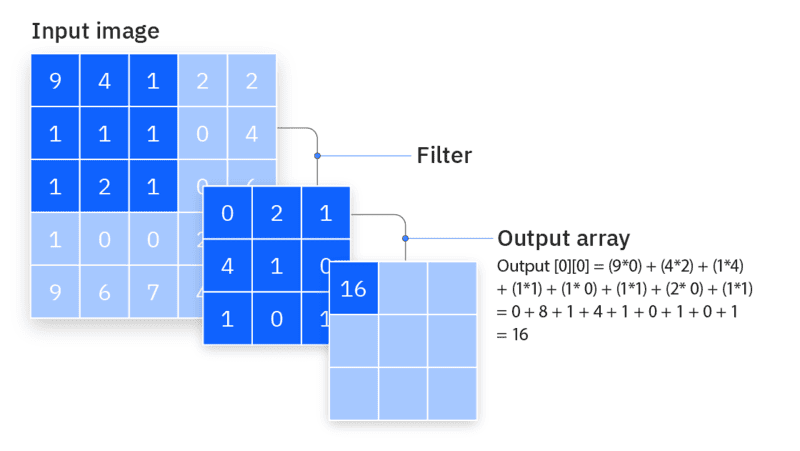
Trong kỷ nguyên công nghệ số hiện nay, trí tuệ nhân tạo (AI) và học máy (machine learning) đang dần trở thành nền tảng quan trọng trong việc phát triển các giải pháp công nghệ tiên tiến. Tuy nhiên, để các hệ thống AI có thể hoạt động hiệu quả và chính xác, việc chuẩn bị và gắn nhãn cho dữ liệu đóng vai trò vô cùng quan trọng. Cùng FPT.AI khám phá chi tiết về Data Labeling và vai trò của gán nhãn dữ liệu trong việc xây dựng và triển khai các mô hình trí tuệ nhân tạo.
Gán nhãn dữ liệu (Data Labeling) là gì?
Gán nhãn dữ liệu, hay còn gọi là Data Labeling, là quá trình gắn nhãn hoặc thẻ để cung cấp ngữ cảnh và ý nghĩa cho dữ liệu thô, giúp các mô hình học máy có giám sát (supervised learning) nhận diện các mẫu trong hình ảnh và đưa ra các dự đoán chính xác. Ví dụ, mỗi bức ảnh về con mèo sẽ được gán nhãn “mèo” để các hệ thống AI nhận diện và phân loại hình ảnh đó chính xác.
Đối với dữ liệu văn bản, Data Labeling giúp mô hình xử lý ngôn ngữ tự nhiên (NLP) hiểu được ngữ cảnh, sắc thái ngữ nghĩa, cảm xúc hay thông tin thực thể trong văn bản để thực hiện các nhiệm vụ phức tạp.
Gán nhãn dữ liệu là yếu tố then chốt trong việc đào tạo các mô hình học máy (Machine Learning) và trí tuệ nhân tạo, ảnh hưởng trực tiếp đến khả năng học từ dữ liệu. Nếu không có quá trình gán nhãn dữ liệu, doanh nghiệp sẽ rất khó – thậm chí không thể – đào tạo một hệ thống để thực hiện ngay cả những tác vụ cơ bản, lãng phí nguồn lực đầu tư.
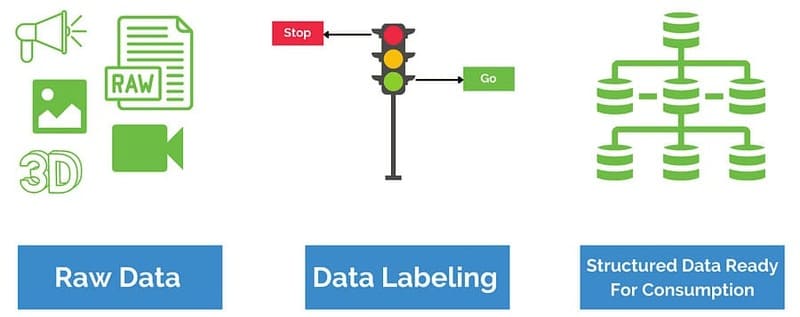
Tầm quan trọng của gán nhãn dữ liệu là gì?
Các lợi ích nổi bật mà gán nhãn dữ liệu mang lại cho doanh nghiệp bao gồm:
- Cách cung cấp dữ liệu gán nhãn chính xác, giúp các mô hình học máy hiểu đúng ngữ cảnh và đưa ra dự đoán chính xác.
