In the era of Industry 4.0, Machine Learning (ML) has become one of the most prominent fields of artificial intelligence (AI). With the ability to process and analyze large amounts of data, machine learning is gradually changing the way people solve complex problems and optimize business operations. This article from FPT.AI will help you better understand machine learning, from basic concepts, types of machine learning, to practical applications and challenges in the implementation process.
What is Machine Learning?
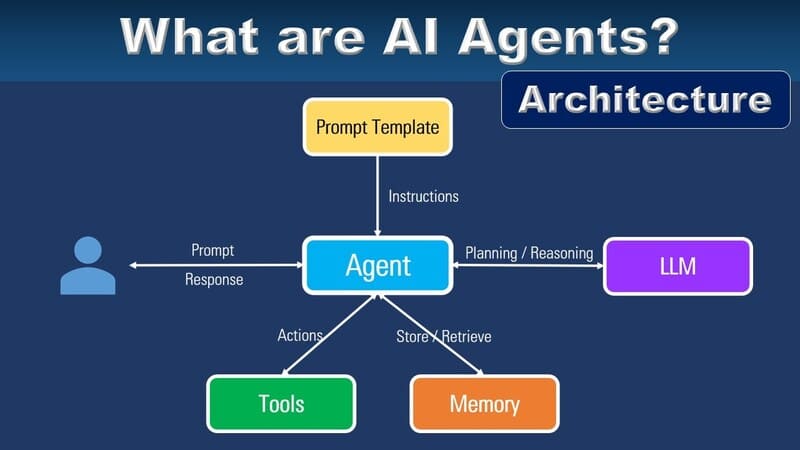
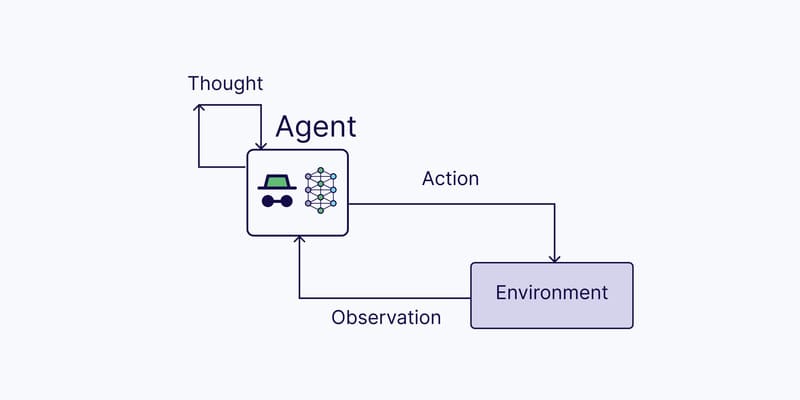
Machine Learning (ML) is a field of artificial intelligence (AI) that focuses on designing computer systems that can learn from data. Machine learning techniques provide the ability to improve the performance of software applications over time, based on input data.
Machine learning algorithms are built to discover patterns and relationships in data. Using historical data, these algorithms can perform predictions, classify, cluster data, reduce dimensionality, and even generate new content. Some notable applications of generative AI include OpenAI’s ChatGPT, Anthropic’s Claude, and GitHub Copilot. These tools clearly demonstrate the advancement of machine learning in reproducibility and performance improvement.
>>> EXPLORE: What is Generative AI? Trends in Applying Generative AI from 2024 to 2027
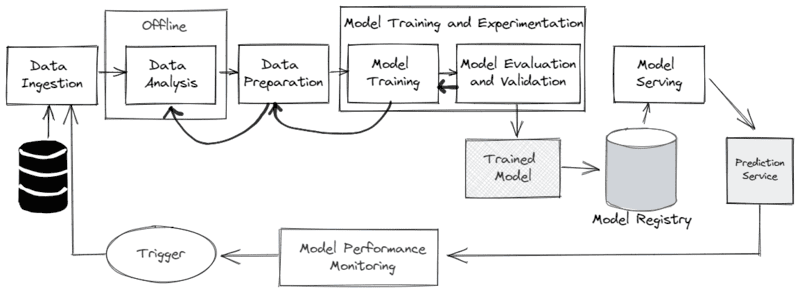
Machine Learning Workflow
Machine Learning Workflow represents the steps to take to work with machine learning effectively. Here are the specific steps:
- Data Collection: This is the first step, in which you need to prepare a dataset for the computer to learn. The data can be collected yourself or use published datasets. It is important that the data comes from reliable sources to ensure accuracy, helping the model learn more effectively.
- Preprocessing: This step is to standardize the data, remove unnecessary attributes, assign labels, encode features, extract features or reduce the size of the data while still ensuring accurate results. This is the most time-consuming step, often accounting for more than 70% of the total process time, especially when working with large amounts of data.
- Training Model: In this step, the model is trained on the processed data. The goal is to help the model “learn” from the data to make predictions or classifications.
- Evaluating Model: After training, the model needs to be evaluated using different evaluation metrics. An accuracy above 80% is generally considered a good model, but the specific criteria may vary depending on the application.
- Improve Model: If the model accuracy is not up to expectation, you need to improve it by tuning or retraining. This process repeats from step 3 until the desired result is achieved. The last three steps usually take about 30% of the total execution time.
>>> EXPLORE: What is Deep Learning? Comparing Deep Learning, AI, and Machine Learning
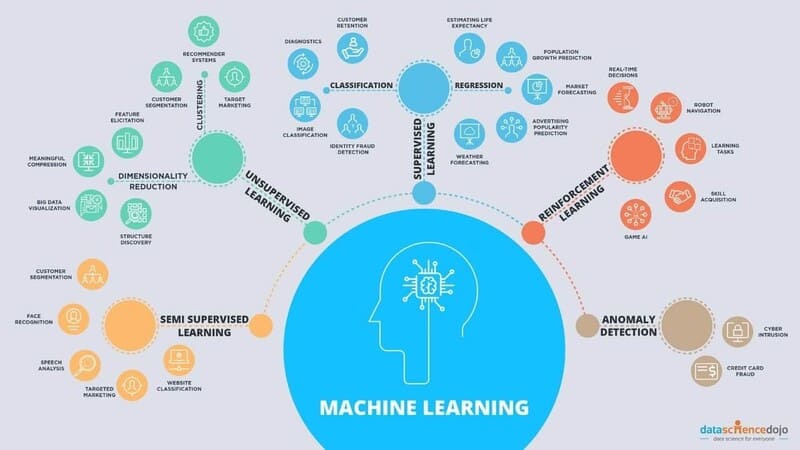
Common Types of Machine Learning
Machine Learning (ML) is often classified based on how the algorithm learns and becomes more accurate at making predictions. The four main types of machine learning include: supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning. Here are the details of each:
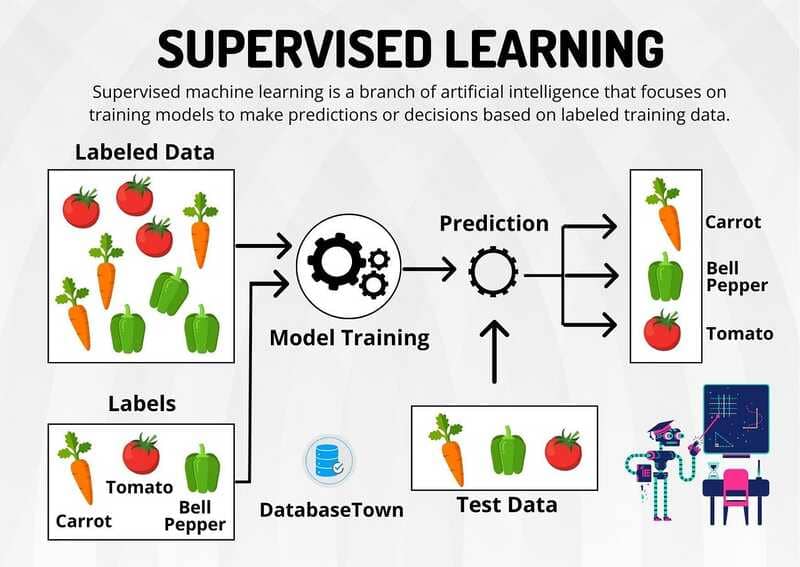
Supervised Learning
Supervised learning is a method in which the algorithm is fed labeled training data. This means that the input and output variables are clearly defined, helping the algorithm learn to associate them to make more accurate predictions.
Applications of Supervised Learning include:
- Binary classification: Dividing data into two groups (e.g., spam or non-spam emails).
- Multiclass classification: Choosing from more than two groups (e.g., classifying images into different animal categories).
Regression: Predicting continuous values (e.g. predicting house prices based on square footage and location). - Ensemble Models: Combining multiple machine learning algorithms to increase accuracy (e.g. Random Forest, Gradient Boosting).
>>> EXPLORE: Generative AI vs Machine Learning: Key Differences
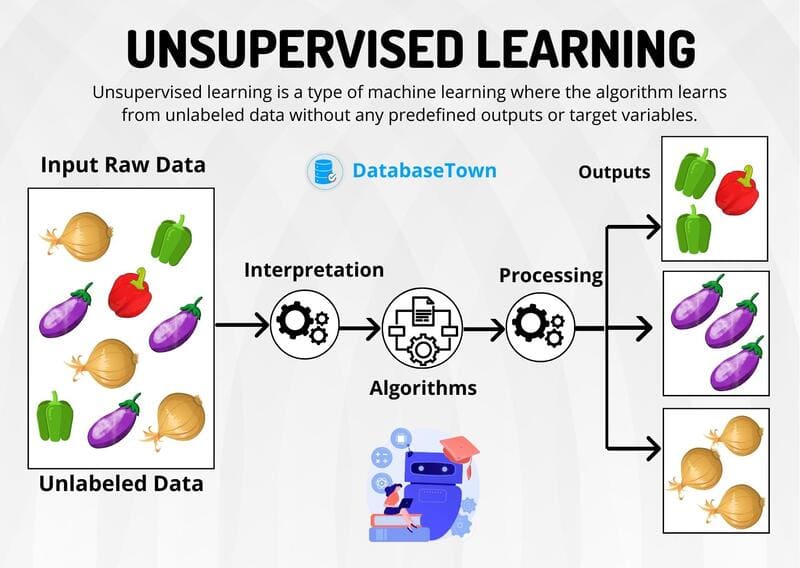
Unsupervised Learning
This method does not require labeled data, instead the algorithm automatically searches for hidden patterns and structures in the data. This is an approach often used when the goal is unclear or the data is incomplete.
Notable applications of Unsupervised Learning:
- Clustering: Group similar data points into the same group (e.g. customer segmentation in marketing).
- Anomaly Detection: Find unusual data points in a dataset (e.g. credit card fraud detection).
- Association Rule Mining: Find relationships between items that frequently appear together (e.g. product recommendations in e-commerce).
- Dimensionality Reduction: Reduce the number of variables in the data, retaining the most important information (e.g. PCA – Principal Component Analysis).
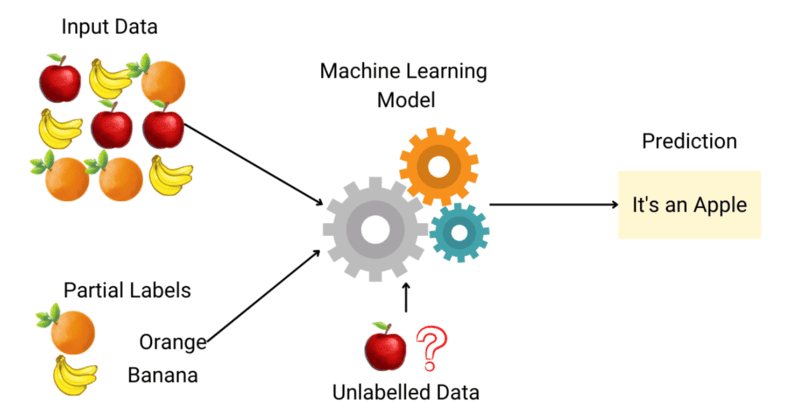
Semi-Supervised Learning
This method combines a small amount of labeled data with unlabeled data. The algorithm learns from the labeled data and applies the knowledge to process the unlabeled data.
Therefore, Semi-Supervised Learning takes advantage of unlabeled data, which is often easier to collect, while reducing the cost and time of labeling data.
Applications of Semi-Supervised Learning are as follows:
- Machine Translation: Teaching algorithms how to translate languages with a limited vocabulary.
- Fraud Detection: Analyzing fraud cases based on only a small number of positive examples.
- Automatic Data Labeling: Using small labeled data to automatically label a larger dataset.
>>> READ MORE: What is Data Leakage? How to Prevent Data Leakage when implementing Generative AI?
Reinforcement Learning
Reinforcement learning involves programming an algorithm with a clear goal and rules to achieve that goal. The algorithm is rewarded for taking actions that move it closer to its goal and penalized for going in the wrong direction.
This method is suitable for complex tasks that require continuous testing and improvement because it has the ability to optimize performance in constantly changing environments.
Applications of Reinforcement Learning include:
- Robot training: Helping robots learn to perform physical tasks such as picking up and placing objects.
- Game playing: Teaching bots to play video games or chess, Go.
- Resource planning: Helping businesses optimize resource allocation.
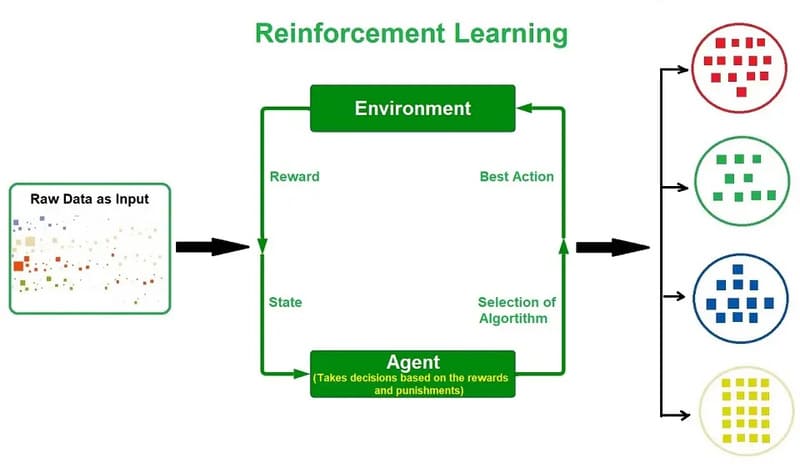
However, the choice of Machine Learning algorithm depends on the characteristics of the data and the specific requirements of the problem. For example, deep learning algorithms such as Convolutional Neural Networks and Recurrent Neural Networks can be flexibly applied in supervised learning, unsupervised learning, and reinforcement learning, depending on the problem to be solved and the availability of data.
>>> EXPLORE: What is Agentic AI? The differences between Generative AI and Agentic AI
Practical applications of machine learning
Machine learning is widely applied in fraud detection, spam filtering, malware detection, predictive maintenance, and business process automation. In e-commerce, Machine Learning is used to develop content recommendation engines based on user behavior.
In the field of self-driving cars, machine learning along with computer vision ensures that cars can navigate safely on the road. Especially in medicine, ML helps doctors diagnose and develop treatment plans based on patient data.
In business, companies use machine learning to:
- Business intelligence (BI): Predictive analytics and BI software use machine learning algorithms such as linear regression and logistic regression to identify important data points, patterns, and anomalies in large data sets. This information helps businesses make data-driven decisions, forecast trends, and optimize performance. Advances in generative AI also enable the creation of reports and dashboards that summarize complex data in an easy-to-understand format.
- Customer relationship management (CRM): Machine learning applications in CRM include analyzing customer data to segment markets, predict behavior like churn, make personalized recommendations, adjust pricing, optimize email campaigns, provide chatbot support, and detect fraud. Generative AI can also create customized marketing content, automate customer service responses, and generate insights based on customer feedback.
- Security and compliance: Support vector machines (SVMs) can distinguish deviations in behavior from the norm, which is important for detecting potential cyber threats, by finding the best boundary to divide data into different groups. Generative adversarial networks (GANs) can generate fake malware samples, helping security teams train machine learning models to better distinguish between safe and malicious software.
- Human resource information systems (HRIS): Machine learning models help optimize the recruiting process by filtering applications and identifying the best candidates for a position. They can also predict employee churn, suggest career paths, and automate interview scheduling. Generative AI can help create personalized job descriptions and training materials.
- Supply chain management: Machine learning can optimize inventory levels, streamline logistics, improve supplier selection, and proactively address supply chain disruptions. Predictive analytics can help forecast demand more accurately, and AI-driven simulations can model different scenarios to improve resilience.
- Natural language processing (NLP): Natural language processing applications include sentiment analysis, language translation, and text summarization, among others. Advances in generative AI, such as OpenAI’s GPT-4 and Google’s Gemini, have significantly improved these capabilities. Generative NLP models can generate human-like text, improve virtual assistants, and enable more complex language applications, including content generation and document summarization.
Examples of real-world enterprise machine learning applications include:
- Financial services: Capital One uses machine learning to enhance analysis of large volumes of data, detect anomalous transactions, provide personalized customer experiences, and improve business planning. The company uses the MLOps approach to deploy machine learning applications at scale.
- Pharmaceuticals: Drugmakers use machine learning in drug discovery, clinical trials, and manufacturing. For example, Eli Lilly has built AI and machine learning models to identify the best locations for clinical trials and increase participant diversity, significantly reducing trial times.
- Insurance: Progressive Corp.’s popular Snapshot program uses machine learning algorithms to analyze driving data to offer better rates to safe drivers. Other applications of machine learning in insurance include underwriting and claims processing.
- Retail: Walmart has deployed “My Assistant,” an AI content-generating tool that helps its roughly 50,000 employees create content, summarize large documents, and act as a full-service “creation partner.” The company also uses the tool to gather employee feedback on use cases.
>>> READ NOW: What is Robotic Process Automation? Practical Applications of RPA
Difference Between Machine Learning and Deep Learning
Deep Learning is a sub-branch of machine learning that focuses on using deep neural networks to process and extract information from data. With its multi-layered structure, deep learning allows models to automatically learn hierarchical features, which is especially effective in image and speech recognition.
Advantages and Disadvantages of Machine Learning
Machine learning (ML), when implemented effectively, provides a significant competitive advantage to businesses by analyzing trends and predicting outcomes with greater accuracy than traditional statistical methods or human reasoning. Some of the key benefits that ML brings to businesses include:
- Analyzing historical data for customer retention: ML can analyze past customer data to learn about behavior and help build customer retention strategies.
- Introducing intelligent recommendation systems: Personalized recommendation systems increase revenue by offering products or services that match customer preferences.
- Improved planning and forecasting: ML helps businesses plan more accurately for the long term and optimize supply chains.
- Evaluate models to detect fraud: Using transaction data, ML algorithms can detect fraud faster and more accurately.
- Increase operational efficiency and reduce costs: ML automates routine tasks, reducing the workload on employees and optimizing processes.
However, ML also faces significant challenges. First, ML can be very expensive to implement. Investing in software, hardware, and data management infrastructure requires a large investment, not to mention the high salaries of data scientists and machine learning engineers.
Complex algorithms like Deep Neural Networks not only require huge amounts of data, but also make it difficult to interpret the results. Bias in data, caused by algorithms learning from flawed data sets or excluding certain groups of people, can lead to inaccurate or discriminatory results. If businesses rely on biased models to make decisions, the legal and reputational consequences can be severe.
>>> EXPLORE: What is Conversational AI? Comparing Conversational AI vs Generative AI
How to Choose and Build the Right Machine Learning Model
Developing an effective machine learning model to solve a problem requires dedication, thorough testing, and creativity. While this process can be complex, it can be summarized in seven key steps to building a machine learning model:
- Understand the business problem and define success criteria: Convert the team’s knowledge of the business problem and project goals into a problem definition appropriate for machine learning. Consider why the project needs machine learning, choose the most appropriate algorithm for the problem, requirements for transparency, minimizing bias, and defining the desired inputs and outputs.
- Define data needs and understand the data needed: Determine the type of data needed to build the model and assess the data readiness for training. Consider the volume of data needed, how to split the data into training and testing sets, and whether pre-trained machine learning models can be used.
- Collect and prepare data for training: Clean and label the data, including replacing incorrect or missing data, reducing noise, and removing ambiguity. This stage may also include data augmentation, adding necessary data, and anonymizing personal data depending on the dataset. Finally, divide the data into training, testing, and validation sets.
- Define model features and train: Start by selecting appropriate algorithms and techniques, including setting hyperparameters. Next, train and validate the model, then optimize as needed by adjusting hyperparameters and weights. Depending on the business problem, algorithms may include natural language processing capabilities, such as recurrent neural networks (RNNs) or transformers for NLP tasks, or boosting algorithms to optimize decision tree models.
- Evaluate model performance and establish benchmarks: Perform calculations such as confusion matrices, identify business KPIs and machine learning metrics, measure model quality, and determine whether the model meets business objectives.
- Deploy the model and monitor performance in production: This part of the process, often referred to as model operationalization (MLOps), is typically done collaboratively between data scientists and machine learning engineers. Continuously measure model performance, develop benchmarks for future model versions, and repeat the process to improve overall performance. The deployment environment can be in the cloud, at the edge, or on-premises.
- Continuously refine and adjust the model during operation: Even after a machine learning model has been put into production and is continuously monitored, the work is not done. Changes in business needs, technological capabilities, and real-world data can pose new requirements and challenges.
In short, machine learning has proven to be an important role in shaping the future of technology and society. With its powerful analytical, predictive, and automation capabilities, machine learning not only opens up new opportunities but also drives breakthrough developments in many fields.
However, to fully exploit the potential of machine learning, it is necessary to understand how to apply it, along with considering ethical challenges, bias, and costs. Businesses need to ensure data quality, reduce bias in the model so that Machine can maximize its effectiveness without causing negative impacts. Hopefully FPT.AI’s article has provided you with useful information.
>>> EXPLORE: