Text Preprocessing là một bước quan trọng trong xử lý ngôn ngữ tự nhiên (NLP), giúp tạo ra dữ liệu văn bản sạch và nhất quán để tối ưu hóa hiệu suất mô hình. Trong bài viết này, FPT.AI sẽ giới thiệu với bạn về các kỹ thuật tiền xử lý văn bản quan trọng như loại bỏ ký tự thừa, chuẩn hóa ngôn ngữ và mã hóa văn bản. Đọc ngay để khai thác tối đa tiềm năng của dữ liệu ngôn ngữ tự nhiên trong các ứng dụng thực tế.
Tại sao Text Preprocessing lại quan trọng?
Dữ liệu văn bản thô thường chứa nhiều yếu tố không nhất quán như lỗi đánh máy, từ viết tắt, tiếng lóng và thông tin không liên quan. Text Preprocessing, hay tiền xử lý văn bản, là một bước trong quá trình xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP) giúp loại bỏ các yếu tố gây nhiễu này để tạo ra một tập dữ liệu sạch, nhất quán, dễ tiếp cận và có cấu trúc rõ ràng hơn cho các mô hình học máy (Machine Learning)
Nhờ vậy, các mô hình xử lý ngôn ngữ tự nhiên có thể tập trung vào những yếu tố quan trọng mà không bị ảnh hưởng bởi thông tin thừa. Điều này cải thiện độ chính xác và hiệu suất của mô hình khi phân tích và hiểu ngữ nghĩa văn bản, đồng thời tiết kiệm tài nguyên xử lý.
Các kỹ thuật Text Preprocessing (tiền xử lý văn bản) trong NLP
Các kỹ thuật tiền xử lý văn bản (Text Preprocessing) quan trọng trong NLP bao gồm:
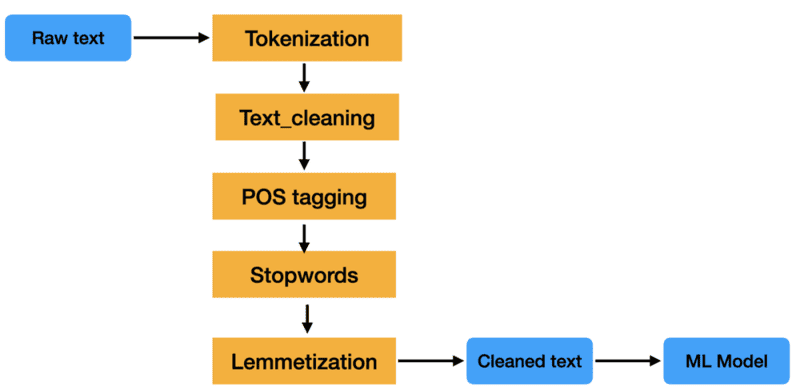
Loại bỏ các thẻ HTML (Remove HTML Tags)
Trong nhiều trường hợp, văn bản thu thập từ web có chứa các thẻ HTML chỉ dùng để định dạng hoặc truyền tải thông tin ngoài ngữ nghĩa của văn bản. Loại bỏ các thẻ HTML giúp làm sạch dữ liệu và tập trung vào nội dung văn bản thực sự. Điều này rất cần thiết khi làm việc với các tập dữ liệu chứa HTML, chẳng hạn như ý kiến khách hàng hoặc bài viết trên trang web, giúp giảm thiểu nhiễu và nâng cao độ chính xác trong phân tích văn bản.
Xoá bỏ các URL không liên quan (Remove URLs)
URL trong văn bản thường không có ý nghĩa ngữ nghĩa và có thể gây nhiễu trong quá trình phân tích. Việc loại bỏ chúng giúp dữ liệu tập trung vào các phần có giá trị phân tích thực sự. Điều này rất hữu ích trong phân tích văn bản chứa nhiều liên kết không liên quan đến nội dung, chẳng hạn các bình luận hoặc nhận xét trực tuyến có chứa đường dẫn đến các trang khác.
Xoá các dấu câu (Remove Punctuations)
Dấu câu thường không mang nhiều giá trị khi phân tích văn bản trong các tác vụ như phân loại hoặc nhận diện thực thể. Bằng cách loại bỏ chúng, dữ liệu trở nên nhất quán và tập trung hơn vào từ ngữ chính. Kỹ thuật này phù hợp với các ứng dụng cần đơn giản hóa cấu trúc câu để mô hình dễ dàng nhận diện các từ và cụm từ quan trọng.
Viết thường các chữ hoa (LoweCasing Text)
Chuyển đổi văn bản về chữ thường trong Text Preprocessing là quá trình chuyển tất cả các ký tự thành chữ viết thường để giảm bớt sự phân biệt không cần thiết giữa các từ viết hoa và viết thường.
Kỹ thuật này giúp giảm kích thước từ vựng, đảm bảo tính nhất quán, và tăng cường hiệu quả của mô hình, đặc biệt hữu ích khi phân tích dữ liệu từ các nguồn có thể không đồng nhất về cách viết hoa chữ. Các ứng dụng phân tích cảm xúc và phân loại văn bản sẽ đặc biệt hưởng lợi từ bước này, vì chữ hoa và chữ thường thường không ảnh hưởng đến ngữ nghĩa.

Đánh dấu loại từ (Part of Speech – POS)
Kỹ thuật đánh dấu loại từ giúp gán nhãn từ vựng với các loại từ như danh từ, động từ, tính từ,… Điều này quan trọng trong Text Preprocessing vì loại từ ảnh hưởng lớn đến ý nghĩa câu. Ví dụ, từ “chạy” có thể là danh từ hoặc động từ tùy thuộc vào ngữ cảnh, và POS giúp làm rõ vai trò này trong câu, hỗ trợ các mô hình NLP hiểu được cấu trúc và ý nghĩa chính xác của câu.
Xử lý ChatWords (Handling ChatWords)
Trong giao tiếp trực tuyến, từ lóng và viết tắt thường được sử dụng. Chuyển các từ này về dạng chuẩn giúp mô hình hiểu đúng ý nghĩa ngôn ngữ và cải thiện chất lượng đầu vào. Đây là bước cần thiết khi phân tích văn bản từ mạng xã hội hoặc tin nhắn, nơi có rất nhiều từ viết tắt và từ lóng, giúp nâng cao độ chính xác và tính nhất quán trong phân tích.
Sửa lỗi chính tả (Spelling Correction)
Lỗi chính tả có thể làm giảm hiệu quả phân tích và gây nhiễu khi mô hình không nhận diện đúng từ ngữ. Sửa lỗi chính tả giúp đảm bảo dữ liệu đầu vào chính xác hơn, tạo điều kiện tốt cho mô hình học được các mẫu ngôn ngữ chuẩn. Kỹ thuật này đặc biệt hữu ích khi làm việc với các dữ liệu không chính thức hoặc dữ liệu từ người dùng trực tuyến.
Xử lý từ dừng (Handling StopWords)
Các từ dừng như “là”, “và” thường xuất hiện nhiều nhưng ít mang ý nghĩa ngữ nghĩa. Loại bỏ chúng trong Text Preprocessing giúp tập trung vào các từ quan trọng hơn, từ đó cải thiện độ chính xác trong phân tích. Phương pháp này phù hợp với các tác vụ cần tập trung vào nội dung chính như phân tích chủ đề hoặc từ khóa.

Xử lý các biểu tượng cảm xúc (Handling Emojies)
Biểu tượng cảm xúc mang thông tin về cảm xúc và ngữ cảnh của người dùng, đặc biệt phổ biến trong các bài đăng trực tuyến. Text Preprocessing chuyển biểu tượng cảm xúc sang dạng văn bản, giúp mô hình hiểu rõ hơn về ý nghĩa và cảm xúc. Kỹ thuật này rất có giá trị trong phân tích cảm xúc hoặc nhận diện cảm xúc từ các nền tảng mạng xã hội.
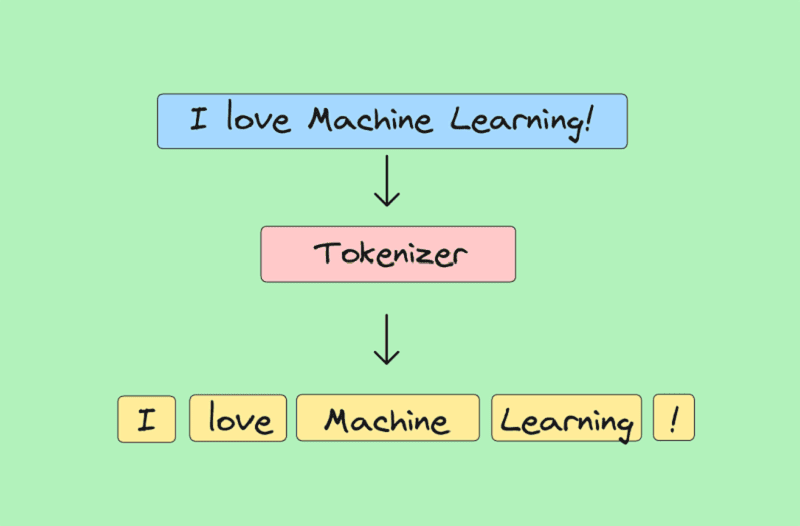
Mã hoá (Tokenization)
Mã hóa văn bản giúp chia văn bản thành các đơn vị nhỏ hơn như từ hoặc câu, tạo điều kiện cho mô hình xử lý từng thành phần riêng lẻ. Điều này đặc biệt cần thiết cho các tác vụ trích xuất đặc trưng và mô hình hóa ngôn ngữ trong NLP, như phân loại văn bản và phân tích câu.
Phân loại từ nguyên (Stemming)
Stemming trong Text Preprocessing là kỹ thuật đưa các từ về gốc mà không quan tâm đến ngữ pháp. Kỹ thuật này giúp giảm sự biến thể của từ và đơn giản hóa dữ liệu, hữu ích trong các ứng dụng tìm kiếm hoặc phân loại văn bản khi không cần quá chú trọng ngữ nghĩa của từng từ.
Cắt nghĩa (Lemmatization)
Khác với Stemming, Lemmatization đưa từ về dạng gốc theo từ điển, giữ nguyên ý nghĩa ngữ pháp của từ. Phương pháp này hỗ trợ các tác vụ phân tích ngữ nghĩa cần độ chính xác cao, như tìm kiếm thông tin hoặc phân tích ngữ nghĩa.
FPT AI Chat – AI Chatbot có kỹ thuật Text Preprocessing tiếng Việt hiện đại
FPT AI Chat là AI chatbot do FPT Smartcloud – Công ty tiên phong về Trí tuệ nhân tạo (AI) và Điện toán đám mây (Computing Cloud) tại Việt Nam đầu tư phát triển. Với khả năng hiểu và xử lý yêu cầu một cách chính xác, FPT AI Chat là giải pháp lý tưởng để các doanh nghiệp duy trì giao tiếp nhất quán và chất lượng với khách hàng, nâng cao hiệu quả tiếp thị, bán hàng và chăm sóc khách hàng một cách toàn diện.

FPT AI Chat được trang bị các kỹ thuật xử lý ngôn ngữ tự nhiên (NLP) chuyên sâu cho tiếng Việt, cho phép hệ thống tiền xử lý văn bản tiếng Việt một cách toàn diện và tối ưu. Chatbot này chuẩn hóa dữ liệu đầu vào một cách chính xác và nhất quán, dễ dàng nhận diện và phân tích nội dung chính xác, ngay cả khi gặp phải các từ viết tắt, từ lóng hay lỗi chính tả thường xuất hiện trong giao tiếp trực tuyến.
FPT AI Chat đảm bảo rằng dữ liệu tiếng Việt từ khách hàng sẽ được làm sạch và chuẩn hóa, giúp nâng cao hiệu suất phân tích ngôn ngữ và giảm thiểu sai lệch trong quá trình xử lý. Giải pháp không chỉ cải thiện hiệu quả giao tiếp và hỗ trợ khách hàng một cách mượt mà mà còn giúp doanh nghiệp giảm tải công việc và gia tăng sự hài lòng của khách hàng trong các tương tác ngôn ngữ tự nhiên.
Bên cạnh đó, AI chatbot này còn tích hợp công nghệ AI tạo sinh và dễ dàng với các hệ thống nội bộ hiện có của doanh nghiệp và các nền tảng nhắn tin phổ biến như Facebook Messenger, Zalo và website thông qua API. Nhờ đó, doanh nghiệp không chỉ mở rộng phạm vi tiếp cận mà còn tối ưu hóa trải nghiệm khách hàng một cách cá nhân hóa và chuyên nghiệp.
Để tìm hiểu thêm hoặc nhận hỗ trợ tư vấn, vui lòng truy cập website: FPT.AI hoặc liên hệ qua hotline: 1900 638 399 và Email: support@fpt.ai.
Với các kỹ thuật Text Preprocessing trên, quá trình xử lý ngôn ngữ tự nhiên trở nên hiệu quả hơn khi dữ liệu được chuẩn hóa và tối ưu hóa. Điều này giúp mô hình NLP dễ dàng khai thác các đặc trưng ngôn ngữ quan trọng mà không bị ảnh hưởng bởi nhiễu, từ đó cải thiện đáng kể độ chính xác và tốc độ xử lý. Hy vọng, qua bài viết này của FPT.AI, bạn đã hiểu rõ hơn về vai trò của Text Preprocessing cũng như các bước tiền xử lý cần thiết cho dữ liệu văn bản.
>>> TÌM HIỂU THÊM: