Text to Speech (TTS) is a technology that converts digital text into natural-sounding audio, allowing computers to read content aloud in a voice that closely resembles human speech. Demand for this technology is growing rapidly, with a projected CAGR of 13.7% between 2024 and 2029. According to Markets and Markets, the TTS market is expected to reach USD 7.6 billion by 2029.
In this article, FPT.AI explores the development, working mechanism, real-world applications, limitations, and future trends of Text-to-Speech technology.
What is Text-to-Speech?
TTS is also known as “speech synthesis” or “computer-generated voice technology”. Most TTS services are offered as APIs, allowing developers to easily integrate voice capabilities into apps, websites, or digital services.

Originally designed to assist individuals with visual impairments or dyslexia, TTS has evolved into a foundational technology powering virtual assistants, automated call centers, and GPS navigation systems. Today, it plays a key role in human-machine interaction and is making the digital world more accessible for everyone.
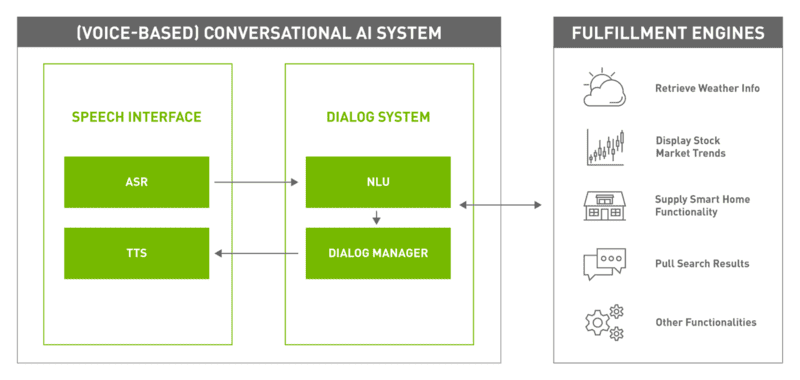
The Evolution of Text-to-Speech Technology
The first electronic speech synthesizer appeared around the 1930s and marked the beginning of TTS development. These early devices had minimal capabilities and were primarily used for research.
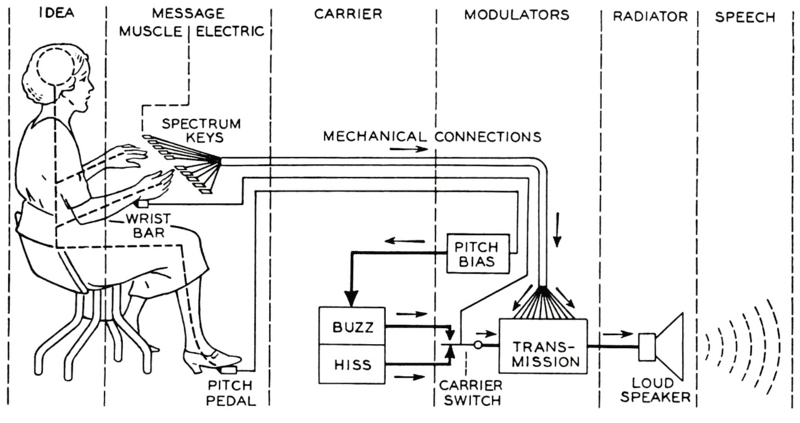
In the late 1950s, with the advent of computers, developers began experimenting with algorithms that matched audio files to text components. These early systems produced robotic and unnatural voices.
A major breakthrough came in the 2000s when Deep Learning and neural networks entered the scene. Instead of piecing together pre-recorded sounds, developers began modeling sound waves using real voice recordings.
This shift led to much more realistic, high-quality synthetic voices. At the same time, there were advancements in Automatic Speech Recognition (ASR) and Natural Language Processing (NLP), which laid the groundwork for modern TTS systems.

In the past decade, AI and Machine Learning have further enhanced voice realism—making synthetic speech nearly indistinguishable from human voices. However, this progress also introduces ethical concerns, particularly around audio deepfakes, which mimic real voices without consent. To combat this, tech companies are developing real-time voice detection tools to identify deepfakes and ensure the responsible growth of TTS technology.

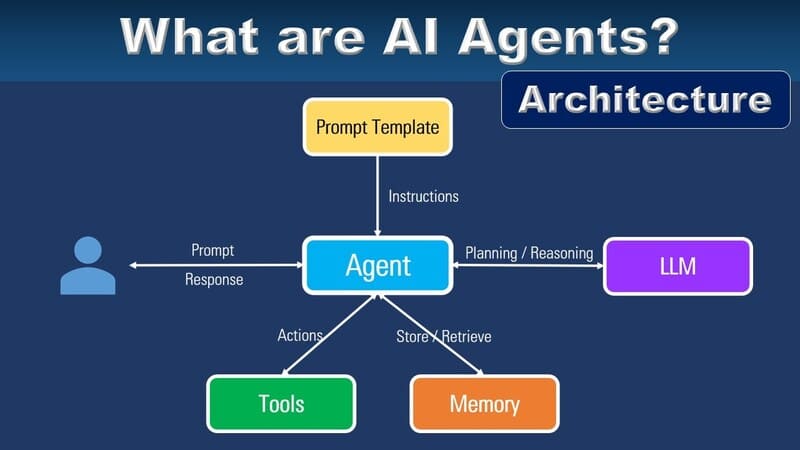
How Does Text-to-Speech Work?
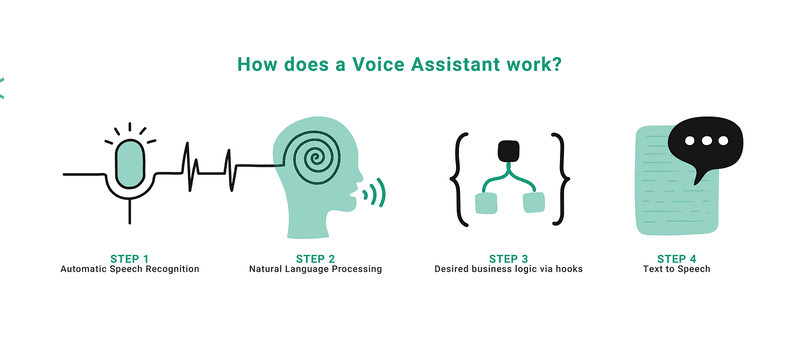
TTS involves both linguistic analysis and speech synthesis. Deep learning models help TTS systems understand how words relate to their audio characteristics and generate realistic AI voices.
Linguistic Analysis
When given a text input, the TTS model first analyzes it using deep neural networks. It examines words, punctuation, and sentence structure to understand intonation, pitch, rhythm, and volume. The system also expands abbreviations, calculates word lengths, determines proper pronunciation, and maps prosody (intonation patterns) across sentences.
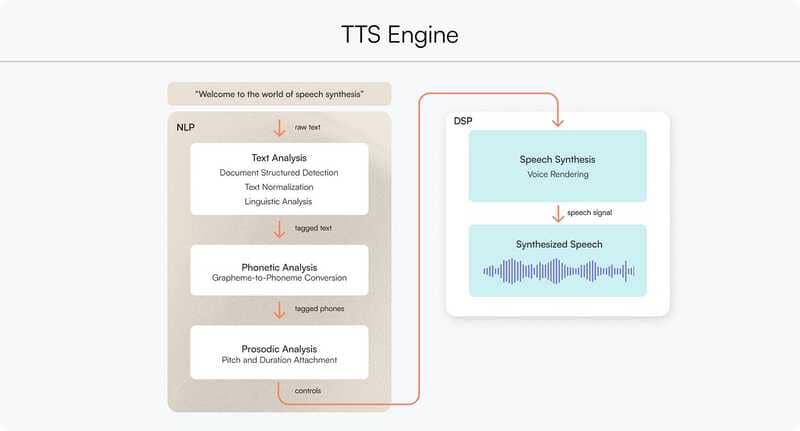
Speech Synthesis
Once the text has been processed, the model converts it into speech using two main steps:
Generate audio features: The model transforms the text into time-aligned features like mel spectrograms, which map changes in sound frequency over time. These features capture detailed characteristics of speech, including pronunciation and emphasis.
Convert to sound waves: A vocoder model, such as WaveNet or WaveGlow, transforms the spectrogram into an actual audio sound wave that sounds natural. Some TTS systems also allow users to adjust pitch, volume, speed, language, accent, or speaking style
TTS systems are built into many devices, such as smartphones, and are available via software, browser extensions, websites, or downloadable apps.
Real-World Applications of Text-to-Speech
TTS is a key component of Conversational AI, especially in applications using Automatic Speech Recognition (ASR) and Natural Language Processing (NLP). It’s a game-changer for people who want to access content hands-free in a fast-paced world.
Here are some major use cases of TTS:
- Audio Content: TTS reads digital text, books, lessons, and instructions aloud. News organizations use TTS to convert articles into audio formats for more flexible content access.
- Education & Learning: TTS supports students by helping them follow along with text, improve pronunciation, and retain information. It’s especially helpful for people with visual impairments or learning disabilities like dyslexia.
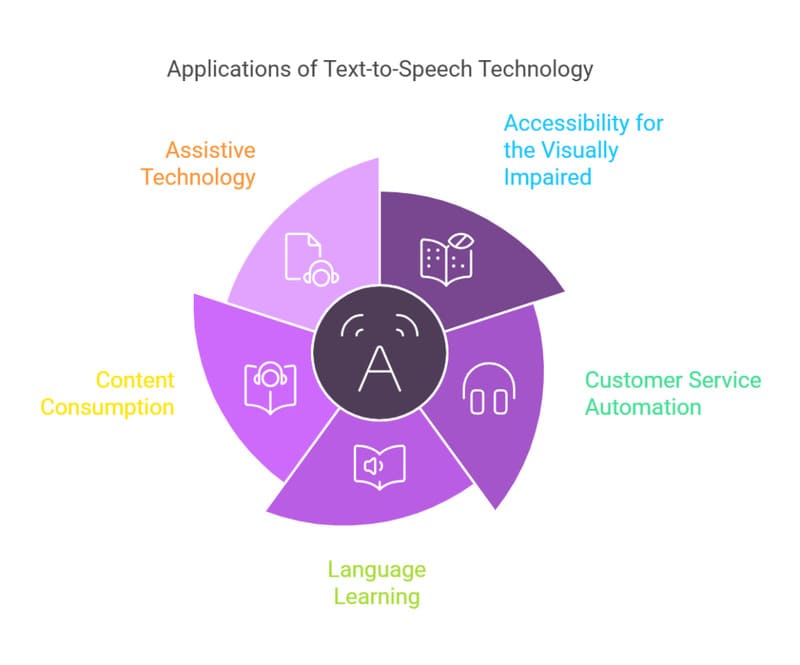
- Virtual Assistants & Chatbots: Virtual assistants like Siri, Google Assistant, and Alexa use both TTS and STT (Speech to Text) to create natural, responsive interactions. They can read messages, make announcements, assist while driving, and offer 24/7 customer support.
- GPS Navigation & Maps: TTS enables real-time spoken directions, helping drivers stay focused. It reads street names, traffic alerts, and alternate routes for safer travel.
- Multilingual Communication & Language Learning: Apps like Google Translate use TTS to help users understand and pronounce foreign words. It also powers voice-overs for video content in different languages.

- Media & Entertainment: TTS creates narration for games, voices for animated characters, and transforms written books into audiobooks, reducing production costs and expanding content accessibility.
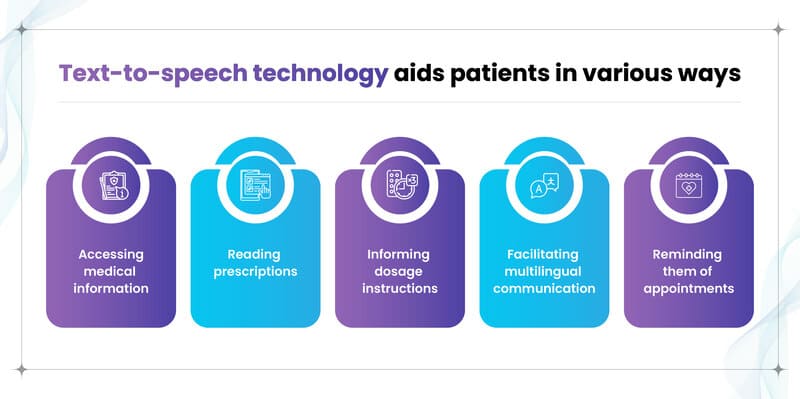
- Healthcare: TTS reads medical documents, device instructions, and prescriptions to patients. It reminds patients of appointments and medication schedules, especially useful for those with visual or speech impairments.
- Marketing & Advertising: TTS generates voice content for ads without the need for voice actors. It enhances personalization in campaigns via voice chatbots and email marketing.
- IoT & Smart Homes: TTS is built into smart speakers, watches, and home security systems. Devices can speak alerts, schedules, or weather updates, offering seamless, voice-based interaction.
- Customer Service & IVR Systems: TTS powers automated phone systems that answer calls and provide spoken options. When paired with voice recognition, these systems can handle complex queries and deliver voice responses, replacing traditional call center agents.

