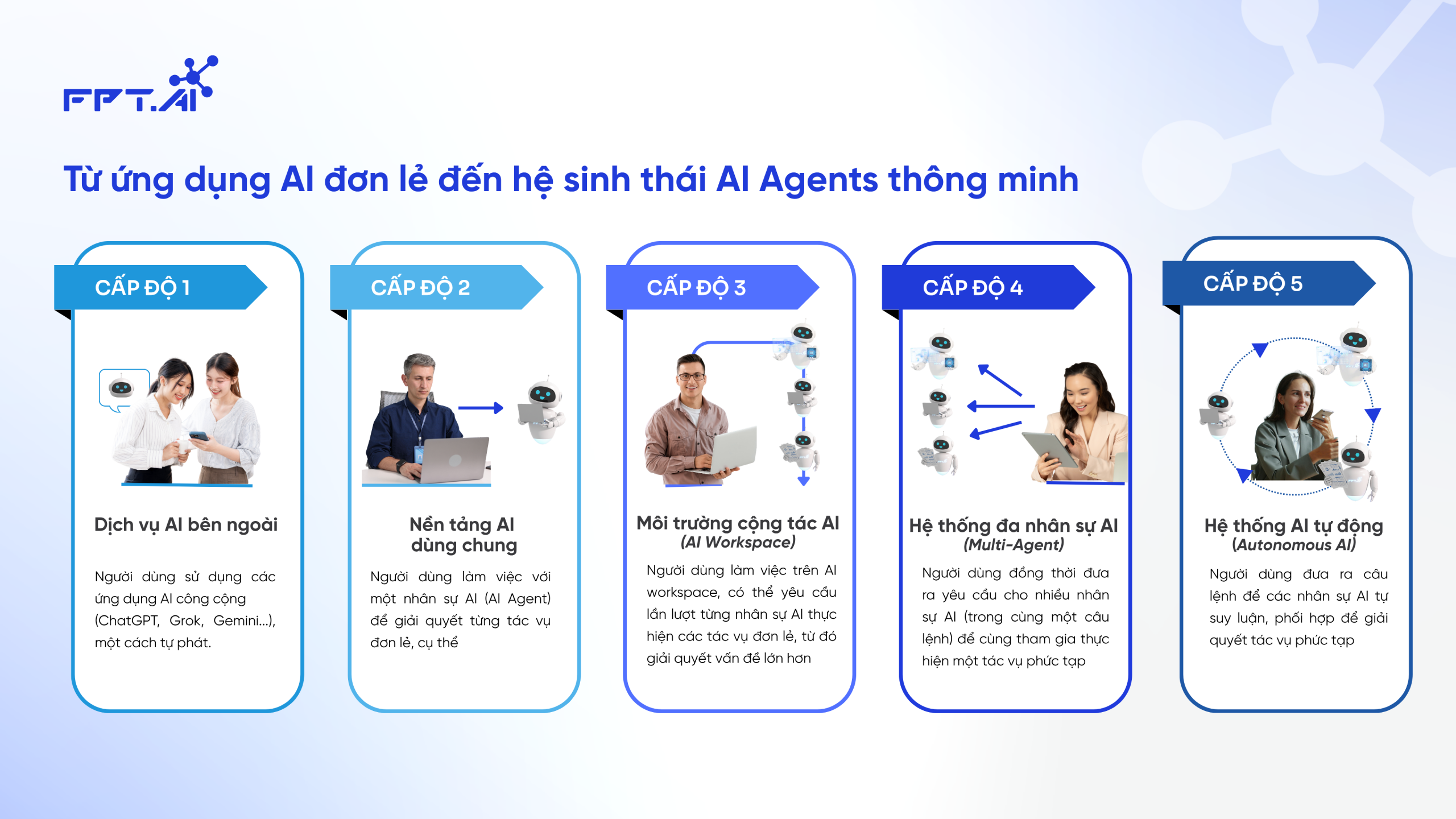
As artificial intelligence (AI) becomes increasingly integrated into various applications, large language models (LLMs) like ChatGPT or Google Gemini have demonstrated their vital role in processing and generating content. However, to better meet the demands of complex and ever-changing user requirements, a new solution has emerged: Retrieval-Augmented Generation (RAG).
So, what is Retrieval-Augmented Generation, and how does it help virtual assistants improve response quality to cater to the diverse needs of modern users? Let’s explore with FPT.AI!
What is Retrieval-Augmented Generation (RAG)?
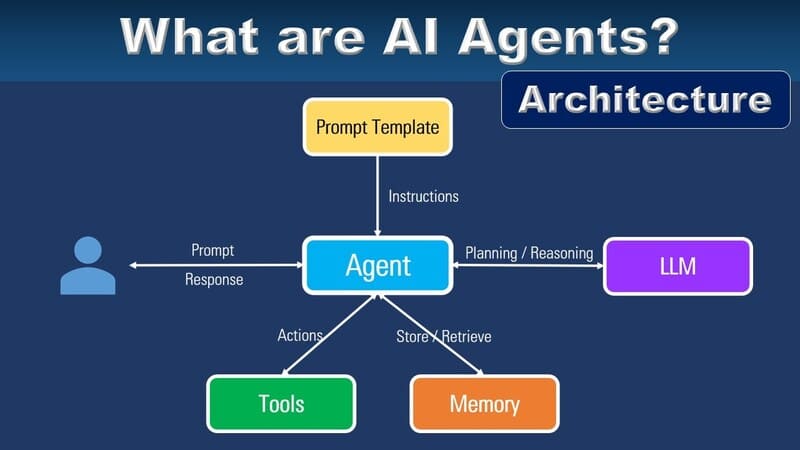
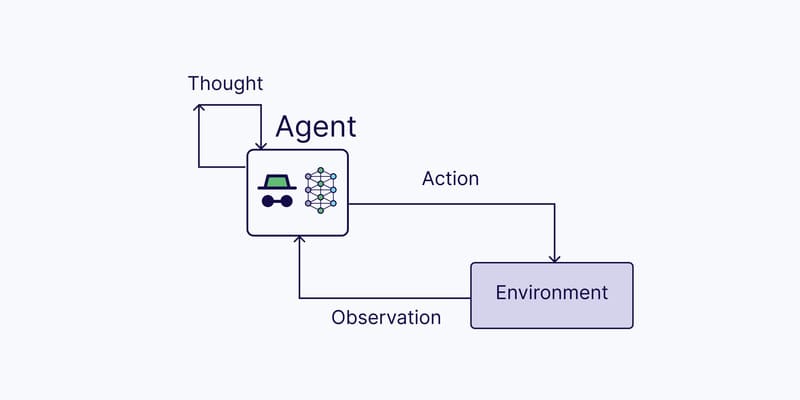
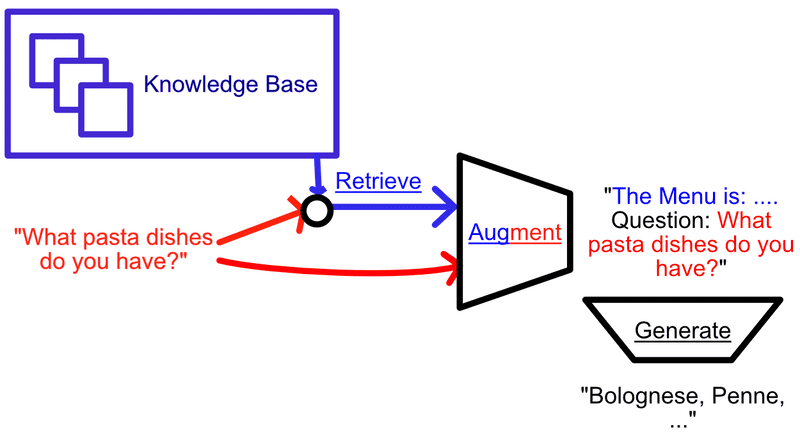
Retrieval-Augmented Generation (RAG) is an AI model designed to enhance the response quality of large language models (LLMs). RAG achieves this by incorporating a retriever tool that retrieves information from external knowledge sources, such as online resources, APIs, databases, or document repositories.
The retriever tool can be customized based on the desired semantic depth and accuracy level, including:
- Vector Databases: Queries are converted into dense vector embeddings using models like BERT (transformer-based models). Alternatively, traditional methods like TF-IDF can be used to create sparse embeddings. Searches are conducted based on semantic similarity or term frequency.
- Graph Databases: A knowledge base is constructed from relationships between entities extracted from text. While this method ensures high accuracy, it requires precise initial queries, which can be challenging in some cases.
- Regular SQL Databases: Store and retrieve structured data but are limited in their flexibility to handle semantic queries.
RAG is particularly useful when dealing with large volumes of unlabeled data, such as data from the internet. Although the internet hosts massive amounts of textual information, most of it is not organized to directly answer specific queries.
RAG models are commonly employed in virtual assistants and chatbots like Siri or Alexa, enabling them to understand questions, retrieve information from various sources, and deliver coherent and accurate answers in real time.
For instance, if you ask a virtual assistant, “How do I reset the ABC remote?”, RAG retrieves relevant information from product manuals or related documents. It then uses this data to generate a concise, clear, and accurate response tailored to the user’s query.
RAG’s ability to combine external knowledge with LLM capabilities makes it a powerful tool for improving user experiences, offering precise answers even in complex or domain-specific scenarios.
The Development History of RAG
In the 1970s, researchers began experimenting with and developing question-answering systems capable of accessing text on specific topics. This process, known as text mining, analyzed vast amounts of unstructured text and used software to identify data attributes such as concepts, patterns, topics, and keywords.
By the 1990s, Ask Jeeves—now known as Ask.com and a predecessor to Google—popularized these question-answering systems.
A major turning point came in 2017 when Google published the paper “Attention Is All You Need,” introducing the transformer architecture. This marked a significant advancement in creating and training large language models (LLMs) with improved scalability and efficiency. The following year, OpenAI launched GPT (Generative Pre-trained Transformer).
In 2020, RAG (Retrieval-Augmented Generation) was introduced as a framework. A team at Facebook AI Research (now Meta) in London developed a method for integrating a retrieval system into LLMs, enabling the models to generate more dynamic and grounded responses.
Today, RAG continues to evolve and expand its applications. This technology has been implemented in various prominent AI chatbots, including ChatGPT.
Why is RAG Important?
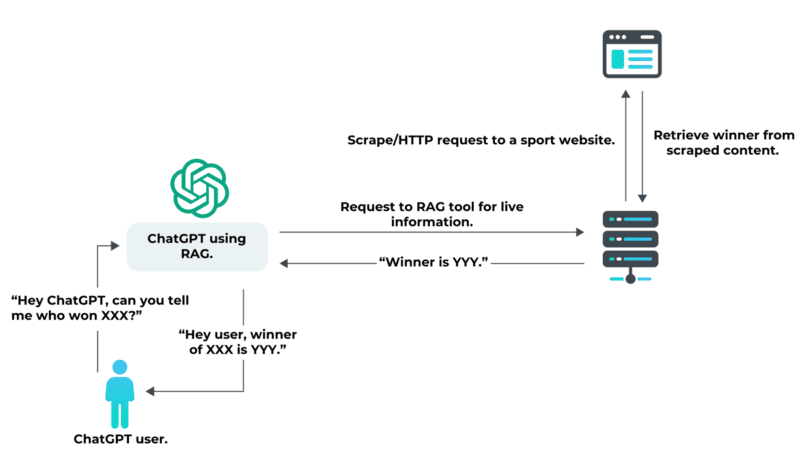
Large Language Models (LLMs), such as OpenAI’s ChatGPT or Google Gemini, are AI models capable of understanding, summarizing, generating, and predicting new content. However, these models are not always consistent and may struggle with tasks requiring specialized or updated knowledge, especially if the task goes beyond their training data. In such cases, LLMs can generate responses that sound fluent and logical but are actually incorrect—a phenomenon known as AI hallucination.
