FPT AI Reader is an application that leverages OCR (Optical Character Recognition) technology to accurately recognize and extract content from existing document templates (such as personal documents and invoices) as well as custom document formats (such as contracts and certificates). This allows for quick and convenient digitization of documents. This article explains how FPT.AI utilizes FPT AI Reader to extract information from images—let’s explore together!
Account Registration and Language Selection for FPT AI Reader
Developed by experts at FPT.AI, the FPT AI Reader application integrates artificial intelligence (AI), computer vision, OCR, and intelligent document processing (IDP) technologies. It also combines image processing techniques with natural language processing (NLP), enabling users to accurately digitize documents within seconds while ensuring high security and ease of storage.
To use the FPT AI Reader application, an FPT ID account is required. If you don’t have an account, register here: https://id.fptcloud.com/. After registration, visit: https://reader.fpt.ai/ to start your experience!
The FPT AI Reader application supports two languages: English and Vietnamese. Click the icon in the upper-right corner of the screen to select your preferred language.
How to extract information using FPT AI Reader’s existing document library
To extract information from image documents already available in FPT AI Reader’s library, follow these steps:
Selecting a Document Template
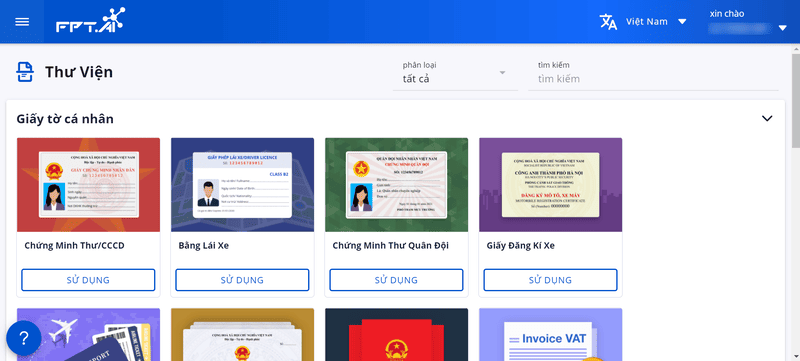
Click the Library button in the upper-right corner of the screen. The FPT AI Reader interface will display pre-integrated document templates within the application, offering up to 98% extraction accuracy.

FPT AI Reader currently supports digitization of various document templates across multiple industries, including:
- Identification documents (ID cards, driver’s licenses, passports, birth certificates)
- Financial documents (invoices, insurance policies)
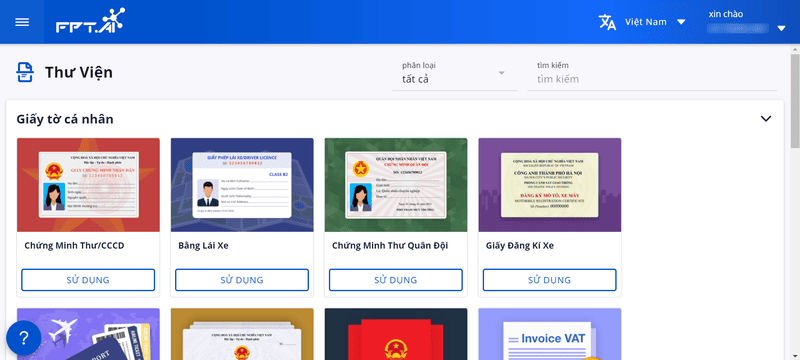
FPT AI Reader supports the digitization of document templates from different industry sectors
To get started, you need to click on the type of document you want to extract data from, name your project and click Create. In this article, we will take a driver’s license document as an example.
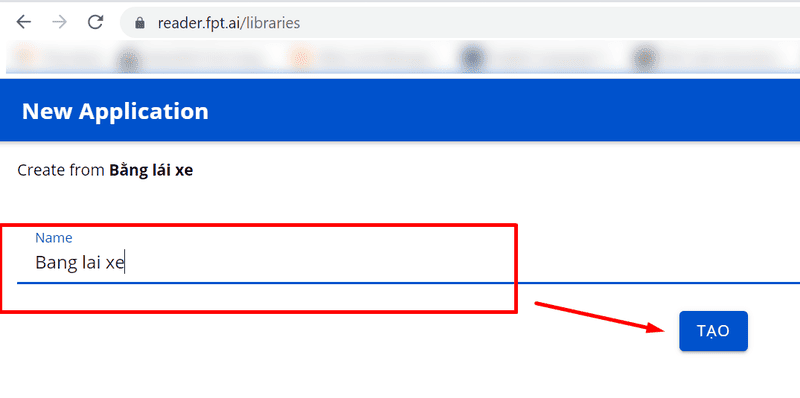
Select the document type you want to extract data from
At this point, the screen interface will display the key information fields and associated data (name, status, update time, creation time, model use, and action) that will be used in extracting driver’s license information.
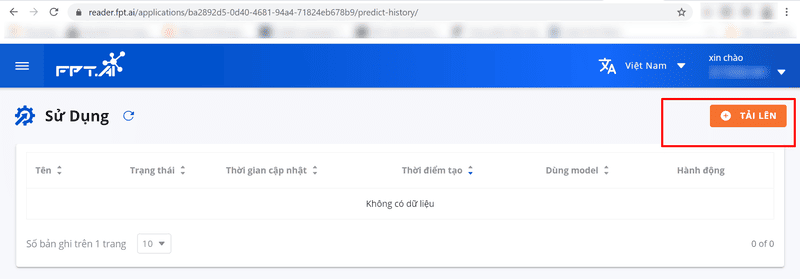
Uploading Data
Click the Upload button in the upper-right corner of the screen to upload an image of the driver’s license to the system.
- Note: Each file must not exceed 5MB, and supported formats include JPG, PNG, and PDF.
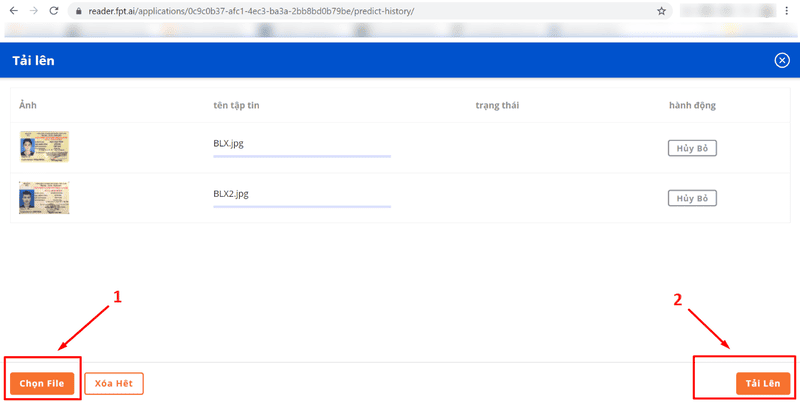
To upload multiple image files simultaneously, click Select Files (1) at the bottom-left corner of the screen, select the images, and then click Upload (2) to complete the process.
Once the driver’s license image is successfully uploaded, FPT AI Reader will automatically process it within seconds, changing the image status to Processed. At this stage, you can click on each row to view the extracted data.
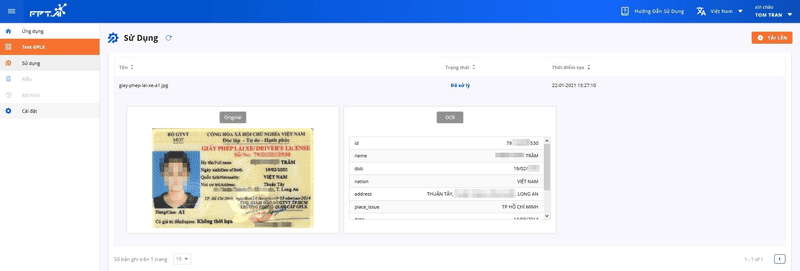
Image processed by FPT AI Reader
(Note: the image is for reference only, it has no real value) Do the same with other successfully uploaded driver’s license images. Using OCR technology, FPT AI Reader can recognize with high accuracy even when the image is blurred, the characters are unclear, there are areas of different colors, the characters are overlapping, the image is not aligned, etc. (For example, the red mark overlaps “ngày/date 05 tháng/month 07” in the image below).
