Large Language Models (LLMs) are becoming a breakthrough trend in automating and optimizing customer interaction processes. In this article, FPT.AI will introduce you to how large language models work, practical applications in many different fields, along with the advantages and disadvantages to note when applying this advanced technology.
What is a Large Language Model (LLM)?
Large Language Models (LLMs) are machine learning models trained on huge text data sets. The model data comes from information sources such as books, articles, websites and other documents on the internet, with the number of parameters of the models up to billions, even trillions.
The largest and most powerful LLMs today are built on the Transformer architecture, which is capable of unsupervised learning and capturing the semantics of text without needing specifically labeled data. They can process data in parallel instead of sequentially like Recurrent Neural Networks (RNNs), leveraging the power of GPUs to improve the speed of natural language processing.
Notable features of large language models:
- Learning ability: LLMs can learn from data, continuously improving their language processing ability over time.
- Generalization ability: This model can generalize knowledge from data and flexibly apply it to new situations.
- Creativity ability: LLMs can generate new content, translate languages, write creatively, and answer questions intelligently based on the context of the question.

The architecture of Large Language Models
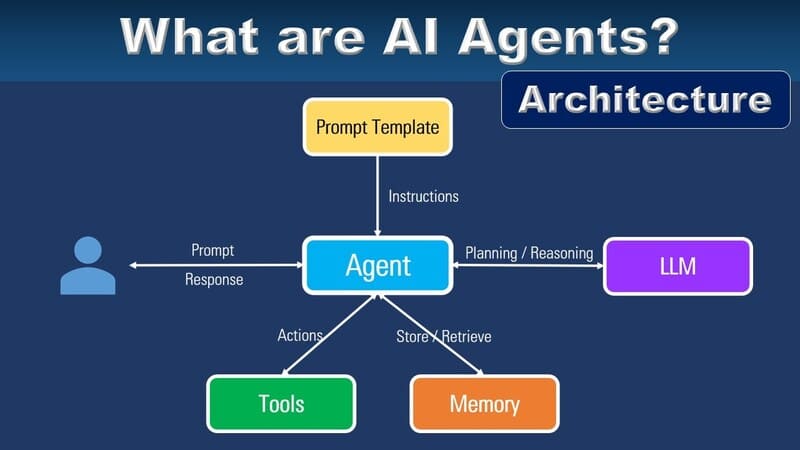
The architecture of LLM consists of multiple layers of neural networks that work together to process input text and generate output predictions. The main components include:
- Embedding Layer: Converts each word or token in the input text into a high-dimensional vector representation. These vectors help the model capture the semantic and syntactic information that makes up the word, sentence, or token to understand the context of the text.
- Feedforward Layers: Consists of multiple interconnected layers that apply non-linear transformations to extract abstract information from the embedding vectors.
- Recurrent Layers: Designed to process text sequentially, maintaining a continuously updated hidden state, helping the model understand the relationships between words in a sentence.
- Attention Layers: Important components that allow the model to focus on the most relevant parts of the input text. This mechanism helps to improve prediction accuracy and better understand context.
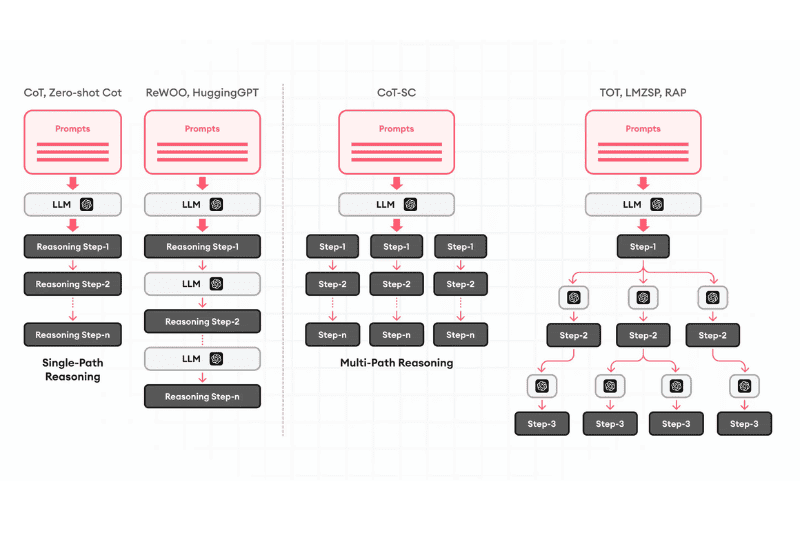
How do Large Language Models Work?
A large language model consists of two main components: an encoder and a decoder. The encoder extracts features from the input, and the decoder uses this information to predict or generate output.
When given a prompt, the LLM uses multidimensional vectors, also known as word embeddings, to represent words that have similar meanings or close contextual relationships in a vector space. This helps the model understand the semantics of individual words, the relationships between words and sentences in the text, and respond logically.
During training, the large language model learns to accurately predict the next token in the input data sequence by continuously adjusting its parameters through self-learning techniques. The ultimate goal of the LLM is to generate coherent and contextually relevant text.
What are the applications of large language models?
Large language models are used in various fields, including:
- Creating AI Chatbots and AI assistants that respond like humans to help businesses improve customer service and experience.
- Classifying customer comments, searching for documents, and organizing text data based on semantics.
- Improving the accuracy of search results by providing more direct and contextual answers.
- Analyzing protein, molecule, DNA, and RNA sequences in biological research.
- Converting natural language prompts into programming code, automating software development.
- Analyzing financial transactions to detect anomalies and protect consumers.
- Creating transcripts of important meetings or summarizing content from calls.
- Creating articles, poems, scripts, or songs.
ChatGPT, based on the GPT-3 model (175 billion parameters), is one of the most typical and popular applications of LLM. Developed by OpenAI, ChatGPT is capable of conversing with users naturally and interacting intelligently based on the context of the conversation. Individuals and businesses can use ChatGPT to translate, summarize text or create new content.
Some other notable large language models:
- Claude 2 (Anthropic): Although the exact number of parameters of Claude 2 is not announced, this model is capable of receiving input of up to 100,000 tokens, allowing it to read and process hundreds of pages of technical documents or even entire books.
- Jurassic-1 (AI21 Labs): Jurassic-1 is one of the largest LLM models today with 178 billion parameters. It has a token vocabulary of 250,000 elements and is capable of generating very natural, human-like text.
- Command (Cohere): Cohere’s Command model is also an LLM with the ability to operate in more than 100 different languages.
- Paradigm (LightOn): Paradigm is a platform that provides LLM models with features that are announced to be superior to GPT-3.
In the digital era, applications that support large language models (LLMs) such as chatbots, virtual assistants and sentiment analysis tools are leading the trend of automating customer interactions. FPT AI Engage is a typical example, successfully applying LLMs to the field of automatic switchboards, helping businesses automate call handling and customer interactions

FPT AI Engage successfully applies LLM to the field of automatic switchboards
At the AI Awards 2022 organized by VnExpress, FPT AI Engage was honored in the Top 5 best projects. This voicebot solution is designed to automate outgoing calls (Outbound calls), receive incoming calls (Inbound calls) and intelligently forward calls (Smart IVR).
Thanks to its ability to understand and interact naturally with an accuracy of up to 92%, FPT AI Engage helps to effectively handle simple tasks, answer customer questions, and reduce the workload for switchboard operators, allowing them to focus on more complex tasks.

FPT AI Engage has been trusted by large enterprises such as VIB, SeABank, FWD and HomeCredit Vietnam. In particular, HomeCredit Vietnam with more than 5 million calls/month has saved 50% of operating costs and improved call center performance by up to 40% thanks to this solution.
FPT AI Engage is an important step in applying artificial intelligence to optimize call center operations and enhance customer experience. To learn more about FPT.AI’s Large Language Model application solution or receive detailed advice, please contact hotline 1900 638 399 or visit the website.