Additionally, when businesses possess vast and proprietary datasets, such as technical manuals or product guides, asking LLMs to extract specific information from this extensive data can feel like “finding a needle in a haystack.” Even GPT-4, OpenAI’s advanced model capable of handling large documents, can face challenges like the “lost in the middle” issue, where essential information in the middle of a document is overlooked.
Retrieval-Augmented Generation (RAG) was developed to address these limitations. RAG enables LLMs to retrieve information from external sources, allowing the model to access new and previously unseen data. This reduces knowledge gaps and minimizes AI hallucination. RAG represents a significant advancement for foundational AI models, chatbots, and question-answering systems, which require accurate, up-to-date, and specific information for users.
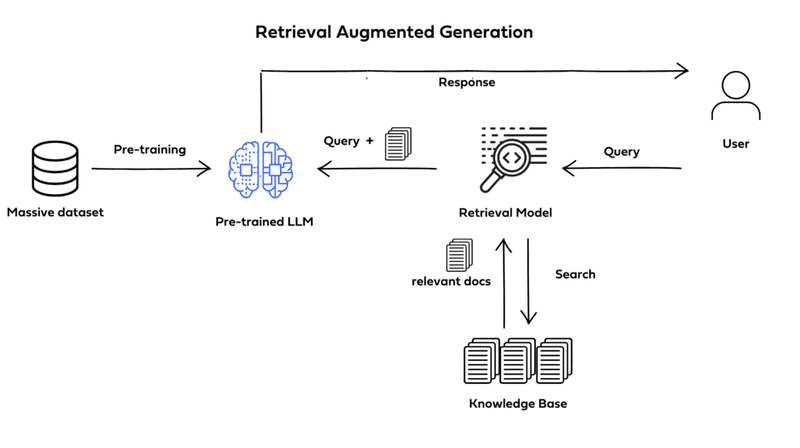
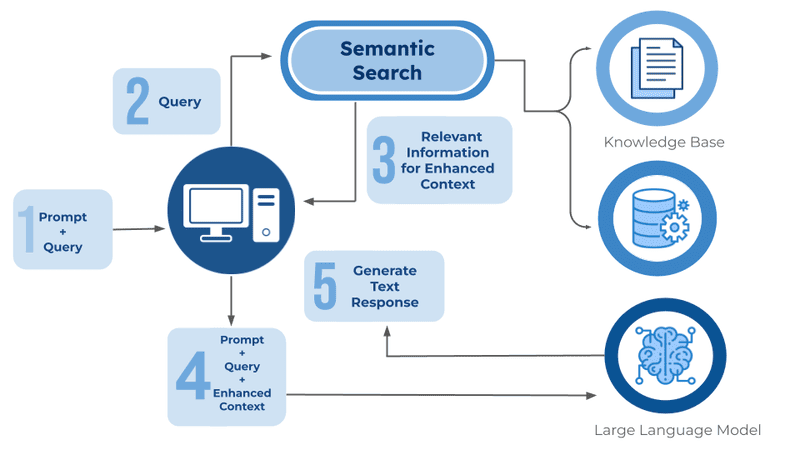
How RAG Works (Retrieval-Augmented Generation Pipeline)
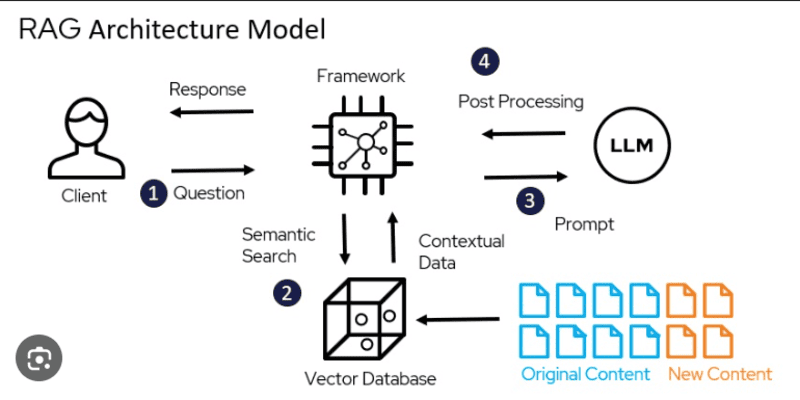
RAG integrates a text generator model with an information retrieval component, functioning by indexing each passage in a document. Upon receiving a query, RAG retrieves the most relevant passages (instead of the entire document) for LLMs such as ChatGPT, GPT-4, and others. This approach avoids information overload and significantly enhances response quality.
The RAG workflow operates as follows:
- Create a Vector Database: The entire knowledge dataset is converted into vector embeddings and stored in a vector database.
- Receive User Query: The user inputs a query in natural language.
- Retrieve Information: The retrieval mechanism scans all vectors in the database to identify passages with semantic similarity to the user’s query. These passages provide additional context for processing.
- Combine Data: The retrieved passages are combined with the original query to form a complete prompt.
- Generate Response: The context-enhanced prompt is input into the LLM, which produces the final response tailored to the added context from the relevant passages.
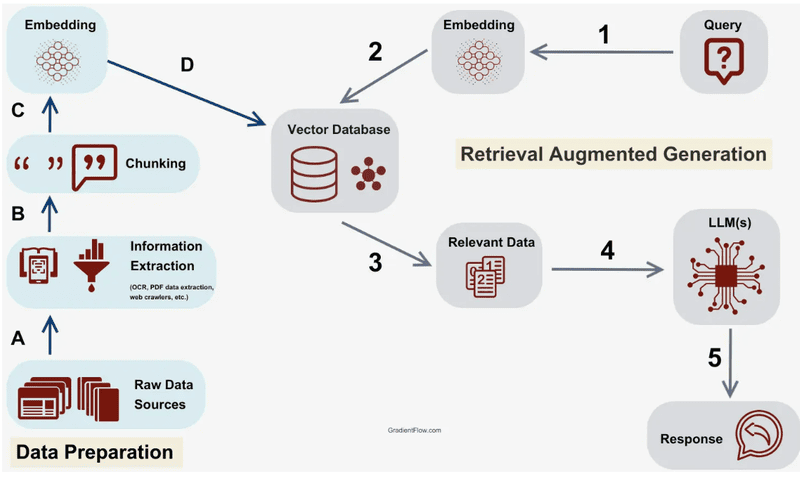
Which one is better in RAG: Graph Databases or Vector Databases?
Compared to vector databases, graph databases are often preferred in RAG due to their ability to store knowledge with high accuracy.
Vector databases divide and index data using vectors encoded by LLMs to retrieve information based on semantics. However, this method can sometimes lead to irrelevant information retrieval, causing inaccuracies. On the other hand, graph databases focus on constructing knowledge bases with clear relationships between entities, making the information retrieval process shorter and more accurate.
However, graph databases require queries to align with the way the data is structured and interconnected. This means that if users are unfamiliar with the structure and relationships of the data, retrieving the desired information can become challenging.
Benefits of RAG
RAG offers several advantages:
- Provides up-to-date information: RAG retrieves information from relevant, reliable, and the most recent sources.
- Enhances user trust: Depending on the AI implementation, users can access the data sources used by the model, promoting transparency, trust in the content, and the ability to verify the accuracy of the information.
- Reduces AI hallucinations: Since LLMs are connected to external data, the chances of generating or returning misleading information are significantly reduced.
- Lowers computational and financial costs: Organizations do not need to continuously retrain models with new data, saving time and resources.
- Aggregates information: RAG combines data from retrieval sources and generative models to produce comprehensive and relevant responses.
- Easier to train: RAG does not require retraining the model, saving time and computational resources.
- Versatile applications: Beyond chatbots, RAG can be tailored for specific use cases such as text summarization and conversational systems.