Challenges in Implementing Text-to-Speech
Despite its progress, TTS still faces some limitations:
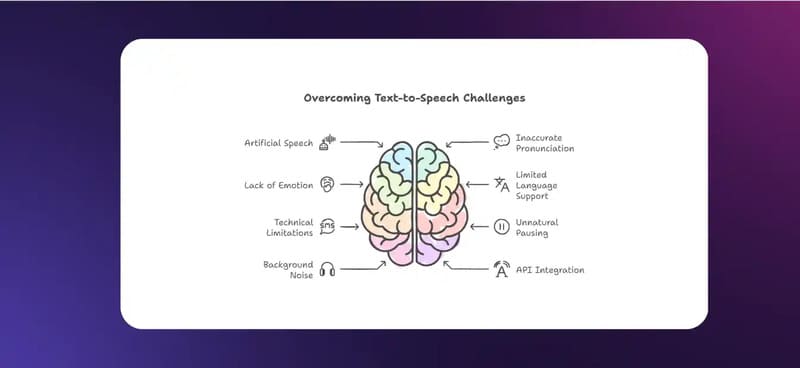
- Voice quality still sounds robotic: Some TTS systems still generate flat, machine-like voices that lack natural flow and can hinder listener engagement.
- Lack of emotional tone: TTS struggles to convey emotions like happiness, sadness, or surprise, making it less suitable for expressive content like storytelling or film dubbing.
- Mispronunciation of special terms: TTS often misreads names, slang, foreign words, or technical terms, leading to confusion in fields like healthcare, finance, or technology.
- Incorrect context interpretation: Unlike humans, TTS systems often fail to understand context, which affects rhythm, pauses, and emphasis.
- Inconsistent handling of abbreviations: TTS may pronounce the same abbreviation in different ways within a single document.
- Incomplete multilingual support: While many TTS systems support multiple languages, they often struggle with mixed-language texts, mispronouncing foreign terms.
- Inconsistent tone in long texts: TTS voices can lose consistency across long passages, leading to abrupt changes in tone.
- Poor sentence pacing and emphasis: TTS often places pauses and pitch changes in unnatural spots—especially problematic for tonal languages like Vietnamese, Chinese, Korean, or Japanese.
- High hardware requirements: Modern AI-based TTS systems require significant computing resources, making them harder to implement on low-power or mobile devices.
- Limited voice personalization: While some systems allow basic voice customization, fully cloning or personalizing a unique voice is still a major challenge.
Future Trends of TTS Technology
- Here’s what the future holds for TTS:
- AI integration to improve voice quality: Advanced AI models like Transformers, WaveNet, and Tacotron are making synthetic voices more human-like. These models can better understand context, adjust tone, and pronounce words accurately across different languages and cultures.
- Voice Cloning: This enables TTS to replicate a specific individual’s voice. It’s great for personalized audiobooks, virtual assistants, or customer service bots, making user interaction feel more authentic.
- AI Dubbing: This innovation syncs speech with lip movements in videos. It revolutionizes dubbing for films, educational content, and online media by making translations more accurate and lifelike.
- Voice Conversion: This allows you to convert one person’s voice into another without re-recording. It’s especially useful in gaming, animation, or podcast production, offering flexible voice creation without additional effort.
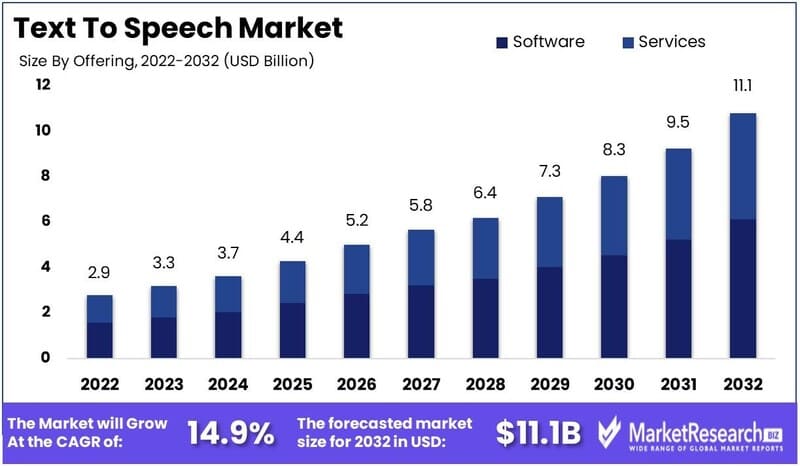
In conclusion, Text to Speech technology has become an essential technology in many fields from education, healthcare, marketing to route navigation, virtual assistants, and smart homes. Although there are still some limitations, TTS is constantly improving significantly. The strong growth of the global TTS market reflects the increasingly important role of this technology in improving human-to-machine communication and building a more accessible digital world for everyone.