Trong thời đại trí tuệ nhân tạo phát triển mạnh mẽ, NLP đang đóng vai trò quan trọng trong việc giao tiếp giữa con người và máy tính, giúp máy tính có thể “hiểu” được ngôn ngữ tự nhiên của con người. Vậy cụ thể NLP là gì? Ứng dụng của xử lý ngôn ngữ tự nhiên là gì? Cùng FPT.AI tìm hiểu chi tiết qua bài viết sau!
NLP là gì?
NLP (Natural Language Processing – Xử lý ngôn ngữ tự nhiên) là một nhánh của trí tuệ nhân tạo (AI) cho phép máy tính hiểu, phân tích, xử lý và tạo ra ngôn ngữ của con người dưới dạng văn bản và giọng nói một cách tự nhiên.
Hiện nay, NLP được ứng dụng rộng rãi trong nhiều lĩnh vực như chatbot và trợ lý ảo, dịch máy, tóm tắt văn bản, phân tích cảm xúc, tìm kiếm thông minh và xử lý dữ liệu. Đây chính là nền tảng giúp doanh nghiệp và hệ thống AI khai thác hiệu quả khối lượng lớn dữ liệu ngôn ngữ trong thời đại số.

Cách hoạt động của NLP (Xử lý ngôn ngữ tự nhiên)
Xử lý ngôn ngữ tự nhiên (NLP) kết hợp ngôn ngữ học tính toán (Computational Linguistics) với máy học (Machine Learning) và học sâu (Deep Learning) để giải quyết các bài toán như dịch máy, tóm tắt văn bản, nhận dạng giọng nói, chatbot, phân tích cảm xúc và tìm kiếm thông minh.
Dưới đây là quy trình chi tiết cách hoạt động của Xử lý ngôn ngữ tự nhiên:
Tiền xử lý văn bản (Text Preprocessing)
Trước khi tiến hành phân tích, cần thực hiện bước chuẩn bị dữ liệu thô và chuyển đổi văn bản thành định dạng dễ hiểu hơn cho máy tính bước này gọi là tiền xử lý văn bản (Text Preprocessing). Quá trình tiền xử lý văn bản bao gồm:
- Tách từ, tách câu: Chia văn bản thành các đơn vị nhỏ như từ, cụm từ hoặc câu rõ ràng, giúp máy tính dễ dàng phân tích cấu trúc ngữ nghĩa.
- Chuyển chữ hoa thành chữ thường: Chuyển đổi tất cả các từ ngữ thành chữ thường để giảm sự phức tạp của văn bản. Ví dụ: “Smile” sẽ được chuyển thành “smile”.
- Loại bỏ các từ khóa không mang nhiều thông tin có giá trị khi phân tích ngữ nghĩa hoặc khi xử lý văn bản như “và”, “của”, “là”, “trong”, “để”, “với”… và xóa các ký tự đặc biệt, dấu câu… không cần thiết.
- Rút gọn từ ngữ về dạng gốc: Là các phương pháp chuẩn hóa từ, giúp máy tính nhận diện các dạng biến thể của từ (ví dụ: “chạy”, “chạy nhanh” sẽ trở thành “chạy”).
Chuyển văn bản thành dữ liệu số
Bước tiếp theo chính là chuyển văn bản thành dữ liệu số (trích xuất đặc trưng) để máy tính có thể phân tích và hiểu được.
Một cách đơn giản để phân tích văn bản là đếm số lần các từ xuất hiện, đây là nền tảng của các phương pháp như Bag of Words và TF-IDF, giúp máy tính nhận diện từ nào xuất hiện nhiều và từ nào quan trọng. Ngoài ra, phương pháp nâng cao hơn là sử dụng kỹ thuật word embeddings như Word2Vec hoặc GloVe.
Những kỹ thuật này không chỉ chuyển đổi từ thành các con số, mà còn giữ lại ý nghĩa và mối quan hệ giữa các từ. Ví dụ, các từ như “thầy giáo” – “học sinh” hay “cha mẹ” – “con cái” sẽ có mối liên hệ rõ ràng trong không gian số, giúp máy hiểu được các kết nối ngữ nghĩa giữa chúng.
Hiện nay, đã có những kỹ thuật tiên tiến hơn như ngữ cảnh hóa từ, giúp máy tính hiểu được nghĩa cụ thể của một từ tùy theo ngữ cảnh. Ví dụ, từ “bank” trong cụm từ “bờ sông” sẽ mang nghĩa khác hoàn toàn so với “ngân hàng”.

Phân tích văn bản
Đây là quá trình máy có thể “hiểu” và khai thác thông tin từ văn bản bằng các tác vụ như:
- Phân tích cú pháp (Parsing): Xác định cấu trúc ngữ pháp của câu, giúp máy hiểu mối quan hệ giữa các từ trong câu như chủ ngữ, vị ngữ và các thành phần khác.
- Phân loại câu (Sentence Classification): Dựa trên ngữ nghĩa của câu, máy sẽ phân loại câu đó là câu hỏi, câu khẳng định, câu mệnh lệnh, v.v.
- Nhận dạng thực thể (Named Entity Recognition – NER): Xác định các thực thể quan trọng trong văn bản như tên người, tổ chức, địa điểm, ngày tháng,…
- Phân tích cảm xúc (Sentiment Analysis): Xác định cảm xúc của người nói hoặc người viết trong văn bản (tích cực, tiêu cực, trung tính).
- Xử lý đồng nghĩa và đa nghĩa (Word Sense Disambiguation): Giải quyết các vấn đề về từ đa nghĩa trong ngữ cảnh, như từ “bank” có thể mang nghĩa “ngân hàng” hoặc “bờ sông”.
Đào tạo mô hình
Khi dữ liệu đã được chuẩn hóa và chuyển thành dạng số, các mô hình học máy sẽ được huấn luyện để hiểu và dự đoán từ các văn bản. Trong quá trình này, máy sẽ phân tích dữ liệu cũ để rút ra các quy tắc, từ đó tạo ra các phản hồi cho văn bản mới. Đồng thời, mô hình cũng có khả năng tự đánh giá và điều chỉnh để giảm thiểu sai sót, nâng cao độ chính xác trong các kết quả dự đoán.
Để thực hiện các bước trong xử lý ngôn ngữ tự nhiên (NLP), một số công cụ phần mềm phổ biến bao gồm:
- NLTK (Natural Language Toolkit): Đây là một thư viện nổi tiếng trong Python, giúp thực hiện các tác vụ như phân loại văn bản, tách từ, gán nhãn từ loại, phân tích cú pháp câu và nhận diện nghĩa của từ trong ngữ cảnh.
- TensorFlow: Được phát triển bởi Google, TensorFlow là thư viện mã nguồn mở dành cho học máy và trí tuệ nhân tạo (AI), hỗ trợ việc xây dựng và huấn luyện các mô hình NLP hiệu quả, đặc biệt trong các ứng dụng liên quan đến phân tích văn bản.

Lợi ích của NLP (Xử lý ngôn ngữ tự nhiên) là gì?
NLP mang lại những lợi ích nổi bật trong các hoạt động hàng ngày của doanh nghiệp và cá nhân. Các lợi ích nổi bật nhất của NLP (xử lý ngôn ngữ tự nhiên) bao gồm:
- Tự động hóa công việc lặp đi lặp lại: NLP giúp tự động hóa các tác vụ như hỗ trợ khách hàng qua chatbot, phân loại email, xử lý văn bản và nhập liệu, giúp tiết kiệm thời gian và giảm thiểu sai sót, cho phép nhân viên tập trung vào công việc sáng tạo và chiến lược hơn.
- Phân tích dữ liệu văn bản hiệu quả: Với khả năng xử lý lượng lớn văn bản không cấu trúc, NLP giúp doanh nghiệp khai thác thông tin từ các bài đánh giá, bài viết trên mạng xã hội và các nguồn dữ liệu khác. Nhờ đó, họ có thể hiểu rõ hơn về cảm nhận của khách hàng, xu hướng thị trường và các vấn đề tiềm ẩn.
- Cải thiện trải nghiệm người dùng: NLP cho phép các hệ thống hiểu và phản hồi theo ngữ cảnh, giúp nâng cao trải nghiệm người dùng. Ví dụ, các công cụ tìm kiếm sử dụng NLP để hiểu ý định của người dùng, cung cấp kết quả chính xác hơn, ngay cả khi câu hỏi không rõ ràng.
- Tạo nội dung một cách tự động và mạch lạc: Xử lý ngôn ngữ tự nhiên có thể tạo ra văn bản tự động và mạch lạc từ dữ liệu có cấu trúc, hỗ trợ các công việc như viết báo cáo, mô tả sản phẩm hoặc tài liệu tiếp thị. Các công cụ NLP hỗ trợ người dùng soạn thảo nội dung một cách nhanh chóng, vẫn giữ được giọng điệu, phong cách và ngữ cảnh phù hợp với mục tiêu giao tiếp, đồng thời giảm gánh nặng cho các nhóm sáng tạo nội dung.
- Tăng khả năng tương tác tự nhiên với công nghệ: NLP là nền tảng cho các trợ lý ảo như Siri, Alexa hay chatbot Generative AI. Thay vì phải sử dụng câu lệnh cố định, người dùng có thể giao tiếp bằng ngôn ngữ thường ngày. NLP giúp máy hiểu được cả các yếu tố ngữ cảnh và giọng điệu, từ đó đưa ra phản hồi chính xác hơn. Điều này không chỉ làm cho công nghệ trở nên thân thiện hơn mà còn giúp nâng cao trải nghiệm người dùng.
- Mở rộng khả năng phân tích và ra quyết định dựa trên dữ liệu: NLP cho phép các tổ chức truy cập và phân tích khối lượng lớn dữ liệu phi cấu trúc mà trước đây bị bỏ qua do giới hạn về công cụ. Nhờ đó, doanh nghiệp có thể hiểu rõ hơn về khách hàng tiềm năng, phản hồi trên mạng xã hội, khảo sát hay đánh giá sản phẩm – từ đó đưa ra quyết định chiến lược dựa trên dữ liệu một cách chính xác và nhanh chóng hơn.

Các phương pháp tiếp cận xử lý ngôn ngữ tự nhiên (NLP)
Ba cách tiếp cận khác nhau đối với Natural Language Processing – xử lý ngôn ngữ tự nhiên bao gồm:
NLP dựa trên quy tắc (Rules-based NLP)
Rules-based NLP là phương pháp cơ bản trong xử lý ngôn ngữ tự nhiên, sử dụng các quy tắc “nếu – thì” được lập trình thủ công. Hệ thống này có thể tạo ra phản hồi đơn giản dựa trên các mẫu câu đã được xác định trước. Tuy nhiên, vì không có khả năng học hỏi từ dữ liệu hay ngữ cảnh, Rules-based NLP chỉ hiệu quả trong các tình huống đã được lập trình sẵn và khó mở rộng để xử lý các tình huống mới.
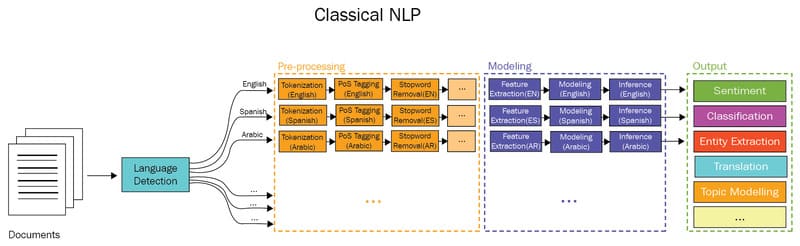
NLP thống kê (Statistical NLP)
Xử lý ngôn ngữ tự nhiên thống kê đánh dấu bước chuyển từ lập trình thủ công sang học máy (Machine Learning), cho phép hệ thống tự động trích xuất, phân loại và gán nhãn các thành phần trong văn bản hoặc giọng nói, đồng thời gán xác suất cho các ý nghĩa khác nhau. Trong phương pháp này, các phương pháp thống kê như hồi quy hay mô hình Markov có thể được áp dụng để phân tích ngôn ngữ, chuyển đổi từ và ngữ pháp thành các biểu diễn toán học (vector). Statistical NLP là nền tảng cho những ứng dụng kiểm tra chính tả hoặc hệ thống gõ T9 texting (Text on 9 keys, để sử dụng trên điện thoại Touch-Tone).
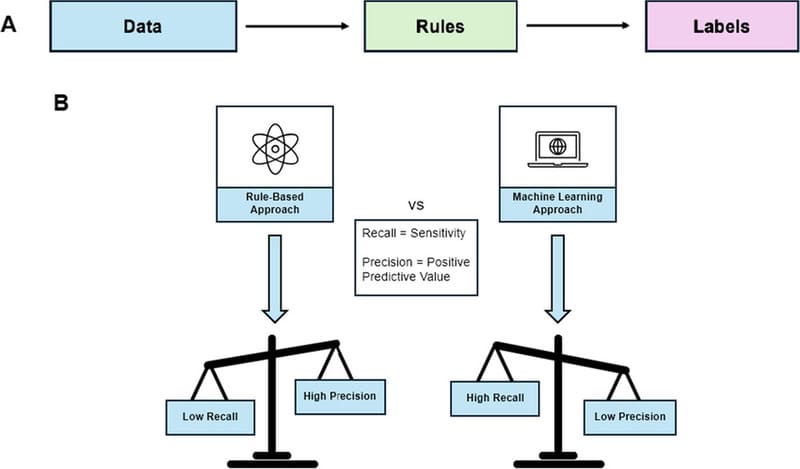
NLP học sâu (Deep Learning NLP)
Ngày nay, học sâu (Deep Learning), đặc biệt là deep neural networks (DNN), là phương pháp chiếm ưu thế trong xử lý ngôn ngữ tự nhiên, giúp các hệ thống đạt được độ chính xác và linh hoạt vượt trội. Khác với Statistical NLP, Deep Learning NLP sử dụng mạng nơ-ron (neural networks) để học trực tiếp từ khối lượng rất lớn dữ liệu văn bản và giọng nói không có cấu trúc (thường là hàng gigabyte).
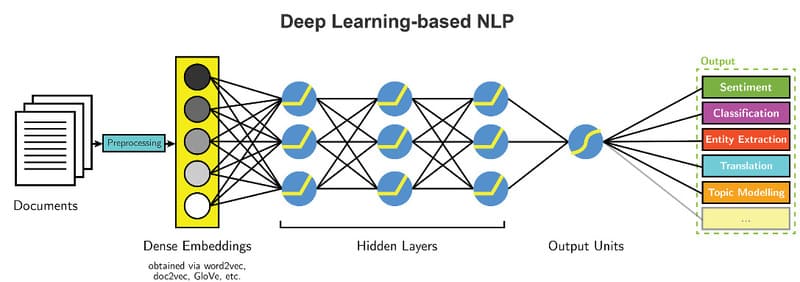
Ngoài ra, ngày nay, để tiết kiệm thời gian tài nguyên đào tạo, các doanh nghiệp đang đẩy mạnh tinh chỉnh (Fine Tuning) các mô hình pretrained cho các nhiệm vụ cụ thể thông qua phương pháp Transfer Learning. Điều này làm cho việc triển khai các mô hình Deep Learning trở nên dễ dàng và nhanh chóng hơn, cho phép áp dụng NLP vào nhiều tình huống khác nhau.
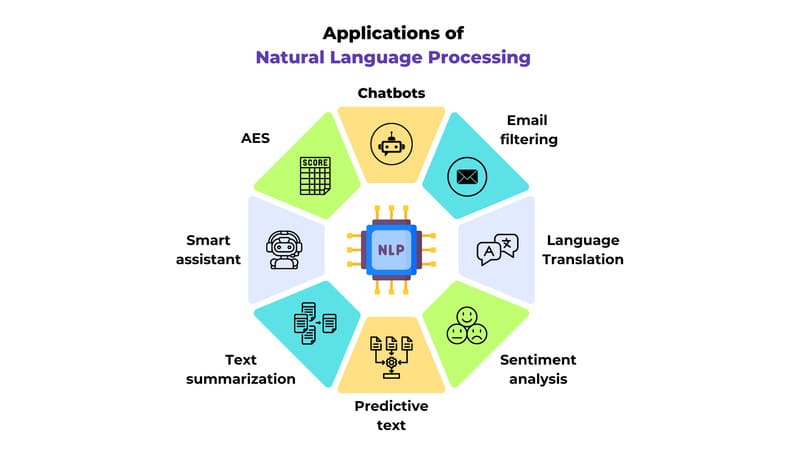
Ứng dụng thực tế của NLP (Xử lý ngôn ngữ tự nhiên):
Xử lý ngôn ngữ tự nhiên (NLP) được ứng dụng rộng rãi trong nhiều lĩnh vực thực tế, từ chatbot, tìm kiếm thông minh đến phân tích dữ liệu văn bản, giúp máy tính hiểu và xử lý ngôn ngữ con người hiệu quả hơn. Các ứng dụng nổi bật của NLP có thể kể đến như:
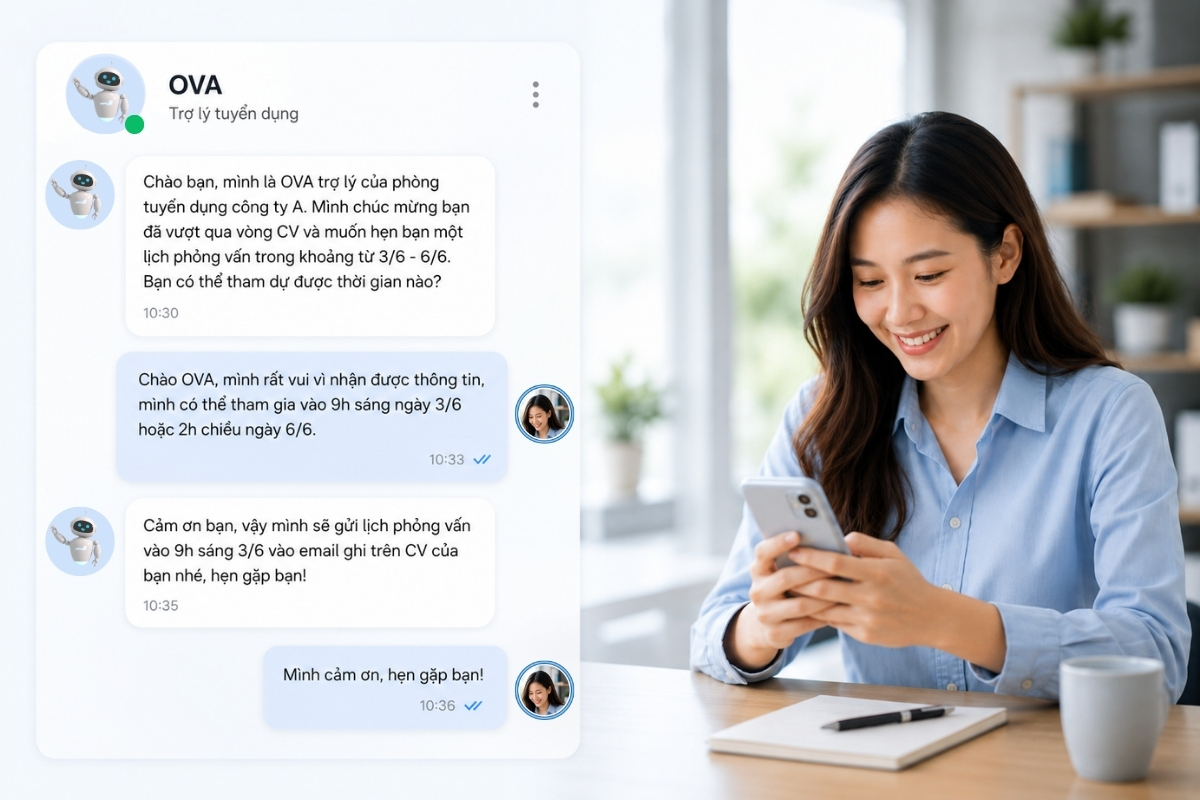
- Chatbot & trợ lý ảo: Hiểu và trả lời câu hỏi người dùng bằng ngôn ngữ tự nhiên. Trả lời đúng ngữ cảnh hội thoại, thường được áp dụng trong CSKH và bán hàng.
- Phân tích cảm xúc (Sentiment Analysis): Dùng để xác định cảm xúc tích cực, tiêu cực hoặc trung lập trong văn bản. Thường dùng để phân tích đánh giá, phản hồi của khách hàng và trên mạng xã hội.
- Language Translation (Dịch ngôn ngữ): NLP được sử dụng để dịch văn bản giữa các ngôn ngữ khác nhau một cách tự động. Được ứng dụng trong website đa ngôn ngữ
- Predictive Text (Dự đoán văn bản): Dùng để dự đoán từ, cụm từ hoặc câu tiếp theo dựa trên nội dung người dùng đã nhập và ngữ cảnh xung quanh.
- Text Summarization (Tóm tắt văn bản): NLP rút gọn nội dung dài thành bản tóm tắt ngắn gọn, dễ hiểu và giữ lại ý chính. Áp dụng trong báo cáo, tin tức.
- Smart Assistant (Trợ lý thông minh): NLP giúp trợ lý ảo hiểu lệnh hoặc văn bản được nhận và thực hiện chính xác yêu cầu của người dùng.
- AES (Automated Essay Scoring – Chấm điểm tự động): NLP được dùng để đánh giá, chấm điểm bài viết hoặc bài luận dựa trên nội dung và ngôn ngữ.
- Email filtering (Lọc email): NLP giúp người dùng phân loại email như spam, quảng cáo hoặc email quan trọng dựa trên nội dung văn bản.
- Nhận dạng giọng nói (Speech Recognition): Giúp nhận dạng ngôn ngữ tự nhiên và chuyển văn bản thành giọng nói.
- Named Entity Recognition (NER): Giúp nhận diện và trích xuất tên người, công ty, địa điểm, ngày tháng được đề cập trong văn bản.
Nhược điểm của xử lý ngôn ngữ tự nhiên (Natural Language Processing)
Xử lý ngôn ngữ tự nhiên (NLP) đối mặt với nhiều thách thức lớn, đặc biệt khi xử lý ngôn ngữ con người, vốn rất phức tạp và mơ hồ. Dưới đây là nhược điểm mà NLP đang gặp phải:
- Các mô hình NLP hiện đại vẫn không hoàn hảo: Điều này nhấn mạnh rằng, giống như ngôn ngữ con người, NLP cũng dễ bị nhầm lẫn và không thể tránh khỏi sai sót.
- Thiên lệch trong huấn luyện (Biased training): Sự thiên lệch trong dữ liệu huấn luyện sẽ ảnh hưởng đến độ chính xác của các kết quả trả về, điều này đặc biệt quan trọng khi ứng dụng NLP trong các dịch vụ công, y tế và nhân sự.
- Nguy cơ hiểu sai (Misinterpretation): Mô hình NLP có thể gặp khó khăn trong việc nhận diện ngữ nghĩa chính xác, đặc biệt khi xử lý tiếng địa phương, từ lóng, hay ngữ pháp sai.
- Từ vựng mới và sự phát triển ngôn ngữ: Xử lý ngôn ngữ tự nhiên gặp khó khăn trong việc thích ứng với từ mới và sự thay đổi của ngữ pháp, khiến các ứng dụng khó chính xác trong thời gian dài.
- Giọng điệu và ngữ điệu: NLP gặp khó khăn trong việc hiểu đúng nghĩa khi giọng điệu hoặc ngữ điệu thay đổi, chẳng hạn như mỉa mai, phóng đại hay nhấn mạnh từ.

Các thư viện hỗ trợ xử lý ngôn ngữ tự nhiên
Đại đa số các dự án xử lý ngôn ngữ tự nhiên được phát triển bằng Python vì môi trường phát triển tương tác của Python tích hợp (IDE) và các công cụ mạnh mẽ giúp dễ dàng phát triển và kiểm tra mã mới. Ngoài ra, để xử lý lượng dữ liệu lớn, R, C++ và Java cũng khá được ưa chuộng.
Các thư viện hỗ trợ NLP nổi bật bao gồm:
- TensorFlow và PyTorch: Đây là hai thư viện Deep Learning phổ biến nhất, được phát triển chủ yếu bằng Python. Chúng hỗ trợ nhiều ngôn ngữ khác nhau nhưng vẫn ưu tiên Python. Cả hai thư viện này cung cấp một lượng lớn các thành phần có sẵn, giúp giảm bớt sự phức tạp khi xây dựng các mô hình NLP phức tạp. Chúng còn hỗ trợ cơ sở hạ tầng điện toán hiệu suất cao như GPU, giúp tăng tốc quá trình huấn luyện và triển khai các mô hình NLP.
- AllenNLP: Đây là thư viện được triển khai trên nền PyTorch và Python, cung cấp các thành phần NLP cấp cao, như các chatbot đơn giản. AllenNLP nổi bật với tài liệu hướng dẫn chi tiết và dễ sử dụng, làm cho việc phát triển các ứng dụng NLP trở nên thuận tiện và nhanh chóng.
- HuggingFace: HuggingFace phân phối các mô hình Deep Learning đã được huấn luyện sẵn và cung cấp các công cụ plug-and-play trong TensorFlow và PyTorch. Điều này giúp các nhà phát triển dễ dàng áp dụng các mô hình NLP cho các nhiệm vụ cụ thể mà không cần phải huấn luyện từ đầu, rút ngắn thời gian phát triển và thử nghiệm các mô hình NLP mới.
- Spark NLP: Là một thư viện mã nguồn mở hỗ trợ các ngôn ngữ như Python, Java và Scala, Spark NLP được thiết kế để xử lý các tác vụ NLP nâng cao. Thư viện này cung cấp các mô hình neural network, pipeline xử lý ngôn ngữ và embeddings đã được huấn luyện sẵn. Nó cũng hỗ trợ việc đào tạo mô hình tùy chỉnh, giúp phát triển các ứng dụng NLP phù hợp với yêu cầu cụ thể.
- SpaCy: Là một thư viện mã nguồn mở miễn phí, SpaCy được tối ưu hóa cho NLP nâng cao và được xây dựng trên nền Python. SpaCy hỗ trợ hơn 66 ngôn ngữ, có khả năng xử lý khối lượng văn bản lớn và được thiết kế rất trực quan. Đây là công cụ tuyệt vời để xây dựng các ứng dụng NLP thông thường, từ phân tích cú pháp, nhận dạng thực thể đến phân loại văn bản.
- NLTK (Natural Language Toolkit): Đây là một bộ công cụ mã nguồn mở trong Python, cung cấp các thư viện và tài nguyên để thực hiện các tác vụ NLP cơ bản và nâng cao. NLTK bao gồm các công cụ để phân tích cú pháp câu, phân đoạn từ, stemming, lemmatization, tokenization và suy luận ngữ nghĩa, giúp các nhà phát triển dễ dàng xây dựng và triển khai mô hình NLP.

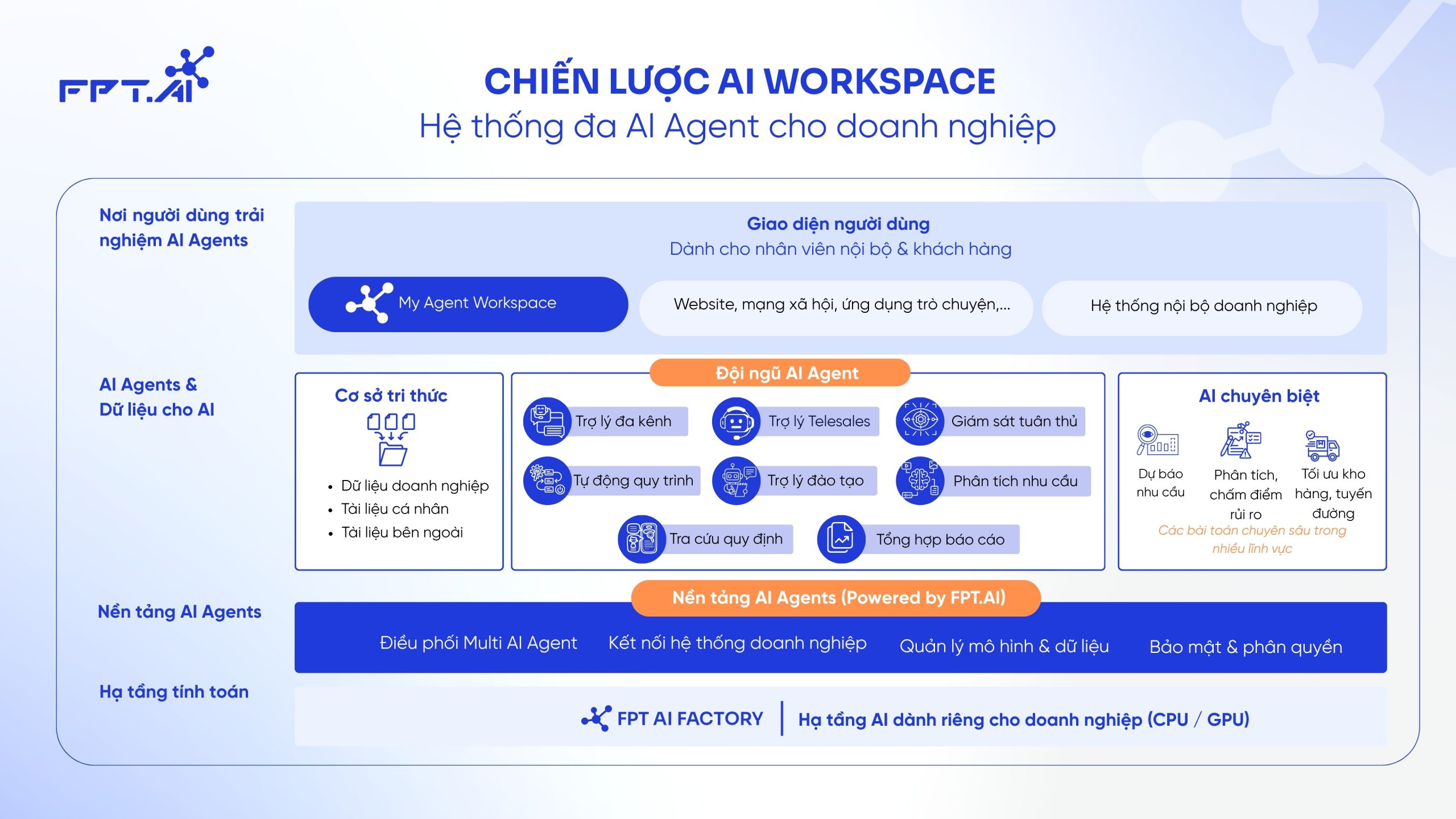
Các sản phẩm AI của FPTAI ứng dụng NLP giúp tối ưu hóa doanh nghiệp
FPT.AI là nền tảng công nghệ trí tuệ nhân tạo tiên tiến, phát triển bởi FPT, cung cấp các giải pháp AI toàn diện cho doanh nghiệp. Với mục tiêu tối ưu hóa hiệu suất và nâng cao trải nghiệm khách hàng, FPT.AI ứng dụng các công nghệ như Xử lý Ngôn ngữ Tự nhiên (NLP) trong nhiều sản phẩm và dịch vụ như:
- FPT AI Chat: Giải pháp chatbot đa kênh giúp tự động hóa các cuộc hội thoại, nâng cao hiệu quả chăm sóc khách hàng và giảm chi phí vận hành.
- FPT AI Engage: Voicebot tương tác hai chiều giúp doanh nghiệp tự động hóa quy trình tổng đài và tăng hiệu suất công việc, đồng thời cải thiện sự hài lòng của khách hàng.
- FPT AI Read: Giải pháp xử lý tài liệu thông minh với công nghệ OCR và NLP, giúp tự động trích xuất dữ liệu từ các tài liệu văn bản, nâng cao năng suất và giảm thiểu sai sót trong công việc.
Các sản phẩm này đang được ứng dụng rộng rãi tại nhiều ngành nghề, từ ngân hàng, bảo hiểm đến thương mại điện tử và chăm sóc khách hàng, đóng góp lớn vào việc chuyển đổi số cho doanh nghiệp. Liên hệ ngay FPT.AI qua hotline 1900 638 399 để khám phá ngay các giải pháp AI ứng dụng NLP, giúp thúc đẩy chuyển đổi số ai chatbot và nâng cao hiệu suất doanh nghiệp của bạn.

Tóm lại, xử lý ngôn ngữ tự nhiên là công nghệ cốt lõi cho phép máy tính hiểu và tương tác với ngôn ngữ con người một cách tự nhiên và hiệu quả. Thông qua các kỹ thuật từ đơn giản đến tiên tiến như rule-based, thống kê và học sâu, NLP ngày càng mở rộng ứng dụng thực tế trong dịch thuật, tìm kiếm thông tin, chăm sóc khách hàng, phân tích dữ liệu và nhiều lĩnh vực khác.
Nhờ sự phát triển mạnh mẽ của các mô hình tiên tiến và khả năng xử lý dữ liệu lớn, NLP ngày càng trở nên phổ biến và trở thành nền tảng của nhiều ứng dụng quen thuộc trong kỷ nguyên số như ChatGPT của OpenAI, Google Dịch, công cụ tìm kiếm web, trợ lý ảo (Siri, Alexa, Google Assistant), hệ thống GPS điều khiển bằng giọng nói, phần mềm chuyển giọng nói thành văn bản và chatbot dịch vụ khách hàng.
Liên hệ ngay với FPT.AI để biết thêm thông tin và nhận tư vấn miễn phí:
- Hotline: 1900 638 399.
- Website: www.fpt.ai.
- Địa chỉ: FPT Tower, 10 P. Phạm Văn Bạch, Dịch Vọng, Cầu Giấy, Hà Nội
- Hồ Chí Minh: tòa nhà PJICO, 186 Điện Biên Phủ, Phường Võ Thị Sáu, Quận 3