Challenges of implementing RAG
Despite its advantages, RAG also has some challenges and limitations, including:
- Accuracy and data quality: Since RAG retrieves information from external sources, the response’s accuracy depends on the quality of the data it collects. RAG cannot independently evaluate the accuracy of the retrieved data, making it reliant on the quality and reliability of the data sources.
- Computational cost: RAG requires a model and a retrieval component capable of integrating retrieved data effectively, leading to high resource consumption.
- Transparency: Some systems may not be designed to reveal the origin of the data, which can affect user trust.
- Latency: Adding a retrieval step to the LLM process can increase response time, especially if the retrieval mechanism needs to search large knowledge bases.
Comparison: Retrieval-Augmented Generation (RAG) vs. Semantic Search
Semantic search is a data retrieval technique that focuses on understanding the intent and contextual meaning behind search queries. This technique uses Natural Language Processing (NLP) and Machine Learning (ML) algorithms to analyze factors such as query terms, previous search history, and geographic location. It is more efficient than keyword-based searches, which only attempt to match exact words or phrases in queries. Semantic search is widely used in web search engines, content management systems, chatbots, and e-commerce platforms.
While RAG aims to improve the response quality of an LLM by incorporating data from external sources, semantic search focuses on enhancing the accuracy of searches by better understanding user queries and search intent.
The two methods can complement each other. Semantic search can improve the quality of RAG queries by providing a deeper understanding of the search intent, enabling RAG systems to generate more accurate and meaningful responses.
When used independently, RAG is suitable for applications requiring the most up-to-date information, while semantic search is ideal for applications where understanding user intent is critical for improving search accuracy.
In conclusion, Retrieval-Augmented Generation (RAG) has demonstrated immense potential in enhancing the capabilities of Large Language Models (LLMs) by combining external data with advanced algorithms. Not only does it address limitations like AI hallucination and knowledge gaps, but RAG also unlocks new applications across various domains, from virtual assistants and chatbots to intelligent question-answering systems.
We hope this article from FPT.AI has provided you with valuable insights into the potential and applications of RAG technology.
If you need more in-depth consultation about the FPT GenAI ecosystem, feel free to contact us. This is an advanced Generative AI platform, focusing on five key factors:
- Powerful Performance: FPT GenAI is designed with the capability to process data at lightning speed, achieving up to 12,000 tokens per second. With a maximum context length of 128,000 tokens, the platform comprehends complex scenarios better. It also integrates 8 billion parameters to handle large and diverse datasets, ensuring optimal performance.
- Multilingual Support: The platform supports interactions in multiple languages, including Vietnamese, English, and Indonesian, enabling businesses to expand their operations internationally and meet the demands of multilingual and multicultural communication flexibly and naturally.
- Integration with Chatbots on Messaging Platforms: FPT GenAI supports a variety of interaction formats, from text and images to Carousel, allowing businesses to effectively deploy customer care solutions, provide online consultation, or support group chats, optimizing the conversational experience.
- Retrieval-Augmented Generation (RAG): Leveraging RAG technology, FPT GenAI utilizes knowledge from internal and reliable data sources of businesses. The platform is capable of tailoring responses to industry-specific requirements, ensuring accurate, up-to-date, and high-quality feedback that delivers practical benefits during operations.
- Customizable Language Models: FPT GenAI is designed to meet the unique needs of each business. Advanced techniques like zero-shot and few-shot learning reduce time-to-market while supporting the rapid development of tailored solutions to meet specific business requirements efficiently.
Explore FPT GenAI today to experience the breakthroughs that RAG technology and Generative AI bring to your business.
Reference:
- TechTarget. (n.d.). What is Retrieval-Augmented Generation (RAG)?. Retrieved January 18, 2025, from https://www.techtarget.com/searchenterpriseai/definition/retrieval-augmented-generation
- Viblo. (n.d.). ChatGPT Series #5: Understanding Retrieval-Augmented Generation (RAG). Retrieved January 18, 2025, from https://viblo.asia/p/chatgpt-series-5-tim-hieu-ve-retrieval-augmented-generation-rag-Ny0VGRd7LPA