- Tăng tốc độ học máy, cho phép các mô hình học nhanh hơn, giảm thiểu thời gian để đạt được độ chính xác mong muốn, từ đó giúp doanh nghiệp triển khai các giải pháp AI nhanh chóng hơn.
- Tính nhất quán của dữ liệu thông qua data labeling làm tăng độ tin cậy của các mô hình AI trong tài chính, y tế và tự động hóa. Ví dụ, gán nhãn chính xác trong các hệ thống nhận diện khuôn mặt đảm bảo nhận diện đúng các cá nhân, giúp doanh nghiệp tránh được các vấn đề về uy tín và pháp lý.
- Phát hiện sớm và sửa chữa kịp thời các lỗi trong dữ liệu trong quá trình gán nhãn, tránh ảnh hưởng đến kết quả cuối cùng của mô hình AI và các quyết định kinh doanh dựa trên mô hình đó.
>>> XEM THÊM: OCR là gì? Ưu điểm, tính năng của 5 phần mềm OCR tiếng Việt
Các phương pháp gắn nhãn dữ liệu phổ biến
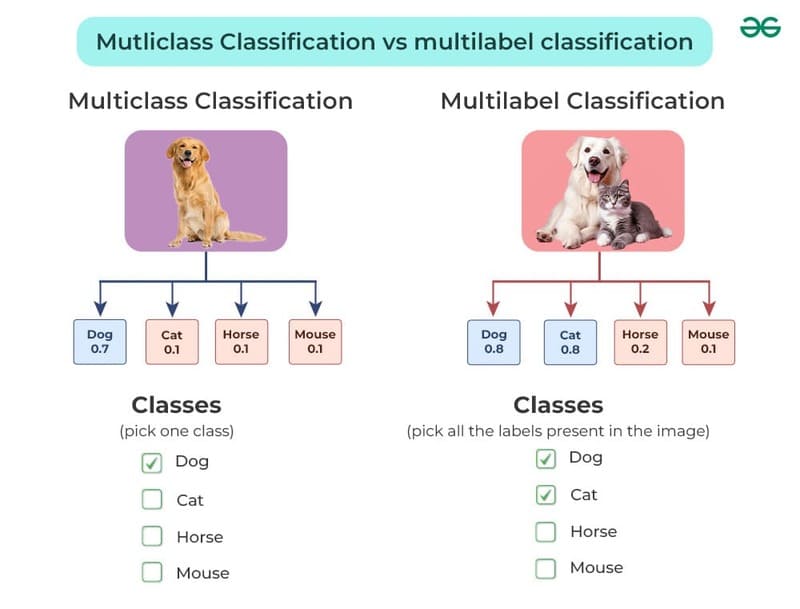
- Phân loại dữ liệu theo danh mục (Classification Labeling): Phương pháp này tập trung vào việc phân định dữ liệu thành các nhóm riêng biệt dựa trên đặc điểm chung. Ví dụ như khi một hệ thống được huấn luyện để nhận diện và phân biệt giữa các loài động vật khác nhau trong các hình ảnh.
- Gán nhãn cho từng phần tử trong dãy dữ liệu (Sequence Labeling): Kỹ thuật này đánh dấu riêng lẻ cho mỗi thành phần trong một tập hợp có thứ tự. Điển hình như trong xử lý ngôn ngữ tự nhiên, khi cần xác định vai trò ngữ pháp (danh từ, động từ, tính từ) cho từng từ trong câu.
- Đánh dấu đa đối tượng trong cùng một dữ liệu (Simultaneous Labeling): Áp dụng khi một đơn vị dữ liệu cần được gán nhiều nhãn cùng lúc cho nhiều thực thể khác nhau xuất hiện trong đó. Ví dụ trong một bức ảnh phong cảnh có người, động vật và các vật thể khác nhau.
- Gán nhãn đa chiều cho một đối tượng (Multi-label Labeling): Cho phép một mẫu dữ liệu đơn lẻ được gắn với nhiều thuộc tính hoặc phân loại khác nhau. Như khi một hình ảnh được gắn đồng thời các thẻ mô tả như “thiên nhiên”, “bầu trời”, và “hoàng hôn”.
- Gán nhãn theo diễn biến thời gian (Temporal Labeling): Phương pháp chuyên biệt cho dữ liệu thay đổi theo thời gian, đánh dấu các điểm dữ liệu dựa trên khung thời gian cụ thể. Ứng dụng trong việc phân tích các xu hướng biến động như dữ liệu thị trường chứng khoán theo từng giờ.
- Gắn nhãn bán giám sát (Semi-supervised Labeling): Kỹ thuật kết hợp giữa dữ liệu đã được gán nhãn và chưa được gán nhãn, đặc biệt hữu ích khi nguồn lực gán nhãn hạn chế. Giúp tối ưu hóa quy trình khi không thể gán nhãn cho toàn bộ dữ liệu vì lý do chi phí hoặc thời gian.
- Gán nhãn bán tự động (Semi-automatic Labeling): Cách tiếp cận lai ghép giữa hệ thống tự động và sự can thiệp của con người, trong đó máy tính thực hiện phần lớn công việc nhưng vẫn cần sự xác nhận hoặc điều chỉnh từ chuyên gia. Phương pháp này cân bằng giữa hiệu quả và độ chính xác.
Các nền tảng gắn nhãn dữ liệu hàng đầu hiện nay
Labelbox
Labelbox là nền tảng khuyến khích làm việc nhóm hiệu quả giữa các người gán nhãn, cho phép gán nhãn bằng hộp biên, đa giác, đường thẳng, kiểm tra chất lượng tùy chỉnh, đảm bảo các gán nhãn đạt tiêu chuẩn cao. Labelbox tích hợp nhiều giao thức bảo mật, bao gồm mã hóa và kiểm soát truy cập, giúp bảo vệ dữ liệu nhạy cảm trong suốt quá trình gắn nhãn.
Khả năng tích hợp và cộng tác làm cho Labelbox trở thành sự lựa chọn phổ biến cho các nhóm muốn tối ưu hóa nỗ lực gán nhãn dữ liệu. Tuy nhiên, một số người dùng vẫn gặp khó khăn khi điều hướng qua giao diện phức tạp và có sự chậm trễ trong việc nhận hỗ trợ kỹ thuật.
Scale AI
Scale AI là nền tảng cho phép gán nhãn đa dạng dữ liệu, bao gồm hình ảnh, văn bản và âm thanh với nhiều tùy chọn giá linh hoạt. Các tính năng nổi bật của Scale AI gồm tạo nhãn, chỉnh sửa nhãn, quản lý dự án, cộng tác, phát hiện và sửa lỗi, kiểm soát chất lượng tự động. Với khả năng tích hợp liền mạch với quy trình học máy hiện có thông qua APIs, Scale AI có thể xử lý hiệu quả các dự án quy mô lớn.
Appen
Appen là công cụ gắn nhãn dữ liệu tập trung vào ngôn ngữ, văn bản và hiểu biết ngữ nghĩa. Appen ưu tiên thực hành bảo mật mạnh mẽ, bao gồm mã hóa dữ liệu và quy trình xử lý dữ liệu an toàn, làm cho nó trở thành đối tác quý giá cho các dự án yêu cầu gán nhãn văn bản chính xác và tinh vi.
>>> XEM THÊM: Khai phá dữ liệu là gì? 9 công cụ và kỹ thuật Data Mining
CVAT
CVAT là công cụ mã nguồn mở được phát triển bởi Intel, hỗ trợ nhiều loại dữ liệu khác nhau bao gồm hình ảnh, video, âm thanh và văn bản. Ưu điểm của CVAT bao gồm khả năng sử dụng trực tuyến không cần cài đặt và hỗ trợ cộng tác. Nền tảng này cho phép tạo tác vụ công khai để phân chia công việc và chú thích tự động cho phép nội suy giữa các khung hình chính. Tuy nhiên, CVAT chỉ hỗ trợ trình duyệt hạn chế (yêu cầu Google Chrome), thiếu tài liệu hướng dẫn về mã nguồn và quy trình kiểm tra cần thực hiện thủ công.
LabelMe
LabelMe là công cụ gán nhãn trực tuyến được tạo bởi Phòng thí nghiệm Khoa học Máy tính và Trí tuệ Nhân tạo MIT. Công cụ này có thể sử dụng trực tuyến hoặc ngoại tuyến, chạy trên nhiều hệ điều hành với trình khởi chạy Python. LabelMe cho phép chú thích cờ hình ảnh, dọn dẹp và xuất phân đoạn ngữ nghĩa ở định dạng VOC và COCO. Dù cho phép người dùng tùy chỉnh giao diện, LabelMe không hỗ trợ việc cộng tác và quản lý dự án gán nhãn.
Dataturk
Dataturk là các nền tảng gán nhãn dữ liệu có phí hoạt động trên đám mây, cho phép tạo nhãn, chỉnh sửa nhãn, quản lý dự án, cộng tác và kiểm soát chất lượng. Nền tảng xử lý được loại dữ liệu khác nhau bao gồm hình ảnh, video, âm thanh và văn bản, phù hợp cho các dự án chuyên nghiệp yêu cầu độ chính xác cao và quy trình làm việc phức tạp.

>>> XEM THÊM: Text mining là gì? So sánh Text mining và Data Mining
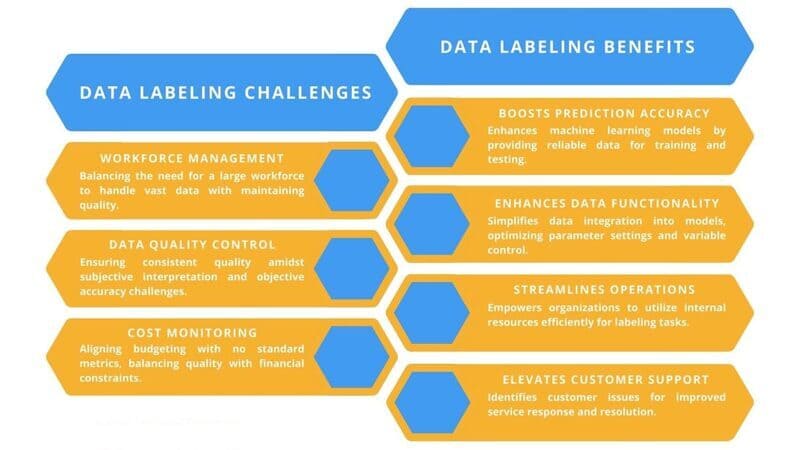
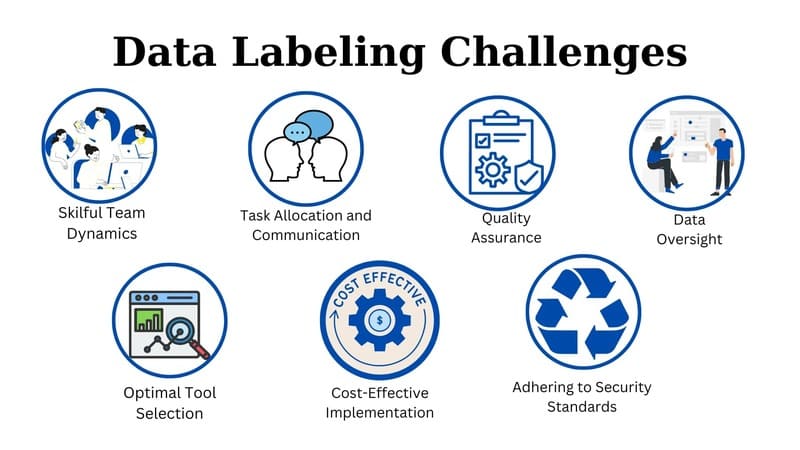
Thách thức trong Data Labeling
Nghiên cứu của Gartner chỉ ra rằng chất lượng dữ liệu kém có thể khiến các công ty mất khoảng 15% doanh thu. Tuy nhiên, với hàng triệu bản ghi dữ liệu cần được gán nhãn, chi phí, thời gian và công sức phải bỏ ra là rất lớn. Doanh nghiệp cần cân bằng giữa phương pháp gắn nhãn thủ công (thường có chi phí theo nhãn hoặc theo dự án thấp hơn) và tự động (chính xác hơn nhưng đắt đỏ) để đảm bảo độ chính xác, tốc độ tính hiệu quả khi xử lý ngữ cảnh phức tạp của các hệ thống học máy.
Việc duy trì sự nhất quán trong gán nhãn giữa các tập dữ liệu và giữa các người gán nhãn khác nhau là một thách thức lớn, vì những lỗi nhỏ trong quá trình gán nhãn có thể dẫn đến sai lệch lớn trong kết quả của mô hình AI. Ngoài ra, bảo vệ dữ liệu nhạy cảm khỏi các cuộc tấn công và truy cập trái phép là điều cực kỳ quan trọng, đặc biệt khi xử lý thông tin cá nhân hoặc y tế. Doanh nghiệp phải triển khai các biện pháp bảo mật mạnh mẽ như mã hóa, lưu trữ an toàn và kiểm soát truy cập nghiêm ngặt.
Tóm lại, gán nhãn dữ liệu không chỉ là một bước quan trọng trong quá trình phát triển hệ thống AI mà còn là chìa khóa giúp các mô hình học máy đạt được hiệu quả tối đa. Hiểu rõ và ứng dụng đúng cách Data Labeling sẽ giúp doanh nghiệp đạt được những kết quả tốt nhất trong các dự án AI, đồng thời tối ưu hóa thời gian và chi phí trong quá trình triển khai.
>>> XEM THÊM: