Thị giác máy tính (Computer Vision) là một trong những lĩnh vực phát triển mạnh mẽ trong khoa học máy tính và trí tuệ nhân tạo. Mặc dù chưa thể sánh ngang với khả năng thị giác của con người, công nghệ này đã tạo ra nhiều ứng dụng hữu ích, bao gồm nhận dạng hình ảnh, phát hiện đối tượng,…
Trong bài viết này, FPT.AI sẽ cũng bạn khám phá Computer Vision là gì và cách hoạt động của công nghệ này. Đọc ngay nhé!
Computer Vision là gì? Tại sao thị giác máy tính quan trọng?
Thị giác máy tính (Computer Vision) là công nghệ cho phép máy tính thu nhận, xử lý, phân tích và nhận diện hình ảnh, video từ nhiều nguồn như camera giám sát, hệ thống an ninh, máy quét, thiết bị y tế,… Nhờ ứng dụng trí tuệ nhân tạo (AI), học máy (Machine Learning) và học sâu (Deep Learning), công nghệ này có thể tự động nhận diện đối tượng, nhận diện khuôn mặt, phân loại hình ảnh, giám sát và phát hiện sự kiện với độ chính xác cao.
Trước đây, việc xử lý hình ảnh yêu cầu con người phải gắn thẻ thủ công hàng ngàn hình ảnh với các điểm dữ liệu như chiều rộng sống mũi hay khoảng cách giữa hai mắt. Việc tự động hóa các tác vụ này đòi hỏi sức mạnh điện toán lớn do dữ liệu hình ảnh không có cấu trúc và rất phức tạp để máy tính sắp xếp. Điều này khiến việc ứng dụng Computer Vision trở nên tốn kém và khó tiếp cận với nhiều tổ chức
Ngày nay, nhờ sự phát triển của AI và điện toán đám mây, quy trình xử lý dữ liệu hình ảnh bằng Computer Vision đã đạt được độ chính xác cao ở quy mô lớn và trở nên và dễ tiếp cận hơn. Công nghệ này được ứng dụng rộng rãi trong tài chính (xác minh danh tính), bảo hiểm (phát hiện gian lận), sản xuất (kiểm tra lỗi sản phẩm), y tế (phân tích hình ảnh y khoa),… góp phần nâng cao hiệu suất, giảm chi phí và thúc đẩy đổi mới trong thời đại số hóa.

>>> XEM THÊM: Xu hướng ứng dụng công nghệ OCR trong ngành bảo hiểm tại Việt Nam
Cách thức hoạt động của Computer Vision
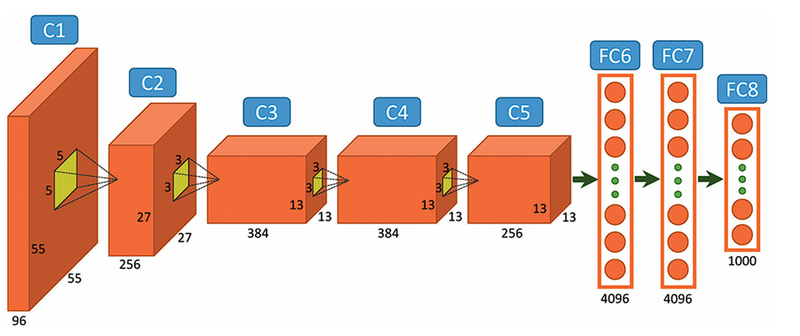
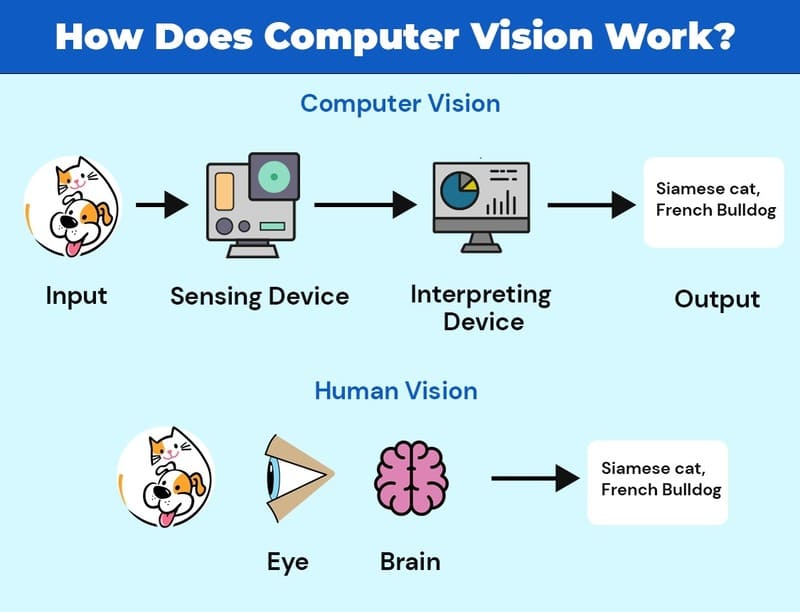
Những ứng dụng của Computer Vision
Computer Vision, với khả năng phân tích và hiểu hình ảnh, đã trở thành nền tảng của nhiều ứng dụng thực tế trong cuộc sống.
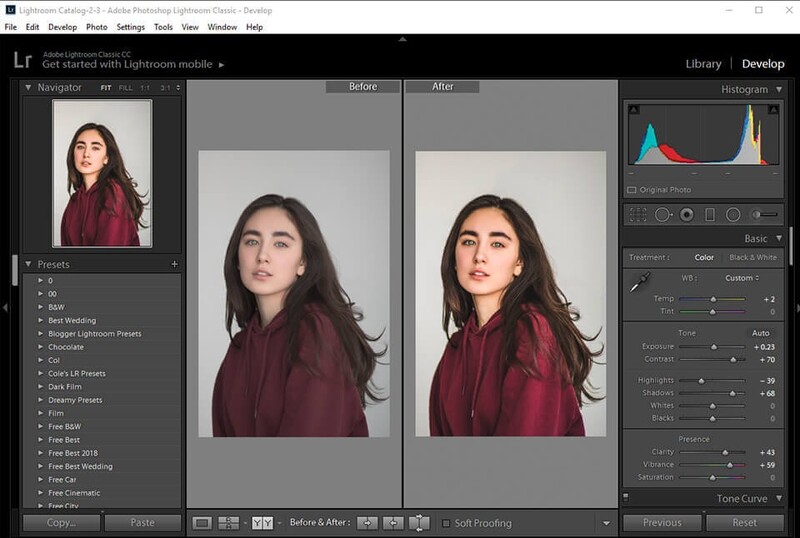
Google Photos sử dụng thị giác máy tính để cho phép người dùng tìm kiếm đối tượng hoặc cảnh vật trong thư viện ảnh bằng các từ khóa đơn giản như “chó” hay “hoàng hôn”. Adobe Lightroom tận dụng Machine Learning để phát hiện các đối tượng trong hình ảnh và làm sắc nét các đặc trưng quan trọng sau khi được phóng to.
Google Dịch cũng tích hợp Computer Vision để cung cấp dịch vụ dịch thuật (Machine Translation) theo thời gian thực. Người dùng chỉ cần hướng camera điện thoại vào một biển báo hoặc văn bản bằng ngôn ngữ nước ngoài, hệ thống sẽ trích xuất nội dung thông qua công nghệ OCR và dịch nó sang ngôn ngữ mong muốn gần như ngay lập tức.
Xe tự lái của Tesla cũng được tích hợp thị giác máy tính để nhận diện các biển báo giao thông, làn đường, người đi bộ và phương tiện khác, từ đó đưa ra quyết định chính xác trong thời gian thực. Các hệ thống bán tự hành cũng sử dụng Computer Vision để giám sát người lái, phát hiện dấu hiệu mệt mỏi hoặc phân tâm.

Trong lĩnh vực y tế, Computer Vision được ứng dụng rộng rãi để phân tích hình ảnh chụp X-quang, MRI và CT scan. Các thuật toán học sâu hỗ trợ bác sĩ phát hiện sớm các bệnh lý như ung thư, khối u hoặc bất thường trong cấu trúc cơ thể, góp phần nâng cao hiệu quả điều trị và kéo dài tuổi thọ bệnh nhân.
Computer Vision còn được sử dụng để nhận diện khuôn mặt (Apple Face ID và Facebook), mở khóa thiết bị, xác minh danh tính tại các sân bay, cửa khẩu hoặc cây ATM.
FPT AI Read là giải pháp ứng dụng công nghệ thị giác máy tính và nhận dạng ký tự quang học (OCR) để nhận dạng chữ viết tay và số hóa file ảnh chụp, PDF thành file Word với độ chính xác lên tới 98%. Hệ thống hỗ trợ nhận diện và trích xuất thông tin từ hơn 30 loại giấy tờ khác nhau như CMND, CCCD, hộ chiếu, bằng lái xe, giấy đăng ký xe, hóa đơn và các chứng từ bảo hiểm.
FPT.AI Car Damage ứng dụng Computer Vision và Deep Learning để hỗ trợ các công ty bảo hiểm giám định, nhận diện các loại thương tổn như vỡ, móp, xước và đánh giá mức độ thiệt hại tại 12 vị trí thường gặp như mui xe, đèn trước, đèn sau, gương, đuôi xe, bánh xe và gầm xe. Giải pháp còn có thể phân biệt rõ giữa tai nạn thật và giả để giảm thiểu sai sót trong quy trình bồi thường, nhanh chóng đưa ra báo giá cho các hư hại dễ đánh giá.

FPT AI eKYC là giải pháp ứng dụng công nghệ Computer Vision, công nghệ nhận diện khuôn mặt và Liveness Detection để đối chiếu ảnh selfie với dữ liệu sinh trắc học trên giấy tờ tùy thân như CMND, CCCD, cho phép khách hàng mở tài khoản ngay tại nhà, rút tiền, gửi tiền hoặc kiểm tra số dư tại cây ATM mà không cần dùng thẻ vật lý hay mã PIN.

>>> XEM THÊM: Machine Vision là gì? So sánh Machine Vision vs Computer Vision
Thách thức và hạn chế khi triển khai Computer Vision
Các hệ thống thị giác máy tính hiện nay có khả năng phân loại hình ảnh và xác định vị trí đối tượng trong ảnh khá tốt khi được đào tạo với đủ dữ liệu. Tuy nhiên, cốt lõi của chúng vẫn là các thuật toán học sâu, chủ yếu hoạt động bằng cách so sánh các mẫu pixel chứ không thực sự “hiểu” nội dung hình ảnh.
Để nhận diện mối quan hệ giữa con người và vật thể trong dữ liệu hình ảnh, cần đến kiến thức nền tảng và sự cảm nhận như con người. Đây là lý do tại sao thuật toán thị giác máy tính trên mạng xã hội có thể phát hiện nội dung khỏa thân nhưng lại gặp khó khăn trong việc phân biệt giữa ảnh nghệ thuật hoặc cho con bú với nội dung khiêu dâm bị cấm. Tương tự, chúng cũng gặp thách thức khi phân biệt giữa tài liệu tuyên truyền cực đoan và phim tài liệu về chủ đề đó.
Con người có thể tận dụng kiến thức tổng quát để xử lý các tình huống mới mà họ chưa từng gặp trước đây. Trong khi đó, thuật toán thị giác máy tính phải được hướng dẫn chi tiết về các đối tượng cần nhận diện. Khi gặp những điều không có trong dữ liệu huấn luyện, chúng có thể phản ứng một cách phi lý, chẳng hạn như không nhận diện được phương tiện khẩn cấp đỗ ở vị trí khác thường.
Hiện tại, cách duy nhất để khắc phục những hạn chế này là cung cấp thêm dữ liệu huấn luyện, với hy vọng mở rộng phạm vi nhận diện của AI. Tuy nhiên, thực tế cho thấy nếu không có khả năng nhận thức theo ngữ cảnh, vẫn sẽ tồn tại những trường hợp hiếm hoi mà thuật toán không thể xử lý chính xác.
Nhiều chuyên gia tin rằng để đạt được thị giác máy tính thực sự, cần phải phát triển trí tuệ nhân tạo tổng quát (AGI), một AI có thể giải quyết vấn đề như con người.
Nhà nghiên cứu AI Melanie Mitchell từng nhận định trong cuốn Trí thông minh nhân tạo: Hướng dẫn về tư duy con người: “Có vẻ như trí thông minh thị giác không thể tách rời khỏi trí thông minh tổng quát, đặc biệt là kiến thức nền tảng, tư duy trừu tượng và kỹ năng ngôn ngữ. Hơn nữa, có thể những kiến thức cần thiết cho trí thông minh thị giác của con người không thể học từ hàng triệu bức ảnh trên mạng, mà phải được tiếp thu qua trải nghiệm thực tế.”

Các thách thức khi triển khai Computer Vision không có nghĩa là chúng ta nên dừng lại việc nghiên cứu. Ngược lại, để vượt qua các hạn chế, Computer Vision cần được tích hợp với các công nghệ tiên tiến khác và phải được trải nghiệm thực tế trong thế giới thực, thay vì chỉ dựa trên các bức ảnh tải về từ web. Điều này sẽ giúp công nghệ này gia tăng sức mạnh, nâng cao tính chính xác để ngày càng thông minh và hữu ích hơn trong các lĩnh vực phức tạp. Hy vọng bài viết của FPT.AI đã mang đến cho bạn các thông tin bổ ích!
———————————-
? Trải nghiệm các sản phẩm khác của #FPT_AI tại: https://fpt.ai/vi
? Địa chỉ: Tầng 7, tháp FPT, số 10 Phạm Văn Bạch, quận Cầu Giấy, Tp. Hà Nội// Tầng 3 toà Pijico 186 Điện Biên Phủ, Phường 6 Quận 3, TP. HCM.
☎ Hotline: 1900 638 399
? Email: support@fpt.ai
>>> ĐỪNG BỎ LỠ: