra đúng để mô hình học theo. Thuật toán sẽ liên tục điều chỉnh trọng số nhằm tối ưu kết quả dự đoán, từ đó nhận diện được mối liên hệ giữa đặc trưng đầu vào và nhãn đầu ra. Nhờ cách tiếp cận rõ ràng và dễ triển khai, học có giám sát được ứng dụng rộng rãi trong phân loại email spam, dự đoán giá cổ phiếu, nhận diện hình ảnh y tế,…
Với dữ liệu gán nhãn chất lượng, Supervised Learning trở thành một trong những phương pháp Machine Learning phổ biến và đáng tin cậy hiện nay.
Cơ chế hoạt động của Supervised Learning là gì?
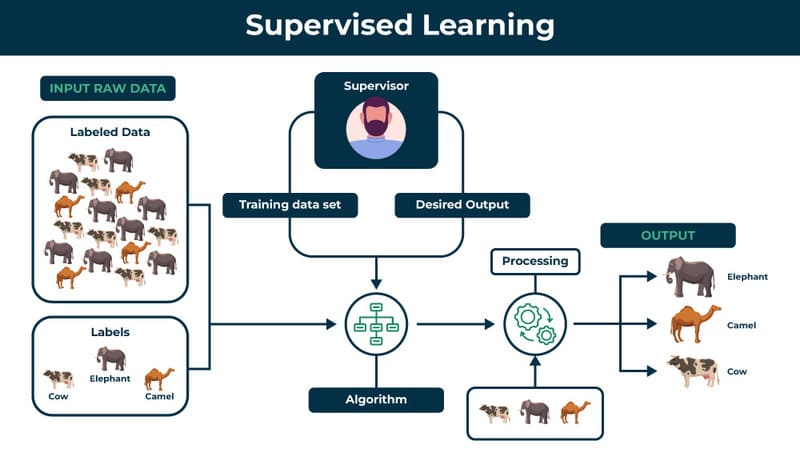
Supervised Learning sử dụng tập dữ liệu đào tạo đã được gán nhãn để hiểu mối quan hệ giữa dữ liệu đầu vào và đầu ra. Khác với các phương pháp học không giám sát, phương pháp này đòi hỏi con người tham gia vào quá trình chuẩn bị dữ liệu huấn luyện trước khi thuật toán có thể học và đưa ra dự đoán.
Quy trình Supervised Learning diễn ra theo các bước sau:
- Thu thập và gán nhãn dữ liệu: Các nhà khoa học dữ liệu tạo thủ công tập dữ liệu chứa các cặp đầu vào – đầu ra, trong đó mỗi dữ liệu đầu vào đều đi kèm với nhãn chính xác tương ứng. Ví dụ, trong bài toán phân loại hình ảnh, tập dữ liệu sẽ bao gồm các hình ảnh (đầu vào) cùng với nhãn xác định nội dung như “mèo” hay “chó” (đầu ra). Chất lượng của tập dữ liệu sẽ ảnh hưởng trực tiếp đến hiệu quả học tập của mô hình. Dữ liệu đào tạo phải không có sự thiên lệch dữ liệu để tránh thiên lệch thuật toán kết quả và các lỗi hiệu suất khác.
- Xác định loại dữ liệu huấn luyện: Dữ liệu được sử dụng cho việc huấn luyện nên tương tự với dữ liệu đầu vào mà mô hình sẽ xử lý trong thực tế. Điều này đảm bảo mô hình có thể áp dụng những gì đã học vào các tình huống thực tế.
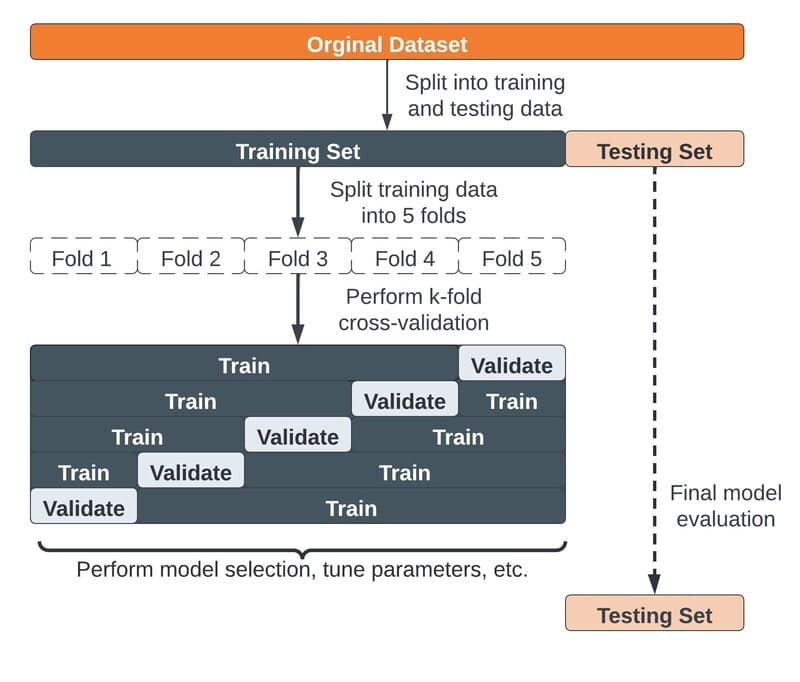
- Tạo các nhóm dữ liệu riêng biệt: Chia tập dữ liệu thành ba nhóm: dữ liệu huấn luyện (training data), dữ liệu xác thực (validation data) và dữ liệu kiểm tra (test data). Mỗi nhóm đóng vai trò khác nhau trong quá trình phát triển mô hình.