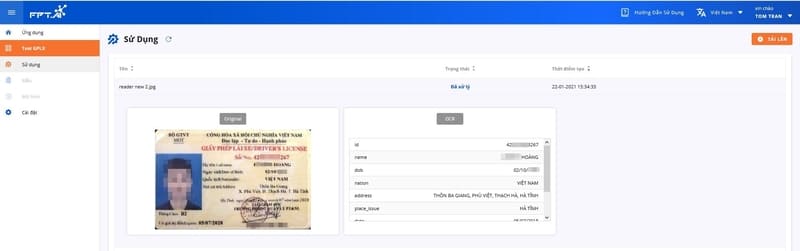
FFPT AI Reader can recognize text with high accuracy even when red marks are overlapping the text.
(Note: Images are for reference only and have no practical value)
Setting User Permissions
FPT AI Reader provides the ability to set role-based access rights for other individuals in the same organization. Users with access rights can access the database or contribute data directly to projects. Click Settings in the application bar on the left side of the screen to set permissions for other users.
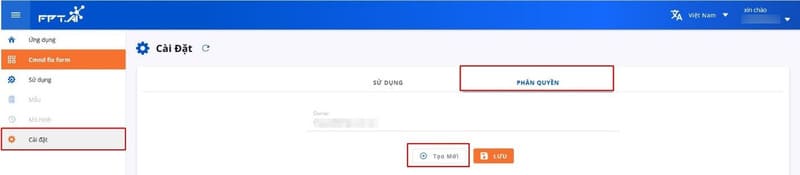
Set access rights based on the individual’s role within the organization
Select “Create new” to set permissions for the user. Select Editor or Viewer.
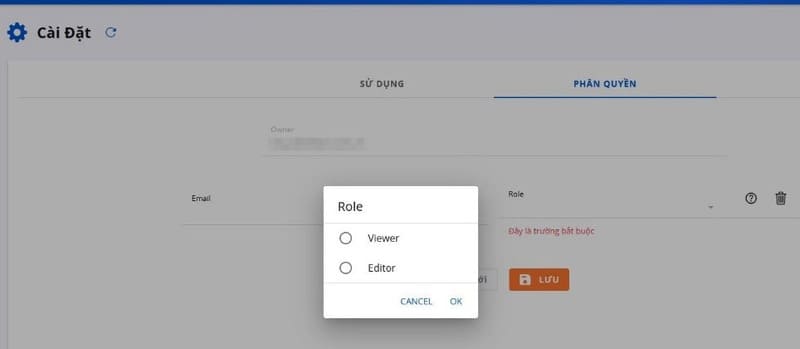
Editor or Viewer
Enter the email address of the account you want to share the project with and select the appropriate Role. There are two roles: Admin: The user can upload images to test the API as the application owner Viewer: The user can only view the test process Note: New users must have an FPT.AI Reader account before permissions can be set.
Testing OCR API
After accessing the project you want to test, on the Usage page, click the Upload button to upload a test image, click the OCR FPT.AI button to search for an image by name or apply filters to your image.
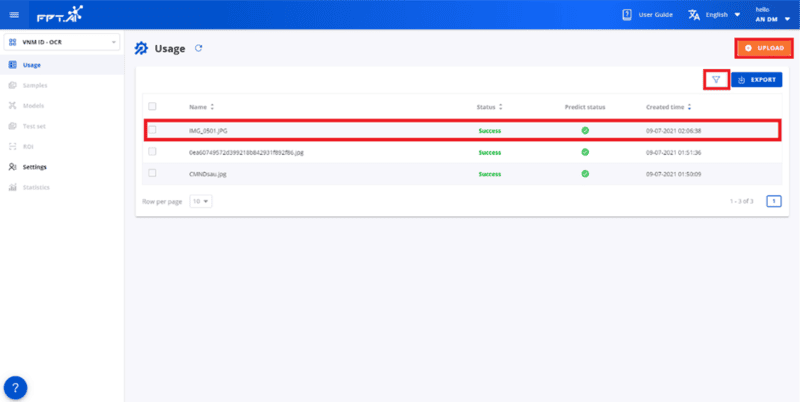
Search for images by name or filter images
Click on the image name to view API results as below:
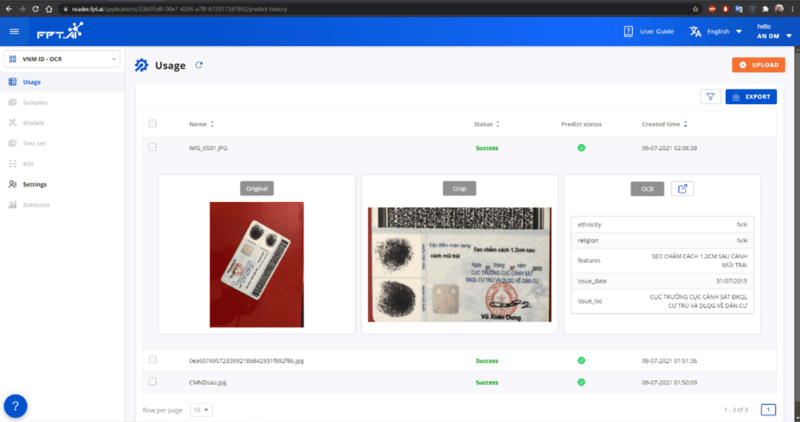
OCR API Results
Click the OCR FPT.AI button to learn more about the OCR results for your image.
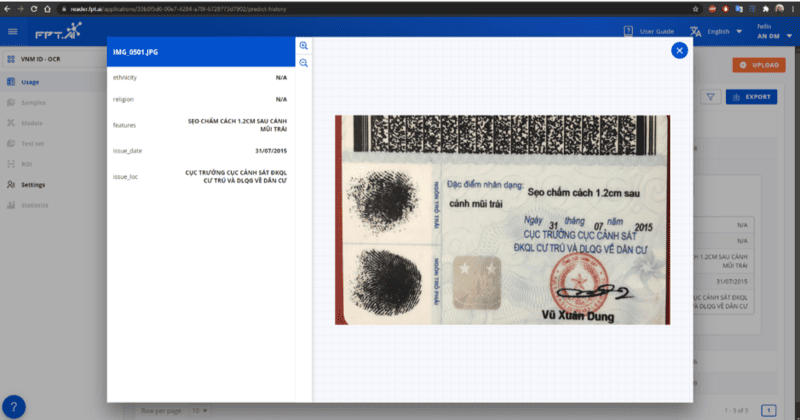
Explore image OCR results
If the extraction results are not accurate, drag the information and click the flag to report the error.
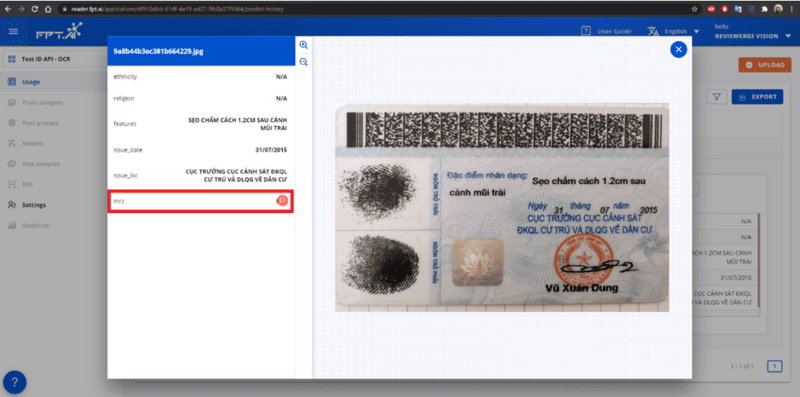
Report an error if the information is not accurate
Enter accurate information and click Save.
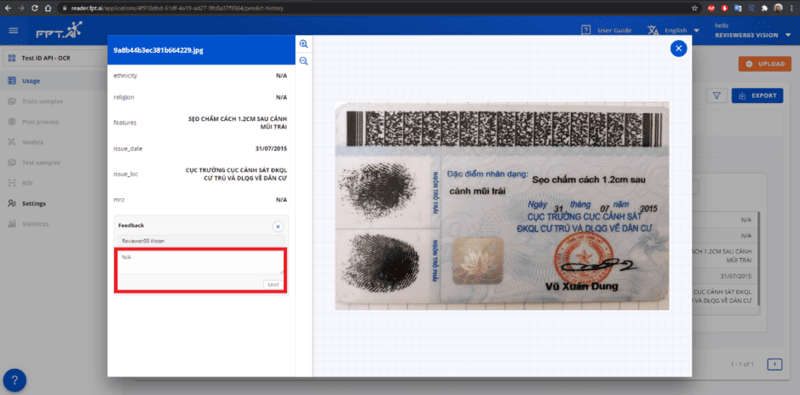
If the information is correct, click Save.
To extract or filter the OCR recognition results, click the OCR FPT.AI button and approve the data download.

Extracting Information from Custom Document Templates not in FPT AI Reader’s Library
Besides supporting information recognition and extraction from existing document templates, FPT AI Reader also allows users to build smart extraction models according to any custom document format, such as contracts, certificates, cards, etc. The specific steps are as follows:
Create a model and upload a photo of the document
For document types that are not in the library, click Applications on the navigation bar on the left side of the screen to return to the main screen, and then click the Create New button on the top right of the screen to create your own document template.
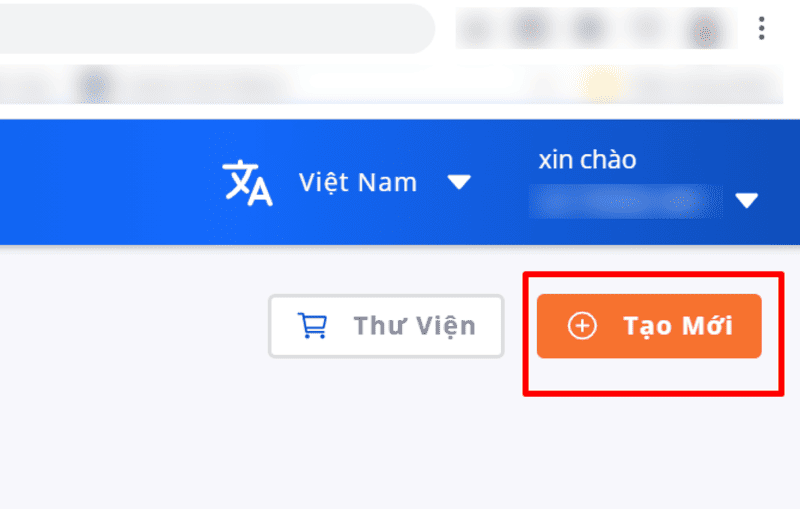
Create a new document type that is not in the library
Then, enter a project name, select the OCR document type, and click the Create button. In this article, we will use the example of how to extract information from a student ID card.
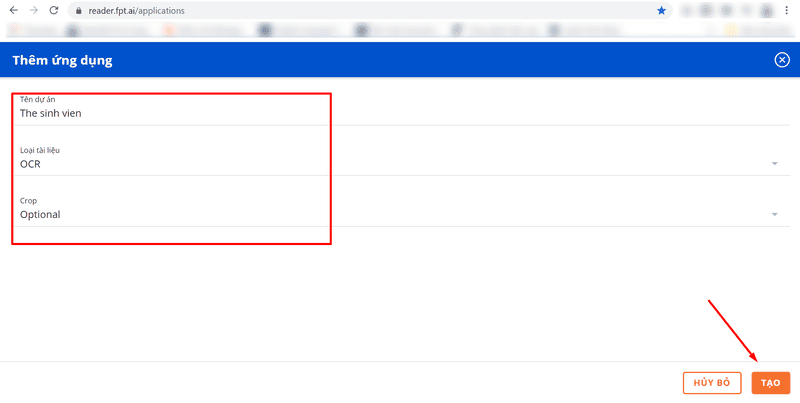
Enter the project name, select the OCR document type and click the Create button
At this point, the screen interface displays important information fields to track the entire usage process and the digitized data (name, status, update time, creation time, model use, action). The user selects the template in the navigation bar on the left side of the screen and selects Upload to upload the input data for the new document template.
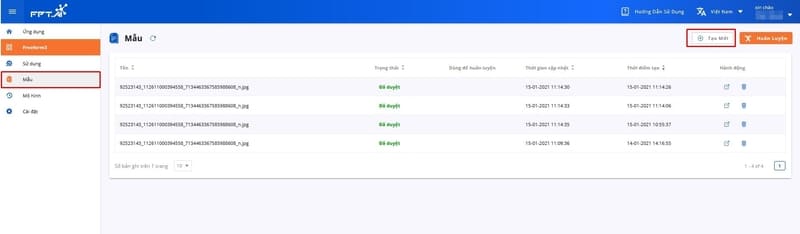
Upload input data for a new document template
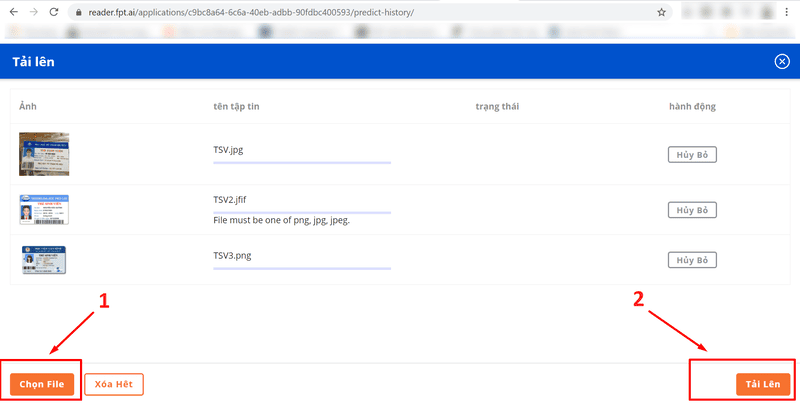
You can upload multiple image files at the same time by clicking File Selection (1) in the lower left corner of the screen. After selecting the image files of your student ID, click Upload (2) to complete this step. Note: The upload size of one file should not exceed 5MB and we accept various image formats such as jpg, png, etc.
既存の文書テンプレートで操作する場合と同様に、画像から抽出された情報は右側の列に表示されます。
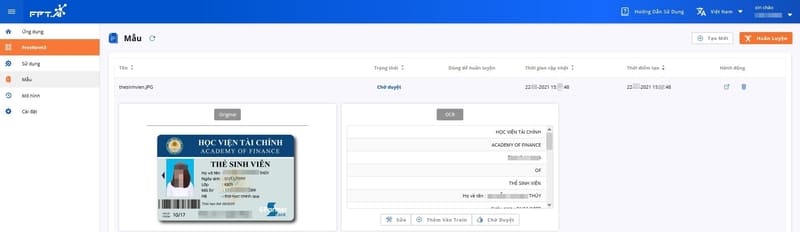
The information extracted from the image is displayed in the right column
Building an extraction model
To filter out the important information/information that needs to be extracted, users need to build a text recognition and extraction model using a core document template. The document template should be a good quality photo, taken straight, not blurry or out of frame. A good quality document template will improve the accuracy of recognition and extraction. At least three document templates are required to build a recognition and extraction model. After adding an image template to the “Templates” section, users can label the information fields that need to be extracted and select “Edit” to correct the extraction results and improve the recognition accuracy. Select “Templates” in the navigation bar on the left side of the screen, select each image that needs to be labeled and select “Edit”.
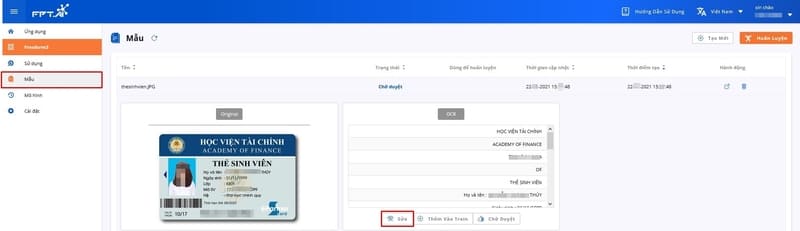
Building a recognition and extraction model for the core document template
In this step, you need to train the system by pointing out each information field (1) on the image and matching it with the data the system extracts (2). You need to correct data that is inaccurately recognized or remove unnecessary data. For each change, the system automatically saves the corrected information.
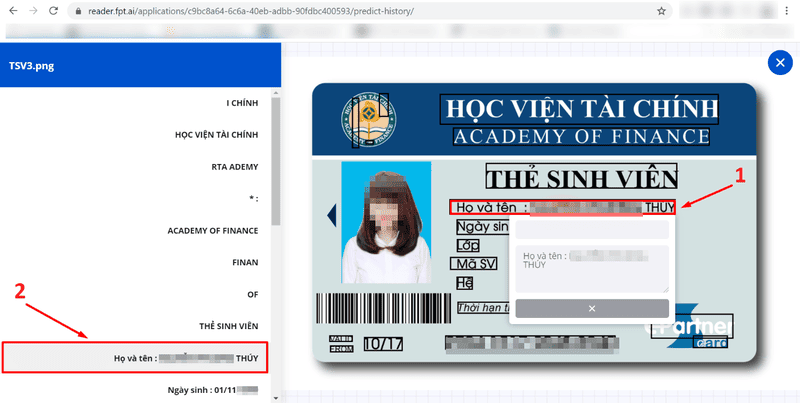
Training is required for the system to recognize information accurately
After selecting and correcting the data, select “Add to Training” to add the template to the training waiting list. **Once all data template corrections are complete, the user selects the “Train” button to allow the system to begin the data template training process
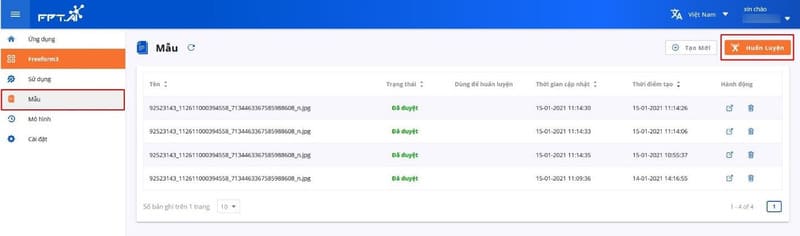
Start the training process of the data template
This training process takes several hours and requires at least three templates to start training. The system will notify the user when training is complete. FPT AI Reader software self-learns and gets smarter through previously adjusted and trained data. By providing high-quality document templates, accurately labeling the data, and regularly training and testing the model, it can be trained to easily and conveniently recognize and extract information from new document templates that are not in the library.
Using the extraction model
After the data template is successfully trained, the user recognizes and extracts documents according to the existing template format. These operations are similar to using document templates in the library. The user selects “Use” in the navigation bar on the left side of the screen, uploads the document, and receives the extraction results.
How to integrate FPT AI Reader application into your enterprise system
Integrating FPT AI Reader application into your enterprise system is very easy through API and can be done at a reasonable cost based on the actual number of requests. To connect to OCR API, you need an account on Console.fpt.ai. Then create a new API key and send requests to the gateway (by default, you can only send 50 requests per new API key). FPT AI Reader can be flexibly deployed according to the actual needs of enterprises and expand the data processing scale of the system.
Purchase additional capacity
Vietnamese OCR software FPT AI Reader provides 50 requests per year for free. However, if you need more traffic and faster conversion, you can purchase a paid plan in the “Settings” section and select the “Purchase” button. If you are an enterprise customer or need a large number of requests, please contact us immediately!
_____________________________
👉🏻 Experience other products from FPT.AI: https://fpt.ai/vi
📍 Address: 7th Floor, FPT Tower, 10 Phạm Văn Bạch, Cầu Giấy District, Hanoi City
☎️ Hotline: 1900 638 399
📧 Email: support@fpt.ai