Bản cập nhật nhằm nâng cao khả năng tích hợp hệ thống và tối ưu hóa trải nghiệm xây dựng AI Agent.
Xem thêm tài liệu hướng dẫn chi tiết tại: HDSD_Release Note
Bổ sung chức năng trên FPT AI MyAgents
Đề cập tới tài liệu cá nhân trong luồng trò chuyện với AI Agents
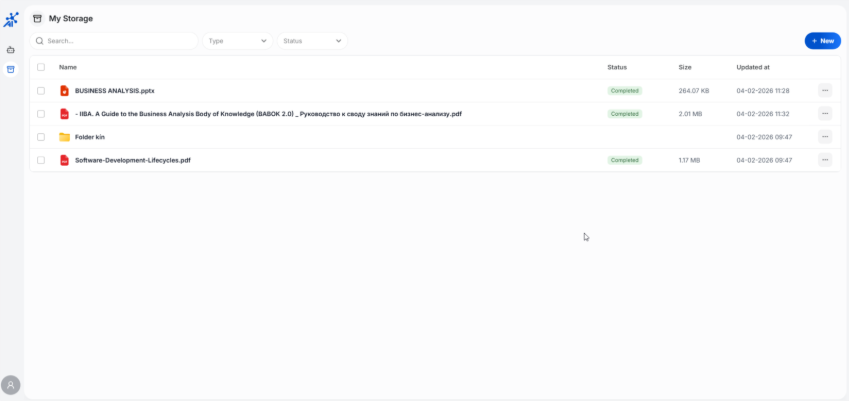
Ngoài khả năng cho phép người dùng có thể đính kèm file tài liệu cá nhân để sử dụng trong khi trò chuyện với AI Agent thì FPT AI MyAgents hỗ trợ cung cấp một kho lưu trữ dữ liệu riêng để giúp người dùng có thể tái sử dụng tài liệu khi khi làm việc với nhiều Agent khác nhau hoặc trong các cuộc hội thoại khác nhau. Tính năng My Storage cho phép người dùng tạo thư mục và tải lên tệp để quản lý tài liệu cá nhân. Khi một tệp được tải lên, hệ thống sẽ tự động xử lý (ingest) dữ liệu, giúp người dùng có thể tái sử dụng mà không cần xử lý lại, từ đó tiết kiệm thời gian.
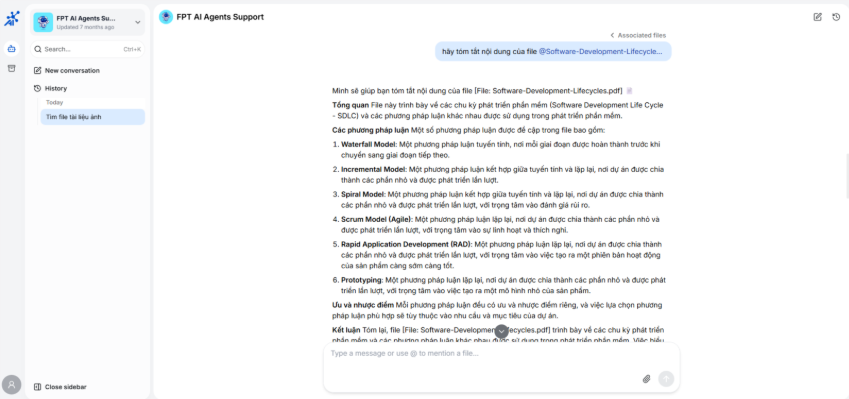
Ngoài ra, các tệp được tải lên trong quá trình trò chuyện với Agent cũng sẽ được tự động lưu vào My Storage, giúp người dùng dễ dàng quản lý và truy xuất khi cần. Sau khi tệp được tải lên My Storage và xử lý thành công, người dùng có thể dùng tệp đó trong quá trình trò truyện trên MyAgent bằng cách đề cập tới tên tệp (sử dụng cú pháp @ trong hộp chat) với mục đích cụ thể như tóm tắt, tổng hợp, hỏi đáp thông tin… với tài liệu riêng này.
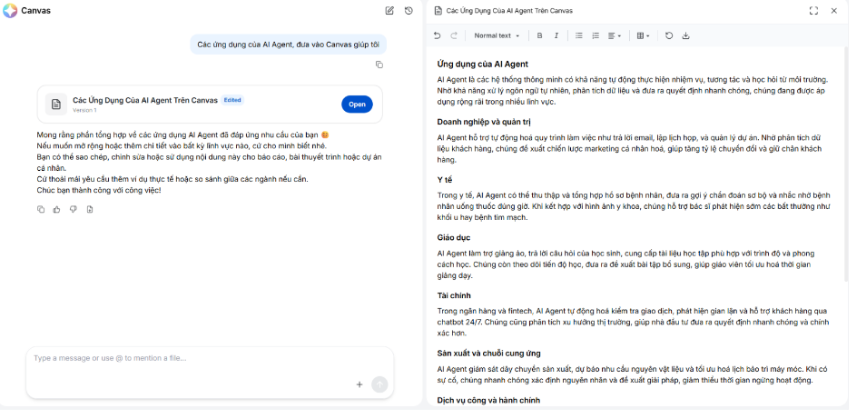
Sử dụng Canvas trên MyAgents
Trên MyAgents, sau khi Agent tạo ra các nội dung như báo cáo, dàn ý hoặc bài luận, người dùng thường có nhu cầu chỉnh sửa lại câu trả lời, tùy biến nội dung theo ý muốn, định dạng lại cho đẹp và dễ đọc, đồng thời tải về phiên bản đã chỉnh sửa. Để đáp ứng nhu cầu này, hệ thống cung cấp tính năng Canvas, cho phép người dùng chỉnh sửa trực tiếp câu trả lời mà Agent tạo ra ngay trong phiên hội thoại. Nhờ đó, trải nghiệm làm việc trở nên liền mạch, thuận tiện, không cần rời khỏi cuộc trò chuyện với Agent
Lưu ý: Để sử dụng tính năng Canvas, Agent cần được chỉnh sửa Nhiệm vụ mặc định để trả ra định dạng tương thích với Canvas (liên hệ ai.agents.support@fpt.com để được hướng dẫn chi tiết)
Kiểm soát chất lượng
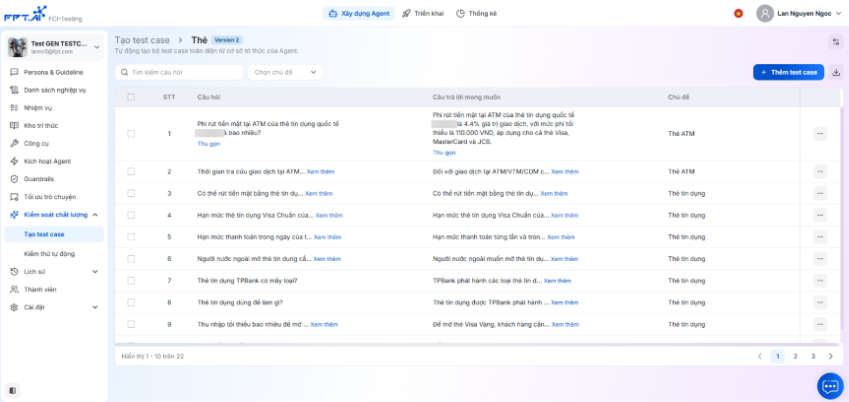
Tự động tạo Testcase
Tính năng Tạo testcase tự động cho phép người dùng nhanh chóng sinh ra bộ testcase chất lượng cao từ tài liệu trong kho tri thức. Bộ testcase này được dùng để kiểm thử khả năng phản hồi của AI Agent dựa trên nhiều loại nghiệp vụ khác nhau (trích xuất, tóm tắt, so sánh, tổng hợp, suy luận). Chức năng này giúp: Tự động hóa quá trình tạo testcase, tiết kiệm thời gian cho QC/Tester. Đảm bảo bộ kiểm thử đa dạng, bám sát tài liệu nguồn. Theo dõi tiến trình sinh testcase và kết quả kiểm thử trực tiếp trên hệ thống. Xuất dữ liệu testcase để tái sử dụng.
Lưu ý: Hiện tại, tính năng hỗ trợ tự động sinh test case dạng QnA (cặp câu hỏi – câu trả lời), chưa hỗ trợ sinh test case dạng luồng self-service (nhiều lượt).
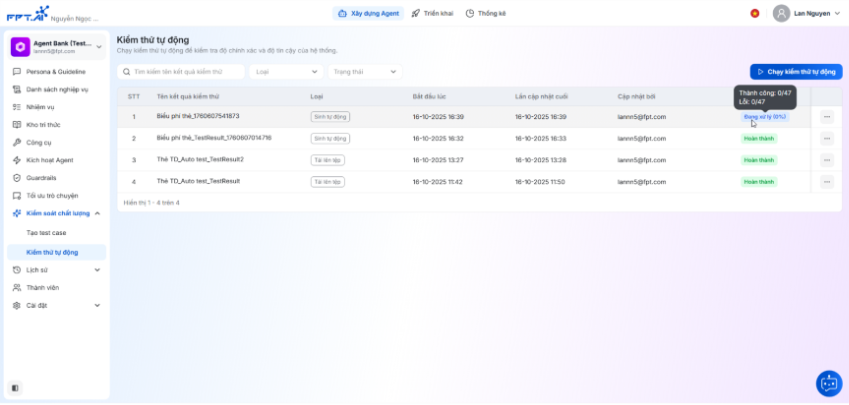
Kiểm thử tự động
Kiểm thử tự động (Automation Test) là tính năng cho phép hệ thống tự động thực thi các bộ testcase để đo lường chất lượng phản hồi của AI Agent theo tiêu chí đã cấu hình. Người dùng có thể:
- Chọn bộ testcase đã sinh trong hệ thống, hoặc
- Tải lên file testcase chuẩn theo mẫu file excel hệ thống đã cung cấp.
Cách hoạt động: hệ thống lần lượt gửi câu hỏi trong testcase tới AI Agent → thu nhận câu trả lời thực tế → so sánh với kết quả kỳ vọng → đánh giá theo tiêu chí và trọng số đã cấu hình → tổng hợp điểm Overall và lưu kết quả để theo dõi.
Loại kiểm thử: Hệ thống hỗ trợ kiểm thử 2 loại use cases chính là:
- QNA: Kiểm tra khả năng hỏi đáp dựa trên tài liệu (tri thức đã cung cấp cho Agent)
- Quy trình nghiệp vụ: Kiểm tra khả năng xử lý quy trình nghiệp vụ tự động (Self-service)
Lợi ích chính:
Tự động hóa quy trình kiểm thử: giảm thao tác thủ công, rút ngắn thời gian cho QC/Tester. Đánh giá nhất quán theo các tiêu chí mong muốn (ví dụ: Tính chính xác, Độ an toàn, Độ trôi chảy) và kết quả tổng thể dựa trên tỷ trọng các tiêu chí do người dùng thiết lập. Báo cáo và truy vết đầy đủ: xem chi tiết từng testcase, tổng hợp theo lô/batch, xuất báo cáo Excel để phân tích sâu hoặc lưu trữ.
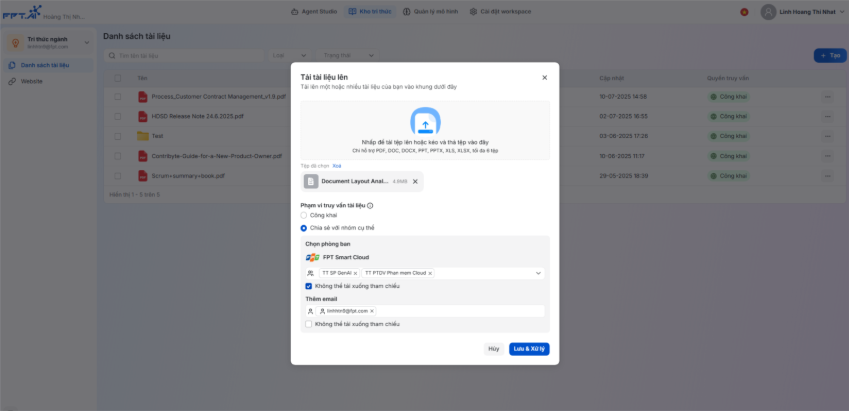
Kho tri thức
Quản lý quyền truy vấn tri thức của Agent
Tính năng Quản lý quyền truy vấn tri thức của Agent trong nền tảng AI Agents cho phép quản trị viên kiểm soát chặt chẽ phạm vi tài liệu mà người dùng cuối được phép truy vấn khi trò chuyện với Agent. Mục tiêu của tính năng là đảm bảo: Người dùng cuối chỉ có thể hỏi đáp và nhận thông tin từ những tài liệu họ được cấp quyền truy cập.
- Tăng cường bảo mật thông tin và đảm bảo tính phù hợp với từng vai trò, phòng ban hoặc nhu cầu công việc trong doanh nghiệp.
📌Ví dụ: Một nhân viên thuộc phòng ban A hoặc lĩnh vực chuyên môn A chỉ có thể nhận được câu trả lời từ AI Agents với các thông tin từ tài liệu liên quan đến phòng ban hoặc chuyên môn đó, không thể nhận được các tài liệu của các bộ phận khác.
Các lựa chọn phạm vi truy vấn:
Khi cấu hình quyền truy cập tài liệu, quản trị viên có thể lựa chọn một trong hai phạm vi phân quyền sau:
- Công khai:
Đây là lựa chọn mặc định của hệ thống. Khi chọn công khai, tất cả người dùng cuối có quyền truy cập vào tương tác với AI Agent trên các kênh tích hợp đều có thể truy vấn thông tin có trong tài liệu đó.
- Chia sẻ với nhóm cụ thể:
Cho phép chỉ định rõ ràng những người dùng hoặc nhóm người dùng được quyền truy vấn thông tin có trong tài liệu. Hệ thống hỗ trợ hai cách cấp quyền:
- Theo phòng ban trong tổ chức: áp dụng khi người dùng đăng nhập vào các nền tảng tích hợp AI Agents bằng tài khoản của tổ chức, hiện chỉ đang hỗ trợ trong FPT.
- Theo địa chỉ email cụ thể mà quản trị viên muốn cấp quyền.
Luồng hoạt động khi người dùng cuối truy vấn tri thức:
Khi người dùng cuối trò chuyện với AI Agents trên các kênh tích hợp như Website, App, Messenger, Zalo, Microsoft Teams… hệ thống sẽ xử lý theo luồng sau: Người dùng cuối truy cập vào AI Agent qua một trong các kênh tích hợp. Hệ thống kiểm tra tài khoản đăng nhập của người dùng cuối để xác định loại tài khoản:
Tài khoản có định danh (người dùng đăng nhập bằng email hoặc tài khoản tổ chức trong FPT) → Hệ thống hiển thị thông tin được lấy từ: Các tài liệu công khai và các tài liệu đã được phân quyền truy cập cho tài khoản đó.
Tài khoản không định danh (người dùng không đăng nhập, hoặc truy cập từ kênh không hỗ trợ định danh bằng email/tài khoản doanh nghiệp như Messenger, Zalo…) → Hệ thống chỉ hiển thị thông tin được lấy từ các tài liệu công khai trong câu trả lời.
📌Lưu ý: Cơ chế phân quyền này giúp đảm bảo mỗi người dùng chỉ được truy vấn vào những tài liệu phù hợp với quyền hạn và vai trò của họ, đồng thời bảo vệ an toàn thông tin của doanh nghiệp.
Tự động đồng bộ nội dung tri thức từ URL của Website
Đối với các tệp đã được thêm vào AI Agent thông qua SharePoint, khi nội dung trên SharePoint được cập nhật, người dùng có thể sử dụng tính năng Đồng bộ để làm mới dữ liệu. Tính năng này giúp đảm bảo nội dung giữa SharePoint và AI Agent luôn khớp nhau, đồng bộ hóa thay đổi một cách nhanh chóng và chính xác, hạn chế sai lệch trong quá trình làm việc. Khi đồng bộ một tệp, hệ thống kiểm tra xem tệp đó có đủ điều kiện đồng bộ không. Tệp trên SharePoint cần thỏa mãn các điều kiện sau:
- Tệp gốc chưa bị xóa trên SharePoint
- Dung lượng tệp nhỏ hơn 30M
- Tệp nằm trong thư mục đã có trên AI Agent
Sau khi kiểm tra điều kiện, nếu nội dung của tệp thay đổi, hệ thống sẽ thực hiện download tệp đó về, tải lên AI Agent để thay thế tệp cũ. Quá trình xử lý tệp sẽ hiển thị trạng thái xử lý tương ứng trên giao diện.
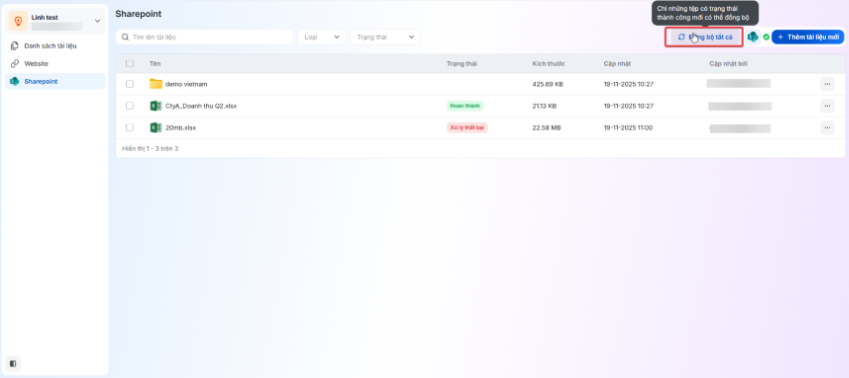
Tích hợp tri thức từ nguồn dữ liệu sharepoint
Bên cạnh hai nguồn tài liệu hiện tại là Tri thức từ tài liệu tải lên kho tri thức và Tri thức đồng bộ về từ website, hệ thống hỗ trợ thêm tính năng tích hợp nguồn dữ liệu từ SharePoint.Tính năng này giúp mở rộng và đa dạng hóa nguồn dữ liệu, cho phép đồng bộ và khai thác dữ liệu nội bộ một cách linh hoạt, đồng thời giảm thiểu thao tác thủ công trong quá trình làm việc
Khi kết nối tài khoản SharePoint, người dùng cần cấp quyền truy cập để AI Agent có thể xem và truy xuất danh sách site, thư mục và tệp. Sau đó, người dùng có thể lựa chọn các thư mục hoặc tệp cần đồng bộ. Hệ thống sẽ tự động tải dữ liệu từ SharePoint này vào AI Agent. Sau khi xử lý hoàn tất, người dùng có thể quản lý và thao tác với các tệp, thư mục SharePoint tương tự như khi tải tệp trực tiếp từ máy tính.
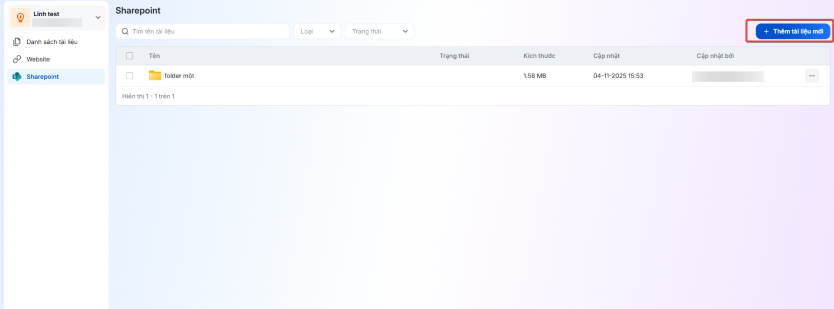
Quản lý câu hỏi thường gặp (FAQS)
Tính năng Quản lý câu hỏi thường gặp (FAQs) cho phép quản trị viên tạo và quản lý tập trung các câu hỏi thường gặp (Question/Answer) để bổ sung tri thức cho Agent nhanh chóng. Thay vì phải ingest cả tài liệu theo luồng xử lý tài liệu thông thường, tính năng giúp cập nhật từng câu hỏi và câu trả lời, dễ kiểm soát, xử lý nhanh chóng và chính xác, phù hợp cho các tình huống cần tra cứu nhanh.
Khi người dùng đặt câu hỏi với Agent có chứa câu hỏi tương ứng với danh sách câu hỏi thường gặp, hệ thống thực hiện retrieve thông tin và đưa ra câu trả lời cho người dùng.
Phạm vi và đối tượng sử dụng:
Chỉ người dùng có vai trò Workspace Admin được truy cập trang quản lý câu hỏi thường gặp. Câu hỏi thường gặp được quản lý theo từng Kho tri thức (knowledge base) (mỗi kho tri thức có danh sách FAQs riêng).
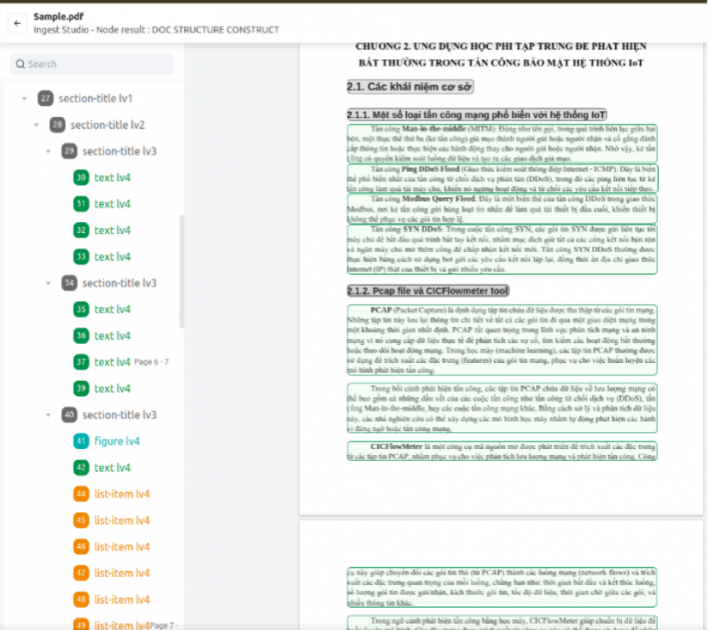
Xem bố cục tài liệu
Tính năng Xem bố cục tài liệu (View Document Layout) cho phép người dùng kiểm tra và hiệu chỉnh kết quả của bước Document Layout Analysis (DLA – Phân tích bố cục tài liệu) trong Ingest Pipeline của hệ thống FPT AI Agents.
Tính năng này giúp người dùng:
- Xem chi tiết kết quả xử lý của bước DLA: hiển thị cấu trúc bố cục tài liệu đã được hệ thống phân tích (bao gồm elements và các thông tin đi kèm của elements)
- Chỉnh sửa thông tin element trong trường hợp hệ thống nhận diện chưa chính xác, bao gồm loại element (element type) và vị trí (location).
- Thực thi lại các bước xử lý tiếp theo như Extract và Chunking sau khi hiệu chỉnh, nhằm cập nhật và tối ưu kết quả trích xuất dữ liệu.
Khi người dùng tải tài liệu lên làm tri thức cho Agent, hệ thống sẽ chạy Ingest Pipeline gồm các bước:
- Document Classification – Phân loại tài liệu
- Document Layout Analysis (DLA) – Phân tích bố cục tài liệu
- Extraction (Trích xuất): Text / Table / Figure / Slide
- Structure Reconstruction (Tái dựng cấu trúc)
- Chunking – Chia nhỏ thành các khối tri thức
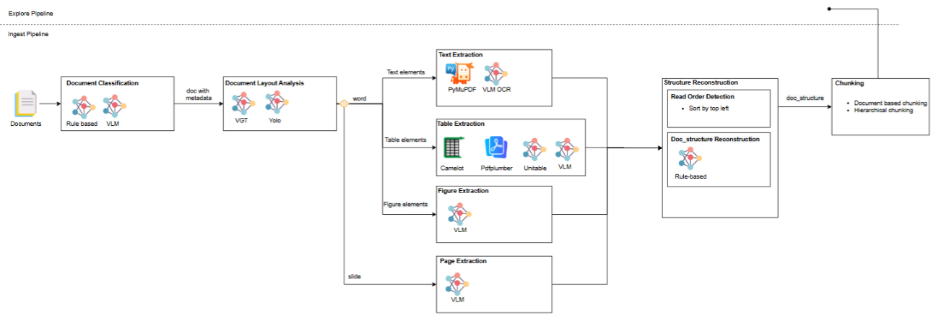
Như trong sơ đồ trên, DLA là bước phân tích cấu trúc tài liệu nhằm xác định các elements trên từng trang (text, title, table, figure, header, footer, list-item, …). Khi tài liệu được ingest vào hệ thống, DLA chạy tự động và trả về danh sách các elements cùng vị trí tương ứng của chúng trên tài liệu.
Cấu trúc phân cấp của một văn bản thông thường như sau:
Tiêu đề / main-title
Đề mục cấp 1: // section-title lv 1
Đề mục cấp 2:
Đoạn văn
Đề mục cấp 2:
Đoạn văn
Bảng biểu
Đoạn văn
Hình ảnh
Đề mục cấp 3:
Danh sách và định nghĩa các elements hệ thống đang hỗ trợ:
| STT | Loại element | Định nghĩa |
| 1 | text | Đoạn văn bản thông thường. |
| 2 | title | main-title: Tiêu đề chính của văn bản section-title: Đề mục phân cấp |
| 3 | list-item | Một phần tử (thông thường là 1-3 dòng) của danh sách các phần tử trong một mục nào đó |
| 4 | table | Thông tin được biểu diễn dưới dạng ô lưới theo hàng cột phân chia bởi các đường kẻ, kể cả không có border |
| 5 | header (page-header) | Các đoạn text lặp đi lặp lại giữa các trang (ví dụ: số trang ở trên đầu của trang) ở đầu trang, đoạn text này nằm bên ngoài luồng text thông thường. |
| 6 | footer (page-footer) | Các đoạn text lặp đi lặp lại giữa các trang (ví dụ: số trang ở chân của trang) ở chân trang, đoạn text này nằm bên ngoài luồng text thông thường. |
| 7 | figure | Biểu đồ, logo, ảnh minh họa…, có thể bao gồm text đi kèm tuy nhiên text này nếu không gắn với figure thì sẽ không có ý nghĩa |
| 8 | form | Các biểu mẫu điền thông tin |
| 9 | footnote | Ghi chú nhỏ cuối trang |
| 10 | useless | Nội dung không phục vụ tri thức (ví dụ: khẩu hiệu, tiêu ngữ…) |
Lưu ý: Việc gán đúng element type giúp hệ thống tái dựng cấu trúc và chunking chính xác hơn.
Bổ sung chức năng tại “Nhiệm vụ”
Khối phân tích tài liệu (File Parser)
Mô tả: Khối “Phân tích tài liệu” có tác dụng phân tích và trích xuất các nội dung của tệp được tải lên
Mục đích: Trong quá trình trò chuyện với AI Agent, người dùng có thể tải lên tệp đính kèm (ví dụ: ảnh, tệp PDF, Excel, …). Trước đây, các tệp này được xử lý mặc định ở hê thống. Hiện tại, nền tảng đã bổ sung tính năng tùy biến luồng xử lý tệp trong phần Nhiệm vụ, giúp xây dựng các quy trình khác nhau tùy theo nghiệp vụ thông qua: Biến hệ thống “sys.attachments”: Là biến mặc định của hệ thống, chứa thông tin về tệp mà người dùng tải lên Khối “Phân tích tài liệu” (File Parser): Dùng để phân tích nội dung tệp và trích xuất thông tin cần thiết (ví dụ: mã lỗi, dữ liệu bảng, text, …).
Usecase sử dụng:
1.Trích xuất mã lỗi từ ảnh
- Người dùng gửi ảnh chụp lỗi hệ thống.
- Hệ thống sử dụng khối “Phân tích tài liệu” để trích xuất mã lỗi từ ảnh.
- Sau đó, mã lỗi được dùng để query vào cơ sở dữ liệu, giúp hiển thị hướng dẫn xử lý phù hợp.
2. Gửi ảnh để tư vấn
- Người dùng gửi ảnh sản phẩm/dịch vụ.
- Hệ thống tự động chuyển tệp đến TVV (tư vấn viên) để hỗ trợ chi tiết hơn.

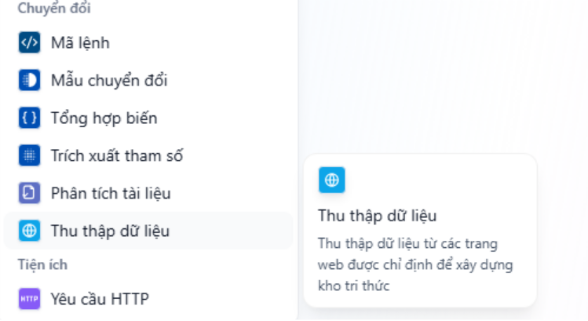
Khối thu tập dữ liệu (Crawler)
Khối “Thu thập dữ liệu” có tác dụng truy cập và lấy nội dung từ các URL được khai báo trong sys.urls, sau đó trả về dữ liệu ở định dạng HTML.
Đầu vào: Biến “sys.urls”
{
”urls”: [
””
]
}
Đầu ra: Biến “results”, kiểu dữ liệu array[object]
{
”invalid_urls”: [],
”results”: [
{
”content”: ””,
“url”: ””
}
]
}
Mục đích
Trong quá trình tạo Nhiệm vụ, người dùng có thể cần thu thập dữ liệu từ các trang web để phục vụ cho việc phân tích thông tin, xây dựng báo cáo hoặc soạn thảo nội dung. Hệ thống hỗ trợ thao tác này thông qua hai thành phần chính:
- Biến hệ thống “sys.urls”: là biến mặc định của hệ thống, chứa các URL người dùng mong muốn lấy thông tin.
- Khối “Thu thập dữ liệu” (Crawler): Thực hiện truy cập và lấy nội dung từ các URL được khai báo trong sys.urls, sau đó trả về dữ liệu ở định dạng HTML để hệ thống hoặc người dùng có thể xử lý tiếp theo
Lưu ý:
Do cấu trúc hệ thống, các Nhiệm vụ (Task) có chứa khối “Thu thập dữ liệu” không thêm được vào bất kỳ Nghiệp vụ nào (Busines Process) Trong quá trình chỉnh sửa Nhiệm vụ, khi thêm khối “Thu thập dữ liệu” vào một trong các Nhiệm vụ đang được gắn với Nghiệp vụ bất kỳ, hệ thống không cho phép lưu Nhiệm vụ đó
Khối vòng lặp (Loop)
Trong quá trình thiết kế nhiệm vụ, người dùng đôi khi cần xử lý các tác vụ theo dạng lặp lại, trong đó mỗi vòng lặp có thể phụ thuộc vào kết quả của vòng trước – chẳng hạn như tạo chuỗi số cho đến khi đạt điều kiện, đọc và xử lý từng phần tử trong danh sách, gọi API liên tục cho đến khi nhận được trạng thái “hoàn tất”, hoặc tích lũy dữ liệu cho đến khi đủ ngưỡng. AI Agent cung cấp khối “Vòng lặp” (Loop) với các đặc điểm chính:
Mỗi lần lặp có thể sử dụng dữ liệu hoặc kết quả từ lần lặp trước, giúp xử lý các tác vụ mang tính tuần tự hoặc tích lũy.

Vòng lặp sẽ tiếp tục chạy cho đến khi thỏa mãn điều kiện dừng (loop termination condition) hoặc cho đến khi đạt số vòng lặp tối đa (maximum loop count) nhằm tránh tình trạng lặp vô hạn.
Bổ sung thêm khối “Thoát vòng lặp” (Exit loop). Nếu luồng xử lý đi qua nút này, vòng lặp sẽ dừng ngay lập tức, bất kể các điều kiện dừng khác
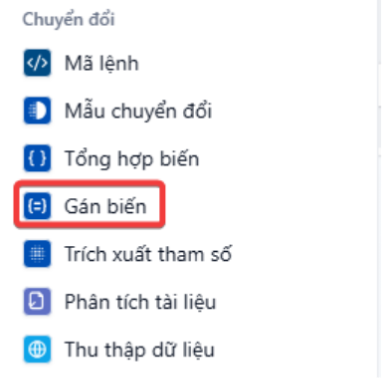
Khối gán biến (Variable Assigner)
Trong quá trình xây dựng Nhiệm vụ, người dùng có nhu cầu gán giá trị cho các biến và sử dụng biến đó cho các khối phía sau. AI Agent bổ sung thêm khối “Gán biến” (Variable Assigner). Đây là khối dùng để gán giá trị cho các biến có thể viết được (writable variables) – ví dụ: các “conversation variables” (biến hội thoại) mà sau đó có thể được dùng tiếp trong quá trình chat hoặc xử lý logic.
Ví dụ: bạn muốn lưu lại “ngôn ngữ ưa thích của user”, “thông tin user đã cung cấp”, “checklist đã hoàn thành tới đâu” → bạn sẽ gán các giá trị đó vào biến và lưu lại. Sau khi gán rồi, các bước sau trong workflow có thể đọc lại biến đó để điều hướng hoặc phản hồi phù hợp
Cách hoạt động & các chế độ gán biến. Có vài loại biến và mỗi loại có cách vận hành khác nhau”
Biến đích có kiểu dữ liệu: String
- Overwrite (Ghi đè)
- Ghi đè trực tiếp biến đích bằng giá trị từ biến nguồn.
- Clear (Xóa): Xóa nội dung của biến đích.
- Set (Đặt giá trị): Gán thủ công một giá trị mà không cần biến nguồn.
Biến đích có kiểu dữ liệu: Number
- Overwrite: Ghi đè trực tiếp giá trị.
- Clear: Xóa nội dung hiện tại của biến.
- Set: Gán thủ công giá trị mới.
- Arithmetic (Phép toán): Thực hiện phép cộng, trừ, nhân hoặc chia trên biến đích.
Biến đích có kiểu dữ liệu: Object
- Overwrite: Ghi đè toàn bộ giá trị của biến đích.
- Clear: Xóa nội dung của biến đích.
- Set: Gán thủ công giá trị mới mà không cần biến nguồn.
Biến đích có kiểu dữ liệu: Array
- Overwrite: Ghi đè toàn bộ mảng bằng mảng từ biến nguồn.
- Clear: Xóa toàn bộ phần tử trong mảng.
- Append (Thêm phần tử): Thêm một phần tử mới vào cuối mảng.
- Extend (Mở rộng mảng): Thêm một mảng mới vào biến đích, cho phép thêm nhiều phần tử cùng lúc.
- Remove (Xóa phần tử): Xóa một phần tử khỏi mảng, với tùy chọn:
- First: Xóa phần tử đầu tiên.
- Last: Xóa phần tử cuối cùng.
- Mặc định là First.
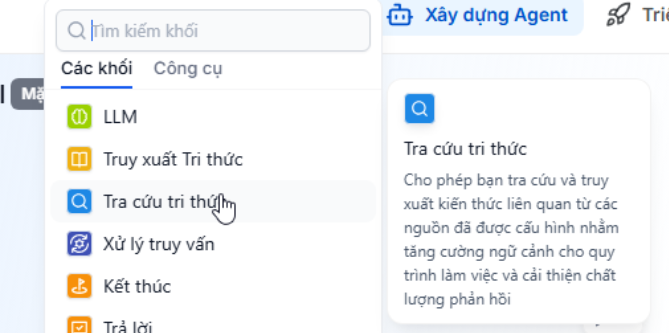
Khối tra cứu tri thức (Knowledge Lookup)
Trong quá trình xây dựng Nhiệm vụ, người dùng có thể cần lấy dữ liệu theo các điều kiện cụ thể (ví dụ: theo tên tệp, loại nội dung, nguồn dữ liệu…). Để đáp ứng nhu cầu này, hệ thống cung cấp khối “Tra cứu tri thức”.
Khác với khối “Truy xuất tri thức” là khối tự động tìm nội dung liên quan dựa trên mức độ tương đồng của dữ liệu, khối “Tra cứu tri thức” hoạt động theo cách lọc trực tiếp: chỉ lấy những tri thức đáp ứng đúng các điều kiện đã cấu hình, không thực hiện so sánh mức độ liên quan.
Cấu trúc của khối “Tra cứu tri thức” bao gồm:
Nguồn truy xuất (Source): Xác định nguồn dữ liệu mà Agent sẽ tìm kiếm thông tin. Người dùng có thể chọn: Agent Knowledge: Kho tri thức đã được kết nối với Agent trong mục Kho tri thức.
My Storage: Kho tài liệu cá nhân của người dùng trên MyAgent.
Bộ lọc tri thức (Knowledge filter): Tùy chọn này chỉ khả dụng khi Nguồn truy xuất (Source) là Agent
- Knowledge. Người dùng có thể giới hạn phạm vi truy xuất bằng cách chọn:
- Thư mục
- Tệp
- URL
- Câu hỏi thường gặp (FAQ)
Agent sẽ chỉ tìm thông tin trong các mục đã chọn, giúp kết quả chính xác hơn.
- Bộ lọc tệp (File filter):
Tùy chọn này áp dụng khi Nguồn truy xuất là My Storage. Người dùng có thể lọc dữ liệu dựa trên biến được chọn. VD: Khi bật File Filter và chọn biến mentioned_files, Agent sẽ chỉ truy xuất các tệp mà người dùng đề cập trực tiếp (mention) trong câu hỏi khi chat trên MyAgent.
- Lọc Metadata: Cho phép lọc dữ liệu dựa trên metadata của tài liệu, bao gồm: Tên tệp (file_name), Kiểu dữ liệu của chunk (chunk_type), URL gốc (original_url).
Hệ thống hỗ trợ các điều kiện so sánh (là, chứa, bắt đầu với, …) với một giá trị cố định hoặc một biến, giúp kiểm soát dữ liệu truy xuất một cách linh hoạt.
- Tổng hợp (Aggregation)
- Cho phép hệ thống gom và lọc dữ liệu dựa trên phương thức và biến được chọn.
- Hiện tại, hệ thống hỗ trợ:
- Phương thức: Unique
- Biến: file_name
Cấu hình này có nghĩa là hệ thống sẽ loại bỏ các chunk có cùng tên tệp, đảm bảo mỗi tệp chỉ được lấy một lần.
- Giới hạn (Limit): Dùng để giới hạn số lượng chunk được trả về từ khối.
Trong trường hợp số lượng chunk thỏa mãn điều kiện vượt quá giới hạn cho phép của khối hệ thống sẽ sắp xếp các chunk theo ngày tạo từ xa nhất đến gần hiện tại nhất và lấy đúngsố lượng giới hạn để đảm bảo không vượt quá giới hạn xử lý.
Tích hợp kênh
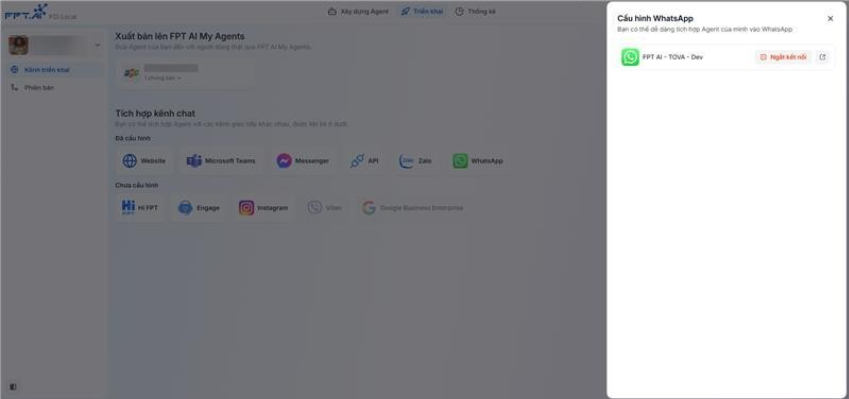
Tích hợp AI Agent với kênh Whatsapp
Sau khi hoàn thiện AI Agent, người dùng có thể muốn đưa Agent lên WhatsApp để phục vụ người dùng cuối. Để hỗ trợ nhu cầu này, hệ thống đã bổ sung tính năng tích hợp WhatsApp thông qua Meta Developer, giúp người dùng dễ dàng kết nối và triển khai AI Agent trên nền tảng WhatsApp
Tích hợp AI Agent với kênh Instagram DMs
Sau khi hoàn thiện xây dựng AI Agent, người dùng có thể muốn đưa Agent lên Instagram DM để người dùng cuối có thể tương tác hỏi đáp với AI Agents trên đó. Để hỗ trợ nhu cầu này, hệ thống đã bổ sung tính năng tích hợp AI Agent với Instagram DM thông qua Meta Developer, giúp người dùng dễ dàng kết nối và triển khai AI Agent trên nền tảng Instagram DM.

Quản lý cấp Workspace
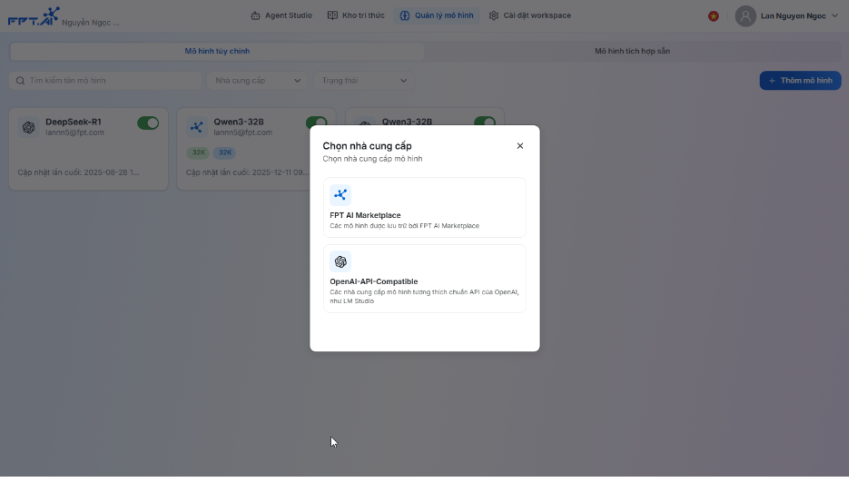
Quản lý mô hình
Tính năng Quản lý mô hình cho phép người dùng trên nền tảng AI Agents dễ dàng cấu hình và bổ sung các mô hình ngôn ngữ lớn (sau đây gọi là LLM) khác, bên cạnh những mô hình mặc định có sẵn trong hệ thống. Chức năng này giúp:
- Mở rộng lựa chọn mô hình: Người dùng có thể thêm các LLM phù hợp với nhu cầu, phục vụ cho nhiều mục đích khác nhau như xử lý Nhiệm vụ hoặc Kiểm soát chất lượng.
- Tăng tính linh hoạt: Cho phép người dùng lựa chọn mô hình phù hợp nhất với từng tình huống sử dụng, thay vì bị giới hạn ở một số mô hình cố định.
- Tối ưu hiệu quả: Đảm bảo AI Agent có thể hoạt động với độ chính xác và hiệu suất cao hơn, tùy theo yêu cầu cụ thể của doanh nghiệp.
Tính năng này được thiết kế nhằm mang đến khả năng kiểm soát tốt hơn và thích ứng nhanh hơn trong cách AI Agent tương tác với các mô hình ngôn ngữ khác nhau, từ đó hỗ trợ người dùng giải quyết bài toán thực tế một cách chủ động và hiệu quả.
Nhật ký hoạt động
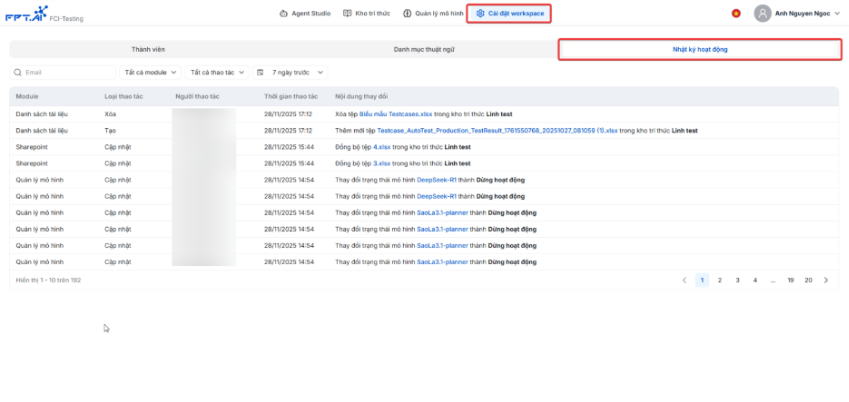
Trong một workspace, mọi thao tác quan trọng đều cần được ghi nhận để phục vụ việc theo dõi và tra cứu khi cần thiết. AI Agent cung cấp tính năng Nhật ký hoạt động (Audit Log), giúp Tenant Admin dễ dàng kiểm soát ai đã thực hiện thao tác gì, đồng thời hỗ trợ việc kiểm tra khi xảy ra sự cố hoặc cần rà soát lịch sử.
Mỗi bản ghi (log) bao gồm các thông tin sau:
- Module: Xác định log thuộc nhóm tính năng nào của hệ thống.
- Loại thao tác: Ghi nhận loại hành động được thực hiện, bao gồm: Tạo, Cập nhật, Xóa, Xử lý lại, Cập nhật lại.
- Người thao tác: Tài khoản người dùng đã thực hiện hành động.
- Thời gian thao tác: Thời điểm diễn ra hành động.
- Nội dung thay đổi: Mô tả chi tiết sự thay đổi, gồm hành động cụ thể, đối tượng bị tác động, và trạng thái trước – sau (nếu có).
Nếu có câu hỏi hay thắc mắc về các tính năng mới trong quá trình sử dụng FPT AI Agents, bạn vui lòng liên hệ đội ngũ hỗ trợ qua địa chỉ email: ai.agents.support@fpt.com
Trân trọng,
Đội ngũ FPT.AI