- Chọn thuật toán Machine Learning: Lựa chọn thuật toán phù hợp với loại dữ liệu và mục tiêu của bài toán cần giải quyết để tạo mô hình.
- Huấn luyện mô hình: Đưa tập dữ liệu đào tạo vào thuật toán đã chọn. Thuật toán sẽ xử lý lượng lớn dữ liệu đã gán nhãn để tìm ra mối tương quan tiềm ẩn giữa đầu vào và đầu ra. Mô hình học cách ánh xạ từ dữ liệu đầu vào đến kết quả dự đoán mong muốn.
- Đánh giá mô hình bằng Cross-Validation: Áp dụng phương pháp Cross-Validation (Xác thực chéo) – sử dụng các phần khác nhau của tập dữ liệu để kiểm tra hiệu suất mô hình – để đảm bảo mô hình có khả năng tổng quát hóa tốt và không bị hiện tượng Overfitting (quá khớp với dữ liệu huấn luyện).
- Tối ưu hóa mô hình với Gradient Descent: Supervised Learning thường sử dụng họ thuật toán Gradient Descent, bao gồm Stochastic Gradient Descent (SGD), để tối ưu hóa mô hình. Đây là các thuật toán phổ biến trong huấn luyện Neural Networks và các mô hình Machine Learning, hoạt động bằng cách đánh giá độ chính xác thông qua Loss Function – phương trình đo lường sự chênh lệch giữa dự đoán và giá trị thực tế.
- Sử dụng Gradient để cải thiện mô hình: Gradient, hay độ dốc của hàm mất mát, là thước đo chính của hiệu suất mô hình. Thuật toán điều chỉnh các tham số theo hướng “đi xuống” theo Gradient để giảm thiểu giá trị hàm mất mát. Quá trình này được lặp lại liên tục, giúp mô hình cải thiện khả năng dự đoán.
- Kiểm tra mô hình cuối cùng: Đánh giá hiệu suất của mô hình đã huấn luyện bằng tập dữ liệu kiểm tra – phần dữ liệu được tách riêng mà mô hình chưa từng thấy trong quá trình huấn luyện. Bước này xác định mức độ hiệu quả của mô hình khi áp dụng vào dữ liệu mới.
- Theo dõi và duy trì: Sau khi triển khai, mô hình cần được theo dõi hiệu suất và cập nhật thường xuyên để duy trì độ chính xác khi dữ liệu thực tế thay đổi theo thời gian.
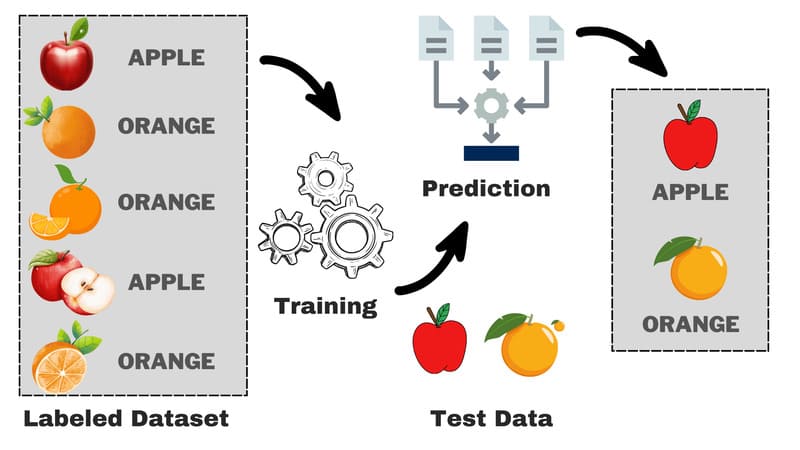
Ví dụ về học có giám sát trong thực tế
Hãy tưởng tượng một mô hình được xây dựng để nhận diện các phương tiện giao thông trong hình ảnh. Ứng dụng quen thuộc là các bài kiểm tra CAPTCHA yêu cầu chọn hình có “ô tô” hay “xe buýt” để xác minh người dùng thật.
Để huấn luyện, mô hình được cung cấp hàng nghìn hình ảnh đã gán nhãn sẵn như “ô tô”, “xe máy”, “xe tải”, “xe đạp”, “xe buýt”. Từ các cặp hình ảnh và nhãn này, hệ thống học cách phân biệt đặc điểm của từng loại phương tiện.
Trong quá trình học, thuật toán phân tích các yếu tố như hình dáng, kích thước, số bánh xe… rồi liên kết chúng với nhãn tương ứng. Sau khi huấn luyện xong, mô hình được kiểm tra bằng tập dữ liệu mới chưa từng thấy trước đó để đánh giá độ chính xác.
Nếu kết quả chưa đạt yêu cầu, mô hình sẽ được điều chỉnh và huấn luyện lại. Khả năng dự đoán đúng trên dữ liệu mới được gọi là generalization, đây là yếu tố quan trọng quyết định chất lượng của một hệ thống Supervised Learning.
Các loại học có giám sát (Supervised Learning) chính
Các tác vụ Supervised Learning trong Machine Learning có thể được phân chia thành các vấn đề phân loại và hồi quy. Dưới đây là các loại Supervised Learning chính:
- Classification (Phân loại): Phương pháp này sử dụng thuật toán để phân loại dữ liệu thành các danh mục riêng biệt. Classification nhận dạng các thực thể cụ thể trong tập dữ liệu và xác định cách các thực thể đó nên được gán nhãn hoặc định nghĩa (email – thư rác, chó – mèo). Các thuật toán phân loại phổ biến bao gồm Linear Classifiers, Support Vector Machines (SVM), Decision Trees, K-Nearest Neighbor và Random Forest.
- Regression (Hồi quy): Không như phân loại, hồi quy được sử dụng để hiểu mối quan hệ giữa các biến phụ thuộc và độc lập. Mô hình sẽ cố gắng dự đoán đầu ra mục tiêu (một giá trị liên tục) thay vì nhóm dữ liệu vào các danh mục. Các ứng dụng của Regression bao gồm dự báo doanh thu bán hàng, ước tính giá nhà dựa trên vị trí hay lập kế hoạch tài chính. Thuật toán phổ biến bao gồm Linear Regression, Logistical Regression và Polynomial Regression.
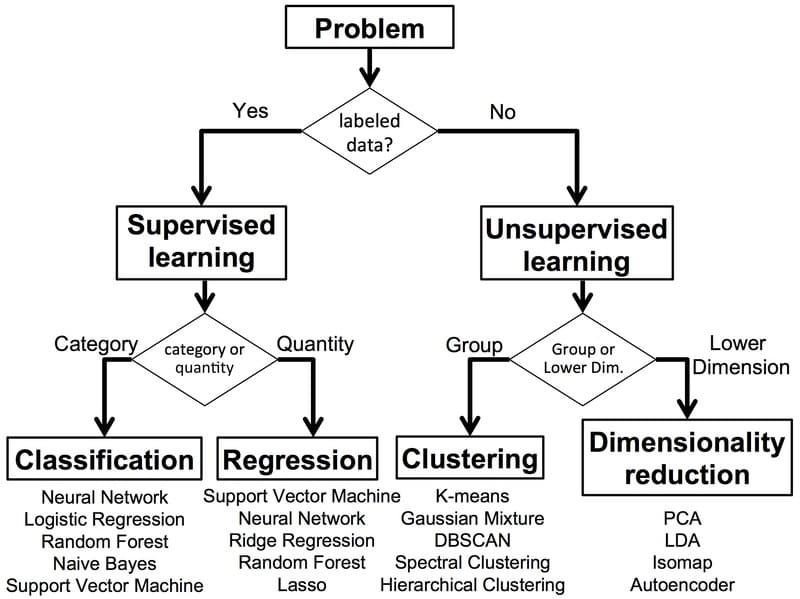
Vì các tập dữ liệu lớn thường chứa nhiều đặc trưng, các nhà khoa học dữ liệu có thể đơn giản hóa độ phức tạp này thông qua Dimensionality Reduction. Kỹ thuật khoa học dữ liệu này giảm số lượng đặc trưng xuống chỉ còn những đặc trưng quan trọng nhất để dự đoán nhãn dữ liệu, đảm bảo mô hình giữ được độ chính xác trong khi tăng hiệu quả.
Khi lựa chọn thuật toán Supervised Learning phù hợp, cần xem xét các yếu tố như độ phức tạp của mô hình, độ chính xác mong muốn, tính tuyến tính của dữ liệu và sự cân bằng giữa độ chệch (bias) và phương sai (variance). Những cân nhắc này giúp đảm bảo mô hình được chọn sẽ tối ưu hóa hiệu suất và độ chính xác của kết quả dự đoán cho bài toán cụ thể.
Các thuật toán học có giám sát phổ biến
Dưới đây là những thuật toán Supervised Learning phổ biến nhất:
| Thuật toán | Mô tả | Ứng dụng phổ biến |
| Naive Bayes | Thuật toán phân loại dựa trên định lý Bayes và giả định các đặc trưng độc lập có điều kiện. Mỗi đặc trưng có mức ảnh hưởng ngang nhau đến kết quả. Bao gồm các biến thể Multinomial, Bernoulli và Gaussian. | Phân loại văn bản, nhận dạng thư rác, hệ thống đề xuất |
| Linear Regression | Mô hình hóa mối quan hệ giữa biến phụ thuộc liên tục và một hoặc nhiều biến độc lập dưới dạng đường thẳng. Gồm Simple Linear Regression và Multiple Linear Regression. | Dự đoán giá trị, dự báo xu hướng |
| Nonlinear Regression | Sử dụng khi mối quan hệ giữa biến đầu vào và đầu ra không tuyến tính. Biểu diễn bằng đường cong phi tuyến để xử lý quan hệ phức tạp. | Mô hình hóa dữ liệu phi tuyến |
| Logistic Regression | Thuật toán phân loại nhị phân với đầu ra dạng đúng/sai hoặc dương tính/âm tính. Dù tên là “Regression”, chủ yếu dùng cho phân loại. | Nhận diện spam, phát hiện gian lận, dự đoán hành vi khách hàng |
| Polynomial Regression | Tập con của Nonlinear Regression, mô hình hóa quan hệ bằng hàm đa thức nhiều bậc để biểu diễn xu hướng phi tuyến. | Phân tích dữ liệu có xu hướng cong |
| Support Vector Machine (SVM) | Thuật toán dùng cho phân loại và hồi quy. Tìm siêu phẳng (Hyperplane) tối ưu để tách các lớp dữ liệu với khoảng cách lớn nhất. | Phân loại dữ liệu, nhận diện mẫu |
| K-Nearest Neighbor (KNN) | Thuật toán phi tham số phân loại dựa trên khoảng cách giữa các điểm dữ liệu. Giả định các điểm gần nhau có đặc điểm tương tự. | Công cụ đề xuất, nhận dạng hình ảnh |
| Random Forest | Tập hợp nhiều Decision Tree không tương quan để giảm phương sai và tăng độ chính xác. Tổng hợp kết quả từ nhiều cây quyết định. | Phân loại và hồi quy, giảm overfitting |

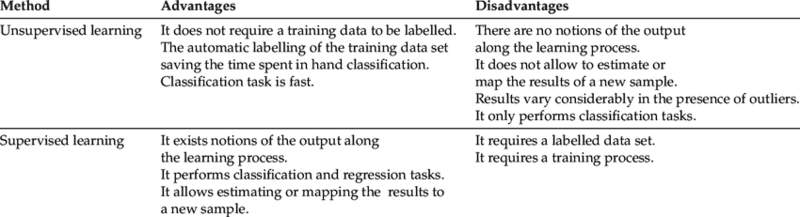
Ưu và nhược điểm của học có giám sát
Nhờ khả năng học mối quan hệ giữa dữ liệu đầu vào và đầu ra, Supervised Learning được ứng dụng rộng rãi trong phân loại hình ảnh, dự đoán giá trị và xử lý ngôn ngữ tự nhiên. Tuy nhiên, phương pháp này cũng tồn tại cả điểm mạnh và hạn chế cần cân nhắc trước khi triển khai.
Ưu điểm của Supervised Learning
- Dễ hiểu và dễ triển khai: Các thuật toán học có giám sát hoạt động rõ ràng, phù hợp với nhiều bài toán thực tế trong doanh nghiệp.
- Độ chính xác cao: Khi sử dụng dữ liệu gán nhãn chất lượng, mô hình có thể đạt hiệu suất dự đoán tốt và ổn định.
- Có thể giải thích kết quả: Một số thuật toán như Decision Tree cho phép phân tích cách mô hình đưa ra quyết định, giúp tăng tính minh bạch.
Nhược điểm của Supervised Learning
- Phụ thuộc vào dữ liệu gán nhãn: Việc thu thập và gắn nhãn dữ liệu tốn nhiều thời gian, chi phí và nguồn lực.
- Khả năng tổng quát hóa hạn chế: Nếu dữ liệu huấn luyện không đa dạng, mô hình có thể hoạt động kém với dữ liệu mới.
- Nguy cơ overfitting: Mô hình quá phức tạp có thể học cả nhiễu trong dữ liệu huấn luyện, làm giảm hiệu suất trên tập kiểm tra.
Hiểu rõ ưu và nhược điểm của Supervised Learning giúp nhà khoa học dữ liệu lựa chọn phương pháp phù hợp với từng bài toán và tối ưu hiệu quả triển khai AI trong thực tế.
So sánh Supervised Learning với các phương pháp Machine Learning khác
Học có giám sát không phải là phương pháp học duy nhất để đào tạo các mô hình Machine Learning. Các loại Machine Learning khác bao gồm:
Học có giám sát và học không giám sát
Sự khác biệt lớn nhất giữa Supervised Learning và Unsupervised Learning nằm ở dữ liệu huấn luyện.
Supervised Learning sử dụng dữ liệu đã gán nhãn, tức mỗi đầu vào đều có sẵn kết quả đúng. Mô hình học cách liên kết đầu vào với đầu ra để dự đoán chính xác trên dữ liệu mới. Ví dụ: phân loại email thành spam hoặc không spam dựa trên dữ liệu đã được gắn nhãn.
Ngược lại, Unsupervised Learning làm việc với dữ liệu không có nhãn. Mô hình tự tìm ra các mẫu hoặc cấu trúc ẩn trong dữ liệu, chẳng hạn như nhóm khách hàng có hành vi mua sắm tương tự. Phương pháp này thường dùng cho bài toán phân cụm và giảm chiều dữ liệu.
Trong thực tế, nhiều mô hình AI tạo sinh hiện đại kết hợp cả hai cách: trước tiên học không giám sát để hiểu cấu trúc chung của dữ liệu, sau đó dùng học có giám sát để nâng cao độ chính xác cho nhiệm vụ cụ thể.

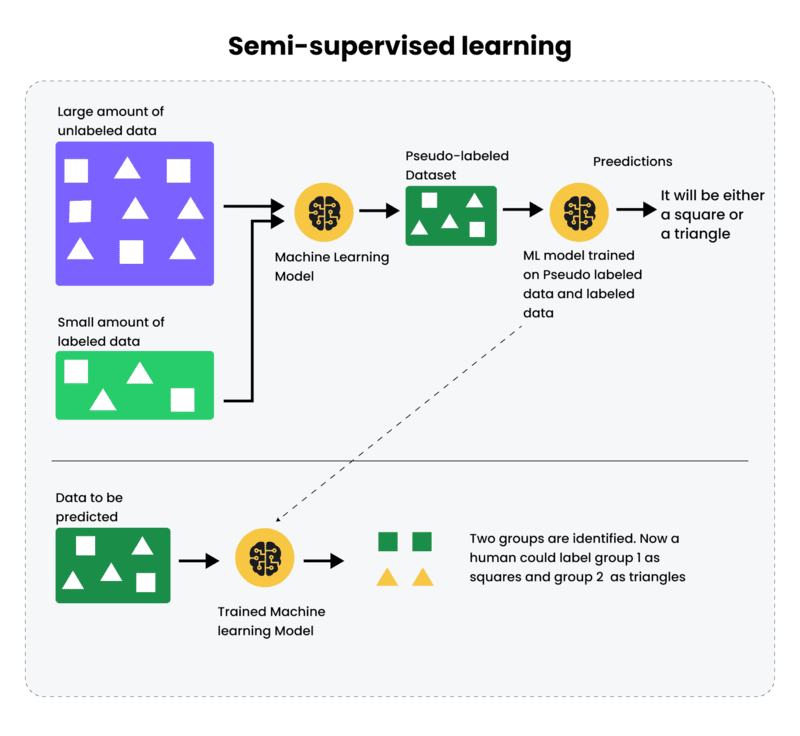
Học có giám sát so với học bán giám sát
Điểm khác biệt cơ bản giữa học có giám sát (Supervised Learning) và học bán giám sát (Semi-Supervised Learning) nằm ở cách thức sử dụng dữ liệu đã được gán nhãn.
Trong Supervised Learning, toàn bộ dữ liệu huấn luyện đều phải được gán nhãn đầy đủ. Mỗi mẫu dữ liệu đầu vào đi kèm với kết quả chính xác, giúp mô hình học cách ánh xạ giữa đầu vào và đầu ra. Tuy nhiên, việc thu thập và gán nhãn dữ liệu ở quy mô lớn thường tốn nhiều thời gian, chi phí và nguồn lực chuyên môn.
Ngược lại, Semi-Supervised Learning chỉ yêu cầu một phần dữ liệu được gán nhãn, trong khi phần còn lại có thể không có nhãn. Mô hình sẽ tận dụng cả dữ liệu có nhãn và không nhãn để cải thiện hiệu suất dự đoán. Phương pháp này phù hợp trong các tình huống mà dữ liệu dồi dào nhưng việc gán nhãn gặp nhiều hạn chế.
Ví dụ minh họa: Trong bài toán nhận diện khuôn mặt, chỉ một số hình ảnh được gán tên cụ thể, còn phần lớn hình ảnh khác không có nhãn. Mô hình học bán giám sát sẽ sử dụng các ảnh đã gán tên để định hướng học, đồng thời khai thác các ảnh chưa gán nhãn nhằm nhận diện đặc trưng chung. Nhờ đó, hệ thống vẫn có thể nâng cao độ chính xác mà không cần gán nhãn toàn bộ dữ liệu.
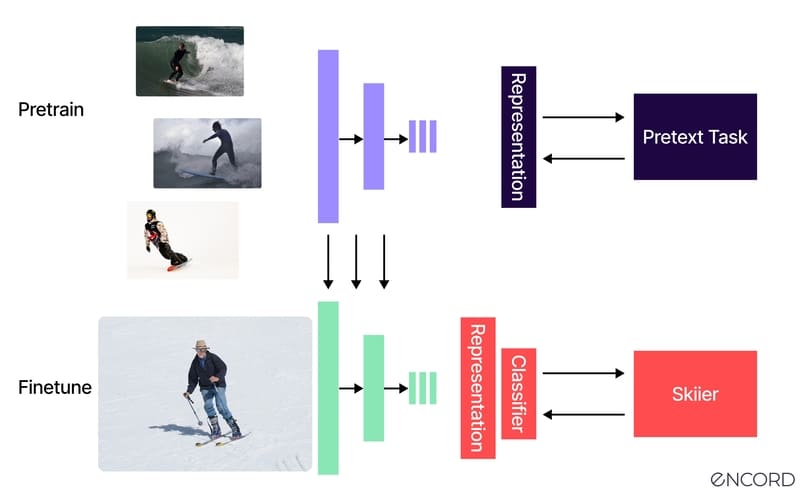
Học có giám sát so với học tự giám sát
Điểm khác biệt quan trọng nhất giữa học có giám sát (Supervised Learning) và học tự giám sát (Self-Supervised Learning) nằm ở nguồn gốc của nhãn dùng để huấn luyện mô hình.
Trong Supervised Learning, dữ liệu được gán nhãn thủ công bởi con người trước khi đưa vào huấn luyện. Mỗi mẫu dữ liệu đều có kết quả đúng đi kèm, giúp mô hình học cách dự đoán chính xác. Tuy nhiên, quá trình gán nhãn này thường tốn nhiều thời gian, chi phí và nguồn lực chuyên môn, đặc biệt với tập dữ liệu lớn.
Ngược lại, Self-Supervised Learning không cần nhãn do con người tạo ra. Thay vào đó, mô hình tự sinh ra “nhãn ngầm” từ chính dữ liệu đầu vào và sử dụng chúng để huấn luyện. Cách tiếp cận này giúp khai thác khối lượng dữ liệu phi cấu trúc khổng lồ mà không cần gán nhãn thủ công.
Học tự giám sát đặc biệt phổ biến trong lĩnh vực Deep Learning, nhất là trong các bài toán Xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) và Thị giác máy tính (Computer Vision. Các mô hình ngôn ngữ lớn như GPT và BERT đã tận dụng phương pháp này để học từ dữ liệu văn bản quy mô lớn.
Ví dụ minh họa: Trong NLP, mô hình có thể được huấn luyện bằng cách che một từ trong câu và yêu cầu dự đoán từ bị thiếu dựa trên ngữ cảnh xung quanh. Thông qua quá trình này, hệ thống dần hiểu cấu trúc và quy luật ngôn ngữ mà không cần bất kỳ nhãn thủ công nào.
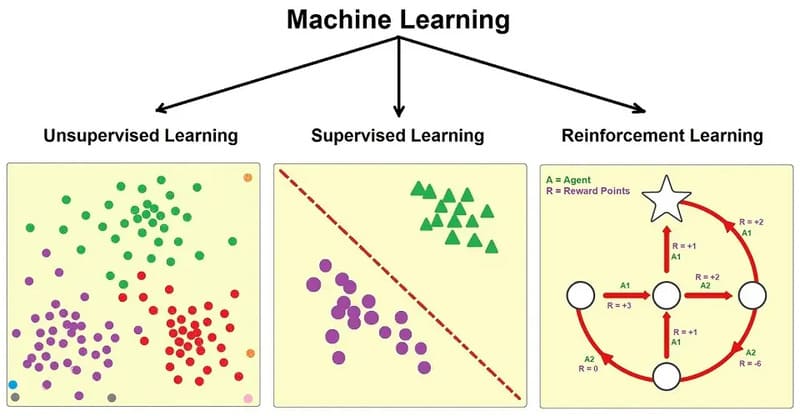
Học có giám sát so với học tăng cường
Supervised Learning và Reinforcement Learning là hai phương pháp học máy với cơ chế hoạt động khác nhau.
Supervised Learning sử dụng dữ liệu đã được gán nhãn để mô hình học mối quan hệ giữa đầu vào và đầu ra, từ đó đưa ra dự đoán chính xác trên dữ liệu mới. Phương pháp này phù hợp với các bài toán có mục tiêu rõ ràng và bộ dữ liệu huấn luyện đầy đủ.
Ngược lại, Reinforcement Learning không dựa trên dữ liệu gán nhãn sẵn. Thay vào đó, mô hình hoạt động như một “tác nhân” (agent) tương tác trực tiếp với môi trường. Thông qua cơ chế thử và sai, agent nhận phần thưởng hoặc hình phạt sau mỗi hành động, rồi điều chỉnh chiến lược để tối ưu hóa kết quả trong tương lai.
Khác với học không giám sát, Reinforcement Learning có cơ chế phản hồi rõ ràng dựa trên hệ thống thưởng – phạt để cải thiện hiệu suất theo thời gian.
Ví dụ: Trong nhận dạng chữ viết tay, Supervised Learning học từ tập dữ liệu chữ số đã gán nhãn để phân loại chính xác hình ảnh mới. Trong khi đó, với Reinforcement Learning, một robot học cách di chuyển bằng cách thử nhiều hành động khác nhau, nhận phản hồi về mức độ cân bằng và dần tối ưu chiến lược vận động của mình.
Reinforcement Learning thường được ứng dụng trong robot tự động, xe tự lái hoặc hệ thống ra quyết định phức tạp. Ngược lại, Supervised Learning phù hợp hơn với các bài toán dự đoán và phân loại có dữ liệu huấn luyện rõ ràng.
>>> XEM THÊM: Robotic Process Automation là gì? Các ứng dụng của RPA trong thực tiễn
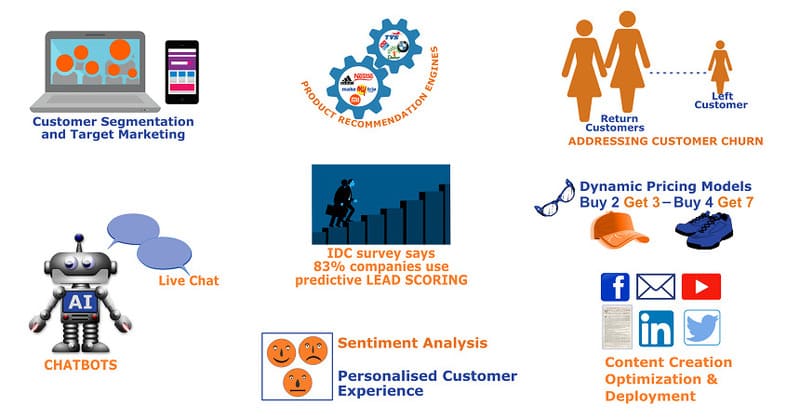
Các ứng dụng của Supervised Learning trong thực tế
Các mô hình học có giám sát có thể xây dựng và nâng cao các ứng dụng kinh doanh, bao gồm:
- Nhận diện hình ảnh và vật thể: Các thuật toán học có giám sát giúp xác định, khoanh vùng và phân loại đối tượng trong video hoặc hình ảnh, mang lại những tiến bộ quan trọng trong lĩnh vực thị giác máy tính (Computer Vision) và phân tích hình ảnh.
- Phân tích dự đoán: Mô hình Supervised Learning tạo ra các hệ thống phân tích có khả năng dự báo kết quả dựa trên dữ liệu đầu vào. Điều này giúp các nhà lãnh đạo doanh nghiệp đưa ra quyết định có cơ sở vững chắc, biện minh cho chiến lược của họ hoặc điều chỉnh kế hoạch vì lợi ích của tổ chức.
- Dự đoán y tế: Trong lĩnh vực chăm sóc sức khỏe, các mô hình hồi quy (Regression) giúp các nhà cung cấp dịch vụ dự đoán kết quả dựa trên tiêu chí bệnh nhân và dữ liệu lịch sử. Ví dụ, một mô hình dự đoán có thể đánh giá nguy cơ mắc bệnh cụ thể dựa trên dữ liệu sinh học và lối sống của bệnh nhân.
- Phân tích cảm xúc (Sentiment Analysis): Các tổ chức có thể tự động trích xuất và phân loại thông tin quan trọng từ khối lượng dữ liệu lớn, bao gồm ngữ cảnh, cảm xúc và ý định của khách hàng với sự can thiệp tối thiểu của con người. Kỹ thuật này mang lại sự hiểu biết sâu sắc về tương tác khách hàng, từ đó cải thiện chiến lược gắn kết thương hiệu.
- Phân khúc khách hàng: Các mô hình hồi quy có khả năng dự đoán hành vi của khách hàng dựa trên đặc điểm cá nhân và xu hướng lịch sử. Doanh nghiệp sử dụng những dự đoán này để phân nhóm cơ sở khách hàng và xây dựng chân dung người mua (Buyer Personas), nhằm tối ưu hóa nỗ lực tiếp thị và phát triển sản phẩm.
- Phát hiện thư rác: Supervised Learning được ứng dụng hiệu quả trong việc phân loại email. Thông qua các thuật toán phân loại có giám sát, hệ thống có thể nhận diện các mẫu hoặc bất thường trong dữ liệu mới, từ đó tự động sắp xếp và phân loại thư rác và thư hợp lệ một cách hiệu quả.
- Dự báo xu hướng: Các mô hình hồi quy đặc biệt xuất sắc trong việc dự báo dựa trên dữ liệu lịch sử, làm cho chúng trở nên lý tưởng trong ngành tài chính. Ngoài ra, doanh nghiệp còn sử dụng chúng để dự đoán nhu cầu hàng tồn kho, ước tính lương nhân viên và phòng tránh các trục trặc tiềm ẩn trong chuỗi cung ứng.
- Công cụ đề xuất: Với Supervised Learning, các nền tảng nội dung và thị trường trực tuyến có thể phân tích lựa chọn, sở thích và hành vi mua sắm của khách hàng để xây dựng hệ thống gợi ý thông minh. Những công cụ này cung cấp các đề xuất phù hợp có khả năng chuyển đổi cao hơn, nâng cao trải nghiệm người dùng và tăng doanh thu.
Thách thức của học có giám sát là gì?
Mặc dù Supervised Learning có thể mang lại cho doanh nghiệp những lợi thế như thông tin chi tiết dữ liệu sâu sắc và tự động hóa cải tiến, nhưng nó có thể không phải là lựa chọn tốt nhất cho tất cả các tình huống. Dưới đây là những thách thức chính của học có giám sát:
- Yêu cầu thời gian: Tập dữ liệu đào tạo lớn thường phải được gắn nhãn thủ công, khiến quá trình học có giám sát trở nên tốn thời gian. Việc chuẩn bị dữ liệu có thể chiếm phần lớn thời gian và công sức trong toàn bộ quá trình phát triển mô hình.
- Sự tham gia của con người: Các mô hình học có giám sát không có khả năng tự học hoàn toàn. Các nhà khoa học dữ liệu phải liên tục xác nhận đầu ra và hiệu suất của mô hình, điều này làm tăng chi phí vận hành và phụ thuộc vào nguồn nhân lực.
- Hạn chế về nhân sự: Việc phát triển và triển khai mô hình học có giám sát đòi hỏi mức độ chuyên môn nhất định để cấu trúc chính xác. Tìm kiếm nhân sự có kỹ năng phù hợp có thể là thách thức đối với nhiều tổ chức.
- Thiên kiến trong dữ liệu: Tập dữ liệu huấn luyện có nguy cơ cao chứa đựng lỗi và thiên kiến của con người, dẫn đến thuật toán học không chính xác. Thiên kiến này có thể được nhân rộng và khuếch đại trong quá trình đào tạo mô hình.
- Quá khớp (Overfitting): Học có giám sát dễ dẫn đến hiện tượng quá khớp khi mô hình trở nên quá phù hợp với tập dữ liệu đào tạo nhưng lại kém hiệu quả trong thực tế. Để tránh quá khớp, mô hình cần được kiểm tra với dữ liệu khác với dữ liệu đào tạo.
- Thiếu linh hoạt: Các mô hình học có giám sát thường gặp khó khăn trong việc gán nhãn dữ liệu nằm ngoài ranh giới của tập dữ liệu đào tạo. Trong khi đó, một mô hình học không giám sát có thể có khả năng xử lý dữ liệu mới tốt hơn trong nhiều trường hợp.
- Khả năng tổng quát hóa hạn chế: Mô hình hoạt động kém hiệu quả khi gặp dữ liệu mới, đặc biệt khi dữ liệu huấn luyện không đủ đa dạng.
Tóm lại, học có giám sát đã chứng minh giá trị vượt trội trong việc tạo ra các mô hình dự đoán chính xác dựa trên dữ liệu đã được gán nhãn. Trong tương lai, Explainable AI sẽ giúp các mô hình Supervised Learning trở nên minh bạch hơn, tăng cường niềm tin của người dùng và mở rộng phạm vi ứng dụng trong các lĩnh vực nhạy cảm như y tế và tài chính.
>>> XEM THÊM: