AI systems are most effective when they reflect the people and environments they are built to serve.
Models often fail not because they lack parameters, but because they lack context. Personas provide a structured representation of the people AI systems are intended to serve, helping developers train, evaluate, and adapt models for specific populations and tasks.
For developers and businesses building AI in Vietnam, that means training and evaluating models on data that reflects Vietnam’s own population, language, and social context rather than relying solely on generalized global datasets.
FPT, in collaboration with NVIDIA, is releasing Nemotron Personas Vietnam Datasets: 900,000 synthetic personas grounded in Vietnam’s official demographic and labor statistics and made openly available on Hugging Face.
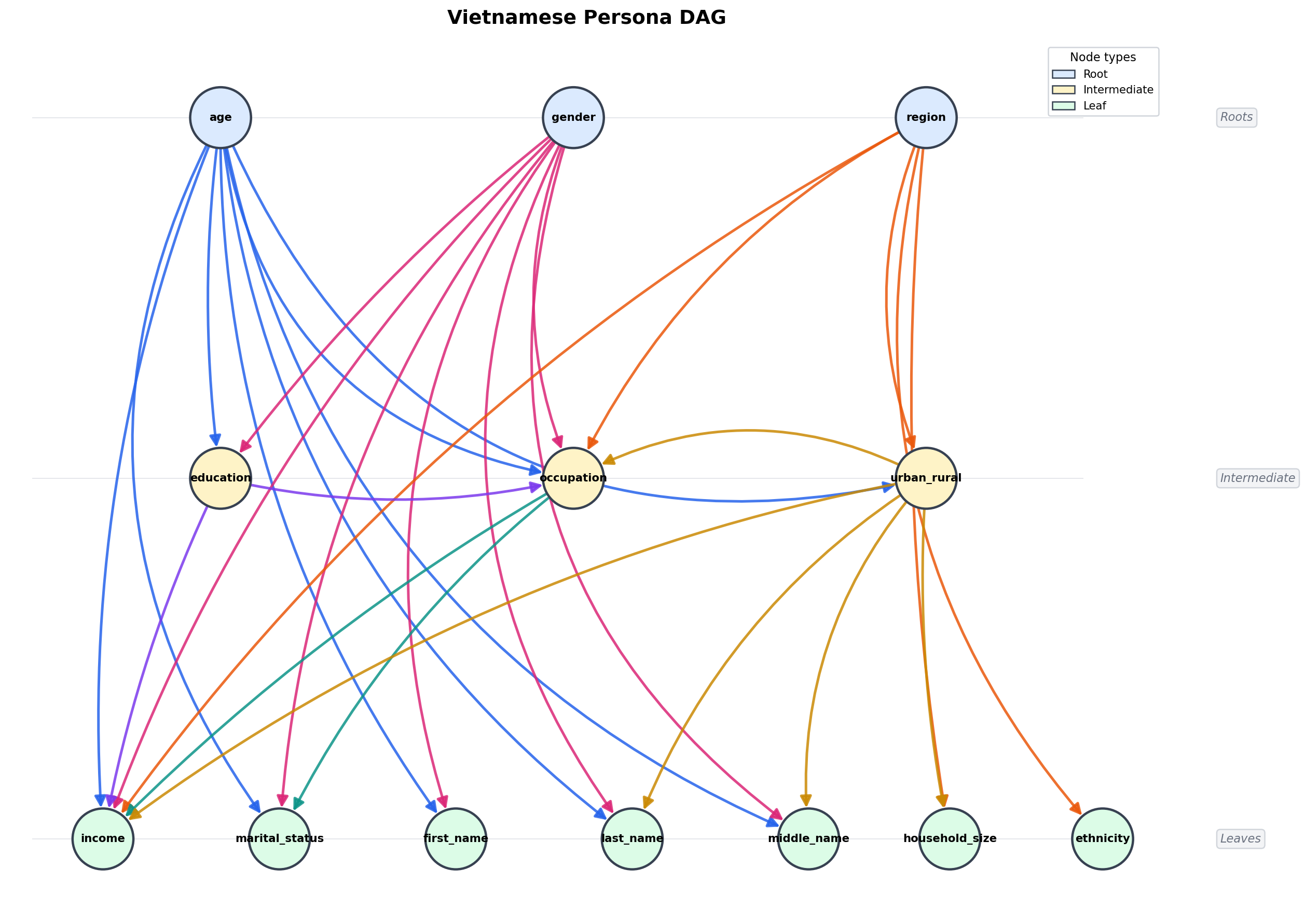
Dataset at a Glance
Nemotron-Personas-Vietnam dataset extends NVIDIA Nemotron-Personas methodology, a structured framework for building population-scale synthetic datasets that are auditable, grounded in demographic data, and designed for real-world AI development.
The original framework uses a Probabilistic Graphical Model (PGM) to anchor persona generation in real-world statistics, while open-weight LLMs generate high-fidelity personal narratives.
Unlike prompt-generated synthetic profiles, Nemotron-Personas are grounded in a PGM that preserves relationships between demographic variables such as age, occupation, education, income, and region, ensuring personas reflect real population patterns rather than random generation.
For the Vietnam dataset, FPT grounds the framework in two authoritative local sources: the Statistical Yearbook of Vietnam 2024 and Vietnam’s post-consolidation administrative boundary map. These sources serve two roles: (1) aligning the generated personas with Vietnam’s real population structure (by province, gender, and age), and (2) filling gaps where FPT’s data does not cover all demographic groups sufficiently. In turn, FPT’s data captures relationships between attributes – age, education, income, occupation, and marital status – that government statistics alone cannot provide.
Because the dataset is generated from documented public sources and an explicit generation pipeline, developers can inspect, reproduce, and adapt the methodology for their own regions and use cases.
The dataset includes 900,000 synthetic personas spanning 31 structured fields, including 9 personas, 6 persona attributes, 15 contextual attributes, and 1 unique identifier:
| Dimension | Category Level |
| Occupation | 20 |
| Age | 73 |
| Income | 7 |
| Education | 7 |
Beyond structured fields, each persona includes rich narrative attributes such as career_goals_and_ambitions, skills_and_expertise, hobbies_and_interests, cultural_background, sports_persona, culinary_persona, and more, helping developers build and evaluate models against more realistic Vietnamese user profiles.
Sample Record
Let’s take a closer look at how the dataset works in practice.
{"age": "50-64","marital_status": "da_ket_hon",
|
Consider Vũ Hồng Xuân: a 55-year-old retired educator in Ho Chi Minh City, with a university degree, a monthly income of 20–35 million VND, and a household of two. Her structured fields alone are sufficient to place her within a well-defined demographic segment. The narrative fields, however, are where the dataset’s value becomes more apparent. Her skills_and_expertise – retirement fund management, personal financial planning, investment advisory – indicate a financially literate individual with long-term asset considerations. Her hobbies_and_interests and professional_persona point to an active social life and community engagement, characteristics that bear on spending behavior and channel preferences.
For a banking model, this combination of attributes enables a more precise product recommendation than income bracket alone would allow, distinguishing her, for instance, from a younger professional at the same income level with an entirely different risk profile and financial horizon.
Built for Vietnam’s Researchers, Developers, and Enterprises
The dataset supports training, evaluation, benchmarking, red teaming, and agent development workflows across the AI lifecycle.
- LLM training and instruction tuning: Enhance model performance by incorporating diverse personas that improve response diversity, instruction adherence, and adaptability across a wide range of tasks
- Safety, security, and benchmark evaluation: Conduct red teaming, simulate phishing and social engineering scenarios, build benchmark datasets, and evaluate model behavior without relying on real user data.
- Prototyping for regulated industries: Support organizations in sectors such as finance, healthcare, and government with representative population simulations for AI model evaluation, bias assessment, and fairness testing
- Agentic AI and simulation: Create specialized agent personas, simulation environments, and evaluation benchmarks for agentic workflows grounded in realistic Vietnamese users and organizations.
Within Vietnam’s AI landscape, the market demand is clear. The country is actively promoting digital transformation, with official targets for the digital economy to reach 20% of GDP by 2025 and 30% by 2030. This increases demand for data-driven customer understanding, segmentation, and personalization [1].
Across banking, finance, healthcare, insurance, retail, and public services, organizations increasingly need realistic persona data for product testing, service personalization, simulation, and AI model evaluation [2, 3].
After more than a decade of AI development and implementation for Vietnamese enterprises, FPT witnesses two sectors standing out for immediate impact.
Banking – Finance
Vietnam’s population spans a wide range of financial literacy levels, income brackets, and attitudes toward formal banking that generic models often fail to capture accurately. Nemotron Personas Vietnam datasets give organizations structured personas to train and evaluate telesales models by income segment and communication style, and evaluate credit scoring models across different demographic groups across diverse customer profiles.
Retail
Consumer behavior across Vietnam’s regions, from the northern highlands to the Mekong Delta, differs substantially in purchasing power, product preferences, and cultural context. The dataset enables more accurate customer segmentation, recommendation engine tuning that better reflects behavior beyond major urban and high-income segments, and behavioral simulation for new market entry decisions.
As Vietnam continues investing in sovereign AI capabilities, localized datasets will play an increasingly important role in helping organizations build AI systems that are both technically capable and contextually relevant. Nemotron Personas Vietnam datasets are designed to support that effort with open, developer-ready resources grounded in Vietnamese reality.
The dataset is released openly on HuggingFace under a permissive license and is compatible with NVIDIA NeMo libraries.
————
Reference:
[1] https://www.mpi.gov.vn/en/Pages/2024-10-11/Digital-transformation-in-businesses-for-a-sustainegpc5n.aspx
[2] https://vietnamnews.vn/economy/1725975/banking-industry-needs-data-driven-customer-centric-breakthrough-experts.html
[3] https://b-company.jp/digital-transformation-in-the-healthcare-sector-in-vietnam