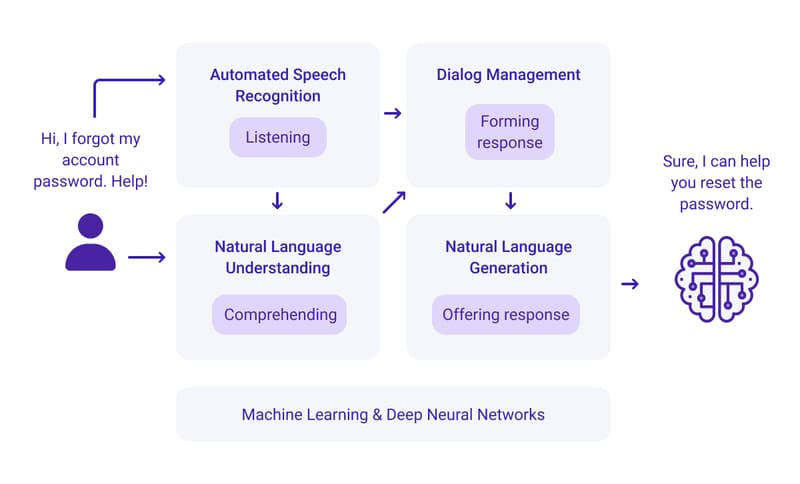
Hiểu ngôn ngữ tự nhiên (Natural Language Understanding – NLU) là một nhánh của trí tuệ nhân tạo tập trung vào việc giúp máy tính thấu hiểu hoàn toàn ý định, ngữ cảnh và ý nghĩa trong giao tiếp con người. Không dừng lại ở việc nhận diện đơn thuần từng từ riêng lẻ, NLU đi sâu phân tích những sắc thái phức tạp trong ngôn ngữ thông qua phân tích ngữ nghĩa và cú pháp, giúp máy tính vượt qua rào cản của ngôn ngữ con người vốn đầy tinh tế và luôn biến đổi.
Trong bài viết này, FPT.AI sẽ giúp bạn hiểu rõ về NLU thông qua việc so sánh NLU vs NLP (Xử lý ngôn ngữ tự nhiên) và NLG (Tạo ngôn ngữ tự nhiên), tìm hiểu cơ chế hoạt động cũng như các ứng dụng nổi bật và hạn chế của hiểu ngôn ngữ tự nhiên.
NLU là gì?
Hiểu ngôn ngữ tự nhiên (Natural Language Understanding – NLU) là một nhánh quan trọng của trí tuệ nhân tạo giúp máy tính nắm bắt trọn vẹn ý định, ngữ cảnh và ý nghĩa trong giao tiếp của con người. Thay vì chỉ nhận diện từng từ riêng biệt, NLU đào sâu vào những sắc thái phức tạp của ngôn ngữ thông qua phân tích ngữ nghĩa và cú pháp.

Ngôn ngữ con người vốn đầy rẫy những ý nghĩa tinh tế, phức tạp và luôn biến đổi. Đây chính là lý do NLU trở thành một thách thức học máy (Machine Learning) đầy khó khăn đối với các nhà khoa học máy tính và kỹ sư làm việc với các mô hình ngôn ngữ lớn (LLMs). Hệ thống NLU giúp máy tính vượt qua rào cản này bằng cách xử lý đa dạng yếu tố phức tạp trong ngôn ngữ như cấu trúc câu phức tạp, tiếng lóng, phương ngữ và các cách diễn đạt dễ gây nhầm lẫn.
NLU cho phép máy tính hiểu và phản hồi ngôn ngữ tự nhiên như tiếng Anh, tiếng Pháp hay tiếng Quan Thoại mà không cần cú pháp máy tính chính thức. Điều này mở ra khả năng trích xuất thông tin từ dữ liệu phi cấu trúc (như văn bản viết và ngôn ngữ nói), đồng thời tạo cầu nối giao tiếp cho những người dùng không có kiến thức lập trình.
Sự phát triển mạnh mẽ của AI tạo sinh đã thúc đẩy làn sóng đầu tư thương mại vào NLU, đặc biệt trong các ứng dụng như chatbot, dịch máy và trả lời câu hỏi. Chính NLU là nền tảng cốt lõi giúp các Generative AI chatbot như ChatGPT có thể tương tác một cách tự nhiên và chân thực với người dùng. Nếu không có NLU, những chatbot tương tác này có lẽ sẽ không thể tồn tại.
NLU mở ra khả năng đối thoại tự nhiên với máy tính thông qua các sản phẩm tiêu dùng và tính năng hiện đại như trợ lý giọng nói và chuyển giọng nói thành văn bản, khiến công nghệ trở nên thân thiện và dễ tiếp cận hơn với mọi người dùng, bất kể trình độ công nghệ của họ. Nhiều tập đoàn công nghệ lớn như Amazon, Apple, Google và Microsoft, cùng vô số công ty khởi nghiệp đang tích cực đầu tư vào nghiên cứu các mô hình ngôn ngữ và dự án NLU.

>>> XEM THÊM: Cách tạo chatbot đa kênh dễ dàng, thuận tiện
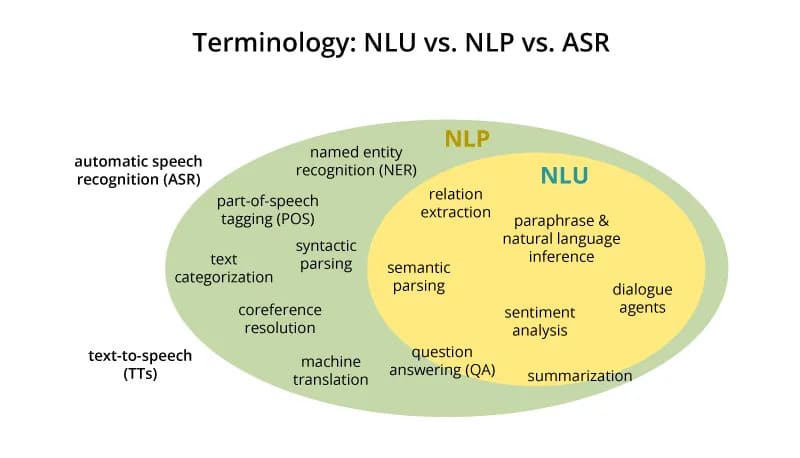
So sánh NLU vs NLP (Xử lý ngôn ngữ tự nhiên)
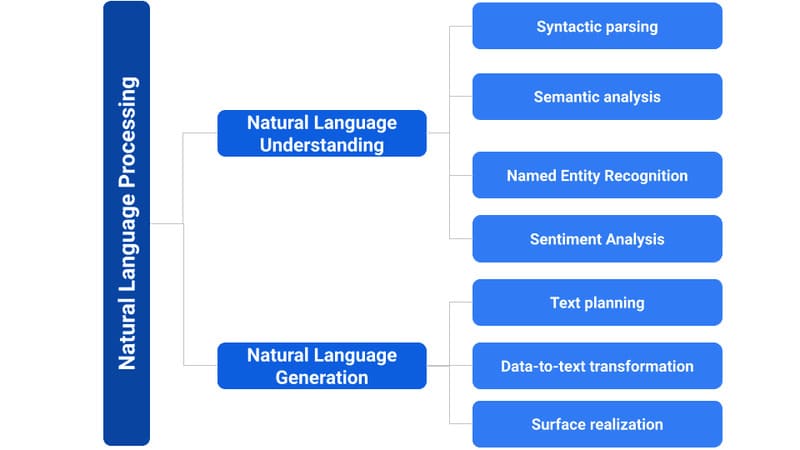
NLU là một nhánh con của NLP (Natural Language Processing – Xử lý ngôn ngữ tự nhiên). Trong khi NLP bao quát toàn bộ quá trình giúp máy tính hiểu và giao tiếp bằng ngôn ngữ con người, bao gồm việc ánh xạ các yếu tố ngôn ngữ như cú pháp, định nghĩa từ và phân tích cấu trúc câu, thì NLU tập trung đặc biệt vào việc nắm bắt ý nghĩa sâu xa và ý định trong giao tiếp của con người.
Trước khi NLP ra đời, người dùng chỉ có thể giao tiếp với máy tính thông qua các ngôn ngữ lập trình như Python và C++. Sự xuất hiện của NLP và NLU cho phép người dùng không chuyên cũng có thể tương tác với máy tính. Đặc biệt, các ứng dụng phần mềm không cần mã (no-code) ngày nay cho phép người dùng ra lệnh trực tiếp cho máy tính bằng ngôn ngữ tự nhiên.
Điểm mạnh đặc biệt của NLU là khả năng giao tiếp với những người chưa qua đào tạo kỹ thuật và hiểu được ý định thực sự của họ. Không chỉ đơn thuần hiểu từ ngữ và diễn giải ý nghĩa, NLU còn được lập trình để nắm bắt bản chất thông điệp ngay cả khi có những lỗi thường gặp của con người như phát âm sai, chuyển vị chữ cái hoặc sắp xếp từ không chuẩn.
Xử lý ngôn ngữ tự nhiên NLP có nguồn gốc từ lĩnh vực khoa học máy tính về ngôn ngữ học tính toán (computational linguistics), tập trung vào việc sử dụng máy tính để phân tích ngôn ngữ. Sự phát triển vượt bậc của lĩnh vực này đến từ việc tích hợp các thuật toán học máy và mô hình học sâu (Deep Learning), giúp máy tính thực hiện được nhiều nhiệm vụ phức tạp liên quan đến ngôn ngữ như nhận diện giọng nói và tạo nội dung.

>>> XEM THÊM: Review 10 phần mềm chuyển văn bản thành giọng nói online miễn phí
So sánh NLU vs NLG (tạo ngôn ngữ tự nhiên)
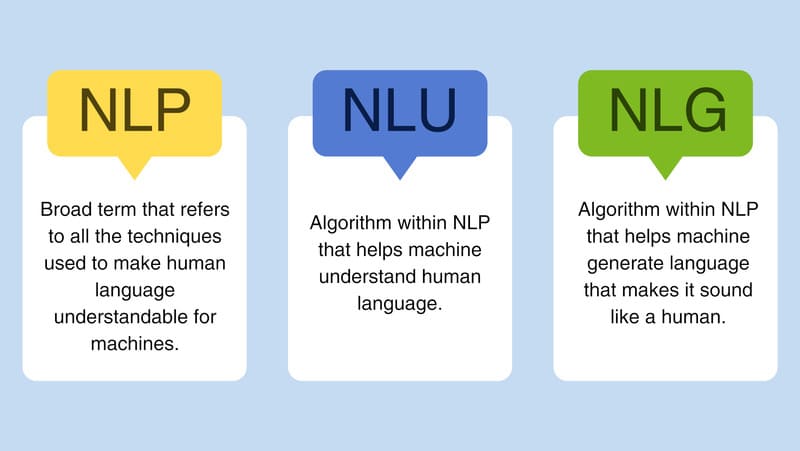
Tạo sinh ngôn ngữ tự nhiên (Natural Language Generation – NLG) là công nghệ giúp máy tính tự động tạo nội dung bằng ngôn ngữ con người, thể hiện rõ nhất qua các chatbot khi tóm tắt văn bản hoặc đối thoại với người dùng. NLG thường hoạt động song hành với NLU trong một chu trình hoàn chỉnh: mô hình học sâu tiếp nhận đầu vào ngôn ngữ tự nhiên, chuyển đổi thành dữ liệu xử lý được qua NLP (bao gồm NLU), rồi tạo phản hồi thông qua NLG mà người dùng có thể hiểu.
Điểm đột phá của hệ thống NLG là khả năng tạo văn bản mô phỏng giao tiếp tự nhiên của con người. Trước đây, nội dung do máy tính tạo ra thường thiếu tính lưu loát, cảm xúc và cá tính – những yếu tố làm nên sự thú vị và hấp dẫn trong nội dung của con người. Tuy nhiên, khi kết hợp NLG với NLP, máy tính có thể tạo văn bản giống con người bằng cách xác định chủ đề chính của tài liệu sau đó sử dụng NLP để xác định cách viết phù hợp nhất trong ngôn ngữ mẹ đẻ của người dùng.
NLG mở ra nhiều ứng dụng thực tiễn như tự động tạo bài viết tin tức từ dữ liệu về sự kiện cụ thể, hoặc soạn thư bán hàng dựa trên các thuộc tính sản phẩm.
Tóm lại, NLP, NLG và NLU đều có liên quan với nhau. Trong hệ sinh thái xử lý ngôn ngữ, NLP đóng vai trò bao quát, với NLU và NLG là hai nhánh chuyên biệt. Chính NLG là yếu tố then chốt tạo nên sự tương tác gần gũi với con người của các chatbot như ChatGPT, các bot hỗ trợ khách hàng hiện đại và trợ lý ảo như Alexa của Amazon.
>>> XEM THÊM: Dialog Management và vai trò trong việc phát triển chatbot
Cách thức hoạt động của NLU là gì?
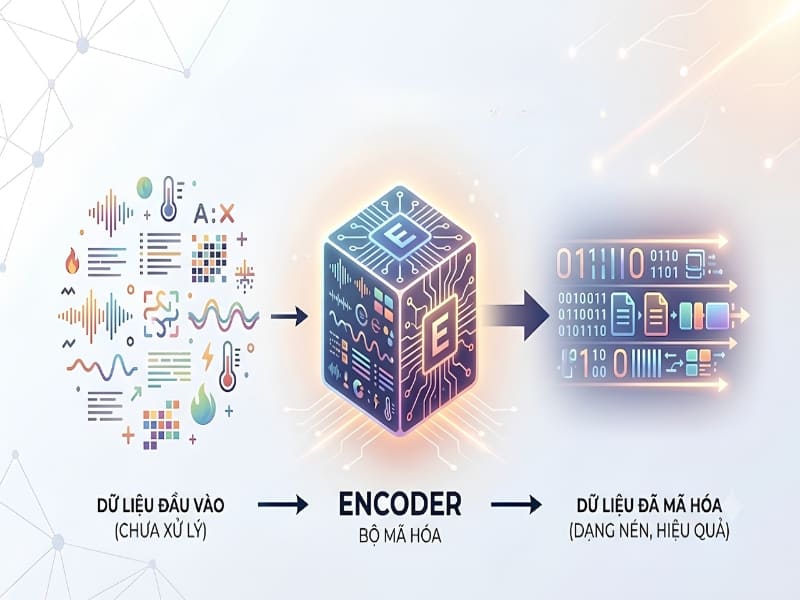
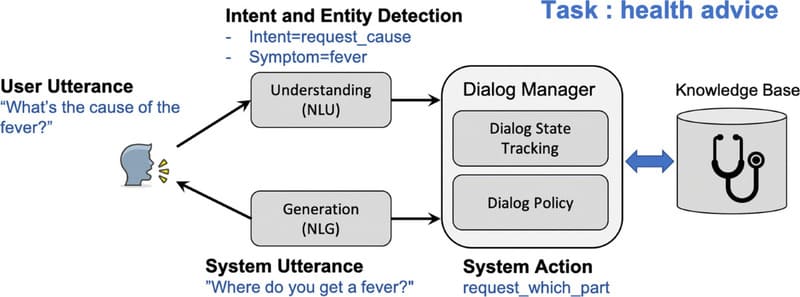
Natural Language Understanding sử dụng các thuật toán học máy để chuyển đổi ngôn ngữ nói hoặc viết phi cấu trúc thành một mô hình dữ liệu có cấu trúc đại diện cho nội dung và ý nghĩa của nó. Hệ thống NLU áp dụng phân tích cú pháp để hiểu các từ trong câu và phân tích ngữ nghĩa để xử lý ý nghĩa của những gì đang được nói.
Các khái niệm cơ bản trong cơ chế hoạt động của NLU bao gồm:
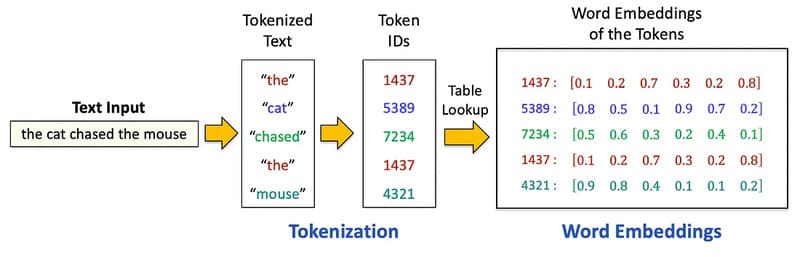
Tokenization và embedding
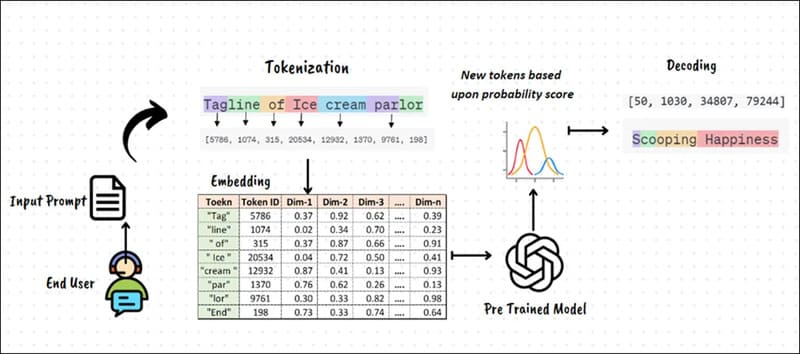
Tokenization trong hiểu ngôn ngữ tự nhiên (NLU) là quá trình phân tách văn bản phi cấu trúc thành các đơn vị nhỏ hơn gọi là token, bao gồm từ, dấu câu và các ký hiệu khác. Các token này sau đó được so sánh với từ điển để xác định từ và loại từ. NLU sau đó phân tích cấu trúc ngữ pháp để hiểu vai trò của từng từ và giải quyết các mơ hồ có thể xuất hiện trong ý nghĩa.
Tiếp theo, thuật toán embedding sẽ chuyển đổi token thành các biểu diễn số học và biểu diễn chúng trong không gian vector ba chiều để lập bản đồ mối quan hệ giữa các token, cho phép máy tính hiểu cách các từ liên quan đến nhau.
Các hệ thống NLU hiện đại thường sử dụng các mô hình dựa trên kiến trúc Transformer, chẳng hạn như GPT, vì chúng xuất sắc trong việc nắm bắt các phụ thuộc giữa các token, ngay cả khi chúng cách xa nhau trong văn bản. Việc nắm bắt chính xác các phụ thuộc giúp máy tính duy trì sự hiểu biết về ngữ cảnh trong các chuỗi đầu vào dài.
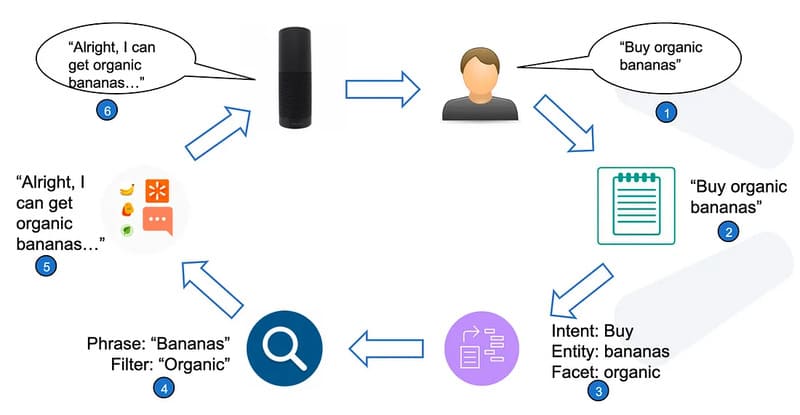
Để hiểu rõ hơn, hãy xem xét trường hợp người dùng nhập vào công cụ tìm kiếm: “chuyến cắm trại trên đảo Vancouver ngày 18 tháng 8”. Một hệ thống NLU sẽ phân tích câu này thành các thành phần sau:
- Vé phà [ý định/nhu cầu]
- Đặt chỗ cắm trại [ý định]
- Đảo Vancouver [địa điểm]
- Ngày 18 tháng 8 [ngày]
Hệ thống NLU sẽ hiểu mục tiêu của người dùng là mua vé phà, vì phà là phương tiện hợp lý nhất để đến một khu cắm trại trên đảo. Nhờ vậy, kết quả tìm kiếm có thể hiển thị thông tin về lịch trình phà và liên kết để mua vé, đáp ứng chính xác nhu cầu của người dùng dựa trên sự phân tích toàn diện về nhu cầu, địa điểm, mục đích và thời gian từ dữ liệu đầu vào.
>>> XEM THÊM: Text Preprocessing – Kỹ thuật tiền xử lý văn bản trong NLP (Natural Language Processing)
Nhận diện ý định (Intent Recognition)
Intent recognition là quá trình phân tích văn bản nhập vào để xác định cảm xúc và mục đích của người dùng. Đây là thành phần then chốt của NLU, đặt nền móng cho việc hiểu đúng ý nghĩa của văn bản và mong muốn thực sự của người dùng.
Các công cụ tìm kiếm áp dụng Intent Recognition để cung cấp kết quả không chỉ liên quan đến từ khóa, mà còn đáp ứng đúng nhu cầu thông tin thực tế của người dùng.
Chẳng hạn, khi người dùng tìm kiếm “chicken tikka masala”, hệ thống có thể hiểu rằng họ muốn nấu món này và hiển thị các công thức nấu ăn. Tuy nhiên, nếu truy vấn là “chicken tikka masala near me”, intent recognition sẽ nhận diện rằng người dùng không có ý định nấu nướng mà đang tìm kiếm nhà hàng gần đó phục vụ món ăn này. Nhờ đó, công cụ tìm kiếm có thể đưa ra kết quả phù hợp với nhu cầu thực sự của người dùng.
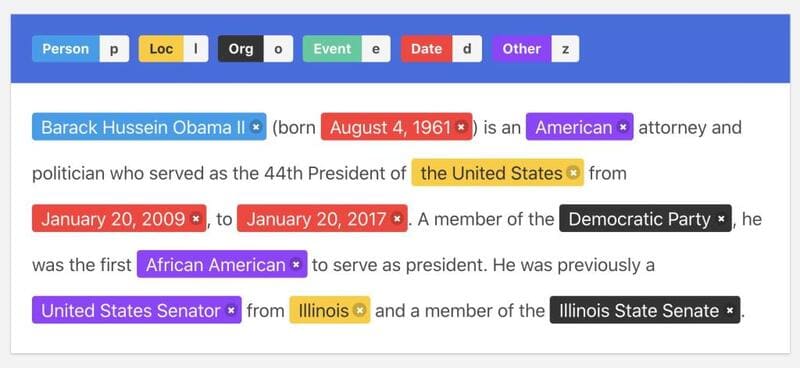
Named entity recognition (NER)
Named entity recognition (NER) là một kỹ thuật quan trọng trong NLU, tập trung vào việc nhận diện và phân loại các thực thể trong văn bản, sau đó trích xuất thông tin quan trọng nhất về chúng.
Có hai loại thực thể: thực thể được đặt tên và thực thể số. Thực thể được đặt tên được nhóm thành các danh mục, chẳng hạn như tên người, tên doanh nghiệp và địa điểm. Thực thể số tập trung vào việc nhận diện các giá trị số lượng, ngày tháng, tiền tệ và phần trăm.
Các thực thể được NER nhận diện phân thành hai loại chính. Thực thể được đặt tên bao gồm các danh mục như tên người, tổ chức, doanh nghiệp, địa điểm, đồ vật, ngày tháng, tuổi tác và số điện thoại. Trong khi đó, thực thể số tập trung vào việc nhận diện các giá trị số lượng, ngày tháng, tiền tệ và phần trăm.
Để phát triển hệ thống NLU hiệu quả, các nhà khoa học dữ liệu sử dụng nhiều phương pháp học máy khác nhau. Trong học có giám sát, các thuật toán cung cấp dữ liệu huấn luyện đã được gắn nhãn, giúp NLU hiểu rõ các sắc thái ngôn ngữ. Ví dụ, khi gặp từ đồng âm “mean”, thuật toán sẽ phân biệt được liệu từ này đang được sử dụng trong ngữ cảnh thống kê hay để đánh giá tính cách.
Ngược lại, các kỹ thuật học không giám sát sử dụng bộ dữ liệu khổng lồ không có nhãn để tự khám phá các mối quan hệ và mẫu cơ bản trong ngôn ngữ. Các mô hình NLU hiện đại thường kết hợp cả hai phương pháp này để đạt được hiệu quả cao nhất, tận dụng ưu điểm của cả học có giám sát và không giám sát trong việc hiểu ngôn ngữ tự nhiên.
>>> XEM THÊM: Gán nhãn dữ liệu là gì? Data Labeling trong học máy và AI
Các ứng dụng nổi bật của Natural Language Understanding
Các ứng dụng NLU bao gồm nhiều trường hợp sử dụng trong đó máy tính cần giao tiếp trực tiếp với con người hoặc xử lý dữ liệu ngôn ngữ của con người. Các trường hợp sử dụng hiểu ngôn ngữ tự nhiên bao gồm:
Nhận diện giọng nói, phản hồi bằng giọng nói tương tác (IVR) và định tuyến tin nhắn
Khi được tích hợp tính năng xử lý ngôn ngữ tự nhiên (NLP) và hiểu ngôn ngữ tự nhiên (NLU), hệ thống tổng đài tự động (Interactive Voice Response – IVR) không chỉ có thể nhận diện giọng nói mà còn có thể chuyển âm thanh thành văn bản, sau đó phân tích cấu trúc ngữ pháp của câu để xác định ý định của người gọi.
Nhờ NLU, các hệ thống tổng đài tự động có thể hiểu chính xác yêu cầu của khách hàng và điều hướng cuộc gọi đến bộ phận thích hợp, giúp doanh nghiệp giảm tải công việc cho nhân viên đồng thời cải thiện trải nghiệm khách hàng.
Chẳng hạn, là khi khách hàng gọi đến ngân hàng và nói “Tôi muốn kiểm tra số dư tài khoản”. Hệ thống IVR thông minh sẽ tự động nhận diện yêu cầu này và cung cấp thông tin số dư ngay lập tức mà không cần chuyển máy đến nhân viên.
>>> XEM THÊM: Voicebot là gì? Ứng dụng của Voicebot AI trong CSKH tự động
Xác định ý định và cảm xúc
Thông qua việc xử lý lượng lớn dữ liệu từ nhiều nguồn khác nhau như bình luận trên mạng xã hội, đánh giá sản phẩm và email phản hồi sau đó phân loại cảm xúc của họ thành tích cực, tiêu cực hoặc trung lập, NLU nâng cao hiệu quả trong việc hiểu ý định cũng như phân tích cảm xúc của người dùng.
Nhờ vậy, doanh nghiệp có thể nhanh chóng nắm bắt xu hướng cảm nhận chung của khách hàng về thương hiệu hoặc sản phẩm, ngay cả khi họ sử dụng ngôn ngữ mơ hồ hoặc không rõ ràng. Điều này giúp doanh nghiệp đưa ra các quyết định chiến lược về phát triển sản phẩm mới, điều chỉnh chính sách giá cả và thực hiện các thay đổi quan trọng khác để đáp ứng tốt hơn nhu cầu khách hàng.
Khi ứng dụng trong các search engine như Google, Bing AI, NLU giúp phân tích các từ khóa và cụm từ người tìm kiếm sử dụng, sau đó cung cấp kết quả chính xác và phù hợp hơn với mong muốn thực sự của họ. Các trang web thương mại điện tử cũng tận dụng công nghệ này để hiển thị sản phẩm đúng với nhu cầu khách hàng, từ đó nâng cao trải nghiệm mua sắm và gia tăng doanh số.
>>> XEM THÊM: Knowledge Base – Công nghệ nâng cấp hiệu quả CSKH cho ngành Bảo hiểm
Hỗ trợ khách hàng
NLU đã cách mạng hóa cách doanh nghiệp tương tác với khách hàng. Nhờ khả năng phân tích ngữ cảnh và ý định của người dùng, NLU giúp các hệ thống AI chatbot và trợ lý ảo, như Siri, Google Assistant, Amazon Alexa và Google Home phân đoạn từ và câu, nhận dạng ngữ pháp và áp dụng kiến thức ngữ nghĩa để hiểu ý định của người dùng và đưa ra phản hồi phù hợp một cách nhanh chóng.
Cùng với sự phát triển của AI tạo sinh, chatbot đã trở nên thông minh hơn, có thể thay nhân viên chăm sóc khách hàng xử lý các truy vấn phổ biến, hướng dẫn mua hàng và cung cấp hỗ trợ 24/7. Các trợ lý giọng nói giúp người dùng thực hiện các tác vụ như quản lý lịch trình, đặt lịch hẹn, tìm kiếm thông tin, thậm chí là tra cứu thông tin bệnh dựa trên các triệu chứng được mô tả.
Giao diện đàm thoại sử dụng NLU như loa thông minh, điện thoại di động đều có thể nhận lệnh bằng giọng nói và phản hồi bằng ngôn ngữ tự nhiên, tạo nên trải nghiệm tương tác liền mạch và trực quan cho người dùng.
>>> XEM THÊM: Callbot là gì? So sánh sự khác biệt giữa Callbot vs Voicebot và Chatbot
Machine translation
Hiểu ngôn ngữ tự nhiên (NLU) đóng vai trò then chốt trong các nền tảng dịch thuật như Google Dịch và DeepL. Thay vì chỉ đơn thuần dịch từ vựng, NLU giúp phần mềm hiểu được ngữ cảnh và sắc thái của từng câu, từng đoạn văn, từ đó, cung cấp bản dịch nhanh chóng, tự nhiên, chính xác và phù hợp với văn hóa của ngôn ngữ đích.
Qua đó, rào cản ngôn ngữ được phá bỏ, giúp người dùng nói tiếng Tây Ban Nha vừa trò chuyện với người nói tiếng Anh, vừa hiểu mọi thông tin tiếng Anh xung quanh họ, tạo điều kiện giao tiếp liền mạch giữa người dùng nói các ngôn ngữ khác nhau trong thời đại toàn cầu hóa.
Phòng chống gian lận
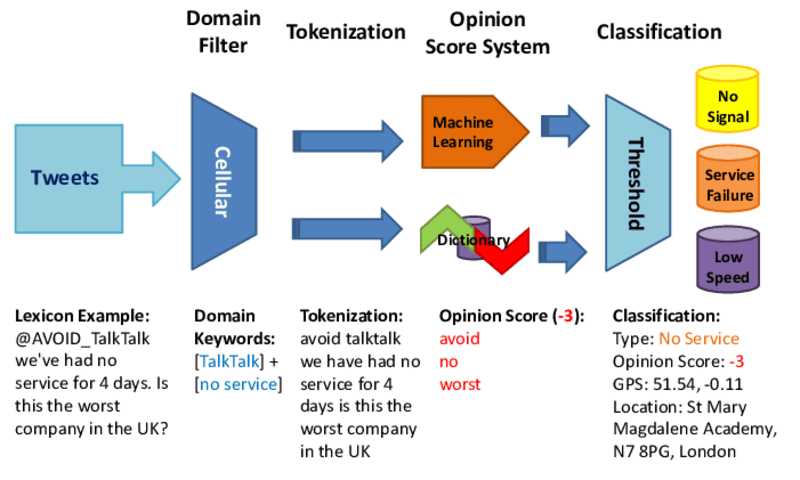
Công nghệ Hiểu ngôn ngữ tự nhiên (NLU) giúp doanh nghiệp theo dõi dữ liệu các kênh giao tiếp như email và tin nhắn cũng như hệ thống tài chính. Bằng cách phân tích mẫu giao tiếp và giao dịch, NLU có thể hiểu ngữ cảnh và diễn biến phức tạp của các âm mưu gian lận tinh vi, đưa ra cảnh báo sớm cho các hành vi bất thường để tổ chức ngăn chặn kịp thời trước khi thiệt hại xảy ra.
Quản lý nội dung số và bảo vệ dữ liệu cá nhân
NLU mang đến giải pháp quản lý nội dung thông minh trong môi trường số. Hệ thống có thể nhận diện ngay lập tức nội dung có hại như spam, phát ngôn thù địch hoặc ngôn từ kích động trên các nền tảng mạng xã hội. Đặc biệt, NLU còn có khả năng tự động nhận diện và ẩn thông tin nhạy cảm như số điện thoại, địa chỉ và thông tin cá nhân trong văn bản, tạo lớp bảo vệ quyền riêng tư trong kỷ nguyên dữ liệu mở.
Thu thập dữ liệu
Thu thập dữ liệu là quá trình thu thập và ghi lại thông tin về một đối tượng, người hoặc sự kiện. Ví dụ, nếu một công ty thương mại điện tử sử dụng NLU, họ có thể yêu cầu khách hàng nhập thông tin vận chuyển và thanh toán bằng lời nói. Phần mềm sẽ hiểu ý của khách hàng và tự động nhập thông tin.

Trích lọc tinh hoa từ đại dương thông tin
Một trong những ứng dụng thiết thực nhất của NLU là khả năng tóm tắt và trích xuất thông tin quan trọng từ tài liệu dài. Thay vì dành hàng giờ đọc hợp đồng phức tạp hay báo cáo dài hàng trăm trang, NLU có thể nhanh chóng nắm bắt và tổng hợp những điểm chính.
Điều này giúp người dùng tập trung vào những thông tin thực sự quan trọng trong biển dữ liệu ngày càng mênh mông, tiết kiệm thời gian và nâng cao hiệu quả làm việc.
>>> XEM THÊM: Khai phá dữ liệu là gì? 9 công cụ và kỹ thuật Data Mining
Chuyển hóa dữ liệu thành chiến lược kinh doanh
Trong kinh doanh, NLU chuyển hóa khối lượng dữ liệu khổng lồ thành những hiểu biết có giá trị. Công nghệ này phân tích các báo cáo, phản hồi khách hàng và xu hướng thị trường để đề xuất hướng đi chiến lược phù hợp. NLU giúp các nhà quản lý tiếp cận thông tin đa chiều, cân nhắc nhiều yếu tố phức tạp và đưa ra quyết định sáng suốt dựa trên dữ liệu thực tế.
Hạn chế của NLU là gì?
Song song với những tiến bộ vượt bậc, Natural Language Understanding vẫn đối mặt với nhiều thách thức đáng kể như sau:
- Mơ hồ trong ngôn ngữ: NLU thường gặp khó khăn khi phải xác định ý nghĩa chính xác của câu có thể hiểu theo nhiều cách. Chẳng hạn câu “Tôi thấy một người đàn ông với chiếc ống nhòm” có thể hiểu là người nói đang dùng ống nhòm để quan sát, hoặc người đàn ông kia đang cầm ống nhòm. Máy tính chưa thể nắm bắt ngữ cảnh tinh tế như con người để phân biệt các trường hợp này.
- Ngôn ngữ hình tượng: Các thành ngữ, tục ngữ và ẩn dụ như “Đá thúng đụng nia” hay “Nước đến chân mới nhảy” tạo thành rào cản lớn cho NLU. Những biểu đạt này không thể hiểu theo nghĩa đen, đòi hỏi hệ thống phải được huấn luyện trên khối lượng dữ liệu khổng lồ để nắm bắt ý nghĩa thực sự.
- Rào cản đa dạng văn hóa-ngôn ngữ: Sự biến đổi của ngôn ngữ theo khu vực, văn hóa và nhóm xã hội là thách thức lớn cho NLU. Một từ như “football” mang nghĩa hoàn toàn khác nhau giữa người Anh và người Mỹ. Tiếng lóng và phương ngữ địa phương càng làm phức tạp thêm khả năng hiểu của máy.
- Thiên kiến từ dữ liệu huấn luyện: Hệ thống NLU học từ dữ liệu do con người cung cấp, do đó dễ bị ảnh hưởng bởi những định kiến tiềm ẩn trong tập dữ liệu. Khi được huấn luyện trên dữ liệu thiên về một nhóm người dùng cụ thể, hệ thống có thể phản ứng không chính xác với đầu vào từ các nhóm khác.
- Lỗi đầu vào: Con người thường mắc lỗi chính tả hoặc dùng từ viết tắt như “ko” thay vì “không”. Nếu không được thiết kế để nhận diện và xử lý các sai sót này, hệ thống NLU có thể hiểu sai hoặc không hiểu được ý định của người dùng.
- Từ đa nghĩa: Nhiều từ mang nhiều ý nghĩa tùy thuộc vào ngữ cảnh sử dụng. Ví dụ tiếng Anh, “bark” có thể là tiếng sủa hoặc vỏ cây, “bank” có thể là ngân hàng hoặc bờ sông. NLU phải phân tích ngữ cảnh rất kỹ để xác định nghĩa chính xác, nhưng vẫn thường gặp trường hợp khó xử lý.
- Chất lượng dữ liệu: Hiệu suất của NLU phụ thuộc vào tính đa dạng và chính xác của dữ liệu huấn luyện. Nếu dữ liệu không phong phú hoặc chứa sai sót, mô hình sẽ học sai hoặc hoạt động kém hiệu quả khi đối mặt với tình huống thực tế.
- Sai sót do dự đoán dựa trên xác suất: NLU sử dụng mô hình xác suất để đưa ra dự đoán, khiến hệ thống đôi khi trả về kết quả không chính xác. Ví dụ điển hình là khi chatbot hiểu sai câu hỏi và đưa ra câu trả lời hoàn toàn không liên quan, gây bối rối cho người dùng.
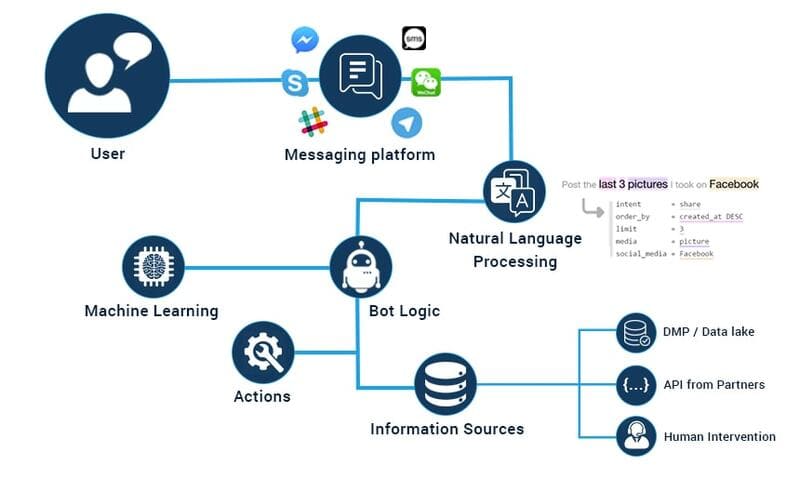
Tóm lại, nhờ khả năng trích xuất thông tin từ dữ liệu phi cấu trúc và hiểu được những sắc thái tinh tế trong ngôn ngữ, NLU đã mở ra một kỷ nguyên mới cho giao tiếp người-máy. Cùng với NLP và NLG, NLU tạo nên một hệ sinh thái hoàn chỉnh cho việc xử lý ngôn ngữ tự nhiên, mang đến những ứng dụng thiết thực trong nhiều lĩnh vực. Khi công nghệ tiếp tục tiến bộ, chúng ta có thể kỳ vọng NLU sẽ ngày càng thu hẹp khoảng cách giữa giao tiếp người-máy, tạo ra những trải nghiệm tương tác tự nhiên, liền mạch hơn nữa.
>>> XEM THÊM:
- Conversational AI là gì? So sánh Conversational AI và Generative AI
- Language Model là gì? 10 Ứng dụng Language Modeling nổi bật
- Ứng dụng Callbot ngành ngân hàng – Tiềm năng công nghệ 2025